Last updated on 10th Jun 2020| 5212
Kubernetes (also known as k8s or “kube”) is an open source container orchestration platform that automates many of the manual processes involved in deploying, managing, and scaling containerized applications. In other words, you can cluster together groups of hosts running Linux containers, and Kubernetes helps you easily and efficiently manage those clusters.
1. What is Kubernetes, and why is it used?
Ans:
Kubernetes is an open-source container orchestration platform that automates containerised applications’ deployment, scaling, and management. Kubernetes is used to ensure high availability, scalability, and ease of management for applications in the containers. Kubernetes simplifies the deployment and management of containers, making it more straightforward to manage the complex microservices architectures.
2.Explain the architecture of Kubernetes.
Ans:
Kubernetes has a master-node architecture. The controller node manages the control plane, while worker nodes run application containers. The control plane consists of an API server for configuration data, a scheduler, and a controller manager. Worker nodes have kubelet kube-proxy, and container runtime.
3. What are Nodes in Kubernetes, and what are their types?
Ans:
Nodes in Kubernetes are the individual machines that form clusters. There are two types of nodes: worker nodes (minions), where application containers run, and controller nodes, which control and manage collection. Worker nodes are where workloads are executed.
4. What is Pod in Kubernetes? time?
Ans:
A Pod in Kubernetes is a smallest deployable unit and represents the single instance of a running process in a cluster. A Pod in Kubernetes contains one or more containers that share the same network and storage. Pods are used to group the related containers that must work together closely.
5. What are the differences between Deployment and StatefulSet in Kubernetes?
Ans:
A Deployment is used for stateless applications, providing features like scaling, rolling updates, and rollbacks. A StatefulSet is used for stateful applications that require stable network identities and storage. StatefulSets maintains the consistent naming convention and order when creating pods.
6. What is Kubernetes Service and its types?
Ans:
A Kubernetes Service is the abstraction that enables communication between the different parts of an application or between applications within the cluster. The three types of Services include ClusterIP (internal service), NodePort (exposes the port on each node externally), and LoadBalancer (exposes services externally using the cloud providers’ load balancers).
7. What is Namespace in Kubernetes, and why is it important?
Ans:
A Namespace in the Kubernetes is the logical partition within a cluster that allows creating multiple virtual collections within a same physical set. A Namespace helps organise and isolate the resources, applications, and policies, making managing and securing multi-tenant environments more straightforward.
8.How does Kubernetes use etc?
Ans:
Kubernetes uses etcd as distributed key-value store to store configuration data and cluster state information. Etcd ensures consistency and reliability of data, making it a critical component of a Kubernetes control plane.
9. What is ReplicaSet in Kubernetes?
Ans:
A ReplicaSet in the Kubernetes is a resource that ensures the specified number of identical replicas (pods) are running at all the times. A ReplicaSet in Kubernetes is used for a scaling and maintaining desired number of pod instances, replacing the failed pods, and performing rolling updates when changes are made to pod template.
10. Explain kube-scheduler.
Ans:
The kube-scheduler in the Kubernetes helps in determining which node in cluster should run a newly created pod based on the various factors like resource requirements and constraints like affinity, anti-affinity, and node constraints.
11. What is DaemonSet in Kubernetes?
Ans:
A DaemonSet in the Kubernetes is the specialized controller that ensures that specific set of pods, often referred to as daemons, runs on the every node within the cluster. DaemonSet is commonly used for a tasks such as monitoring, logging, and networking, where need one instance of the pod is on each node.
12. How do we monitor the health of the Kubernetes cluster?
Ans:
Monitoring the health of the Kubernetes cluster involves using various tools and techniques such as critical components, including Prometheus for metrics collection, Grafana for the visualization, and Kubernetes-native features like readiness and liveness probes to ensure the health of individual pods.
13. Explain Helm is in the context of Kubernetes.
Ans:
Helm is Kubernetes’s package manager, simplifying the process of deploying, managing, and upgrading applications. Helm uses the charts to define the structure and configuration of the Kubernetes resources, making it more straightforward to handle complex applications.
14. What is Kubernetes Ingress?
Ans:
Kubernetes Ingress is the resource used to manage external access to the services within the cluster. Kubernetes Ingress acts as a traffic manager, routing incoming requests to appropriate services based on the rules and configurations, enhancing the cluster’s routing capabilities.
15. How can Kubernetes handle container storage?
Ans:
Kubernetes handles the container storage through Persistent Volumes (PVs) and Persistent Volume Claims (PVCs). PVs represent physical storage resources, while PVCs are requests made by the pods for storage. Kubernetes dynamically provisions and binds the PVs to PVCs based on the availability and requirements.
16. What are ConfigMaps in Kubernetes?
Ans:
ConfigMaps in the Kubernetes stores configuration data separately from the application code. ConfigMaps in Kubernetes allows decoupling configuration settings from the containers, making it easier to update and manage configuration across different environments.
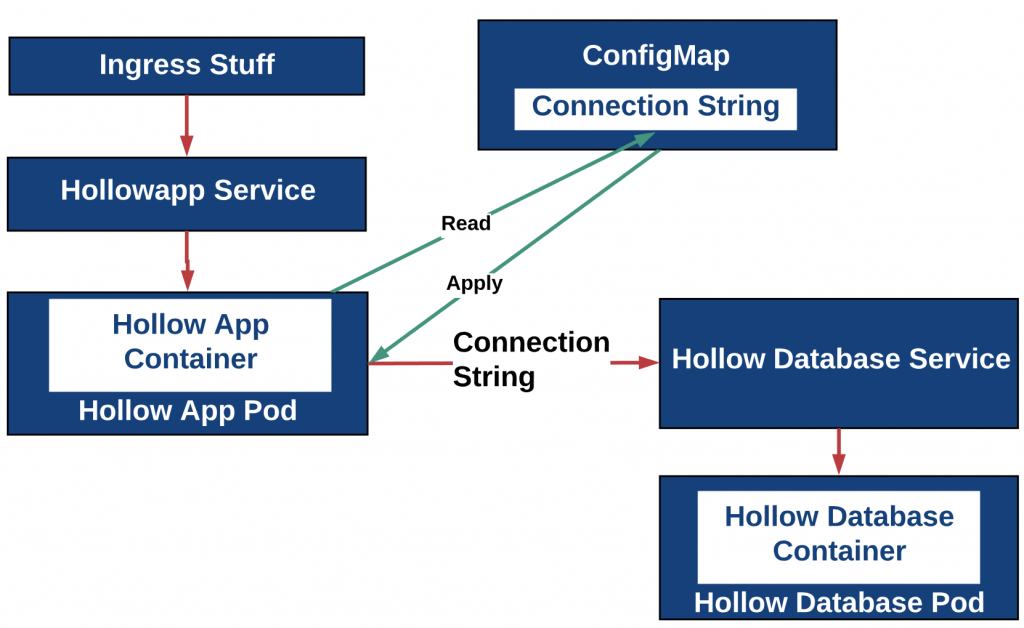
17. Explain Kubernetes Secret.
Ans:
Kubernetes Secrets securely store sensitive information, like passwords, API keys, and tokens. Kubernetes Secrets are encoded and can only be accessed by authorized containers, enhancing security in containerized applications.
18. What is kube-proxy?
Ans:
Kube-proxy is the network proxy that runs on each node within the Kubernetes cluster. Kube-proxy maintains network rules on nodes and enables communication between the pods across different nodes, facilitating network routing and load balancing.
19. How does Kubernetes provide high availability?
Ans:
Kubernetes achieves high availability through features like replica sets, which ensure that specified pod replicas are always running, and by supporting the multi-node clusters with automatic failover and rescheduling of workloads.
20. What is the difference between PersistentVolume and PersistentVolumeClaim in Kubernetes?
Ans:
The difference between the PersistentVolume and a PersistentVolumeClaim in Kubernetes is that PersistentVolumes (PVs) are storage resources in Kubernetes, while the PersistentVolumeClaims (PVCs) are requests made by pods for storage. The administrators provision PVs, while the users create PVCs to consume storage resources.
21. Explain how to scale applications in Kubernetes?
Ans:
Scaling applications in the Kubernetes involves adjusting a number of replica pods to meet changing demand. Scaling can be done manually or automatically using features are Horizontal Pod Autoscaling (HPA) based on the CPU and memory usage.
22. What are labels and selectors in Kubernetes?
Ans:
Labels and selectors in the Kubernetes are key concepts for an organizing and identifying resources. Labels are the key-value pairs attached to objects, while selectors are used to filter and target objects based on labels.
23. How do perform rolling updates in Kubernetes?
Ans:
Rolling updates in the Kubernetes involve gradually updating a pods of a deployment to the new version while maintaining availability. Rolling updates in Kubernetes is achieved by creating a new pods with the updated images and terminating old ones in the controlled manner.
24. What is role of kubelet in Kubernetes?
Ans:
The kubelet is the critical component in Kubernetes that runs on each node and ensures that containers are running in the Pod. The kubelet communicates with API server, manages container’s lifecycle, and reports node status and resource utilization.
25. Explain the process of deploying application in Kubernetes?
Ans:
Containerization : The application is first containerized using the technologies like Docker. This encapsulates application and its dependencies into the portable container image.
Creating Kubernetes Manifests : Kubernetes uses the YAML or JSON manifests to define desired state of application, including the number of the replicas, networking, and storage configurations.
Applying Manifests : These manifests are applied to Kubernetes cluster using the kubectl apply command. Kubernetes will then work to ensure that the actual state matches desired state defined in manifests.
26. What is Init Container in Kubernetes?
Ans:
An Init Container in Kubernetes is the special type of container that runs before main application container starts. An Init Container is used for a tasks such as setup, configuration, or data population. Init Containers are the different from regular containers because they run to the completion before the main container starts, ensuring that any dependencies or a prerequisites are in place.
27. How does Kubernetes use resource quotas?
Ans:
Kubernetes uses the resource quotas to limit the amount of the CPU and memory resources that namespace or a group of containers can consume. The process prevents a resource contention and ensures as fair resource distribution among the applications running in the cluster.
28. What are main components of Kubernetes master node?
Ans:
API Server : Exposes Kubernetes API and is the entry point for all the commands and management operations.
etcd : A distributed key-value store that stores cluster’s configuration data and desired state.
Controller Manager : Watches for changes in cluster’s desired state and makes changes to bring current state closer to a desired state.
Scheduler : Assigns pods to the worker nodes based on the resource requirements and constraints.
29. How does Kubernetes use liveness and readiness probes?
Ans:
Kubernetes uses the liveness and readiness probes to ensure health and availability of containers within pod. A liveness probe checks if container is running correctly and if it fails, Kubernetes restarts container. A readiness probe checks if container is ready to accept the traffic and if it fails, container is temporarily removed from a load balancing until it becomes ready.

Get Kubernetes Course from leading Professional Certification Training Provider
Weekday / Weekend BatchesSee Batch Details30 Explain process of autoscaling in Kubernetes?
Ans:
Autoscaling in the Kubernetes involves automatically adjusting a number of pod replicas based on the resource utilization or custom metrics. Kubernetes provides a two types of autoscaling listed below.
Horizontal Pod Autoscaling (HPA) : It scales number of replicas of a Deployment or ReplicaSet based on the CPU or custom metrics thresholds.
Cluster Autoscaler : It scales number of nodes in the cluster based on resource requirements and constraints, ensuring that there are the enough resources to run desired number of pods.
31.How do implement zero-downtime deployments in Kubernetes?
Ans:
Zero-downtime deployments in the Kubernetes are achieved using a rolling updates and readiness probes. Uninterrupted service is a maintained by gradually replacing old pods with the new ones and ensuring a new pods are ready to handle the traffic before proceeding
32. Describe the process of setting up Kubernetes cluster on-premises?
Ans:
Setting up the Kubernetes cluster on-premises involves installing the Kubernetes components like a kube-apiserver, kube-controller-manager, kube-scheduler, etcd, and kubelet on the each node. Network configuration and storage setup are the essential, followed by initializing cluster using the kubeadm or similar tools.
33. Explain the role and workings of Kubernetes API server? Explain
Ans:
The Kubernetes API server acts as a central management entity and exposes the Kubernetes API. It processes the REST requests, validates them, updates the state of Kubernetes objects in etcd, and then triggers the controllers to handle the new states.
35. How do manage stateful applications in Kubernetes?
Ans:
Stateful applications in the Kubernetes are managed using StatefulSets, which maintain the sticky identity for each of Pods. Persistent Volumes and Persistent Volume Claims are used to the handle storage requirements.
36. Discuss process of setting up network policies in Kubernetes?
Ans:
Setting up the network policies in Kubernetes involves defining a rules that specify how pods can communicate with the each other and other network endpoints. NetworkPolicy resources are created to the enforce these rules, controlling a traffic flow at IP address or port level.
37. What are best practices for securing a Kubernetes cluster?
Ans:
Best practices for a securing a Kubernetes cluster include the regular updates, minimal base images for a containers, restricting a cloud metadata access, using network policies, enabling the RBAC, auditing logs, and scanning for the vulnerabilities.
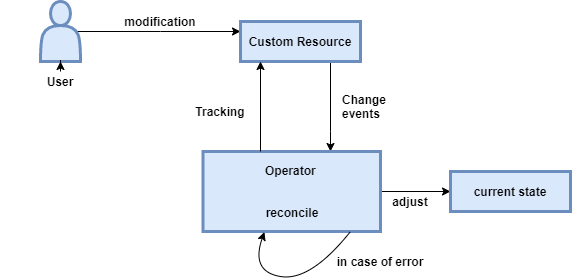
38. Explain Kubernetes Operator?
Ans:
A Kubernetes Operator is the method of packaging, deploying, and managing the Kubernetes application. A Kubernetes Operator extends the Kubernetes to automate the management of the complex applications through the custom resource definitions and associated controllers.
39. How do troubleshoot failing Pod in Kubernetes?
Ans:
Troubleshooting the failing Pod in Kubernetes involves for inspecting logs using the kubectl logs, checking events with the kubectl describe pod, ensuring resource limits are not being hit, and verifying a configuration and network connectivity.
40. Describe the setting up a service mesh in Kubernetes?
Ans:
Setting up a service mesh in the Kubernetes typically involves for installing a service mesh solution like Istio or Linkerd. Setting up the service mesh includes deploying the control plane, integrating it with the Kubernetes services, and configuring a sidecar proxies for a traffic management.
41. How Kubernetes integrate with cloud providers for a persistent storage?
Ans:
Kubernetes integrates with the cloud providers for a persistent storage through Container Storage Interface (CSI) allowing the Kubernetes to dynamically provision storage resources as a Persistent Volumes from a cloud provider-specific storage solutions.
42. What are custom resource definitions (CRDs) in Kubernetes?
Ans:
Custom Resource Definitions (CRDs) in the Kubernetes are extensions of Kubernetes API that allow creation of new, custom resources. Custom Resource Definitions (CRDs) in the Kubernetes enable the operators to add own APIs to Kubernetes clusters.
43. Explain implement autoscaling based on custom metrics in Kubernetes?
Ans:
Implementing autoscaling based on custom metrics in Kubernetes requires deploying the Kubernetes Metrics Server and Horizontal Pod Autoscaler (HPA). Custom metrics are defined and HPA is configured to scale pods based on these metrics.
44. Discuss the challenges of managing microservices in Kubernetes?
Ans:
Managing microservices in the Kubernetes presents challenges like complex service-to-service communication, maintaining a service discovery, implementing consistent security policies, and handling the distributed transaction logging and monitoring.
45. How do manage secrets in Kubernetes at scale?
Ans:
Managing secrets in Kubernetes at scale involves using Kubernetes Secrets for storing sensitive data, implementing access controls through RBAC, and potentially integrating external secret management systems like HashiCorp Vault for enhanced security.
46. What is Kubernetes webhook?
Ans:
The purpose of the Kubernetes webhook is to allow the custom admission controllers to the intercept, modify, or validate requests to Kubernetes API server before the object is stored.
47. Explain role and configuration of kube-controller-manager?
Ans:
The kube-controller-manager runs the controller processes to regulate the state of Kubernetes cluster. The kube-controller-manager manages the various controllers that handle the nodes, jobs, endpoints, and more, and is configured through the command-line arguments or a configuration files.
48. How does Kubernetes handle service discovery?
Ans:
Kubernetes handles the service discovery through the DNS and environment variables. Services within cluster are automatically assigned the DNS entries, which pods use to the discover and communicate with the each other.
49. What are considerations for implementing Kubernetes in multi-cloud environment?
Ans:
Implementing Kubernetes in the multi-cloud environment requires considerations such as network configuration, data storage consistency, security policies, and application deployment strategies. These considerations ensure a seamless operation across the different cloud platforms, focusing on a cross-cloud compatibility and centralized management.
50. Discuss use of annotations in Kubernetes?
Ans:
Annotations in the Kubernetes provide the way to attach metadata to the Kubernetes objects. Annotations in the Kubernetes are used to store additional information that can aid in management, orchestration, or deployment processes without altering core functioning of object.

Enroll for Kubernetes Training from Top-Rated DevOps Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
51. How do manage resource limits and requests in Kubernetes Pods?
Ans:
Resource limits and requests in the Kubernetes Pods are managed by defining a CPU and memory constraints in a Pod specification. Resource limits and requests in Kubernetes Pods ensure the optimal resource allocation and prevent the any single Pod from a monopolizing cluster resources.
52. Difference between horizontal and vertical Pod autoscaler?
Ans:
A horizontal Pod auto scaler scales number of Pod replicas based on the observed CPU utilization or the other select metrics, while vertical Pod auto scaler adjusts the CPU and memory limits of a containers in a Pod, scaling the resources vertically without changing a number of replicas.
53. Explain the process of implementing CI/CD pipeline in Kubernetes?
Ans:
Implementing a CI/CD pipeline in the Kubernetes involves setting up the series of stages for development, testing, and deployment, often using tools like Jenkins, Spinnaker, or GitLab. Implementing the CI/CD pipeline automates deployment of applications to Kubernetes, ensuring the 54.consistent and reliable software delivery.
54. How does Kubernetes support stateful applications with StatefulSets?
Ans:
Kubernetes supports the stateful applications with the StatefulSets, which manage the deployment and scaling of set of Pods while maintaining a state and identity of each Pod. StatefulSets is the crucial for applications that require a stable, persistent storage and a unique network identifiers.
55. What are implications of using Node Affinity and Anti-Affinity in Kubernetes?
Ans:
Using Node Affinity and Anti-Affinity in Kubernetes allows for a precise control over where Pods are placed in cluster. Using Node Affinity and Anti-Affinity in Kubernetes optimizes the resource utilization and ensures the high availability by spreading Pods across the different nodes or grouping related Pods on a same node.
56. Discuss Kubernetes uses Taints and Tolerations?
Ans:
Kubernetes uses the Taints and Tolerations to ensure that Pods are not scheduled on the inappropriate nodes. Taints are applied to the nodes, and only Pods with matching tolerations can be scheduled on nodes, enabling an effective segregation and utilization of the cluster resources.
57. How do implement and manage Kubernetes Federation?
Ans:
Implementing and managing the Kubernetes Federation involves setting up the multiple Kubernetes clusters and central control plane. Implementing and managing the Kubernetes Federation allows for management of resources across the various clusters, ensuring a high availability and scalability.
58. What is significance of Kubernetes Endpoints object?
Ans:
The Kubernetes Endpoints object is significant as it tracks IP addresses of a Pods that match a Service. The Kubernetes Endpoints ensure that Service can direct traffic to a correct Pods, facilitating effective network communication within cluster.
59. How do monitor and log applications in Kubernetes environment?
Ans:
Monitoring and logging applications in the Kubernetes environment involve using the tools like Prometheus for as monitoring and Fluentd or Elastic Stack for logging. The tools collect and analyse metrics and logs to provide the insights into the application performance and health.
60. Explain Pod Disruption Budgets in Kubernetes?
Ans:
Pod Disruption Budgets in the Kubernetes allow administrators to define minimum number of Pods that must be available during the voluntary disruptions. Pod Disruption Budgets in the Kubernetes ensure high availability and prevent applications from becoming unavailable during the maintenance or upgrades.
61. Discuss the use and limitations of Kubernetes Horizontal Pod Autoscaler?
Ans:
The Kubernetes Horizontal Pod Autoscaler automatically scales a number of Pod replicas based on the observed CPU utilization or other metrics. The Kubernetes Horizontal Pod Autoscaler has the limitations in handling rapid fluctuations in a load and is less effective for the applications with the non-linear scaling patterns.
62. What are the key metrics to monitor in Kubernetes cluster?
Ans:
Key metrics to the monitor in a Kubernetes cluster include the CPU and memory usage, Pod and node status, network traffic, and disk I/O. Monitoring Key metrics is the crucial for maintaining a cluster performance and stability.
63. How do configure Kubernetes to use external DNS services?
Ans:
Configuring Kubernetes to use the external DNS services involves a setting up a DNS provider like a CoreDNS or kube-dns to interface with the external DNS providers. This integration ensures the seamless domain name resolution for the services within and outside Kubernetes cluster.
64. What is Kubernetes Aggregation Layer?
Ans:
The significance of a Kubernetes Aggregation Layer lies in its ability to extend Kubernetes API. It allows for integration of additional, custom APIs into the cluster, enhancing functionality and flexibility of the Kubernetes.
65. How does Kubernetes handle pod eviction?
Ans:
Kubernetes handles the pod eviction through Kubelet, which evicts Pods to reclaim resources or in a response to node pressure. Pod eviction through Kubelet ensures stability and resource availability of a cluster.
66. Discuss process of implementing network segmentation in Kubernetes?
Ans:
Implementing network segmentation in the Kubernetes involves defining a network policies that control a flow of traffic between Pods. Implementing network segmentation enhances the security by isolating sensitive workloads and limiting communication paths within cluster.
67. What strategies do use for backup and disaster recovery in Kubernetes?
Ans:
Strategies for backup and disaster recovery in the Kubernetes include regular snapshots of a persistent volumes, exporting the cluster state, and replicating critical data across the multiple clusters. These measures ensure a data integrity and quick recovery in case of the failures.
68. How manage rolling updates and rollbacks in StatefulSets?
Ans:
Managing rolling updates and rollbacks in the StatefulSets involves the configuring update strategies in a StatefulSet specification. Managing the rolling updates and rollbacks enables a controlled updates with the minimal downtime and ability to roll back to the previous state if necessary.
69. What are best practices for managing large-scale Kubernetes clusters?
Ans:
Best practices for the managing large-scale Kubernetes clusters include the automating deployment and scaling, implementing the robust monitoring and logging, enforcing a strict security policies, and optimizing resource allocation to be ensure an efficient and stable cluster operation. .
70. How does Kubernetes manage container runtime environments?
Ans:
Kubernetes manages the container runtime environments using Container Runtime Interface (CRI). Container Runtime Interface (CRI) allows the Kubernetes to interact with the various container runtimes like a Docker, containerd, and CRI-O, providing the flexibility and consistency in the container management.
71. Describe the challenges of migrating legacy application to Kubernetes?
Ans:
Migrating a legacy application to the Kubernetes involves containerizing application, modifying its architecture to fit the microservices model, and ensuring compatibility with the Kubernetes APIs. Challenges include the managing stateful components, adapting to the new deployment model, and ensuring a seamless integration with an existing infrastructure.
72. How do manage cross-cluster communication in Kubernetes?
Ans:
Cross-cluster communication in the Kubernetes is managed through the federation, where clusters are linked and can share the resources and configurations. Network policies and ingress the controllers are configured to facilitate secure and efficient data exchange between the clusters.
73. Explain implementation of pod priority and preemption in Kubernetes.?
Ans:
Pod priority and preemption in the Kubernetes allow the prioritizing certain pods over others. Pods with the higher priority are scheduled first, and if necessary, can cause the lower priority pods to be evicted. Pod priority is implemented using the PriorityClass resources that assign the priority values to pods.
74. Discuss Kubernetes in DevOps environment?
Ans:
| Aspect | Description | |
| Container Orchestration |
Kubernetes automates the deployment, scaling, and management of containerized applications. |
|
| Scalability | Enables horizontal scaling of applications, adjusting resources based on demand. | |
| Continuous Integration (CI) | Integrates with CI tools to automate building, testing, and deploying containerized applications. | |
| Continuous Deployment (CD) | Facilitates continuous delivery and deployment of applications through automated processes. |
75. How implement and manage multi-tenancy in Kubernetes cluster?
Ans:
Multi-tenancy in the Kubernetes cluster is implemented by the isolating namespaces, enforcing a resource quotas, and applying the role-based access control (RBAC). Multi-tenancy in the Kubernetes ensures that different teams or the applications can operate independently within a same cluster without interference.
76. Explain customizing the Kubernetes scheduler?
Ans:
Customizing a Kubernetes scheduler involves the creating custom scheduler policies that define how pods are to be assigned to nodes. The policies consider factors like a resource requirements, node affinity, and taints and tolerations to can optimize pod placement.
77. What are best practices for managing sensitive data in Kubernetes?
Ans:
Managing sensitive data in the Kubernetes’ best practices include the using Secrets for storing sensitive data, encrypting a data at rest and in transit, implementing RBAC for the controlled access, and regularly auditing the access logs and security policies.
78. How do optimize Kubernetes for large-scale, high-traffic applications?
Ans:
To optimize the Kubernetes for a large-scale, high-traffic applications, configure the horizontal pod autoscaling, optimize the resource allocation, use efficient load balancing strategies, and implement the robust monitoring and logging for a performance insights.
79. Discuss strategies for implementing blue-green deployments in Kubernetes?
Ans:
Implementing blue-green deployments in the Kubernetes involves maintaining a two identical environments, the ‘blue’ active version and the ‘green’ new version. Traffic is gradually shifted to a green environment, ensuring a minimal downtime and easy rollback if issues arise.
80. Explain Kubernetes integrates with different container runtimes?
Ans:
Kubernetes integrates with the different container runtimes through Container Runtime Interface (CRI), which provides the standardized way for Kubernetes to communicate with the container runtimes like a Docker, containerd, and CRI-O.
81. Describe troubleshooting network issues in Kubernetes cluster?
Ans:
Troubleshooting network issues in the Kubernetes cluster involves checking a pod-to-pod communication, validating a network policies, examining DNS resolution, and inspecting ingress and egress configurations for the potential misconfigurations or bottlenecks.
82. How do manage dependencies between services in Kubernetes environment?
Ans:
Dependencies between services in the Kubernetes environment are managed through the service discovery mechanisms, defining a readiness and liveness probes, and orchestrating deployment orders with init containers and also Kubernetes Jobs.
83. Discuss considerations for implementing Kubernetes in hybrid cloud environment?
Ans:
Implementing Kubernetes in the hybrid cloud environment requires the considerations like network connectivity between the on-premises and cloud environments, consistent security policies across the environments, and tools for the unified management of resources.
84. Explain challenges and solutions for Kubernetes cluster upgrades?
Ans:
Challenges for the Kubernetes cluster upgrades include the maintaining application availability, compatibility between the different versions, and data integrity. Solutions involve the using rolling updates, thorough the testing in staging environments, and ensuring a backward compatibility.
85. How do automate compliance checks and security scanning in Kubernetes?
Ans:
Automating compliance checks and security scanning in the Kubernetes is achieved using tools like a Pod Security Policies, network policies, and integrated security scanning tools that continuously monitor and enforce the security best practices.
86. Discuss impact of Kubernetes on application architecture design?
Ans:
Kubernetes impacts application architecture design by the promoting microservices architecture, enabling the scalable and resilient systems, and facilitating faster and more frequent deployments through the containerization and orchestration.
87. Explain cloud controller manager in Kubernetes?
Ans:
The cloud controller manager in the Kubernetes abstracts cloud-specific functionality, allowing the Kubernetes to interact seamlessly with different cloud providers. The cloud controller manager in the Kubernetes manages cloud resources like a nodes, load balancers, and storage interfaces.
88. How do manage Kubernetes clusters across different regions?
Ans:
Managing Kubernetes clusters across the different regions involves for synchronizing configurations, ensuring the consistent deployment practices, and implementing global load balancing for an optimal performance and reduced latency.
89. Discuss fine-tuning Kubernetes for performance and efficiency?
Ans:
Fine-tuning Kubernetes for a performance and efficiency involves for optimizing resource allocation, implementing the autoscaling, tuning network and storage performance, and leveraging cluster monitoring tools to identify and address the performance bottlenecks.
90.What strategies use for effective logging and monitoring in Kubernetes?
Ans:
Effective logging and monitoring in the Kubernetes involve implementing centralized logging solutions are ELK Stack, configuring a comprehensive monitoring tools like Prometheus, and setting up alerts and dashboards for a real-time analysis and troubleshooting.




