Last updated on 03rd Jul 2020| 3057
These puppet Interview Questions have been designed specially to get you acquainted with the nature of questions you may encounter during your interview for the subject of puppet.As per my experience good interviewers hardly plan to ask any particular question during your interview, normally questions start with some basic concept of the subject and later they continue based on further discussion and what you answer.we are going to cover top puppet Interview questions along with their detailed answers. We will be covering puppet scenario based interview questions, puppet interview questions for freshers as well as puppet interview questions and answers for experienced.
1. What is a Puppet?
Ans:
Puppet is an open-source configuration management tool designed to automate the provisioning and management of infrastructure. It allows system administrators to define and enforce the desired state of their infrastructure using code, making it easier to deploy, configure, and maintain servers.
2. Explain the difference between declarative and imperative programming.
Ans:
- Declarative programming focuses on describing what the result should be without specifying the step-by-step procedure.
- In contrast, imperative programming outlines the exact steps or procedures to achieve a particular outcome.
- Puppet uses a declarative approach where users define the desired state of their infrastructure, and Puppet takes care of determining how to achieve that state.
3. How does Puppet help in configuration management?
Ans:
- Puppet helps in configuration management by allowing administrators to define the desired state of their systems in code (manifests).
- Puppet then automatically enforces this desired state on the target systems, ensuring consistency and repeatability and reducing manual configuration efforts.
- It handles tasks such as installing packages, configuring files, managing services, and more.
4. What are the key components of Puppet architecture?
Ans:
The key components of Puppet architecture include:- Puppet Master: The central server that stores configuration information and sends it to the Puppet agents.
- Puppet Agent: The software installed on each node that communicates with the Puppet master and applies the configurations.
- Facter: A system profiling tool that gathers facts (information about the system) that Puppet uses during the catalogue compilation.
- Catalog: A document compiled by the Puppet master containing the desired state for each node.
- Hiera: A tool for separating data from code, allowing the management of configuration data outside of Puppet manifests.
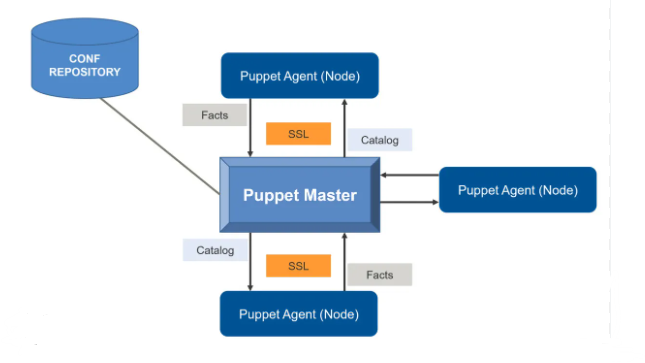
5. Describe the Puppet master-agent architecture.
Ans:
Puppet uses a client-server architecture known as the master-agent architecture. The process involves the following steps:
- The Puppet agent runs on each node and collects facts about the system using Factor.
- The Puppet agent sends these facts to the Puppet master.
- The Puppet master compiles a catalogue based on the desired state defined in Puppet manifests and the received facts.
- The Puppet master sends the catalogue back to the Puppet agent.
- The Puppet agent applies the catalogue, ensuring the node’s configuration matches the desired state.
6. What is the purpose of the Puppet catalogue?
Ans:
- The Puppet catalogue is a compiled set of instructions that defines the desired state of a node’s configuration. It contains information on how resources (such as files, packages, and services) should be managed on a specific node.
- The Puppet master generates the catalogue based on the Puppet manifests and the facts collected from the node. The Puppet agent uses this catalogue to apply the desired configuration and ensure that the system is in the specified state.
7. How do you install Puppet on a Linux system?
Ans:
The installation process may vary based on the Linux distribution. Here are general steps for installing Puppet on a Linux system using a package manager:
On Ubuntu/Debian:- sudo apt-get update
- sudo apt-get install puppet
- Sudo yum install puppet
After installation, you may also need to start and enable the Puppet service:
- sudo systemctl start puppet
- sudo systemctl enable puppet
8. Explain the role of the Puppet controller server.
Ans:
The Puppet controller server is a central component in Puppet’s architecture. Its primary roles include:
- Storing Configuration Data:
- Compiling Catalogues:
- Certificate Authority (CA):
The Puppet master stores configuration information, known as Puppet manifests, which define the desired state of nodes in the infrastructure.
When a Puppet agent requests its configuration, the master compiles a catalog based on the manifests and sends it to the agent.
The Puppet master acts as a certificate authority, verifying and signing certificates for Puppet agents, ensuring secure communication between them.
9. What is the significance of Puppet manifests?
Ans:
- Puppet manifests are files that contain code written in the Puppet language. They define the desired state of the infrastructure, specifying how resources should be configured.
- Manifests consist of resource declarations that describe the properties of various system components, such as files, packages, services, users, and more.
- Puppet agents use manifests to understand and apply the configurations specified by administrators, facilitating automated and consistent system management.
10. Describe the purpose of the Puppet configuration file (puppet. conf).
Ans:
The puppet. conf file is the main configuration file for Puppet. It is used to customise the behaviour of the Puppet agent and master. Key purposes include:
- Specifying Puppet Master: The server configuration option in the puppet.conf file is used to define the Puppet controller server to which the agent should connect.
- Setting Certificate Paths: It contains settings related to SSL certificates, such as the location of the certificate authority (CA) and certificate paths.
- Configuring Module Paths: The modulepath option defines the directories where Puppet looks for modules.
- Defining Node Classification: It may include node-specific configurations and classification information.
- Specifying Puppet Environment: The environment setting allows users to define which Puppet environment the node should use.
11. How do you configure a Puppet agent to connect to a specific Puppet master?
Ans:
To configure a Puppet agent to connect to a specific Puppet master, you need to edit the Puppet. conf file on the agent node. Modify the server setting to specify the hostname or IP address of the Puppet master. For example:
- [main]
- server = puppet-master.example.com
12. What is a Puppet manifest?
Ans:
A Puppet manifest is a file written in the Puppet language that contains code defining the desired state of a system. Manifests consist of resource declarations that specify how various system components (resources) should be configured. These resources include files, packages, services, users, and more. Puppet agents use manifests to understand and apply the configurations defined by administrators.
13. Explain the difference between classes and definitions in Puppet.
Ans:
- Classes: Classes are a way to group related resources. They serve as containers for organising and managing resources in a modular and reusable manner. Classes are defined using the class keyword and can be included in manifests to apply the configurations they contain.
- Defines: Defines are similar to classes but are primarily used for defining and managing instances of a resource type. They allow you to create reusable templates for configuring resources with similar properties. Defines are defined using the define keyword.
14. How do you define a resource in Puppet?
Ans:
Resources in Puppet are defined using a resource declaration syntax. The basic structure is:
- resource_type { ‘resource_name’:
- attribute1 => value1,
- attribute2 => value2,
- # Additional attributes as needed
- }
For example, to define a file resource:
- file { ‘/etc/example.conf’:
- ensure => ‘present,’
- content => ‘This is an example file.’,
- mode => ‘0644’,
- }
15. What is the purpose of the notify resource in Puppet?
Ans:
The notify resource in Puppet is used for producing log messages during the execution of a catalogue. It does not manage any system resource but can be used to print messages to the console or logs. It is often used for debugging or providing information about the progress of a Puppet run.
16. How can you include a class in a Puppet manifest?>
Ans:
To include a class in a Puppet manifest, you use the include keyword followed by the class name. For example:
- include my class
Alternatively, you can use the class resource-like syntax:
- class { ‘myclass’:
- # Class parameters, if any
- }
17. List some common Puppet resource types.
Ans:
Common Puppet resource types include:
- File: Manages files and directories.
- Package: Manages packages.
- Service: Manages services.
- User and group: Manage user accounts and groups.
- Exec: Executes commands.
- Cron: Manages cron jobs.
- Mount: Manages mounted filesystems.
18. Explain the purpose of the file resource type.
Ans:
The file resource type in Puppet is used to manage files and directories on a system. It can ensure that a file or directory exists, define its content, set permissions, manage ownership, and more. The file resource is fundamental for configuring and controlling the state of files across nodes.
19. How do you manage user accounts using Puppet?
Ans:
User accounts in Puppet can be managed using the user resource type. For example:
- user { ‘john_doe’:
- ensure => ‘present’,
- uid => ‘1001’,
- gid => ‘users’,
- home => ‘/home/john_doe’,
- shell => ‘/bin/bash’,
- }
This example ensures that a user named ‘john_doe’ exists with the specified UID, primary group, home directory, and shell.
20. What is the exec resource type, and when would you use it?
Ans:
The exec resource type in Puppet is used to execute commands on a node. It is often used when a specific configuration task cannot be achieved using existing resource types. However, using exec should be minimized in favor of declarative resource types whenever possible. Example:
- Exec { ‘apt-update’:
- command => ‘/usr/bin/apt-get update,’
- refresh only => true,
- }
This example runs the command to update package repositories but only triggers if another resource signals that it needs to refresh.
21. How does the service resource type work in Puppet?
Ans:
The service resource type in Puppet is used to manage services on a system. It ensures that a service is running, stopped, enabled, or disabled based on the specified configuration. For example:
- service { ‘apache2’:
- ensure => ‘running’,
- enable => true,
- }
This example ensures that the Apache service (apache2) is running and will start on system boot (enable => true).
22. What is a Puppet module?
Ans:
A Puppet module is a self-contained collection of manifests, files, templates, and other elements that work together to provide specific functionality or manage a particular aspect of system configuration. Modules are used to organise and share Puppet code in a structured way, promoting reusability and maintainability.
23. How do you create a Puppet module?
Ans:
To create a Puppet module, you can use the pdk (Puppet Development Kit) command-line tool or create the necessary directory structure manually. Here are the basic steps using pk:
This command creates a directory structure with the necessary files and folders for a Puppet module.
24. How can you install a Puppet module?
Ans:
Puppet modules can be installed using the Puppet module install command, specifying the module name and version. For example: puppet module install puppetlabs-apache –version 2.6.0 This command instals version 2.6.0 of the Apache module from Puppet Forge.
25. What is the purpose of the manifests directory in a Puppet module?
Ans:
The manifests directory in a Puppet module contains the main Puppet manifests that define the resources and configurations provided by the module. The primary manifest file is often named init. pp and serves as the entry point for the module. It includes resource declarations, classes, and other definitions that describe the desired state of the system.
26. Explain the structure of a typical Puppet module.
Ans:
A typical Puppet module has the following structure:
- module/
- ├── manifests/
- └── init.pp
- ├── files/
- ├── templates/
- ├── examples/
- ├── tests/
- ├── metadata.json
- └── README.md
- The manifests directory contains Puppet manifests, including the primary init. pp.
- The files directory holds static files to be distributed with the module.
- The templates directory contains Puppet templates.
- The examples directory may include example usage of the module.
- The tests directory is for testing the module.
- metadata.json provides metadata about the module.
- README.md is documentation for the module.
27. What are Puppet facts?
Ans:
Puppet facts are pieces of information about a node (system) that are collected by the Factor tool. Facts include details such as the operating system, hardware details, network configuration, and custom facts if defined. Puppet uses these facts during catalogue compilation to make decisions about which resources to apply and how to configure the node.
28. How can you view the facts collected by Puppet on a node?
Ans:
You can view the facts collected by Puppet on a node using the factor command. For example, facter This command displays a list of facts for the current node.
29. Explain the role of Facter in Puppet.
Ans:
Facter is a system profiling tool used by Puppet to gather information about a node’s configuration, which is then used during catalogue compilation. Facter collects facts, such as operating system details, IP addresses, system architecture, and more. Puppet uses these facts to determine the current state of the node and to apply the appropriate configurations defined in Puppet manifests.
30. How do you define variables in Puppet?
Ans:
In Puppet, variables are defined using the $ symbol. For example:
- $my_variable = ‘Hello, Puppet!’
The variable $my_variable can then be used throughout the Puppet manifest.
31. What is a Puppet template?
Ans:
A Puppet template is a file written in the Embedded Puppet (EPP) or Embedded Ruby (ERB) syntax, allowing dynamic content generation. Templates are used to create configuration files that may contain variables, conditionals, and loops, allowing for flexible and reusable configurations.
32. How do you use templates in Puppet manifests?
Ans:
Templates are used with the file resource type in Puppet. For example:
- File { ‘/etc/config.conf’:
- content => epp(‘mymodule/myconfig.conf.epp’),
- }
33. What is a dependency in Puppet?
Ans:
A dependency in Puppet represents a relationship between different resources. Dependencies ensure that resources are applied in the correct order. There are several types of dependencies, including before, require, notify, and subscribe, each defining a different relationship between resources.
34. Explain the difference between before, require, notify, and subscribe.
Ans:
- Before: Ensures that the resource containing the before relationship is applied before the specified resource.
- Require: Requires that the resource containing the required relationship is applied before the specified resource.
- Notify: Sends a signal to the specified resource, causing it to be reapplied if the notifying resource changes.
- Subscribe: Causes the resource containing the subscribe relationship to be reapplied if the specified resource changes.
35. How do you establish relationships between Puppet resources?
Ans:
Relationships between Puppet resources are established using dependency arrows (-> and ~>) or using the before, require, notify, and subscribe meta parameters. For example:
- File { ‘/etc/config file’:
- ensure => file,
- content => ‘This is a configuration file.’,
- }
- Service { ‘myservice’:
- ensure => running,
- require => File[‘/etc/config file’],
- }
36. What is a Puppet environment?
Ans:
A Puppet environment is a separate and isolated directory structure containing its own set of modules, manifests, and other configuration files. Environments allow administrators to manage different configurations for nodes based on their roles, locations, or other criteria. Environments are defined in the Puppet configuration and can be used to stage changes or apply specific configurations to different sets of nodes.
37. How can you switch between Puppet environments?>
Ans:
Puppet environments are typically specified in the puppet.conf file using the environment setting. To switch between environments, update the environment setting to the desired environment name. For example:
- [main]
- environment = production
38. Explain the purpose of the environment. Conf file.
Ans:
The environment. conf file, located within each Puppet environment, allows administrators to configure environment-specific settings. It can be used to define variables, set module paths, configure Puppet server settings, and more. The environment. conf file is used to customise the behaviour of Puppet within a specific environment.
39. What are some best practices for writing clean and efficient Puppet code?
Ans:
Some best practices for writing clean and efficient Puppet code include:
- Use meaningful resource names and titles.
- Organise code into classes and modules for reusability.
- Limit the use of conditional statements in favour of declarative resource definitions.
- Use parameterized classes for flexibility.
- Follow a consistent code style.
- Leverage Puppet linting tools for code validation.
- Document code using comments and README files.
40. How do you manage sensitive information such as passwords in Puppet?
Ans:
Sensitive information, such as passwords, should be managed securely. Puppet provides the Sensitive data type to handle sensitive information. Additionally, tools like Hiera-eyaml or other encryption solutions can be used to encrypt sensitive data in Hiera files. Using environment variables or external tools for secure data storage is also a common practice. It’s important to follow security best practices and avoid storing sensitive information directly in Puppet manifests.

Get Hands-on Puppet Certification Course from Real-Time Experts
Weekday / Weekend BatchesSee Batch Details41. What is Hiera in Puppet?
Ans:
Hiera is a key-value lookup tool used in Puppet for separating configuration data from Puppet code. It allows administrators to define and manage configuration data hierarchically, making it easier to organise and override data for different nodes or environments.
42. How does Hiera help in managing data?
Ans:
- Hiera helps in managing data by providing a way to organise and lookup configuration data based on a hierarchical structure.
- It allows administrators to define data at different levels, such as global, environment, and node-specific, and Puppet uses this hierarchy to retrieve the appropriate data during catalogue compilation.
- This separation of data from code enhances flexibility and maintainability.
43. Explain the hierarchy concept in Hiera.
Ans:
The hierarchy concept in Hiera refers to the order in which data is looked up. It typically includes global, environment, and node-specific levels. When Puppet needs to retrieve a specific piece of data, it searches through the hierarchy from the most specific to the least specific until it finds a match. This allows for the customization of data based on different levels of specificity.
44. How do you secure communication between Puppet master and agents?
Ans:
Communication between the Puppet master and agents can be secured using SSL/TLS. This involves configuring Puppet with signed SSL certificates for both the master and agents. Puppet uses SSL certificates to authenticate and encrypt communication between nodes, ensuring secure and trusted communication.
45. What is SSL in Puppet, and how is it used for security?
Ans:
SSL (Secure Sockets Layer) in Puppet is used for securing communication between Puppet master and agents. SSL certificates are used for authentication and encryption. The Puppet master signs certificates for each agent, establishing a secure and trusted connection. SSL ensures that the communication is not intercepted or tampered with, providing a secure channel for transmitting configuration data.
46. How can you enable and configure Puppet reporting?
Ans:
Puppet reporting can be enabled and configured by modifying the puppet.conf file on the Puppet master. Key settings include reports and reportdir. Additionally, you can configure specific report processors, such as PuppetDB or other third-party tools. For example:
- [Master]
- reports = puppetdb
47. What tools can be used for monitoring Puppet infrastructure?
Ans:
Some tools for monitoring Puppet infrastructure include:- PuppetDB: Provides a powerful interface for querying and analysing Puppet data.
- Foreman: Offers a web-based interface for managing Puppet infrastructure and provides monitoring features.
- Prometheus: A popular open-source monitoring and alerting toolkit that can be integrated with Puppet for monitoring purposes.
48. How do you troubleshoot issues with Puppet agents?>
Ans:
Troubleshooting Puppet agents involves checking logs, verifying configurations, and testing connectivity. Key steps include:- Reviewing Puppet agent logs (e.g., /var/log/puppet.log).
- Verifying network connectivity between the agent and master.
- Checking SSL certificates on both the agent and master.
- Using the puppet agent –test command for manual testing.
- Examining Puppet resource statuses and error messages.
49. Explain common error messages you might encounter in Puppet.
Ans:
Common Puppet error messages include:
- Certificate-related issues: Errors related to SSL certificates, such as certificate verification failures.
- Resource conflicts: Issues where conflicting resource declarations exist.
- Module or file not found: Errors indicating that Puppet cannot find the specified module or file.
50. What is an External Node Classifier?
Ans:
An External Node Classifier (ENC) is a mechanism that allows Puppet to determine the node’s classification (which classes it should include) from an external source. It is used to dynamically assign classes and configurations to nodes based on their characteristics. ENC helps in centralising and abstracting node classification from the Puppet code.
51. How can you configure and use an ENC with Puppet?
Ans:
To configure an ENC with Puppet, you need to define the external_nodes setting in the Puppet. conf file. The ENC script should output YAML or JSON data that includes the node’s classification. The script’s path is specified in the configuration.
52. How do you upgrade Puppet to a new version?
Ans:
Upgrading Puppet involves several steps, including:
- Backing up configuration files and data.
- Checking for compatibility with existing modules and code.
- Updating or reinstalling Puppet packages.
- Testing the new version in a non-production environment.
- Verifying and monitoring the Puppet run after the upgrade.
53. Explain the process of migrating from Puppet 3 to Puppet 4.
Ans:
The migration from Puppet 3 to Puppet 4 involves updating code and addressing changes in syntax and behaviour. Key steps include:
- Reviewing Puppet 4 release notes for changes and deprecated features.
- Updating Puppet manifests to comply with Puppet 4 syntax.
- Checking and updating module dependencies.
- Testing the migration in a controlled environment.
54. Name some tools or products in the Puppet ecosystem.
Ans:
Some tools or products in the Puppet ecosystem include:/
- Puppet Bolt: An open-source task automation tool.
- PuppetDB: A storage backend for Puppet data, providing query and reporting capabilities.
- Hiera-eyaml: An extension to Hiera for encrypting sensitive data.
- R10k: A tool for managing Puppet modules and environments.
- Puppet Explorer: A web-based interface for exploring Puppet data.
55. How does Puppet integrate with version control systems?
Ans:
Puppet code can be managed and versioned using version control systems (VCS) such as Git. Puppet manifests, modules, and associated files are stored in a Git repository, allowing for collaborative development, version tracking, and rollback to previous configurations. Continuous integration practices can also be employed to automate testing and deployment.
56. Explain the role of Puppet in a DevOps environment.
Ans:
In a DevOps environment, Puppet plays a crucial role in automating configuration management, ensuring consistency across infrastructure, and enabling rapid and reliable deployments. Puppet facilitates collaboration between development and operations teams by automating repetitive tasks, reducing manual errors, and providing a standardised approach to infrastructure management.
57. How can Puppet be used for continuous integration and continuous delivery (CI/CD)?
Ans:
Puppet can be integrated into CI/CD pipelines to automate testing and deployment processes. Puppet code can be versioned, tested, and promoted through different environments, ensuring that changes are validated before reaching production. CI/CD tools can trigger Puppet runs, and Puppet modules can be tested using tools like Beaker or KitchenPuppet.
58. Compare Puppet with other configuration management tools like Ansible or Chef.
Ans:
While Puppet, Ansible, and Chef are all configuration management tools, they have different approaches:
- Puppet: Uses a declarative language, requires a Puppet master, and relies on an agent-node architecture.
- Ansible: Uses an agentless push-based model, employs YAML for configuration, and does not require a central server.
- Chef: Uses a declarative or imperative language, requires a Chef server, and has a similar agent-node architecture as Puppet.
Each tool has its strengths and is suited to different use cases based on preferences, infrastructure requirements, and team workflows.
59. How does Puppet work with containerization technologies like Docker?
Ans:
Puppet can be used to manage configurations within Docker containers. Puppet modules can define the desired state of a container, including packages, services, and files. Puppet code can be applied to the Docker host or included within a Docker image. Puppet is often used in conjunction with tools like Docker Compose or Kubernetes to manage containerized environments.
60. Explain the concept of “Puppet inside Docker” or using Puppet in containerized environments.
Ans:
“Puppet inside Docker” refers to the practice of using Docker containers to run Puppet agents. In this setup, a Docker container is created with the Puppet agent installed, and it is configured to connect to a Puppet master. This approach allows for isolated testing and execution of Puppet code within a containerized environment.

Learn Puppet Training with In-Depth Concepts to Build Your Skills
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. In what scenarios would you choose Puppet over other tools?
Ans:
Puppet is often preferred in scenarios where declarative language and agent-based architecture are advantageous. Choose Puppet when:
- There is a need for a centralised Puppet master to control configurations.
- You require a strong and mature ecosystem of modules.
- Environments involve complex configurations and dependencies.
- You want detailed reporting and auditing capabilities.
62. How can you contribute to the Puppet open-source community?
Ans:
You can contribute to the Puppet open-source community by:
- Participating in discussions on the Puppet mailing lists.
- Contributing code, bug fixes, or new features via GitHub pull requests.
- Writing and maintaining Puppet modules.
- Reporting bugs and issues on the Puppet issue tracker.
- Contributing to Puppet-related documentation.
- Engaging with the community on forums and social media.
63. Name some online resources for learning Puppet.
Ans:
Some online resources for learning Puppet include:
- Puppet official documentation: Puppet Docs.
- Puppet Learning VM: Puppet Learning VM.
- Puppet Forge: Puppet Forge.
- Puppet YouTube channel: Puppet YouTube.
- Puppet Community Slack: Puppet Community Slack.
64. Share a real-world scenario where Puppet helped improve system configuration and management.
Ans:
In a large-scale web hosting environment, Puppet was used to manage the configurations of hundreds of web servers. Puppet ensures consistency in the configuration of Apache, Nginx, and other components across the infrastructure. This resulted in faster deployments, reduced configuration drift, and simplified management. Puppet’s ability to scale and enforce configurations consistently contributed to the overall stability and reliability of the web hosting platform.
65. Discuss a challenging problem you encountered while using Puppet and how you resolved it.
Ans:
One challenging problem involved troubleshooting a Puppet agent that was failing to communicate with the master due to SSL certificate issues. The resolution included:
- Verifying the system time on both the master and agent.
- Clearing cached SSL certificates on the agent.
- Re-signing the agent’s certificate on the Puppet master.
- Ensuring that the correct Puppet master hostname was specified in the agent’s configuration.
- Verifying that firewalls and network settings allowed communication between the master and agent.
66. Are you familiar with Puppet certification programs?
Ans:
As of my last knowledge update in January 2022, Puppet offered the “Puppet Certified Practitioner” certification. However, certification programs may evolve, and new certifications may be introduced. It’s recommended to check Puppet’s official website or relevant sources for the latest information on Puppet certification programs.
67. Why is Puppet certification valuable in the IT industry?
Ans:
Puppet certification is valuable in the IT industry because it validates a professional’s expertise in Puppet and configuration management. It demonstrates a comprehensive understanding of Puppet tools, best practices, and the ability to manage infrastructure effectively. Certification can enhance career opportunities, increase credibility, and provide a recognized standard for Puppet skills in the industry.
68. What do you think are the future trends in Puppet and configuration management?
Ans:
Future trends in Puppet and configuration management may include:
- Increased focus on cloud-native configurations and integrations.
- Enhanced support for container orchestration tools and Kubernetes.
- Continued emphasis on security and compliance automation.
- Integration with emerging technologies, such as edge computing and serverless architectures.
- Improvements in user experience and ease of adoption for new users.
69. Explain the concept of idempotence and its relevance in Puppet.
Ans:
Idempotence in Puppet means that applying the same configuration multiple times produces the same result as applying it once. Puppet ensures idempotence by only making changes when necessary to bring the system to the desired state. This concept is crucial for predictable and reliable infrastructure management, as Puppet can be run repeatedly without causing unintended side effects.
70. How do you troubleshoot networking issues on a Puppet node?
Ans:
Troubleshooting networking issues on a Puppet node involves:
- Checking network connectivity between the node and Puppet master.
- Verifying DNS resolution for the Puppet master’s hostname.
- Reviewing firewall rules to ensure they allow Puppet traffic.
- Checking SSL certificates for validity.
- Examining Puppet logs on both the node and master for any networking-related errors.
71. Given a specific infrastructure scenario, how would you design a Puppet solution?
Ans:
The design of a Puppet solution depends on the specific infrastructure scenario, including the number of nodes, desired configurations, and deployment requirements. A typical design might involve:
- Setting up a centralised Puppet master for configuration control.
- Organizing configurations into modular Puppet modules.
- Implementing a version control system for Puppet code.
- Configuring Hiera for data separation.
72. Explain the use of exported resources in Puppet.
Ans:
Exported resources in Puppet allow one node to export a resource and another node to collect and realise that resource. This enables the sharing of configurations between nodes. For example, a database server could export a firewall rule, and web servers could collect and apply that rule. Exported resources are useful in scenarios where certain configurations need to be distributed across multiple nodes dynamically.
73. Describe a situation where you would choose Puppet over manual configuration.
Ans:
Puppet is preferred over manual configuration in scenarios where:
- There is a need for consistency and repeatability in system configurations.
- Infrastructure scales and manual configuration become impractical.
- Configuration drift needs to be minimised across a large number of nodes.
- Auditing and reporting capabilities are required.
- Changes need to be tracked, versioned and applied systematically.
74. How do you manage custom facts in Puppet?
Ans:
Custom facts in Puppet are managed by placing executable scripts in the facts.d directory on the node. These scripts output key-value pairs representing custom facts. Puppet automatically discovers and uses these facts during catalogue compilation. Custom facts can be used to gather additional information about nodes, which can then be utilised in Puppet manifests.
75. What is the purpose of the puppet apply command?
Ans:
The puppet apply command is used to apply a standalone Puppet manifest directly to a node without a Puppet master. This allows for ad-hoc configuration management and testing on a single node. The manifest is applied locally, and the node’s state is configured based on the specified Puppet code.
76. How does Puppet integrate with cloud platforms like AWS or Azure?
Ans:
Puppets can integrate with cloud platforms like AWS or Azure by using cloud-specific modules to manage resources. Puppet modules for AWS or Azure provide resources to define and manage instances, networks, storage, and other cloud-related components. Puppet can be used to automate the provisioning and configuration of cloud resources, ensuring consistency across on-premises and cloud environments.
77. Explain the challenges and solutions for managing Puppet in a cloud environment.
Ans:
Challenges in managing Puppet in a cloud environment may include dynamic scaling, security, and network considerations. Solutions involve:
- Leveraging cloud-specific Puppet modules for resource management.
- Integrating Puppet with cloud APIs for dynamic infrastructure changes.
- Implementing secure communication between Puppet controller and cloud nodes.
- Addressing challenges related to firewall rules, networking, and virtualization.
78. Can Puppet manage Windows nodes? How?
Ans:
Yes, Puppet can manage Windows nodes. Puppet provides native support for Windows and includes resource types specific to Windows configurations. Puppet code written for Windows is similar to that for Linux, using resources like files, packages, and services. Additionally, Puppet supports Windows-specific configurations and management tasks, making it a versatile tool for cross-platform infrastructure.
79. What are the key differences between managing Linux and Windows systems with Puppet?
Ans:
While the core concepts are similar, key differences in managing Linux and Windows systems with Puppet include: Use of different resource types for OS-specific configurations.
- Different package management systems (e.g., apt on Linux, msi on Windows).
- Windows-specific file paths and directory structures.
- Unique configurations for services and users on each platform.
80. How can Puppet handle scaling in large environments?
Ans:
Puppet can handle scaling in large environments through:
- Master-Node Architecture: Distributing the load by deploying multiple Puppet controller servers.
- Load Balancing:Using load balancers to distribute agent requests across multiple Puppet masters.
- Code Splitting: Organising Puppet code into modular components to facilitate parallel development and testing.
- Scaling PuppetDB: Configuring PuppetDB for larger deployments to handle increased data storage and retrieval demands.
- High Availability: Implementing high-availability solutions for Puppet controller servers to ensure continuous service availability.
81. Discuss strategies for optimising Puppet performance in a large infrastructure.
Ans:
Strategies for optimising Puppet performance in a large infrastructure include:
- Code Profiling: Identify and optimise resource-intensive code.
- Parallelization: Distribute catalogue compilation across multiple Puppet controller servers.
- Caching: Use caching mechanisms to store compiled catalogues and reduce load.
- Selective Scheduling: Optimise the Puppet run frequency for different node groups.
- PuppetDB Tuning: Adjust PuppetDB settings for improved query and response times.
82. What does Puppet Enterprise provide the additional features?
Ans:
Puppet Enterprise offers additional features compared to the open-source version, including:
- Role-Based Access Control (RBAC): Fine-grained control over user permissions.
- Node Manager: Simplifies node management tasks.
- Puppet Orchestrator: Provides workflow automation and task execution.
- Puppet Discovery: Automated discovery and inventory management.
- Event Inspector: Enhanced visibility into Puppet infrastructure events.
- Enhanced Support: Access to official Puppet support services.
83. How is Puppet Enterprise different from the open-source version of Puppet?
Ans:
Puppet Enterprise includes additional enterprise-focused features such as RBAC, Node Manager, Orchestrator, Discovery, and official support. The open-source version provides core configuration management functionality without the enterprise-specific enhancements.
84. How can Puppet help in achieving and maintaining compliance with industry standards?
Ans:
Puppet helps achieve and maintain compliance by:
- Enforcing standardised configurations across nodes.
- Automating configuration checks to ensure compliance.
- Providing audit trails and reporting capabilities.
- Facilitating quick remediation of non-compliant configurations.
- Integrating with compliance frameworks and reporting tools.
85. Explain the use of Puppet in auditing and reporting for compliance.
Ans:
-
Puppet provides auditing and reporting features by:
- Logging changes made during Puppet runs.
- Generating reports on configuration drift and compliance.
- Integrating with external reporting tools or frameworks.
- Enabling administrators to review and audit historical configuration states.
86. What is configuration drift, and how can Puppet help prevent it?
Ans:
Configuration drift is the unauthorised or unplanned changes in a system’s configuration over time. Puppet helps prevent configuration drift by enforcing a desired state and automatically correcting any deviations during Puppet runs. It ensures that nodes remain in the intended configuration, reducing the risk of configuration drift.
87. Discuss strategies for detecting and remedying configuration drift in Puppet.
Ans:
Strategies for detecting and remedying configuration drift in Puppet include:
- is Regularly running Puppet to enforce the desired state.
- Using Puppet reports to identify discrepancies.
- Implementing alerting mechanisms for significant drift.
- Leveraging external tools for advanced drift detection.
- Automating remediation tasks to bring nodes back to compliance.
88. How does Puppet handle logging and log management?
Ans:
Puppet logs events and changes during Puppet runs in log files. Logging is configurable in the puppet.conf file. Puppet can integrate with centralised log management solutions for aggregation, analysis, and monitoring of Puppet-related logs.
89. What tools can be integrated with Puppet for log analysis?
Ans:
Tools that can be integrated with Puppet for log analysis include:
- ELK Stack (Elasticsearch, Logstash, Kibana): For centralised log aggregation and analysis.
- Splunk: Provides log management, analysis, and visualisation.
- Graylog: Open-source log management solution.
- Fluentd: Unified logging layer for various log sources.
90. How can Puppet be integrated with databases for configuration management?
Ans:
Puppet can be integrated with databases through modules or custom Puppet code. Puppet can manage database configurations, users, permissions, and schema definitions. Puppet’s declarative language allows administrators to define the desired state of the database, and Puppet ensures the system converges to that state.
91. Explain the use of PuppetDB in Puppet infrastructure.
Ans:
PuppetDB is a data warehouse for Puppet that stores data generated by Puppet runs. It allows querying and reporting on Puppet data, facilitating tasks such as node classification, reporting, and export of resources. PuppetDB enhances scalability and performance in large Puppet infrastructures.
92. Discuss the concept of immutable infrastructure and how Puppet fits into this model.
Ans:
Immutable infrastructure involves deploying unchangeable, immutable instances that are replaced rather than modified. Puppet fits into this model by defining the desired state of infrastructure in Puppet code. Immutable instances can be provisioned using Puppet manifests, ensuring consistency and avoiding drift.
93. How does Puppet handle updates and changes in an immutable infrastructure?
Ans:
In an immutable infrastructure, updates and changes are made by creating new instances with updated configurations. Puppet helps by defining and applying the desired state to these new instances during provisioning. The existing instances are terminated, ensuring that updates are rolled out through the creation of fresh, immutable instances.
94. Can Puppet be used for managing configurations in IoT devices?
Ans:
Puppet can be adapted for managing configurations in IoT devices, but challenges exist due to resource constraints and diverse architectures. Lightweight and agentless approaches might be more suitable for IoT. Tools like Puppet Bolt or Puppet for Docker can be used to configure and manage IoT devices.
95. Discuss the challenges and opportunities of using Puppet in IoT scenarios.
Ans:
Challenges in using Puppet for IoT include resource limitations, diverse platforms, and network constraints. Opportunities include centralised configuration management, version control, and automation. Customization of Puppet for IoT may involve lightweight agents, tailored modules, and considerations for intermittent connectivity.
96. How does Puppet support continuous monitoring of infrastructure changes?
Ans:
Puppet supports continuous monitoring by providing reports, logs, and integration with monitoring tools. Continuous monitoring tools can detect changes in Puppet-managed systems, and Puppet reports provide insights into the state of the infrastructure after each Puppet run.
97. What tools can be used in conjunction with Puppet for continuous monitoring?
Ans:
Tools that can be used for continuous monitoring with Puppet include:- Prometheus: A monitoring and alerting toolkit.
- Grafana: A platform for monitoring and observability.
- Nagios: A widely used open-source monitoring solution.
- Sensu: A monitoring framework for cloud, containers, and traditional infrastructure.
98. Explain the role of Puppet in disaster recovery scenarios.
Ans:
Puppet plays a role in disaster recovery by:- Defining infrastructure configurations in code.
- Facilitating quick and consistent rebuilds of infrastructure.
- Automating the recovery process based on predefined configurations.
- Ensuring that infrastructure can be reestablished rapidly and reliably.
99. Discuss strategies for backing up and restoring Puppet configurations.
Ans:
Strategies for backing up and restoring Puppet configurations include:- Regularly backing up Puppet manifests, modules, and Hiera data.
- Storing backup copies in a secure location.
- Documenting and version-controlling Puppet code.
- Testing backup and restoration processes periodically.
100. How can Puppet contribute to high availability and fault tolerance in a system?
Ans:
Puppet contributes to high availability and fault tolerance by:- Allowing the deployment of multiple Puppet controller servers for load balancing.
- Providing options for Puppet controller high availability configurations.
- Enabling the quick redeployment of nodes in case of failures.
- Automating the recovery process to ensure consistent and reliable infrastructure.
- Integrating with other high-availability solutions at the infrastructure level.