
Last updated on 03rd Jul 2020| 6661
DataStage, developed by IBM and part of the IBM InfoSphere Information Server suite, is an enterprise-level ETL (Extract, Transform, Load) tool used for data integration, data warehousing, and business intelligence. It enables businesses to harvest data from a variety of sources, alter it to fulfill specific business requirements, and load it into destination systems such as data warehouses or databases. DataStage is renowned for its strong data transformation capabilities, scalability, and support for parallel processing, making it appropriate for managing massive amounts of data.
1. What is the definition of Datastage?
Ans:
Datastage is a data integration software tool developed by IBM. It is created with the intention of extracting, transforming, and loading (ETL) data from diverse sources into a data warehouse or other target systems. Datastage provides a graphical interface for designing and managing ETL processes, making it easier for organizations to integrate and analyze their data.
2. What is the Enterprise Edition (EE) or parallel DataStage Extender?
Ans:
The Enterprise Edition (EE) or parallel DataStage Extender refers to a version of IBM DataStage that is designed for high-performance data integration and ETL (Extract, Transform, Load) processes. This edition is particularly suitable for large-scale data integration projects, as it can handle large volumes of data and take advantage of parallel processing capabilities to optimize data workflows.
3. How do you use the command line to run the DataStage job?
Ans:
- Open a terminal or command prompt.
- Use the ‘dsjob’ command: dsjob -run -server
-jobstatus [options] - Replace placeholders with your server, project, job, and options.
- Execute the command to start the job.
To run a DataStage job from the command line:
4. What in DataStage is a conductor node?
Ans:
In DataStage, a conductor node refers to a specific type of processing node within a DataStage job. The conductor node acts as the central coordinator for the execution of parallel job stages. It doesn’t perform any data transformation or processing itself but instead manages and directs the flow of data and processing across other parallel stages in the job.
5. What are the distinctions between a sequential file, a dataset, and a fileset?
Ans:
Sequential File: A sequential file is a basic, linear storage format in DataStage, suitable for storing simple, unstructured data.
Dataset: A dataset is a data abstraction that defines data structure and metadata separately, aiding data transformation.
Fileset: A fileset, a type of dataset, optimizes parallel processing by partitioning data for efficient handling in DataStage parallel jobs.
6. What are various options available when using the “dsjob” command?
Ans:
- -run: Starts job execution.
- -server
: Specifies the DataStage server. - -jobstatus
: Checks job status. - -loglevel
: Sets logging level. - -wait: Waits for job completion.
7. How does Kafka Connector work?
Ans:
A Kafka Connector is a software component that facilitates seamless data integration between Apache Kafka, a distributed streaming platform, and other data systems. It works by leveraging Kafka’s producer and consumer APIs to connect to data sources and sinks.
8. What functions does DataStage Flow Designer have?
Ans:
DataStage Flow Designer offers a user-friendly interface for ETL job design, data transformation, and integration with various sources and destinations. It also supports job orchestration, debugging, and real-time monitoring, making it a versatile tool for managing data integration workflows efficiently.
9. Why is Flow Designer advantageous?
Ans:
- User-friendly interface.
- Efficient ETL job development.
- Collaboration support.
- Scalability for various project sizes.
- Seamless integration.
Flow Designer provides several advantages for data integration and ETL processes:
10. Describe an HBase connection.
Ans:
An HBase connection is a configuration setup that enables interaction between a data integration tool like IBM DataStage and Apache HBase, a distributed NoSQL database. It involves specifying connection parameters like HBase host, port, and credentials.
11. Mention the DataStage features.
Ans:
ETL Expertise: Proficient in ETL tasks for data integration and transformation.
Parallel Efficiency: Utilizes parallel processing for speedy handling of large data volumes.
User-Friendly Interface: Offers a drag-and-drop interface for easy job development.
Data Quality: Focuses on enhancing data accuracy and consistency during integration.
Versatile Connectivity: Seamlessly connects to diverse data sources, simplifying integration.
12. Describe IBM DataStage.
Ans:
IBM DataStage is a powerful data integration and ETL (Extract, Transform, Load) software platform. It is designed to efficiently extract data from various sources, transform it according to business rules, and load it into target systems such as databases and data warehouses.
13. How is a source file for DataStage filled?
Ans:
To fill a source file in DataStage, you begin by configuring a source stage within a DataStage job, specifying the source file’s location and format. Data is extracted from this source file using the configured stage. Optionally, you can apply transformations to the extracted data. Subsequently, DataStage loads the transformed data into a target destination, such as a database or another file, ensuring a structured and efficient ETL (Extract, Transform, Load) process.
14. How does DataStage handle merging?
Ans:
Join Stages: DataStage merges data using various join types.
Sorting: Data sorting enhances merging efficiency.
Aggregation: Aggregation stages consolidate data through grouping and functions.
Custom Transformation: Ensures data meets specific standards before merging.
Merging Techniques: Supports flexible merging approaches.
Error Handling: Manages data inconsistencies during merging.
15. How are DataStage and Informatica different?
Ans:
DataStage, developed by IBM, is renowned for its scalability and parallel processing capabilities, making it a preferred choice for enterprises dealing with large data volumes.
In contrast, Informatica offers a broader suite of data management solutions, including ETL, data quality, governance, and cloud integration, with a strong focus on user-friendliness and flexibility.
16. What in DataStage is a routine?
Ans:
In DataStage, a routine refers to a custom code or script written in a supported programming language, such as Java, Python, or Perl, that is used to perform specific data transformation or manipulation tasks within an ETL (Extract, Transform, Load) job. Routines are typically used when standard DataStage functions and stages cannot achieve the desired data processing or when complex calculations or custom logic is required.
17. What steps are involved in eliminating duplicates in DataStage?
Ans:
Data Extraction: Extract the source data containing duplicates.
Data Sorting: Arrange the data based on uniqueness criteria using a “Sort” stage.
Duplicate Detection: Identify and flag duplicates using a “Remove Duplicates” stage.
Aggregation (Optional): Consolidate duplicate records or perform aggregation if necessary.
Data Transformation: Perform any required data transformations.
18. What distinguishes the join, merge from one another?
Ans:
| Aspect | Join | Merge | |
| Purpose |
Combines related tables |
Appends or stacks datasets | |
| Input Data | Related tables | Multiple datasets | |
| Resulting Dataset | Combined columns | Maintains original structure | |
| Data Relationships |
Establishes relationships |
No explicit relationships |
19. What exactly are data and descriptor files?
Ans:
Data Files:
Data files, often referred to as data sets or data containers, are files or entities that store actual data. They contain the information that you want to process, transform, or load within a DataStage job.
Descriptor Files:
Descriptor files, on the other hand, are metadata files that provide essential information about data files. They describe the structure, format, and characteristics of the associated data files.
20. What is the DataStage quality state?
Ans:
The DataStage QualityStage is a module within IBM DataStage dedicated to data quality management. It serves as a comprehensive solution for improving data accuracy and consistency. QualityStage offers features like data profiling, cleansing, standardization, and data matching to identify and rectify data quality issues.
21. What does DataStage’s job control mean?
Ans:
DataStage’s job control refers to the suite of features and tools within IBM DataStage that allow users to manage and control the execution of ETL (Extract, Transform, Load) jobs. This includes functions like job scheduling, job monitoring, and workflow orchestration. Users can define job dependencies, set execution schedules, handle error handling, and receive notifications.
22. How can I optimize the performance of DataStage jobs?
Ans:
To optimize the performance of DataStage jobs:
Parallel Processing: Leverage parallelism for faster execution.
Data Partitioning: Divide data efficiently for parallel tasks.
Smart Joins: Use appropriate joins and reduce unnecessary ones.
Early Filtering: Apply filters at the beginning to reduce data volume.
Simplified Design: Keep jobs simple and use reusable components.
23. What does DataStage’s repository table mean?
Ans:
In DataStage, the repository table refers to a critical component of the DataStage repository database. It serves as a central storage location for metadata related to DataStage projects, jobs, stages, and job designs.
This table stores vital information about job configurations, dependencies, transformations, and lineage, allowing users to manage, track, and version their ETL (Extract, Transform, Load) projects effectively.
24. Describe DataStage’s data type conversion functionality.
Ans:
IBM DataStage provides robust data type conversion functionality that enables seamless transformation of data between different formats and structural elements. It supports a variety of data types, like numeric, string, date, and binary types. DataStage offers built-in functions and operators to facilitate efficient conversion operations, ensuring data integrity and accuracy throughout the ETL process.
25. What is the purpose of DataStage’s exception activity?
Ans:
Error Management: DataStage’s exception activity handles data errors and maintains data quality.
Custom Actions: Users define rules for handling exceptional data.
Reliability: Enhances the reliability of data integration.
Compliance: Supports data quality and governance requirements, especially in regulated industries.
26. What are the Flow Designer’s primary characteristics?
Ans:
Flow Designer is a pivotal tool in IBM DataStage, known for its primary features. It offers a user-friendly, visual interface for ETL processes, simplifying development with drag-and-drop actions. It encourages reusability, streamlines data transformation, and facilitates efficient workflow management.
27. What other kinds of lookups can DataStage support?
Ans:
- Sequential File Lookup
- Merge Lookup
- Join Lookup
- Database Lookup
- Sparse Lookup
- In-Database Lookup
28. What does DataStage’s use analysis entail?
Ans:
DataStage’s “use analysis” refers to a process or feature within the DataStage ETL (Extract, Transform, Load) toolset that helps users analyze and understand how data is utilized within their data integration and transformation processes. It involves examining and documenting how different data elements or fields are accessed, transformed, and loaded within DataStage jobs.
29. What distinguishes a hash file from a sequential file?
Ans:
Hash File: Organizes data using a hashing algorithm, enabling rapid, direct access based on unique keys. Ideal for quick lookups and queries, often used in databases and caches.
Sequential File: Stores data in a linear, sequential fashion, requiring sequential reading for data retrieval. Commonly used for logs and flat files, best suited for tasks with a strictly sequential data processing flow.
30. How should a DataStage repository be cleaned?
Ans:
Back up Data: Start by creating a backup of the repository to prevent data loss.
Remove Unused Objects: Identify and delete unused objects like jobs, parameters, and resources to declutter.
Clean Log Files: Clear old log files to free up storage space.
Update Metadata: Ensure metadata is accurate and consistent.
Regular Maintenance: Establish a routine for ongoing repository maintenance to maintain efficiency.

Enroll in Datastage Training to Build Skills & Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
31. In DataStage, how do we call a routine?
Ans:
Start by adding a “Transformer” stage to your DataStage job canvas. Inside the “Transformer” stage’s “Derivations” tab, you can invoke your custom routine using the “Routine” function. Specify the routine’s name and any required parameters. Ensure proper column mapping to control data flow for your specific ETL (Extract, Transform, Load) operations. This approach allows you to seamlessly integrate custom logic within your DataStage job for efficient data processing.
32. What does NLS in DataStage stand for?
Ans:
In DataStage, NLS stands for “National Language Support.” National Language Support encompasses a set of features and functionalities that enable DataStage to work seamlessly with multiple languages, character sets, and regional settings. It ensures that DataStage can process and transform data in various languages and character encodings, making it a versatile and globally applicable ETL (Extract, Transform, Load) tool.
33. Differentiate between symmetric multiprocessing and huge parallel processing.
Ans:
| Aspect | SMP | MPP |
| Architecture |
Shared memory and bus |
Distributed nodes with local memory |
| Resource Sharing | Shared memory and resources | Dedicated memory per node |
| Scalability | Limited to a smaller number of cores | Highly scalable, can span thousands of nodes |
| Programming Challenges |
Fewer challenges |
More challenging due to distributed data handling |
34. What exactly is a Hive connector?
Ans:
A Hive connector is a software component that facilitates communication and data exchange between a data processing framework like Apache Hive and external data sources or storage systems.
It enables Hive, a data warehousing and SQL-like query tool in the Hadoop ecosystem, to access, ingest, and query data from various data stores, such as HDFS (Hadoop Distributed File System), HBase, or external databases.
35. What are the main components of Datastage?
Ans:
Designer: Where ETL jobs are built.
Director: Manages job execution.
Administrator: Handles system configuration.
Manager: Central job and project management.
Repository: Stores metadata and job definitions.
36. What is the definition of parallel processing design?
Ans:
Parallel processing design is a computing approach that divides complex tasks into smaller, independent subtasks that are concurrently executable by several processors, or computing units. It aims to improve efficiency and reduce processing time by harnessing the power of parallelism, where tasks are performed concurrently rather than sequentially.
37. What are the different kinds of parallel processing?
Ans:
- Task Parallelism.
- Data Parallelism.
- Bit-Level Parallelism.
- Instruction-Level Parallelism (ILP).
- Pipeline Parallelism.
38. What are the Datastage stages?
Ans:
DataStage offers a variety of stages for ETL processes, including Source Stages (data extraction), Transformation Stages (data manipulation), Processing Stages (custom logic), Target Stages (data loading), Debugging Stages (troubleshooting), Monitoring Stages (logging), Utility Stages (auxiliary tasks), and Custom Stages for specialized functions. These stages provide the foundation for building data integration jobs in DataStage.
39. What are the benefits of employing modular development at the data stage?
Ans:
Reusability: Promotes component reuse.
Scalability: Easily accommodates growth.
Efficient Maintenance: Streamlines updates.
Collaboration: Enhances teamwork.
Testing: Simplifies quality assurance.
Version Control: Facilitates change management.
40. Describe Data pipelining.
Ans:
Data pipelining is a fundamental concept in data engineering, involving the automated flow of data through a series of processing stages. It’s a sequential process where data moves from source to destination, undergoing transformations and manipulations along the way. Data pipelines are modular, scalable, and designed for automation, reducing manual effort.
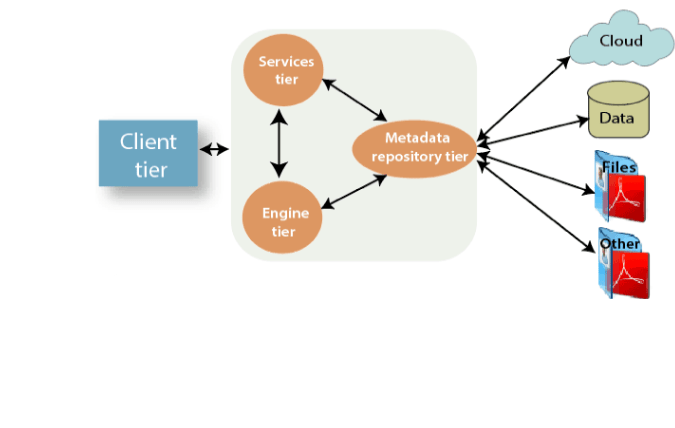
41. What are the various Tiers of the InfoSphere Information Server?
Ans:
- Client Tier.
- Services Tier.
- Engine Tier.
- Metadata Repository Tier.
- Resource Tier.
- External Services Tier.
42. What does Infosphere Information Server stand for?
Ans:
IBM InfoSphere Information Server, commonly known as InfoSphere Information Server, is an all-encompassing data integration platform developed by IBM.
It provides a set of tools and services for designing, building, and managing data integration, data quality, and data governance solutions.
43. What do operators perform in Datastage?
Ans:
In DataStage, operators are essential components that manage data movement, transformation, error handling, and control logic in ETL processes. They guarantee that data flows smoothly from source to destination, that appropriate transformations are performed, that mistakes are handled graciously, and that set criteria for effective data processing are followed.
44. What are the advantages of DataStage’s parallel processing support?
Ans:
- Performance Boost.
- Scalability.
- Resource Efficiency.
- Flexibility.
- Real-time Capabilities.
45. What is the primary purpose of DataStage in the context of data integration?
Ans:
The primary purpose of DataStage in the context of data integration is to enable organizations to efficiently extract, transform, and load (ETL) data from diverse sources into a unified format that is suitable for analysis, reporting, and decision-making.
46. Explain the difference between DataStage Server and DataStage Parallel Edition.
Ans:
DataStage Server, often referred to as “Server Edition,” is designed for single-server deployments. It typically runs on a single machine and is suitable for smaller-scale data integration projects.
On the other hand, DataStage Parallel Edition, also known as “PX,” is engineered for high-performance and scalability. It is designed to harness the power of parallel processing, allowing data integration jobs to be divided into multiple parallel tasks that can execute simultaneously on multiple processing nodes.
47. What is the DataStage Director, and what role does it play in job execution?
Ans:
The DataStage Director is a critical component of IBM DataStage responsible for job execution management. It offers functions for scheduling, monitoring, error handling, and recovery of ETL jobs. This user-friendly interface enhances job visibility and facilitates efficient job execution and troubleshooting.
48. Can you describe the use of DataStage Designer?
Ans:
DataStage Designer is a key component of IBM DataStage used for ETL (Extract, Transform, Load) job design. It offers a visual interface to define data sources, transformations, and destinations, simplifying the creation, validation, and testing of ETL processes.
49. What is a DataStage job sequence, and when is it useful in ETL workflows?
Ans:
A DataStage job sequence is a construct within IBM DataStage that allows you to orchestrate the execution of multiple DataStage jobs in a predefined order.
A DataStage job sequence is especially useful in ETL workflows when there’s a need to manage the execution of multiple jobs in a specific order or based on certain conditions.
50. How do you handle data errors and exceptions in DataStage?
Ans:
Error Logging: Set up robust error logging to capture and document errors.
Reject Handling: Direct erroneous data to reject files for further examination.
Alerts: Configure alerts and notifications for critical errors.
Conditional Logic: Use conditional logic to handle errors based on severity.
Retry Mechanisms: Implement retries for transient errors to minimize failures.

Learn Datastage Certification Course and Get Hired by TOP MNCs
Weekday / Weekend BatchesSee Batch Details51. What are Lookup stages in DataStage, and why are they important?
Ans:
Lookup stages in DataStage are critical components used for data enrichment and reference data retrieval during ETL (Extract, Transform, Load) processes.
Lookup stages play a vital role in data integration by enriching, validating, and enhancing data quality, ultimately contributing to the reliability and usefulness of the processed data in various business applications.
52. Explain the concept of Data parallelism in DataStage.
Ans:
Data parallelism in DataStage involves dividing data processing tasks into smaller, parallel tasks that can be executed simultaneously on multiple processing nodes or partitions. This concept optimizes performance and scalability by distributing the workload, allowing for faster data integration and transformation.
53. What is a shared container in DataStage, and how can it be beneficial?
Ans:
A shared container in DataStage is a reusable and encapsulated collection of job components, including stages, links, and transformations.
They enable the creation of standardized, modular components that can be efficiently utilized across multiple jobs, reducing development effort and ensuring consistency in data integration processes.
54. Describe the steps involved in creating a DataStage job.
Ans:
Design: Use DataStage Designer to create the job.
Stages: Add and configure stages.
Data Flow: Create links for data movement.
Execution: Run and monitor the job.
Optimization: Enhance job performance.
55. What are the DataStage Transformer stages?
Ans:
DataStage Transformer stages are key components in IBM DataStage used for data transformation within ETL (Extract, Transform, Load) processes. These stages allow developers to perform various data manipulations, including data cleansing, enrichment, aggregation, and conversion. Transformer stages are highly flexible and versatile, providing a visual interface for defining complex data transformations using a range of functions, expressions, and conditional logic.
56. Explain the concept of DataStage job partitioning.
Ans:
DataStage job partitioning is a concept that plays a crucial role in raising the standard and scalability of ETL (Extract, Transform, Load) processes within IBM DataStage.
It involves the division of a DataStage job into smaller, parallel tasks or partitions that can be executed simultaneously on multiple processing nodes or servers.
57. How DataStage Shared Containers simplify ETL development?
Ans:
DataStage Shared Containers simplify ETL development by allowing developers to encapsulate and reuse common ETL components, reducing redundancy and ensuring consistency. They streamline maintenance by propagating updates across all jobs using the container. Shared Containers promote collaboration and standardization, enhancing the overall efficiency of data integration workflows.
58. Can you differentiate between DataStage Designer and DataStage Administrator?
Ans:
DataStage Designer is primarily a development tool used by ETL developers and designers. It provides a visual interface for creating, designing, and configuring ETL jobs.
DataStage Administrator, on the other hand, is an administrative tool designed for system administrators and operators. Its main function is to manage the DataStage environment.
59. What are the advantages of using DataStage Director’s job scheduling capabilities?
Ans:
Using DataStage Director’s job scheduling capabilities offers these advantages:
Automation: Enables automated execution, reducing manual work and errors.
Timeliness: Ensures jobs run at preferred times for data freshness.
Resource Efficiency: Optimizes resource usage during off-peak hours.
Dependency Control: Manages job dependencies and ensures proper sequence.
Monitoring: Provides real-time monitoring and alerts for job status.
60. How does DataStage handle data consistency and data quality issues in ETL processes?
Ans:
DataStage addresses data consistency and quality in ETL through data cleansing, validation rules, error handling, and transformation logic.
It identifies and corrects inconsistencies, validates data, handles errors, and standardizes data, ensuring reliable and consistent data throughout the ETL process.
61. Describe the role of DataStage Sequencer in job control and sequencing.
Ans:
The DataStage Sequencer plays a vital role in job control and sequencing within IBM DataStage. It enables the orchestration of multiple jobs, defining their order of execution, and handling job dependencies. With support for conditional execution, looping, and error handling, the Sequencer provides robust control flow mechanisms.
62. What is the significance of metadata in DataStage?
Ans:
Metadata in DataStage is vital for data integration and management. It provides critical information about data, including its structure and lineage, aiding in understanding and governance.
Metadata also streamlines ETL development by offering documentation and enabling automation, ensuring data quality and efficiency. Overall, metadata is the backbone of effective data integration in DataStage.
63. How does DataStage support parallel processing?
Ans:
DataStage supports parallel processing through its Parallel Edition, which enables the simultaneous execution of data transformations, data partitioning, and job parallelism. This parallelism enhances data processing speed, resource utilization, and scalability, making DataStage efficient for handling large-scale ETL tasks. It leverages multi-node environments to distribute data and processing tasks intelligently, optimizing performance.
64. Can you explain the use of DataStage Balanced Optimization?
Ans:
DataStage Balanced Optimization is a feature that aims to optimize ETL job performance by ensuring a balance between data and processing parallelism.
It analyzes the data flow and processing stages in a job to determine the optimal degree of parallelism for each, preventing resource bottlenecks.
65. What is a DataStage parameter set, and when is it used in job design?
Ans:
A DataStage parameter set is a collection of user-defined parameters that can be used to make job designs more flexible and adaptable. It enables you to specify and maintain parameter values independently of task designs, making it simpler to modify job behavior for various circumstances or scenarios.
66. How can you optimize the performance of DataStage jobs when dealing with large datasets?
Ans:
Leverage Parallel Processing: Utilize parallelism to distribute work.
Use Data Compression: Reduce data volume with compression.
Implement Indexing: Create indexes for faster data access.
Filter Data Early: Remove irrelevant data early in the process.
Partition Data: Divide data into smaller subsets.
Manage Memory: Allocate adequate memory for operations.
67. Describe the purpose of DataStage Surrogate Key Generator stage.
Ans:
The DataStage Surrogate Key Generator stage serves the purpose of generating unique surrogate keys for data records in a Data Warehouse or ETL (Extract, Transform, Load) process. These surrogate keys are typically integer values assigned to each record to maintain referential integrity and simplify data tracking and management.
68. What are the different types of DataStage job logs?
Ans:
- Job Log
- Director Log
- Error Log
- Warning Log
- Reject Log
- Orchestra Log
- Execution Log
69. Explain the concept of data lineage in DataStage and why it’s important.
Ans:
Data lineage in DataStage refers to the ability to track and visualize the journey of data from its source to its various transformations and ultimately to its destination. Data lineage supports impact analysis, aids in issue resolution, and serves as valuable documentation for workflows.
70. How can you efficiently handle incremental data loads in DataStage?
Ans:
- Use Change Data Capture (CDC) methods.
- Utilize date or timestamp columns for filtering.
- Maintain surrogate keys for record identification.
- Employ database triggers for automated tracking.
- Set job parameters for dynamic date selection.
To efficiently handle incremental data loads in DataStage:
71. What is a DataStage Connector stage?
Ans:
A DataStage Connector stage is a specialized component within IBM InfoSphere DataStage designed for seamless integration with external data sources or destinations. It acts as a bridge, enabling DataStage to connect, extract, or load data from non-standard or proprietary data platforms, such as databases, cloud services, or legacy systems.
72. Can you differentiate between DataStage PX (Parallel Extender) and Server Edition?
Ans:
DataStage PX (Parallel Extender) is a high-performance and scalable version of IBM InfoSphere DataStage. It is designed to handle large-scale data integration tasks and processes.
Server Edition, on the other hand, is an earlier version of DataStage that lacks the advanced parallel processing capabilities of DataStage PX. It operates on a single node and is typically employed for smaller to medium-sized data integration projects.
73. How do you secure sensitive data within DataStage during ETL processes?
Ans:
Securing sensitive data in DataStage during ETL processes involves encryption for data in transit and at rest, strict access controls, and role-based permissions. Implement data masking techniques to hide sensitive information, maintain audit trails for monitoring, and ensure compliance with data privacy regulations. Regular staff training and vulnerability assessments further strengthen data security within DataStage.
74. What is the role of DataStage QualityStage in data cleansing?
Ans:
DataStage QualityStage plays a pivotal role in data cleansing by providing comprehensive data quality and data cleansing capabilities within the IBM DataStage ecosystem.
It serves as a powerful tool for improving data accuracy, consistency, and reliability during ETL (Extract, Transform, Load) processes.
75. Explain the concept of data encryption in DataStage.
Ans:
Data encryption in DataStage refers to the process of converting plain-text data into a secure, unreadable format known as ciphertext. This encryption is employed to protect sensitive data during various stages of data integration and transfer within the DataStage environment.
76. How do you handle complex transformations involving multiple datasets in DataStage?
Ans:
- Input: Extract data from multiple sources.
- Transform: Apply intricate data manipulations.
- Join: Merge data based on common keys.
- Output: Store transformed data for analysis.
Complex transformations in DataStage are handled through a structured workflow:
77. Describe the role of DataStage Change Capture stage in detecting changes in source data.
Ans:
The DataStage Change Capture stage plays a crucial role in detecting changes in source data. It continuously monitors source data for any modifications, additions, or deletions by comparing the current data with a previously captured snapshot. When changes are detected, it records them as inserts, updates, or deletes, providing a real-time or near-real-time stream of data changes.
78. What are the considerations for optimizing DataStage jobs?
Ans:
Optimizing DataStage jobs involves several key considerations:
Parallel Processing: Utilize parallelism for efficient workload distribution.
Data Partitioning: Minimize data movement by effective data partitioning.
Buffering: Optimize buffer sizes to balance memory and I/O usage.
Pipeline Design: Simplify job design with minimal stages and connections.
Error Handling: Implement robust error handling to ensure data integrity and job reliability.
79. How does DataStage handle metadata propagation between stages in a job?
Ans:
DataStage handles metadata propagation by automatically passing schema information between connected stages in a job. It ensures data consistency and integrity by tracking the data’s structure as it flows, issuing alerts for metadata mismatches, and providing tools for explicit metadata definition when needed.
80. What are the advantages of using DataStage Information Analyzer for data profiling?
Ans:
- Data Quality Assessment
- Data Understanding
- Data Lineage Analysis
- Impact Analysis
- Metadata Management
81. Explain the concept of DataStage job reusability.
Ans:
DataStage job reusability refers to the practice of designing DataStage jobs in a modular and versatile way so that they can be easily reused across different projects or scenarios. This involves creating generic components, such as job templates or shared containers, that encapsulate specific data integration logic, transformations, or data extraction methods.
82. How does DataStage support real-time data integration and streaming data processing?
Ans:
- Change Data Capture (CDC) for monitoring and capturing real-time data changes.
- Streaming Stages for handling high-velocity data streams.
- Parallel processing for high throughput and minimal latency.
- Job Scheduling for automated real-time data processing.
- Integration with Streaming Platforms for leveraging streaming technologies like Kafka, IBM Streams.
DataStage supports real-time data integration and streaming processing through:
83. Can you describe the role of DataStage Shared Metadata?
Ans:
DataStage Shared Metadata ensures consistent, reusable metadata definitions across projects, streamlining job development, supporting data governance, and enhancing data lineage tracking. It simplifies documentation, impact analysis, and resource optimization, fostering efficient and standardized data integration practices.
84. How does DataStage Flow Designer differ from the traditional DataStage Designer?
Ans:
| Aspect | DataStage Flow Designer | Traditional DataStage Designer |
| User Interface |
Web-based, modern interface |
Desktop-based, traditional interface |
| Data Integration and Transformation | Emphasizes visual data integration | Offers visual and code-based options |
| Ease of Use | Low-code/no-code approach | Typically requires advanced ETL skills |
| Collaboration |
Facilitates collaboration and sharing |
Collaboration may require additional tools |
85. Describe the concept of DataStage job parameterization.
Ans:
DataStage job parameterization is the practice of configuring DataStage jobs to accept dynamic inputs or settings at runtime. Instead of hardcoding values, parameters allow users to provide values when executing a job, making it versatile and adaptable for various scenarios. This enables the reuse of jobs with different configurations and simplifies job maintenance and management.
86. How can you efficiently handle schema changes in source data?
Ans:
Schema Evolution: Design adaptable processes.
Metadata Management: Centralize schema tracking.
Parameterization: Enable dynamic schema config.
Error Handling: Capture schema-related issues.
Testing: Ensure data integrity.
Documentation: Record schema changes.
87. What are DataStage Data Sets, and how are they used in job design?
Ans:
DataStage Data Sets are logical representations of data structures used within DataStage jobs. In job design, DataStage Data Sets are used to abstract data structures, simplifying data source management, promoting reusability, and providing metadata for documentation.
88. Explain the role of DataStage Change Apply stage in managing changes in target data.
Ans:
- Detects changes (inserts, updates, deletes) from a source.
- Synchronizes these changes with the target dataset.
- Ensures data quality through validation.
- Logs changes and maintains an audit trail.
- Optimizes performance for efficient processing.
The DataStage Change Apply stage:
89. What is the purpose of DataStage Constraint rules?
Ans:
DataStage Constraint rules serve to enforce data quality and integrity standards within DataStage jobs. They validate, cleanse, enrich, and transform data, ensuring it adheres to predefined rules and policies. These rules contribute to accurate, consistent, and reliable data processing in ETL (Extract, Transform, Load) workflows.
90. How can you monitor the performance of DataStage jobs in real-time?
Ans:
- Use DataStage Director for job status and logs.
- Review logs for errors and statistics.
- Utilize performance monitoring tools.
- Set up alerts and notifications.
- Consider custom scripts or external solutions.
To monitor DataStage job performance in real-time:
91. How do DataStage containers enhance job design and reusability?
Ans:
DataStage containers enhance job design and reusability by organizing reusable components within jobs. They enable modularity by grouping related stages and promoting a modular approach. This improves efficiency, reduces redundancy, and standardizes data integration processes for consistent and faster job development.
92. List the advantages of using DataStage dynamic schemas.
Ans:
- Flexibility
- Reduced Maintenance
- Enhanced Reusability
- Streamlined Development
- Support for Big Data
93. How does DataStage handle complex file formats, such as XML or JSON?
Ans:
DataStage handles complex file formats like XML and JSON by providing specialized stages for parsing and processing, allowing users to define data schemas, perform transformations, and implement data validation. These features enable efficient integration of structured and semi-structured data into ETL processes.
94. What is DataStage ODBC and how is it used for data connectivity?
Ans:
DataStage ODBC (Open Database Connectivity) is a standard interface that allows DataStage to connect and interact with several relational databases and data sources.
It is used for data connectivity by providing a standardized way to establish connections, retrieve data, and perform database operations within DataStage jobs.
95. Explain the role of DataStage Data Rules in data quality assessment.
Ans:
Definition: Data Rules define data quality criteria.
Validation: They validate data against defined criteria.
Cleansing: Data Rules perform data cleansing and standardization.
Error Handling: They generate error records for data quality issues.
Profiling: Data Rules aid in data profiling and anomaly detection.
Reports: They generate data quality reports for insights.
Governance: Data Rules enforce data quality standards and governance.
96. How do you handle incremental data extraction in DataStage ?
Ans:
Handling incremental data extraction in DataStage involves three steps. First, you identify a tracking criterion like a timestamp or unique key. Second, you use job parameters to dynamically configure extraction criteria, ensuring only new or modified data is retrieved during each run. Finally, consider implementing Change Data Capture (CDC) to automate monitoring and extraction of incremental changes.
97. Describe the process of job migration and deployment in DataStage.
Ans:
The job migration and deployment process in DataStage includes exporting jobs from the source environment, transferring them to the target environment, and importing them. Configuration updates, validation, and testing ensure proper functionality, while version control, documentation updates, and a deployment strategy ensure a smooth transition and ongoing management. Monitoring and post-deployment checks verify job performance in the new environment.
98. How does DataStage Job Sequencing enable complex workflow management?
Ans:
DataStage Job Sequencing streamlines complex workflow management by allowing you to define dependencies, use conditional logic, execute tasks in parallel, handle errors, allocate resources efficiently, schedule jobs, monitor progress, and promote reusability. It’s a comprehensive tool for orchestrating intricate ETL workflows.
99. Explain the use of DataStage Pivot and Unpivot stages in data transformation.
Ans:
DataStage Pivot Stage:
The DataStage Pivot stage is used to transform rows into columns. This is helpful when you need to reshape data, such as converting normalized data into cross-tabulations for reporting and analysis.
DataStage Unpivot Stage:
Conversely, the DataStage Unpivot stage transforms columns into rows. It’s useful for converting wide-format data, like spreadsheets, into a more manageable long format for processing and integration.
100. Can you describe the process of handling job failures and recovery in DataStage?
Ans:
Error Detection: DataStage monitors jobs for errors during execution.
Log Analysis: Review detailed job logs to identify the cause of the error.
Error Handling Stages: Use stages like “Row Reject” to manage error-triggering records.
Notifications: Configure alerts for immediate response to failures.
Retry Mechanism: Set retry options to automatically attempt failed stages or jobs.




