
Last updated on 09th May 2024| 3870
CloverETL stands as a resilient and adaptable data integration platform crafted to simplify the extraction, transformation, and loading (ETL) of data from multiple sources. Featuring an intuitive graphical interface and formidable backend processing prowess, CloverETL enables organizations to effectively handle intricate data workflows. Its array of connectors and transformation components facilitates smooth integration with a multitude of data sources and formats, ensuring seamless operations.
1. What about data integration?
Ans:
Data integration is the process of merging information from several sources to create a unified view, which is crucial for organizations to gain a comprehensive understanding of their data landscape. This process enhances decision-making by providing accurate and complete information. Streamlining data also increases operational efficiency workflows and reduces redundancies. Additionally, data integration enriches customer experiences through personalized insights and supports innovation by uncovering actionable insights from the integrated data.
2. Explain the three-layer architecture of an ETL cycle.
Ans:
- Extraction Layer: This Layer gathers Data from many sources, such as databases, files, and APIs.
- Transformation Layer: Data undergoes cleaning, validation, and restructuring to meet the target schema and business rules.
- Loading Layer: Transformed data is fed into the destination, usually a data warehouse or a database, making it ready for analysis and reporting.
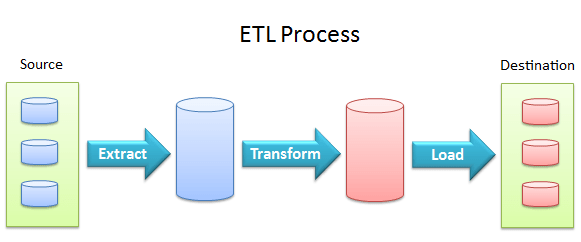
3. What is the difference between OLAP tools and ETL tools?
Ans:
- OLAP (Online Analytical Processing) tools are designed to query and analyze multidimensional data from various perspectives.
- They facilitate complex data analysis, including slicing, dicing, drilling down, and rolling up data.
- ETL (Extract, Transform, Load) tools, on the other hand, are used to extract data from different sources, convert it to an appropriate format, and load information into a destination—database or data warehouse.
4. What are Cubes and OLAP Cubes?
Ans:
In the context of databases, Cubes are multidimensional structures used for analysis and reporting. They organize data into dimensions representing attributes or categories and measures, which are the numerical values being analyzed. OLAP (Online Analytical Processing) Cubes are designed explicitly for multidimensional analysis, allowing users to efficiently slice, dice, and pivot data across multiple dimensions.
5. what is meant by an ETL Pipeline?
Ans:
An ETL (Extract, Transform, Load) pipeline is the process of extracting data from many sources, changing it to a uniform format, and putting it into a data warehouse or database. It involves extracting raw data, applying various transformations like cleaning, filtering, and aggregating, and finally loading the transformed data into a target system for analysis or storage. ETL pipelines ensure data quality, consistency, and accessibility in data-driven organizations.
6. What are the differences between BI tools and ETL tools?
Ans:
- BI (Business Intelligence) tools analyze and visualize data to generate insights and aid decision-making. On the other hand, ETL (Extract, Transform, Load) tools are primarily concerned with data integration;
- Data is extracted from numerous sources, transformed into an appropriate format, and then loaded into a data warehouse or another destination.
- While BI tools facilitate data analysis and reporting, ETL tools handle the data processing and integration aspect of the data pipeline.
7. Define ODS (Operational Data Store).
Ans:
An Operational Data Store (ODS) is a centralized database that provides a snapshot of operational data from various sources in an organization. It serves as an intermediate storage facility between transactional systems and data warehouses. ODS typically holds current or near-real-time data for operational reporting and decision-making. It helps streamline data integration and provides a consistent view of information across departments.
8. Explain the tracing level and its types.
Ans:
Tracing level refers to the degree of detail captured in a system’s log or debug output. It helps diagnose issues and monitor system behavior. Types include:
- Off: No tracing.
- Error: Logs only errors.
- Warning: Logs warnings and errors.
- Info: Logs informational messages along with warnings and errors.
9. What are the differences between ETL and ELT?
Ans:
| Aspect | ETL | ELT |
|---|---|---|
| Sequence of Operations | Extract, Transform, Load | Extract, Load, Transform |
| Transformation Location | Transformations occur outside the target database | Transformations occur within the target database |
| Data Storage | Requires intermediate storage for transformed data | Utilizes target database for storage |
| Scalability and Performance | May face scalability challenges, affected by data movement | Leverages database scalability and performance capabilities |
10. What exactly is the purpose of the CloverETL cluster?
Ans:
The CloverETL cluster aims to provide high availability and scalability for data integration tasks by leveraging multiple nodes. This distributed approach enhances performance by balancing workloads across the cluster, ensuring efficient data processing. It also improves reliability through seamless failover capabilities, minimizing downtime in case of node failures. Load balancing within the cluster optimizes resource utilization and maintains system performance under varying loads.
11. What are the advantages of increasing the number of partitions in an ETL?
Ans:
Increasing the number of partitions in an ETL (Extract, Transform, Load) process can enhance parallelism, allowing faster data processing. It can optimize resource utilization by distributing workload across multiple nodes or threads. Improved scalability enables handling larger datasets efficiently. Enhanced fault tolerance as smaller partitions reduce the impact of failures on the entire process. Lastly, finer-grained partitioning can facilitate better data organization and retrieval.
12. What are the steps followed in the ETL testing process?
Ans:
- Data Extraction: Extract data from various sources like databases, files, or APIs.
- Data Transformation: Convert and manipulate data according to business rules and requirements.
- Data Loading: Load transformed data into the target system, such as a data warehouse.
- Data Validation: Ensure accuracy, completeness, and data consistency through validation checks.
- Error Handling: Identify and rectify any discrepancies or errors encountered during the ETL process.
13. What do ETL Testing operations include?
Ans:
- Verifying data extraction from various sources.
- Ensuring transformation rules are applied accurately.
- Validating data integrity during processing.
- Confirming successful loading into the target system.
It encompasses testing data completeness, correctness, consistency, and performance across the ETL process. ETL testing also involves error handling checks, data quality assessments, and validation of business rules to ensure the reliability and accuracy of data in the target system.
14. What are ETL bugs?
Ans:
ETL (Extract, Transform, Load) bugs refer to issues that arise within the data integration process. These bugs can occur during extraction from the source system, data transformation, or loading it into the target system. Common ETL bugs include data loss, incorrect transformations, and source and target data inconsistencies. Resolving these bugs ensures accurate and reliable data processing and analysis.
15. Differentiate between ETL testing and database testing.
Ans:
ETL testing focuses on validating the extraction, transformation, and loading processes of moving data from source systems to the data warehouse or target database. It ensures data accuracy, completeness, and integrity during this process. On the other hand, database testing primarily verifies the integrity, reliability, and performance of the database itself, including schema validation, data consistency, indexing, and SQL query performance testing.
16. What is the difference between ETL testing and Manual testing?
Ans:
- ETL testing focuses explicitly on verifying data extraction, transformation, and loading processes from source to destination. It ensures data accuracy, completeness, and integrity throughout this process.
- On the other hand, manual testing is a broader term encompassing various testing activities performed manually by testers without using automation tools, including but not limited to ETL testing.
- While ETL testing is a subset of data testing, manual testing can involve various testing types, such as functional, regression, and user acceptance testing across different software applications and systems.
17. What is the staging area in ETL Testing?
Ans:
In ETL testing, the staging area is a temporary storage where data extracted from the source systems is loaded before transformation. It serves as an intermediary step between the extraction and transformation phases. Staging areas help ensure data integrity and provide a space for data cleansing and validation processes. They enable testers to analyze the quality of extracted data before loading it into the data warehouse or target system. Staging areas also facilitate troubleshooting and debugging during the ETL process.
18. How is ETL testing used in third-party data management?
Ans:
- ETL (Extract, Transform, Load) testing is crucial in third-party data management to ensure the accuracy and reliability of data integration processes.
- Third-party data often comes from diverse sources and formats, requiring thorough testing to validate data quality and integrity.
- ETL testing verifies that data extraction, transformation, and loading processes are functioning correctly, minimizing the risk of errors or inconsistencies in the integrated data.
19. What is Regression testing?
Ans:
Regression testing retests software applications or modules to ensure that recent code changes haven’t adversely affected existing features. It verifies that previously developed and tested software still performs correctly after modifications. It aims to catch bugs that may have been introduced due to code changes or system updates. Regression testing is crucial for maintaining software quality and stability throughout the development lifecycle.
20. Explain the data cleaning process.
Ans:
Data cleaning is discovering and removing flaws or inconsistencies in a dataset to enhance its quality and dependability. This process typically includes handling missing or duplicate values, correcting formatting issues, and removing outliers or irrelevant data. Data cleaning ensures the dataset is accurate, complete, and suitable for analysis. It often precedes data analysis or modeling tasks to prevent biases or inaccuracies in results.
21. What are the many ways to update a table using SSIS (SQL Server Integration Service)?
Ans:
- Bulk Insert Task: Allows inserting data from a flat file or another source into a table.
- OLE DB Command Transformation: Enables executing SQL commands for each row in the data flow.
- SQL Server Destination: Utilizes SQL queries or stored procedures to update the destination table.
- Merge Join Transformation: Enables comparing and merging data from multiple sources into a destination table.
22. What are the dynamic and static cache requirements in connected and unconnected transformations?
Ans:
Dynamic cache is used when the data in the cache needs to be refreshed frequently, such as in cases where the source data changes often. Static cache is used when the data in the cache remains constant over time and does not need to be refreshed frequently. In connected transformations, dynamic cache is often used when the transformation requires real-time or near-real-time data updates. Static cache is used when the data does not change frequently and can be preloaded or loaded once during initialization.
23. What is the difference between ETL and SQL?
Ans:
- ETL (Extract, Transform, and Load) is a process that extracts data from numerous sources, converts it to a usable format, and loads it into a data warehouse or database.
- SQL is a language that helps to manage and control relational databases.
- The main difference is that ETL is a process for moving and transforming data, while SQL is a language used to query and manipulate data within a database.
24. What SQL statements may be used to validate data completion
Ans:
- SELECT COUNT(*) FROM table_name: This will return the total number of rows in the table, allowing you to verify if all expected records are present.
- SELECT * FROM table_name WHERE column_name IS NULL: This will return any rows where specific columns are NULL, indicating incomplete data.
- SELECT * FROM table_name WHERE column_name = ”: This will return any rows where specific columns are empty, indicating missing data.
- SELECT * FROM table_name WHERE column_name NOT LIKE ‘%pattern%’: This can be used to find rows where specific columns do not meet a particular pattern or format, indicating potential data completion issues.
25. What exactly are the ETL flaws?
Ans:
ETL (Extract, Transform, Load) flaws commonly include inadequate data validation, leading to errors in data extraction, incomplete or incorrect transformations resulting in inaccurate data, and inefficient processes causing delays in loading data. Additionally, ETL systems may need proper error-handling mechanisms, leading to data loss or corruption. Inadequate scalability can also be a flaw, limiting The system’s capacity to manage rising data volumes successfully.
26. What is ETL partitioning?
Ans:
ETL partitioning refers to dividing data during the Extract, Transform, and Load (ETL) process into smaller, manageable partitions. These divisions can be based on various variables, including time, geographic location, or specific attributes. Partitioning helps optimize data processing by allowing parallelization and efficient retrieval of subsets. It improves performance, scalability, and resource utilization in data warehouses and analytics platforms.
27. What exactly is the ETL Pipeline?
Ans:
- The ETL (Extract, Transform, Load) pipeline is a data integration process used to collect data from numerous sources, translate it into a usable format, and load it into a desired destination, such as a database or data warehouse.
- It involves extracting raw data, applying transformations like cleaning or aggregating, and finally loading it into a storage system for analysis or reporting.
28. What is the Data Pipeline, and how does it work?
Ans:
A Data Pipeline is a system that processes and moves data from one point to another in a structured and automated manner. It usually comprises several steps: data ingestion, transformation, and storage. Data is collected from various sources, processed according to predefined rules or transformations, and delivered to its destination. This process ensures that data is efficiently managed and used for analysis, reporting, or other purposes.
29. Where does the ETL Testing staging take place?
Ans:
- ETL (Extract, Transform, Load) Testing staging typically occurs in a dedicated environment separate from the production environment.
- This staging area is where data extracted from the source systems is temporarily stored and undergoes transformation processes before being loaded into the target destination.
- Staging environments provide a controlled space for testing the ETL processes and ensuring data quality and integrity before deployment to the production environment.
30. Why is ETL Testing Necessary?
Ans:
ETL (Extract, Transform, Load) testing ensures accurate extraction, transformation, and loading of data into the destination system without loss or corruption. It identifies data quality issues, missing or duplicate records, and discrepancies between source and target data. ETL testing also validates data integrity and consistency throughout the process, ensuring reliable and accurate results for business analysis and decision-making.
31. What is an ETL Tester’s job description?
Ans:
An ETL (Extract, Transform, Load) Tester validates the correctness and dependability of data extraction, transformation, and loading procedures. They are responsible for creating and carrying out test scenarios, identifying and reporting defects, and collaborating with developers and stakeholders to resolve issues. They must also validate data integrity and consistency across various systems and databases to ensure smooth data flow.
32. Define ETL (Extract, Transform, and Load) processing.
Ans:
ETL (Extract, Transform, Load) processing is a data integration process in which data is extracted from various sources, transformed to fit operational needs or analytical purposes, and then loaded into the intended destination, such as a data warehouse or database. This process involves extracting data from heterogeneous sources, applying various transformations like cleansing, normalization, and aggregation, and finally loading the transformed data into a suitable storage system for analysis or reporting purposes.
33. Explain the ETL Testing process stages.
Ans:
- Requirement Analysis: Understanding the data sources, transformation rules, and target systems.
- Data Profiling: Assessing the data’s quality, completeness, and consistency.
- Data Validation: Checking whether data is transformed accurately according to business rules.
- Performance Testing: Evaluating the speed and efficiency of the ETL process.
34. What exactly does ETL Testing entail?
Ans:
ETL testing involves verifying data extraction, transformation, and loading processes in data warehouses or lakes. It ensures data completeness, accuracy, and integrity during the transfer across various stages. This testing examines data quality, consistency, and conformity with business requirements. ETL testers validate transformations, mappings, and business rules applied to data.
35. List a few ETL bugs.
Ans:
- Data Loss: Inaccurate transformation logic can lead to data loss during the extraction, transformation, or loading phases.
- Incorrect Data Types: ETL processes may fail to properly convert data types, leading to unexpected errors or inconsistencies.
- Duplicate Records: Improper handling of primary keys or unique constraints can result in duplicate records being loaded into the destination.
- Incomplete Data: ETL jobs may fail to extract or transform all necessary data, leading to incomplete datasets in the target system.
36. What is the definition of fact? What are the different kinds of facts?
Ans:
A fact is a statement that Can be proven true or untrue depending on evidence or observation. Different kinds of facts include empirical facts, which are based on direct observation or experience, such as “the sky is blue”; conceptual facts, which are based on definitions or concepts, like “a square has four equal sides”; and normative facts, which are based on value judgments or social conventions, such as “murder is wrong.”
37. What are OLAP Cubes and Cubes?
Ans:
OLAP (Online Analytical Processing) cubes are multidimensional structures used in data analysis to facilitate complex queries and provide quick access to aggregated data. They organize data into dimensions (such as time, geography, or product) and measures (such as sales or revenue). Users can slice, dice, and pivot the data to gain insights. In this context, Cubes refer to the visual representation of OLAP cubes, often depicted as multidimensional grids or matrices.
38. What are data warehouse software types, and how do data mining and warehousing differ?
Ans:
- Various forms of data warehouse software include traditional relational database management systems (RDBMS) like Oracle, SQL Server, and IBM Db2 and specialized data warehouse solutions like Snowflake, Amazon Redshift, and Google BigQuery.
- Data warehousing focuses on storing and managing large volumes of structured data for reporting and analysis. In contrast, data mining involves discovering patterns and insights from data through algorithms and statistical techniques.
39. What if the sensitive information needs to be stored in the CloveETL server?
Ans:
When storing sensitive information in the CloverETL server, stringent security measures are imperative. This includes encrypting data, implementing access controls, and ensuring compliance with data protection regulations such as GDPR or HIPAA. Regular monitoring and auditing are essential for maintaining data integrity and privacy.
40. What is an ETL cycle’s three-layer architecture?
Ans:
- Extraction Layer: This Layer retrieves data from numerous sources, including databases, files, APIs, and streams.
- Transformation Layer: Data extracted undergoes transformation processes such as cleaning, filtering, joining, aggregating, or enriching to prepare it for analysis or storage.
- Loading Layer: Transformed data is loaded into the target destination, a data warehouse, data lake, or another storage system, ready for querying or further processing.

Get JOB CloverETL Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What is Business Intelligence (BI)?
Ans:
Company intelligence (BI) refers to the technology, processes, and tools that evaluate and present company data to aid decision-making. It entails gathering, storing, and analyzing data from numerous sources to get insight into an organization’s performance and trends. BI helps businesses make data-driven choices, increase operational efficiency, and gain a competitive market edge. It combines data visualization, reporting, and advanced analytics to turn raw data into useful information for stakeholders.
42. What ETL tools are currently available on the market?
Ans:
- Informatica PowerCenter: A widely-used enterprise ETL tool known for its robust capabilities and scalability.
- Talend: A versatile ETL tool with open-source and commercial versions, offering features like data integration, data quality, and big data processing.
- Apache Spark: While primarily known as an extensive data processing framework, Spark also offers ETL capabilities through Spark SQL and DataFrame APIs.
43. When does the staging area come into play in the ETL process?
Ans:
The staging area typically plays after extraction and before loading in the ETL process. It serves as an intermediate storage location where raw data from various sources is temporarily held. Data can be cleaned, transformed, and standardized in this stage before being loaded into the target destination. The staging area facilitates data validation, consolidation, and integration, ensuring data quality and consistency before final deployment.
44. What is a Data Mart, exactly?
Ans:
A Data Mart is a subset of a data warehouse, focusing on an organization’s particular area or department. It stores a condensed, subject-specific data collection for analysis, reporting, and decision-making purposes. Data Marts are intended to fulfill the demands of a particular user group., making data access and analysis more efficient and tailored to their requirements.
45. What exactly is the purpose of ETL testing?
Ans:
ETL (Extract, Transform, Load) testing aims to ensure that data is accurately extracted from the source, transformed correctly according to business rules and requirements, and loaded into the target system without loss or corruption. It validates the integrity of the entire ETL process, identifying any discrepancies or errors in data migration. ETL testing helps guarantee data quality, consistency, and reliability for decision-making and reporting purposes.
46. How is ETL used in data warehousing?
Ans:
- In data warehousing, ETL (Extract, Transform, Load) integrates data collected from many sources and stores it in a single data warehouse.
- Extraction involves retrieving data from various systems or databases. Transformation involves cleaning, formatting, and restructuring the data to fit the warehouse schema.
- Loading is adding converted data into data warehouse tables for analysis and reporting.
47. What is ETL Testing?
Ans:
ETL testing, short for Extract, Transform, and Load testing, is a process used to validate data migration’s correctness, completeness, and performance. It involves verifying data extraction from source systems, ensuring accurate transformation according to business rules, and validating loading into the target database or data warehouse. ETL testing ensures data integrity, consistency, and reliability throughout the ETL process.
48. Which tool is used for ETL Testing?
Ans:
- One commonly used tool for ETL (Extract, Transform, Load) testing is Informatica PowerCenter. It provides features for data extraction, transformation, loading processes, and testing capabilities.
- Another popular tool is Talend Data Integration, offering ETL testing functionalities through a user-friendly interface. Informatica Data Validation Option (DVO) is also utilized for ETL testing, specifically on data validation tasks.
49. How is ETL Testing done?
Ans:
ETL (Extract, Transform, Load) testing involves verifying data extraction, transformation, and loading processes. It typically includes data validation, ensuring accurate transformation and loading, and verifying data integrity. Testers use SQL queries, scripts, and tools to compare source and target data and check for completeness, accuracy, and consistency. ETL testing may involve both automated and manual testing methods to assure the excellence of the ETL process.
50. What is data validation in ETL Testing?
Ans:
Data validation in ETL (Extract, Transform, Load) testing involves ensuring data accuracy, completeness, and consistency during the ETL process. It verifies that data is correctly extracted from the source, transformed according to business rules, and loaded into the target system without loss or corruption. This process involves checking for data integrity, adherence to constraints, and consistency with predefined regulations and standards.
51. What is ETL SQL?
Ans:
- ETL SQL stands for Extract, Transform, Load Structured Query Language. It is a set of SQL queries and scripts to perform data extraction, transformation, and loading tasks in a data warehousing or integration process.
- ETL SQL is used to extract data from various sources, apply transformations to prepare it for analysis or reporting and load it into a target database or data warehouse.
- It involves querying databases, manipulating data, and executing SQL commands to ensure data quality and consistency throughout the ETL process.
52. What is data ETL?
Ans:
- Data ETL is an acronym for Extract, Transform, and Load. It’s a process in data warehousing that transfers data from various sources into a unified destination, such as a data warehouse.
- Extract involves gathering data from databases, files, or applications. Transform involves converting the extracted data into a consistent format or structure, often cleaning, filtering, and standardizing.
- Load involves loading the transformed data. Enter a target database or data warehouse used for analysis and reporting.
53. What is ETL QA?
Ans:
ETL QA stands for Extract, Transform, Load Quality Assurance. It involves testing the processes and systems used to take data from many sources, Transform it to a readable format and put it into a target database or data warehouse. ETL QA ensures data is accurately extracted, transformed, and loaded without loss or corruption. It includes verifying data integrity, consistency, and adherence to business rules throughout the ETL process.
54. What are the ETL Tester’s responsibilities?
Ans:
- ETL (Extract, Transform, Load) Tester responsibilities include designing and executing test cases to ensure accurate and efficient data extraction, transformation, and loading processes.
- They validate data integrity, consistency, and completeness throughout the ETL pipeline, identifying discrepancies or anomalies.
- ETL Testers collaborate with data engineers, and Developers should troubleshoot and address any issues discovered during testing.
55. What are ETL skills?
Ans:
ETL (Extract, Transform, Load) skills refer to gathering data from several sources, converting it to a suitable format, and loading information into a destination database or data warehouse. These skills involve proficiency in data extraction tools, data cleaning and manipulation techniques, and database management. Additionally, knowledge of scripting languages like Python or SQL and understanding data modeling concepts are essential for effective ETL processes.
56. Why is ETL testing required?
Ans:
ETL (Extract, Transform, Load) testing is essential to ensure data integrity, accuracy, and reliability while extracting data from many sources, converting it to match operational needs, and feeding it into the target system. This testing verifies that data is correctly extracted, transformed, and loaded without loss or corruption, maintaining consistency and quality across systems.
57. What is ETL architecture?
Ans:
- ETL (Extract, Transform, Load) architecture refers to the process and framework used to take data from numerous sources, turn it into an analysis-ready format, and feed it into a destination destination, such as a data warehouse or database.
- It typically involves multiple components, including extraction tools, transformation logic, and loading mechanisms. ETL architecture aims to streamline data integration, ensure data quality, and efficiently support analytics and reporting requirements.
58. What are the challenges faced in ETL Testing?
Ans:
Some challenges in ETL (Extract, Transform, Load) testing involve managing enormous amounts of data, guaranteeing data integrity throughout the process, managing complex transformations, validating data accuracy, and maintaining compatibility with various data sources and destinations. Additionally, handling incremental updates, dealing with dependencies between different data elements, and ensuring optimal performance can pose challenges in ETL testing.
59. What is test data in manual testing?
Ans:
Test data in manual testing refers to the input or information used to verify the functionality of a software application or system. It includes various data types, such as valid inputs, invalid inputs, edge cases, and boundary conditions. Test data is designed to cover a wide range of scenarios to ensure thorough system testing. It helps testers identify defects, validate requirements, and provide the software meets quality standards. Test data is often organized into cases and scenarios to facilitate systematic testing.
60. Mention some ETL bugs.
Ans:
- Data loss during extraction or transformation processes.
- Inaccurate data transformation leading to incorrect analysis or reporting.
- Null or missing data must be handled properly, causing downstream errors.
- Data type mismatches cause unexpected behavior or errors.
- Inefficient ETL processes leading to performance issues or timeouts.

Develop Your Skills with CloverETL Certification Training
Weekday / Weekend BatchesSee Batch Details61. Mention some ETL test cases.
Ans:
- Source to Target Data Validation: Verify that data loaded into the target system matches the expected data from the source.
- Data Completeness: Ensure all expected data is loaded into the target system without missing values or records.
- Data Transformation Accuracy: Validate that data transformation rules are applied correctly and accurately during ETL.
- Data Quality Checks: Perform checks for data integrity, consistency, and accuracy to maintain data quality throughout the ETL pipeline.
62. What is the ETL mapping document?
Ans:
The ETL (Extract, Transform, Load) mapping document outlines the data flow from source systems to the target data warehouse. It specifies how data is extracted from source systems, transformed to meet the target schema, and loaded into the destination. This document typically includes source-to-target mappings, data transformation rules, data cleansing procedures, and metadata information.
63. What is a Data Staging Area (DSA)?
Ans:
A Data Staging Area (DSA) is a temporary storage area where data is collected, cleansed, transformed, and prepared for further processing. It is an intermediary between data sources and the target database or data warehouse. DSAs facilitate data integration and ensure data quality before loading it into the final destination. They help streamline the ETL (Extract, Transform, Load) process and improve data consistency and reliability.
64. What is BI?
Ans:
BI stands for Business Intelligence, which refers to technologies, strategies, and practices used to analyze business data and provide actionable insights. It involves collecting, organizing, and interpreting data To assist organizations in making educated decisions, optimizing procedures, and gaining competitive advantages. BI encompasses tools such as data warehouses, dashboards, and reporting software to facilitate data analysis and visualization.
65. What are the differences between ETL tools and BI tools?
Ans:
- ETL (Extract, Transform, Load) tools focus on Data taken from numerous sources, converted into usable prepare and put into a data warehouse or database.
- BI (Business Intelligence) tools, on the other hand, analyze and visualize data to provide insights for decision-making and reporting.
- ETL tools primarily deal with data integration and migration processes, ensuring data quality and consistency.
66. What are the types of Data Warehouse systems?
Ans:
Data warehouses can be categorized into three main types: enterprise (EDWs), operational data stores (ODS), and data marts. EDWs serve as centralized repositories for large volumes of structured data. ODSs provide real-time or near-real-time access to operational data for transactional processing. Data marts are subsets of data warehouses tailored to specific business units or departments for targeted analysis and reporting.
67. What is the difference between OLTP and OLAP?
Ans:
OLTP (Online Transaction Processing) focuses on managing and processing real-time transactional data, optimizing for fast retrieval and transaction processing. OLAP (Online Analytical Processing) is designed for complex queries and data analysis, typically involving historical or aggregated data. OLTP systems are optimized for write operations, while OLAP systems prioritize read-heavy analytical queries.
68. What is the difference between ETL tools and OLAP tools?
Ans:
- ETL (Extract, Transform, Load) tools focus on Data extracted from multiple sources, transformed into usable preparation, and put into a data warehouse or database.
- On the other hand, OLAP (Online Analytical Processing) tools are designed to analyze multidimensional data, allowing users to perform complex queries, slice-and-dice data, and create interactive reports for decision-making.
- While ETL tools handle data integration and preparation, OLAP tools specialize in data analysis and visualization.
69. What are the ETL bugs?
Ans:
- ETL (Extract, Transform, Load) bugs are issues encountered during the data processing stages.
- These bugs can include data loss, incorrect transformations, and inconsistencies in data quality.
- Failure to handle null values properly, inaccurate data mapping, and performance bottlenecks are common ETL bugs.
- If addressed, they can lead to correct reporting, compromised data integrity, and system failures.
70. What is Operation Data Source?
Ans:
Operation Data Source (ODS) refers to an organization’s repository of operational data for reporting and analysis. It typically stores detailed, current, and integrated data from various sources, such as transactional systems. ODS bridges operational systems and data warehouses, providing a real-time or near-real-time snapshot of business operations.
71. How is ETL used in the Data Migration Project?
Ans:
ETL (Extract, Transform, Load) is crucial in data migration projects as it facilitates the movement of data from source systems to target systems. Initially, data is extracted from various sources and then adjusted to meet the target’s demands—system and finally loaded into the new system. ETL ensures data consistency, accuracy, and completeness throughout the migration process, helping to streamline the transition and minimize potential errors or discrepancies.
72. What are the characteristics of a Data Warehouse?
Ans:
- Data warehouses are centralized repositories that integrate data from various sources.
- They are designed for analytical purposes, enabling complex queries and reporting.
- Data warehouses typically undergo an ETL (Extract, Transform, Load) process to clean and structure data.
- They support historical data storage, allowing for trend analysis and decision-making.
73. What is meant by data mart? What is the use of data-mart in ETL?
Ans:
A data mart is a component of a data warehouse that concentrates on a certain business function or department. containing a tailored data set for analysis. In ETL (Extract, Transform, Load), data marts are targets for loading transformed and refined data from various sources. They streamline analysis by providing ready-to-use, pre-aggregated data sets, enhancing decision-making processes within specific business units.
74. What is the three-layer architecture of an ETL cycle?
Ans:
- Extract Layer: Retrieves data from various sources such as databases, files, or APIs.
- Transform Layer: Manipulates and cleanses the extracted data to conform to the desired format, quality, and structure.
- Load Layer: Loads the transformed data into the target destination, typically a data warehouse, database, or another storage system.
75. What is Data purging?
Ans:
Data purging is permanently erasing or removing data from a system or database. It is typically done to free up storage space, enhance system performance, or comply with data retention policies. Purging involves identifying and erasing obsolete, redundant, or sensitive information securely. It helps to reduce the danger of data breaches and ensures compliance with privacy regulations.
76. What are joiner and Lookup?
Ans:
Joiner and Lookup are transformations used in ETL (Extract, Transform, Load) processes within data integration. Joiner is a transformation that joins data from two heterogeneous sources based on a shared key. It merges data from multiple inputs into a single output based on specified conditions. On the other hand, Lookup retrieves data from a relational table or flat file based on a condition. It allows you to look up values in a table based on the specified key and use them to update or enrich your data.
77. What is full load and incremental or refresh load?
Ans:
Full load refers to loading all data from a source system into a target system without considering whether the data has changed. It’s a complete refresh of data. Incremental or Refresh load, however, involves loading only the data that has changed since the last load. It’s a more efficient way of updating data and is typically used for large datasets where loading everything each time would be impractical.
78. What are mapping, Session, Worklet, and Mapplet?
Ans:
- In ETL tools like Informatica, a mapping is a graphical representation of the data flow between sources and targets. It defines the transformation logic that converts the input data into the desired output.
- A session is a task that executes a mapping. It represents the mapping parameters, such as the connection information for source and target systems, and controls how the data is extracted, transformed, and loaded.
- A worklet is a reusable task or set of tasks that can be called within a workflow to perform specific functions.
79. What is the use of dynamic and static cache in transformation?
Ans:
Dynamic cache and static cache are used in transformations in ETL processes to optimize performance and manage data flow. Dynamic cache stores frequently accessed data and changes frequently during runtime, improving query response time by reducing database hits. Static cache, on the other hand, stores data that remains constant throughout the transformation process, lessening the need to fetch the same data repeatedly.
80. What is the transformation in ETL Testing?
Ans:
- In ETL (Extract, Transform, Load) testing, the transformation phase involves verifying that data is correctly transformed according to business rules and requirements.
- This includes validating data accuracy, completeness, consistency, and conformity to standards during the transformation process. Transformation testing ensures data is adequately manipulated, cleansed, and aggregated as intended before loading it into the target system.
81. What is an ETL mapping sheet? Define its significance.
Ans:
An ETL mapping sheet is a document that outlines the detailed mapping between source and target data elements, including transformation rules, data types, and any business logic applied during the ETL process. It serves as a blueprint for ETL developers, testers, and stakeholders, ensuring alignment between source and target systems. The significance of an ETL mapping sheet lies in its ability to facilitate clear communication, documentation, and validation of the ETL process, thereby ensuring accurate and consistent data integration.
82. What is the staging place in the ETL Testing?
Ans:
The staging area in ETL Testing is a temporary storage location where data from source systems is first loaded before undergoing transformations and being loaded into the target system. It acts as an intermediate step in the ETL process, allowing for data cleansing, validation, and manipulation without affecting the operational systems. The staging area helps ensure data integrity and quality by providing a controlled environment for data processing before it is moved to the final destination.
83. What is partitioning in ETL?
Ans:
Partitioning in ETL involves breaking down large datasets into smaller, more manageable subsets based on parameters such as date ranges, geographical regions, or other relevant factors. This approach helps distribute the workload across multiple processing resources, enhancing efficiency. Partitioning accelerates data handling and reduces the strain on individual resources by optimizing data processing and querying.
84. What is the Data Pipeline?
Ans:
The Data Pipeline is a systematic approach to moving data from one location to another, often involving various stages such as extraction, transformation, and loading (ETL). It facilitates the flow of data between systems or components efficiently and reliably.
A data pipeline example could involve:
- Extracting data from various sources.
- Transforming it to a usable format.
- Loading it into a database for analysis.
85. What is ETL Pipeline?
Ans:
- An ETL Pipeline is a particular form of data pipeline focused on Extracting data from a source, Transforming it into a desired format or structure, and Loading it into a target destination such as a data warehouse or database.
- ETL Pipelines are commonly used in data integration and analytics processes. An ETL analytics platform, ensuring consistent and reliable data flow.
- This process helps streamline data integration, enhance quality, and support informed organizational decision-making.
86. What is the data extraction phase in ETL?
Ans:
The data extraction phase in ETL involves retrieving data from one or more sources, such as databases, files, APIs, or streams. This process typically includes identifying the relevant data to be extracted, establishing connections to the source systems, and retrieving the data while adhering to predefined criteria or filters. Data extraction is the initial step in the ETL process and is crucial for obtaining raw data for further processing and analysis.
87. Explain the different layers in ETL systems.
Ans:
- Extraction Layer: Extracts data from various sources like databases, files, or streams.
- Transformation Layer: Transforms extracted data into a usable format, including cleaning, filtering, and structuring.
- Loading Layer: Loads transformed data into the target destination, such as a data warehouse or database.
88. What are the different types of fact tables?
Ans:
- Transactional Fact Tables: Record individual business transactions.
- Periodic Snapshot Fact Tables: Capture data at specific intervals, like daily, weekly, or monthly snapshots.
- Accumulating Snapshot Fact Tables: Track changes to a process or event over time.
89. What are cubes? Explain with example
Ans:
Cubes are multidimensional data structures used in OLAP (Online Analytical Processing) to manage and analyze complex datasets. They let consumers examine data from multiple perspectives, such as by time, location, or product category. For instance, a sales cube might organize information by year, region, and product type, enabling users to analyze trends across these dimensions quickly. This structure enhances the efficiency of querying and reporting, facilitating the extraction of insights from extensive data sets.
90. What are the different types of data models used in the ETL process?
Ans:
- Star Schema: Consists of a central fact table connected to numerous dimension tables in a star-shaped structure.
- Snowflake Schema: Similar to a star schema but with normalized dimension tables, leading to more efficient storage but potentially slower query performance.
- Galaxy Schema: A combination of multiple star schemas sharing standard dimensions, providing flexibility for complex analytical needs.




