Last updated on 24th Jan 2022| 4115
Hive concepts and data file partitioning are fundamental to efficient big data processing in Hadoop. Hive provides a SQL-like interface for querying and managing large datasets stored in Hadoop Distributed File System (HDFS). Data file partitioning in Hive divides tables into smaller, manageable parts based on column values, which significantly improves query performance and data organization. This technique enables faster data retrieval by scanning only the relevant partitions, reducing the amount of data processed and enhancing overall query efficiency.
What is Hive Concepts and Data File Partitioning?
Within the Hadoop ecosystem, Hive is a data warehousing and SQL-like query language tool that makes managing and querying massive datasets stored in the Hadoop Distributed File System (HDFS) easier. By enabling users to write queries in HiveQL, which is similar to SQL, Hive translates these queries into MapReduce jobs, making it easier to process and analyze massive amounts of data in a distributed environment.
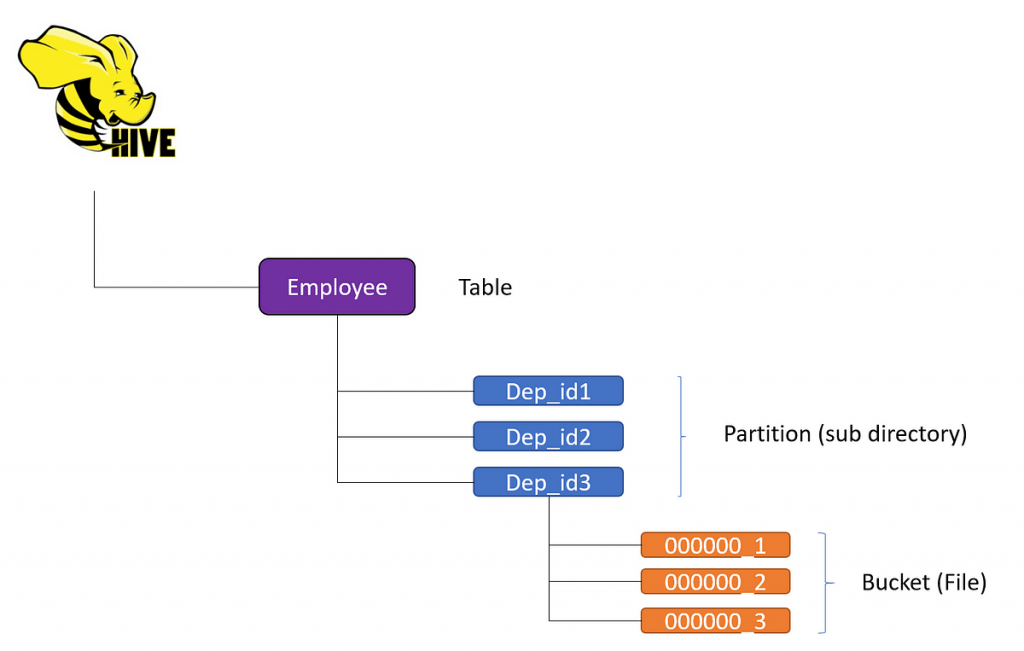
Data file partitioning in Hive is a critical technique used to improve query performance and data management. This method involves dividing large tables into smaller, more manageable parts, called partitions, based on the values of specific columns, such as date or region. By organizing data into partitions, Hive can significantly enhance query efficiency.
When a query is executed, Hive scans only the relevant partitions instead of the entire dataset, thus reducing the amount of data processed. This selective scanning leads to faster query execution times and more efficient resource use. Additionally, partitioning aids in data organization, making it easier to manage and maintain large datasets.
What are the advantages of using Hive concepts and data file partitioning?
- Improved Query Performance: Partitioning divides tables into smaller segments based on column values, allowing queries to scan only relevant partitions rather than the entire dataset. This significantly speeds up query execution.
- Efficient Data Organization: Partitioning helps in logically organizing data, making it easier to manage and retrieve specific subsets of data.
- Scalability: Hive can handle vast amounts of data efficiently, and partitioning further enhances its capability to scale by optimizing storage and retrieval processes.
- Cost-Effective: By reducing the amount of data scanned during queries, partitioning helps lower resource usage and costs associated with data processing.
- Ease of Use: Hive’s SQL-like interface makes it accessible for users familiar with traditional SQL, simplifying the process of writing and executing queries on large datasets.
- Reduced I/O Operations: Partitioning minimizes the input/output operations by targeting specific partitions, which leads to faster data access and processing times and thereby improves overall system efficiency.
- Better Data Management: By organizing data into partitions, it becomes easier to manage data lifecycle events such as data retention, archiving, and purging. This ensures that only the most relevant and recent data is kept active.
- Enhanced Parallel Processing: Partitioning allows for parallel data processing, as different partitions can be processed simultaneously. This parallelism maximizes resource utilization and reduces the time needed for complex data processing tasks.

Get Practical Oriented Hive Concepts and Data File Partitioning Certification Course By Experts Trainers
Weekday / Weekend BatchesSee Batch DetailsTutorial Coverage for Partitioning Data Files and Hive Concepts:
This tutorial aims to provide a comprehensive understanding of Apache Hive concepts and the essentials of data file partitioning. It will cover the fundamental architecture and components of Hive, including the Hive Metastore, Hive Query Language (HQL), and the execution engine. The tutorial will delve into the significance of data partitioning in Hive, explaining how it enhances query performance by reducing data scan times and optimizing resource utilization.
Hive Query Language (HQL)
- Basic Queries: Introduction to HQL syntax, including SELECT statements, filtering with WHERE clauses, and essential functions for data retrieval.
- Advanced Queries: Techniques for writing complex queries involving joins, subqueries, window functions, and advanced aggregations to perform sophisticated data analysis.
- Data Manipulation: Commands for inserting, updating, and deleting data within Hive tables, understanding the implications of these operations in a distributed environment.
Importance of Data Partitioning
- Concept of Partitioning: Detailed explanation of data partitioning and how it logically divides large tables into smaller, more manageable pieces based on partition keys.
- Performance Optimization: Discussion on how partitioning can significantly reduce query times by scanning only relevant partitions instead of entire datasets.
- Resource Management: Effective use of system resources through partitioning, reducing I/O operations, and enhancing overall query performance and scalability.
Practical Implementation
- Creating Partitioned Tables: This section provides step-by-step instructions for defining and creating partitioned tables in Hive, including specifying partition keys and structure.
- Managing Partitions: Techniques for adding, modifying, and deleting partitions, as well as managing dynamic partitions to accommodate new data.
- It is querying Partitioned Data: Best practices for writing efficient queries that take advantage of partition pruning to improve performance.
Hands-on Exercises
- Real-world Scenarios: Practical examples that simulate real-world data warehousing scenarios, guiding participants through the process of creating and managing partitioned tables.
- Performance Tuning: Exercises focused on optimizing query performance through effective partitioning strategies, indexing, and other tuning techniques.
- Troubleshooting: Identifying common issues related to Hive partitioning, offering solutions and best practices for maintaining partitioned data in production environments.
Comprehensive Guide to Hive Concepts and Data File Partitioning:
STEP 1. Hive Overview
- Introduction to Hive: Understand Hive as a data warehouse infrastructure built on Hadoop for querying and managing large datasets.
- Hive Architecture: Explore the architecture, including Hive Metastore, HiveQL (Hive Query Language), and execution engine.
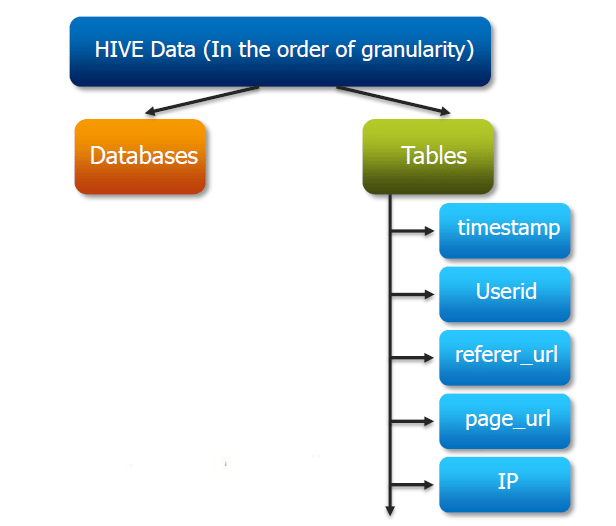
STEP 2. Hive Data Model
- Tables and Databases: Learn how Hive organizes data into tables and databases and understand the similarities and differences compared to traditional databases.
- Examine the idea of “schema on read,” in which data structures are applied during reading rather than storing.
STEP 3. Hive Query Language (HiveQL)
- Syntax and Basic Queries: Learn HiveQL syntax and execute basic queries to retrieve, insert, and manipulate data.
- Advanced Queries: Dive deeper into HiveQL with joins, subqueries, aggregations, and user-defined functions (UDFs).
STEP 4. Data File Partitioning in Hive
- Partitioning Concepts: Understand the concept of partitioning data files based on specific columns to improve query performance.
- Static vs. Dynamic Partitioning: Compare static partitioning, where partitions are predefined, with dynamic partitioning, where partitions are determined during data insertion.
- Partitioning Best Practices: Learn best practices for designing and implementing partitions to optimize data retrieval and storage efficiency.
STEP 5. Managing Hive Tables
- Creating and Altering Tables: Step-by-step instructions for creating and modifying Hive tables, including partitioned tables.
- Loading Data: Techniques for loading data into Hive tables from various sources, such as HDFS files and external databases.
- Optimizing Table Storage: Strategies to maximise table storage formats (e.g., ORC, Parquet) and compression for better performance.
STEP 6. Performance Tuning and Optimization
- Indexing: Explore indexing options in Hive to speed up data retrieval for specific queries.
- Cost-Based Optimization and Statistics: To enhance query execution plans, apply cost-based optimization strategies and statistics.
- Tuning Hive Queries: Tips and techniques for tuning Hive queries for optimal performance in large-scale environments.
STEP 7. Integration with the Hadoop Ecosystem
- Integration with HDFS: Recognize the ways in which Hive stores and retrieves data in relation to the Hadoop Distributed File System (HDFS).
- Integration with Spark: Explore integration possibilities with Apache Spark for enhanced data processing capabilities.
STEP 8. Advanced Hive Concepts
- User-Defined Functions (UDFs): Develop and use custom UDFs to extend HiveQL functionality for specific business requirements.
- Transactions and ACID Compliance: Overview of Hive’s capabilities for handling transactions and ensuring ACID (Atomicity, Consistency, Isolation, Durability) compliance.
STEP 9. Real-World Use Cases and Best Practices
- Case Studies: Examine real-world scenarios where Hive is used effectively for data processing and analytics.
- Best Practices: Guidelines and recommendations for implementing Hive in production environments, ensuring scalability, reliability, and performance.
Conclusion
- Summary of Key Concepts: This section recaps the key concepts covered in the guide, emphasizing the importance of Hive in big data analytics and data warehousing.
- Further Learning: Resources and references for expanding knowledge of Hive, including books, online courses, and community forums.

Get JOB Oriented Hive Concepts and Data File Partitioning Training from Real Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Setting Up Hive Concepts and Partitioning Data Files: Crucial Procedures and Optimal Approaches
Setting up Hive involves several crucial procedures and optimal approaches, especially when it comes to partitioning data files. Here’s a structured approach to understanding and implementing these concepts effectively:
1. Introduction to Hive Setup:
Begin by installing and configuring Apache Hive in your cluster environment to enable data warehousing and SQL-like query capabilities on top of your Hadoop ecosystem. First, ensure that your Hadoop distribution is compatible with the version of Hive you plan to install. Download the appropriate Hive distribution package from the Apache Hive website and extract it to a designated directory on your cluster nodes.
2. Understanding Hive Concepts:
- Tables and Databases: Define Hive databases and tables to organize your data logically.
- HQL (Hive Query Language): Learn the basics of HQL for querying and managing data stored in Hive tables.
- Metastore: Set up and maintain the Hive Metastore, which is used to store metadata about Hive partitions and tables.
3. Partitioning Data Files:
- What is Partitioning?: Understand how partitioning organizes data files into directories based on specific columns, improving query performance and manageability.
- Choosing Partition Columns: Select appropriate columns for partitioning based on your data access patterns and query requirements.
- Partitioning Strategies: Depending on the nature of your data and workload, implement partitioning strategies such as range, list, or hash partitioning.
4. Crucial Procedures:
- Creating Hive Tables: Use CREATE TABLE statements to define Hive tables, specifying storage formats (e.g., ORC, Parquet) and partitioning details.
- Loading Data: Use LOAD DATA commands or INSERT statements to Populate Hive tables with data from external sources or existing Hadoop files.
- Managing Partitions: Add, drop, or alter partitions as needed to accommodate new data or changes in partitioning criteria.
- Optimizing Performance: Monitor and optimize query performance by leveraging partition pruning and statistics.
5. Optimal Approaches:
- Partitioning Best Practices: Follow best practices such as limiting the number of partitions per table, using appropriate data types for partition columns, and maintaining partition granularity.
- Data Organization: Organize data files within partitions efficiently to facilitate efficient data retrieval and processing.
- Data Lifecycle Management: Implement strategies for data retention, archiving, and deletion based on partitioning criteria to manage data effectively over time.
6. Automation and Maintenance:
- Automating Tasks: Use tools like Apache Oozie or Airflow to automate data loading, partition management, and optimization tasks.
- Monitoring and Maintenance: Regularly monitor Hive performance metrics, Metastore health, and data file sizes to identify optimization opportunities and ensure system reliability.
By following these procedures and adopting optimal approaches, you can effectively set up Hive, leverage partitioning to enhance data management and query performance and maintain a robust data processing environment in your Hadoop ecosystem.
Establishing Basic Monitoring for Hive Concepts and Data File Partitioning:
Establishing essential monitoring for Hive concepts and data file partitioning involves several vital steps to ensure efficient data management and performance optimization:
1. Monitoring Hive Concepts:
- Query Execution Monitoring: Implement monitoring for Hive query execution times, resource utilization (CPU, memory), and query plans to identify inefficiencies and optimize performance.
- Job Scheduler Monitoring: Monitor the Hive job scheduler to track job completion times, job dependencies, and overall cluster workload management.
- Resource Allocation: Set up monitoring for resource allocation and utilization across Hive clusters to ensure balanced workload distribution and avoid resource bottlenecks.
2. Data File Partitioning Monitoring:
- Partition Size Monitoring: Monitor the size of partitions created in Hive tables to ensure they are appropriately sized for efficient data retrieval and processing.
- Partitioning Strategy Evaluation: Evaluate partitioning strategies based on data access patterns and query requirements. Monitor query performance across different partitioning schemes to optimize data retrieval times.
- Partition Maintenance: Set up monitoring for partition maintenance tasks, such as adding new partitions, dropping old partitions, and ensuring data retention policies are adhered to.
3. Performance Metrics Monitoring:
- Query Performance: Monitor Hive query performance metrics such as execution time, data scanned, and join operations to identify queries that may require optimization.
- Data File Metrics: Monitor metrics related to data file sizes, file formats (e.g., ORC, Parquet), and storage locations to optimize data storage and retrieval efficiency.
- Concurrency and Workload: Monitor concurrent query execution and workload patterns to adjust resource allocation and optimize Hive cluster performance.
4. Alerting and Notifications:
Set up alerts and notifications for critical metrics, such as query failures, resource overutilization, or partitioning errors, to proactively address issues and ensure continuous operation. Set resource consumption and performance metric thresholds to initiate alerts and messages, allowing for preventative maintenance and prompt intervention.
5. Reporting and Analysis:
Implement reporting and analysis capabilities to visualize monitoring data trends, performance metrics, and resource utilization over time. Use historical data analysis to identify long-term trends, optimize Hive configurations, and make informed decisions about capacity planning and resource allocation. By establishing robust monitoring practices for Hive concepts and data file partitioning, organizations can effectively manage and optimize their Hive deployments, ensuring efficient data processing, enhanced performance, and proactive management of cluster resources.
Exploring Advanced Topics in Hive Concepts and Data File Partitioning:
Hive, a robust data warehouse infrastructure built on top of Hadoop, offers several advanced concepts and techniques for optimizing data management and query performance. Here are vital topics to delve into:
1. Hive Concepts:
- Schema on Read: Understand how Hive allows data to be structured upon reading rather than at the time of ingestion, providing flexibility in data handling.
- Hive Metastore: Explore the role of the megastore in storing metadata information, including schemas, table definitions, and partition details.
- HiveQL: Delve into Hive’s SQL-like query language, HiveQL, and its capabilities for querying and managing large datasets stored in Hadoop Distributed File System (HDFS) or other compatible storage systems.
- Managed vs. External Tables: Learn the differences between managed tables (where Hive manages data and metadata) and external tables (where data is managed externally, but Hive manages metadata).
2. Data File Partitioning:
- Partitioning Strategies: Explore different partitioning strategies, such as static partitioning (based on predefined values) and dynamic partitioning (based on data values).
- Benefits of Partitioning: Understand the advantages of partitioning in terms of query performance optimization, data organization, and management.
- Partition Pruning: Learn how Hive optimizes query performance by reading only relevant partitions based on query predicates, reducing the amount of data scanned.
- Partition Maintenance: Best practices for managing and maintaining partitions over time, including adding, dropping, or altering partitions as data evolves.
3. Advanced Data File Formats:
- Columnar Storage Formats: Explore columnar storage formats like ORC (Optimized Row Columnar) and Parquet, designed to improve query performance and reduce storage space.
- Compression Techniques: Understand how compression techniques (e.g., Snappy, Gzip) can be applied to Hive data files to reduce storage requirements and improve query performance.
- Serialization and Deserialization (SerDe): Overview of custom SerDe libraries for handling various data formats and structures within Hive tables.
4. Advanced Query Optimization:
- Join Optimization: Techniques for optimizing join operations in Hive, including map-side joins, broadcast joins, and sort-merge joins.
- Statistics and Cost-Based Optimization: Understand how statistics collection and cost-based optimization techniques can enhance query performance in Hive.
- Indexing: Explore Hive’s indexing options (e.g., Bitmap Indexing) and their impact on query performance for specific use cases.
5. Integration with Ecosystem Tools:
- Integration with Spark and HBase: Learn how Hive integrates with Apache Spark for real-time processing and Apache HBase for NoSQL capabilities, extending its functionality beyond traditional batch processing.
- Data Ingestion Pipelines: Explore techniques for integrating Hive with data ingestion pipelines, including Apache Kafka for real-time data streaming.
- By exploring these advanced topics in Hive, data engineers and analysts can leverage Hive’s capabilities to build scalable, efficient, and optimized data processing pipelines for big data analytics and reporting within Hadoop ecosystems.
Conclusion:
In conclusion, delving into Hive concepts and data file partitioning reveals a robust framework for managing and querying large-scale data within the Hadoop ecosystem. Hive’s ability to provide a SQL-like interface (HiveQL) simplifies data access and manipulation, making it accessible to analysts familiar with SQL. The Hive Metastore plays a crucial role in storing metadata and facilitating schema management and integration with external systems.
Data file partitioning enhances query performance by organizing data into manageable segments based on specified criteria, such as date ranges or categorical values. This partitioning strategy not only optimizes data retrieval but also improves data processing efficiency by leveraging partition pruning techniques.




