Last updated on 03rd Jul 2020| 22919
A cloud-based data integration solution from Microsoft Azure called Azure Data Factory lets you design, organise, and oversee data operations. With support for a range of data sources and destinations, including on-premises and cloud resources, it enables data transfer and transformation through data pipelines. It is a comprehensive solution for creating, coordinating, and maintaining data pipelines that enable data-driven analytics and decision-making thanks to its integration with Azure services, security features, orchestration, monitoring, and administration tools.
1. What is Azure Data Factory?
Ans:
Azure Data Factory is the cloud-based, fully managed, serverless ETL and data integration service offered by a Microsoft Azure for automating data movement from its native place to, say, data lake or a data warehouse using the ETL (extract-transform-load) OR extract-load-transform (ELT). It lets cancreate and run data pipelines to help for move and transform data and run scheduled pipelines.
2. What is the Azure Data Factory ETL or ELT tool?
Ans:
It is the cloud-based Microsoft tool that provides the cloud-based integration service for data analytics at scale and supports the ETL and ELT paradigms.
3. Why is ADF needed?
Ans:
ADF is a service that can coordinate and operationalize processes to transform vast volumes of raw business data into useful business insights, which is necessary given the growing amount of big data.
4. What sets Azure Data Factory apart from conventional ETL tools?
Ans:
Enterprise Readiness: Data integration at a Cloud Scale for a big data analytics.
Enterprise Data Readiness: There are 90+ connectors supported to get a data from any disparate sources to Azure cloud!
Code-Free Transformation: UI-driven mapping dataflows. Ability to run Code on the Any Azure Compute: Hands-on data transformations.
5. What are the major components of a Data Factory?
Ans:
- Pipelines.
- Activities.
- Dataset·
- Linked Service·
- Integration Runtime.
6. What are the different ways to execute pipelines in Azure Data Factory?
Ans:
- Debug mode can be helpful when trying out a pipeline code and acts as tool to test and troubleshoot a code.
- Manual Execution is what do by clicking on ‘Trigger now’ option in a pipeline. This is useful if want to run the pipelines on an ad-hoc basis.
7. What is the purpose of Linked services in Azure Data Factory?
Ans:
- 1.For Data Store representation, i.e., any storage system like the Azure Blob storage account, a file share, or Oracle DB/ SQL Server instance.
- 2.For a Compute representation, i.e., the underlying VM will execute activity defined in pipeline.
8. Explain Data Factory Integration Runtime?
Ans:
The Integration Runtime, or IR, is a compute infrastructure for Azure Data Factory pipelines. It is bridge between the activities and linked services. The linked Service or Activity references it and provides computing environment where activity is run directly or dispatched. This allows activity to be performed in the closest region to a target data stores or computing Services.
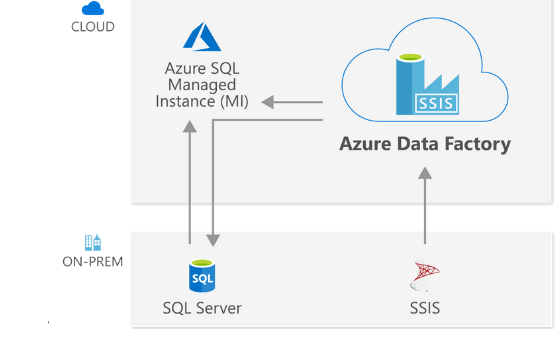
9. What is necessary in order to run an SSIS package in Data Factory?
Ans:
Must create the SSIS integration runtime and an SSISDB catalog hosted in Azure SQL server database or Azure SQL-managed instance before executing SSIS package.
10. What limits the number of Integration Runtimes, if any?
Ans:
Within the Data Factory, the default limit on any entities is set to be 5000, including the pipelines, data sets, triggers, linked services, Private Endpoints, and integration runtimes. If required, one can create the online support ticket to raise limit to a higher number.
11. What exactly are ARM templates in the Azure Data Factory? What is its purpose?
Ans:
An ARM template is the JSON (JavaScript Object Notation) file that explains the infrastructure and configuration for data factory pipeline, including pipeline activities, linked services, datasets, etc. The template will contain an essentially a same code as our pipeline.
12. How does deploy code to higher environments in Data Factory?
Ans:
- Create the feature branch that will store the code base.
- Create the pull request to merge code after sure to the Dev branch.
- Publish the developer’s code that creates the ARM templates.
13. Which three activities can run in Microsoft Azure Data Factory?
Ans:
- Data movement activities: As name suggests, these activities help to move data from one place to another.
- e.g., Copy Activity in a Data Factory copies data from the source to a sink data store.
- Data transformation activities: These activities are help transform the data while load it into data’s target or destination.
- e.g., Stored Procedure, U-SQL, Azure Functions, etc.
14. What are the two different computing environments that Data Factory supports for the transform activities?
Ans:
| Computing Environment | Description() | Use Cases() | |
| Azure Integration Runtime(IR) |
Default environment within Azure Data Factory. A serverless managed environment in the Azure cloud for data movement and transformation. |
– ETL processes – Data migration – Real-time analytics | |
| Azure-SSIS Integration Runtime | Enables the execution of SQL Server Integration Services (SSIS) packages within Azure Data Factory. | – Utilizing existing SSIS assets – Complex data transformations – Legacy system integration |
15. What steps involved in ETL process?
Ans:
Connect and Collect: Connect to a data source/s and move data to local and crowdsource data storage.
Data transformation using the computing services like HDInsight, Hadoop, Spark, etc.
Publish: To load data into the Azure data lake storage, Azure SQL data warehouse, Azure SQL databases, Azure Cosmos DB, etc.
16. If need to use the output by executing a query, which activity shall use?
Ans:
The output might be a singleton value or an array of characteristics that can be used in the copy data action that follows the subsequent copy data activity, or any transformation or control flow activity like ForEach activity.
17. Can parameters be sent to a pipeline run?
Ans:
Yes, parameters are the first-class, top-level concept in Data Factory. And can define parameters at a pipeline level and pass arguments as execute the pipeline run on demand or using the trigger.
18. Have used Execute Notebook activity in a Data Factory? How to pass parameters to notebook activity?
Ans:
Can execute a notebook activity to pass code to the databricks cluster. And can pass parameters to a notebook activity using baseParameters property. If the parameters are not defined/ specified in activity, default values from a notebook are executed.
19.What are some useful constructs available in Data Factory?
Ans:
parameter: Every activity within the pipeline can consume tparameter value passed to the pipeline and run with @parameter construct.
coalesce: can use the @coalesce construct in an expressions to handle the null values gracefully.
20. Can push code and have CI/CD (Continuous Integration and Continuous Delivery) in ADF?
Ans:
Data Factory fully supports the CI/CD of your data pipelines using the Azure DevOps and GitHub. This enables gradual development and delivery of ETL operations prior to releasing a final product. Load the raw data into the Azure Data Warehouse or Azure SQL Azure Data Lake once it has been processed into a business-ready consumable form, Azure Cosmos DB, or whichever analytics engine business uses can point to from business intelligence tools.
21. What are variables in Azure Data Factory?
Ans:
Variables in the Azure Data Factory pipeline provide functionality to hold values. They are used for the similar reason as use variables in any programming language and are available inside a pipeline.
22. What are mapping data flows?
Ans:
Mapping data flows are visually designed a data transformations in Azure Data Factory. Data flows allow the data engineers to develop a graphical data transformation logic without writing a code. The resulting data flows are executed as activities within the Azure Data Factory pipelines that use scaled-out Apache Spark clusters. Data flow activities can be operationalized using the Azure Data Factory scheduling, control flow, and monitoring capabilities.
23. What does copy activity in Azure Data Factory?
Ans:
Copy activity is one of the most popular and universally used activities in Azure data factory. It is used for ETL or Lift and Shift, where want to move the data from one data source to the another.
24. Can elaborate more on Copy activity?
Ans:
Read data from a source data store. (e.g., blob storage)
Perform following tasks on data:Serialization/deserialization Compression/decompression
Column mapping.
Write a data to destination data store or sink. (e.g., azure data lake).
25. What are the different activities used in Azure Data Factory?
Ans:
- Copy Data Activity to copy a data between datasets.
- ForEach Activity for looping.
- Get Metadata Activity that can provide a metadata about any data source.
- Set Variable Activity to define and initiate the variables within pipelines.
26. How can schedule pipeline?
Ans:
Can use the time window or scheduler trigger to schedule the pipeline. The trigger uses the wall-clock calendar schedule, which can schedule pipelines periodically or calendar-based recurrent patterns (for example, on Mondays at 6:00 PM and Thursdays at 9:00 PM).
27. When should choose Azure Data Factory?
Ans:
- When working with the big data, there is a need for data warehouse to be implemented; might require the cloud-based integration solution like ADF for the same.
- Not all team members are experienced in coding and may prefer a graphical tools to work with data.
28. How does one access data using other 90 dataset types in Data Factory?
Ans:
The mapping data flow feature allows the Azure SQL Database, Azure Synapse Analytics, delimited text files from Azure storage account or Azure Data Lake Storage Gen2, and Parquet files from a blob storage or Data Lake Storage Gen2 natively for a source and sink data source.
29. Distinguish difference between mapping and wrangling data flow (Power query activity)?
Ans:
Mapping data flows transform data at a scale without requiring coding.And can design a data transformation job in a data flow canvas by constructing a series of transformations. Start with the any number of source transformations followed by a data transformation steps. Complete the data flow with a sink to land results in a destination. It is excellent at mapping and transforming data with known and unknown schemas in a sinks and sources.
30. Does value be calculated for new column from the existing column from mapping in ADF?
Ans:
Can derive transformations in mapping data flow to generate the new column based on our desired logic. And can create a new derived column or update an existing one when developing the derived one. Enter ta name of the column are making in the Column textbox.

Get Hands-on Azure Data Factory Course from Top-Rated Instructors
Weekday / Weekend BatchesSee Batch Details31. How is lookup activity useful in Azure Data Factory?
Ans:
In ADF pipeline, the Lookup activity is commonly used for a configuration lookup purposes, and source dataset is available. Moreover, it retrieves a data from the source dataset and then sends it as activity output. Generally, the output of lookup activity is further used in pipeline for making decisions or presenting any configuration as a result.
32. Explain Get Metadata activity in Azure Data Factory.
Ans:
The Get Metadata activity is used to retrieve a metadata of any data in Azure Data Factory or a Synapse pipeline. And can use the output from a Get Metadata activity in conditional expressions to perform validation or consume a metadata in subsequent activities.
33. How does debug an ADF pipeline?
Ans:
Debugging is one of the crucial aspects of any coding-related activity needed to be testa code for any issues it might have. It also provides the option to debug pipeline without executing it.
34. What is the breakpoint in the ADF pipeline?
Ans:
To understand better, for example, you are using three activities in the pipeline, and now want to debug up to a second activity only. Can do this by placing breakpoint at a second activity. To add the breakpoint, click circle present at a top of activity.
35. What is the use of the ADF Service?
Ans:
ADF primarily organizes a data copying between relational and non-relational data sources stored locally in the data centers or the cloud. Moreover can use ADF Service to transform an ingested data to fulfill business requirements. In the most Big Data solutions, ADF Service is used as ETL or ELT tool for data ingestion.
36. Why do we need Cloud?
Ans:
The data source is a source or destination system that comprises a data intended to be utilized or executed. The data type can be binary, text, CSV, JSON, image files, video, audio, or proper database. Examples of data sources include the Azure data lake storage, azure blob storage, or any other database like MySQL DB, Azure SQL database, Postgres, etc.
37. Does any difficulties faced while getting data from on-premises to Azure cloud using Data Factory?
Ans:
One of the significant challenges face while migrating from on-prem to the cloud is throughput and speed. When try to copy a data using Copy activity from on-prem, the process rate could be faster, and hence need to get desired throughput.
38. How does one copy multiple sheet data from an Excel file?
Ans:
When using the Excel connector within a data factory, must provide a sheet name from which must load data. This approach is nuanced when have to deal with a single or handful of sheets of data, but when have lots of sheets (say 10+), this may become tedious task as have to change hard-coded sheet name every time!
39. Does possible to have nested looping in Azure Data Factory?
Ans:
There is no direct support for a nested looping in data factory for any looping activity (for each / until). However, can use one for each/until loop activity which will contain execute pipeline activity that can have loop activity. This way, when call the looping activity, it will indirectly call the another loop activity, and will be able to achieve a nested looping.
40. How do you copy multiple tables from one datastore to another datastore?
Ans:
- Maintain the lookup table/ file containing a list of tables and their source, which needs to be copied.
- Then, can use the lookup activity and every loop activity to scan through the list.
41. What are performance-tuning techniques for Mapping Data Flow activity?
Ans:
- should leverage the partitioning in the source, sink, or transformation whenever possible. Microsoft, however, recommends using default partition (size 128 MB) selected by Data Factory as it intelligently chooses one based on the pipeline configuration.
- Still, one should try out a different partitions and see if can have improved performance.
42. What are the limitations of ADF?
Ans:
Cannot have nested looping activities in a data factory, and must use some workaround if have that sort of structure in a pipeline. All looping activities are come under this: If, Foreach, switch, and until activities.
The lookup activity can retrieve the only 5000 rows at a time and not more than that. Again, need to use some other loop activity along with the SQL with the limit to achieve this sort of structure in a pipeline.
43. How does one send email notifications on pipeline failure?
Ans:
Using the Logic Apps with Web/Webhook activity. Configure the logic app that, upon getting an HTTP request, can send an email to required set of people for failure. In pipeline, configure a failure option to hit the URL generated by a logic app.
44. How can integrate Data Factory with Machine learning data?
Ans:
Can train and retrain the model on the machine learning data from a pipelines and publish it as web service.
45. What does Azure SQL database? Can integrate it with Data Factory?
Ans:
Part of a Azure SQL family, Azure SQL Database is always up-to-date, fully managed relational database service built for a cloud for storing data. Using the Azure data factory, can easily design data pipelines to read and write to the SQL DB.
46. Can host SQL Server instances on Azure?
Ans:
Azure SQL Managed Instance is intelligent, scalable cloud database service that combines a broadest SQL Server instance or SQL Server database engine compatibility with all benefits of a fully managed and evergreen platform as a service.
47. What is Azure Data Lake Analytics?
Ans:
Azure Data Lake Analytics is a on-demand analytics job service that simplifies a storing data and processing big data.
48. How does one combine or merge several rows into a one row in ADF?
Ans:
In Azure Data Factory (ADF), can merge or combine the several rows into the single row using the “Aggregate” transformation.
49. How does one copy data as per file size in ADF?
Ans:
Can copy data based on a file size by using the “FileFilter” property in Azure Data Factory. This property allows to specify a file pattern to filter the files based on size.
50. How does insert folder name and file count from blob into SQL table?
Ans:
- Create ADF pipeline with a “Get Metadata” activity to retrieve a folder and file details from the blob storage.
- Add a “ForEach” activity to loop through every folder in the blob storage.
- Inside the “ForEach” activity, add a “Get Metadata” activity to retrieve a file count for each folder.

Gain In-Depth Knowledge on Azure Data Factory Training from Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
51. Why does it require Azure Data Factory?
Ans:
Azure Data Factory is the valuable tool that helps organizations simplify moving and transforming a data between the various sources and destinations, including on-premises data sources, cloud-based data stores, and software-as-a-service (SaaS) applications. It also provides the flexible and scalable platform for managing data pipelines, allowing the users to create, schedule, and monitor complex data workflows easily.
52. Explain how ADF integrates with the other Azure services, such as Azure Data Lake storage, Azure Blob Storage, and Azure SQL Database?
Ans:
Azure Data Factory (ADF) can integrate with the other Azure services like Azure Data Lake Storage, Azure Blob Storage, and Azure SQL Database by using linked services. Linked services provide a way to specify a account name and credentials for first two data sources to establish the secure connection.
53. What does Azure Data Factory’s ARM Templates do? What does they serve?
Ans:
The infrastructure and setup for a data factory pipeline, such as linked services, pipeline activities, datasets, etc, are defined in ARM template, which is a JSON (JavaScript Object Notation) file. The template’s code will be nearly identical to that of the pipeline. When need to move our pipeline code from a Development to a higher environment, such as Production or Staging, after certain that the code is functioning properly, ARM templates come in handy.
54. What steps constitute an ETL process?
Ans:
Integrate and Collect: Attach to data source(s) and transfer a data to crowdsourced and local data storage. Publish: To upload a data to Azure Cosmos DB, Azure SQL databases, Azure Data Lake storage, etc. Monitor: Pipeline monitoring for Azure Data Factory is built-in and supported by the Azure Monitor, API, PowerShell, Azure Monitor logs, and health panels on the Azure portal.55. Which activity use if need to use the results from running a query?
Ans:
Look-up activity can be used to return the results of query execution or executable execution. The result can take the form of a singleton value, an array of characteristics, or any activity that acts as a transition or control flow, like the ForEach activity. The ensuing copy data action can make advantage of these outputs.
56. What do pipeline run parameters?
Ans:
In Data Factory, parameters are the first-class, top-level concept. When running a pipeline on demand or using a trigger, can plate thickness at the pipeline level and pass arguments.
57. When is Azure Data Factory the best option?
Ans:
- A data warehouse must be implemented when continuing to work with the big data; may need a cloud-based integrated platform like ADF for the same.
- Not all the team members have coding experience, and some might find it simpler to work with data using graphical tools.
58. What does “the breakpoint in ADF pipeline” refer to?
Ans:
For instance, let’s say have a pipeline with the three activities and want to focus on a debugging the second action only. By setting cut-off point at the second activity, can achieve this. And can press the circle at activity’s top to add a breakpoint.
59. What purpose does the ADF Service serve?
Ans:
The main function of ADF is to coordinate data copying among the numerous relational and non-relational sources of data that are hosted locally, in data centers, or cloud. Additionally, can use the ADF Service to transform the information that has been ingested to meet the business needs. ADF Service is utilized as ETL or ELT tool for loading data in majority of Big Data solutions.
60. Describe azure data factory’s data source.
Ans:
The system from which the data will be used or executed is referred to as a data source. Data can be in the binary, text, CSV, JSON, or any other format. It might be appropriate database, but it could also be image, video, or audio files.
61. How can move several tables from one datacenter to another?
Ans:
- Keep the lookup table or file that contains the sources and a list of the tables that need to be duplicated.
- After that, can scan the list using data retrieval activity and each loop activity.
- To copy the multiple tables to the target datastore, and can employ a copy activity or a mapping data flow inside for each loop activity.
62. Which assimilation runtime should employ when using Azure Data Factory to copy data from local SQL Server instance?
Ans:
In order to replicate data from an on-premises SQL Database using the Azure Data Factory, the self-hosted assimilation runtime should have been installed on the local system where the SQL Server instance is made available to the host.
63. What distinguishes Azure Data Factory from traditional ETL tools?
Ans:
- Enterprise Readiness: Big Data Analytics, Data Integration at a Cloud Scale.
- Enterprise Information Readiness: can get a data to the Azure cloud from more than 90 different sources.
- Code-Free Transformation: UI-driven dataflows for mapping.
64. What are the various pipeline execution methods available in Azure Data Factory?
Ans:
- Debug mode is helpful for testing and troubleshooting our code as well as for experimenting with pipeline code.
- In pipeline, selecting the “Trigger now” option initiates manual execution. If wish to run the pipelines on an as-needed basis, this is helpful.
65. What does Connected Services in Azure Data Factory serve?
Ans:
- For a representation of a data store, such as Oracle DB/ SQL Server instance, a file share, or Azure Blob storage account.
- The underlying VM will carry out activity specified in a pipeline for Compute representation.
66. What types of integration runtime supported by Azure data factory?
Ans:
- To duplicate a data among cloud data stores and send the activity to various computing services like SQL Server, Azure HDInsight, etc., use the Azure Integration Runtime.
- Self-Hosted Integration Runtime: Used for the copy operations between private network data stores and cloud data stores. Similar to the Azure Integration Runtime, self-hosted integration running time is software that is installed on a local computer or virtual machine by virtual network.
67. What is necessary for SSIS package to run in a Data Factory?
Ans:
Before can run an SSIS package, must first start creating the SSIS integration runtime and an SSISDB catalog hosted in Azure SQL server database or an Azure SQL-managed instance.
68. If there is a cap on quantity of Integration Runtimes, what does it?
Ans:
Data sets, Pipelines, linked services, triggers, integration runtimes, and private endpoints, all have the default limit of 5000 in data factory. If necessary, one can submit an online support ticket to increase a restriction to be higher number.
69. What is the anticipated length of time needed for integration?
Ans:
The Azure Data Factory’s integration runtime is the underlying computational architecture that makes it possible to implement the following data integration features across a variety of network topologies. Through the Azure interface, these functionalities are accessible.
70. How many times may integration be run through its iterations?
Ans:
The number of integration runtime instances that can exist within the data factory is not constrained in any manner. However, there is a limit on the number of a virtual machine cores that can be utilized by an integration runtime for execution of SSIS packages for every subscription.
71. Where does additional information on blob storage offered by Azure?
Ans:
Large volumes of data from Azure Objects, such text or binary data, may be preserved by using the service known as Blob Storage. Using the Blob Storage, have the option of retaining the confidentiality of data associated with the application or making it accessible to general public.
72. Where do you locate the step-by-step instructions for creating Azure Functions?
Ans:
With the Azure Functions, building cloud-based applications requires only the few lines of code rather than the traditional tens or hundreds of lines. Because of this functionality, able to choose the programming language that best suits needs. Pricing is calculated on a per-user basis because the only expense is the time the code is actually performed.
73. How does one access data by using t other 80 dataset types in Data Factory?
Ans:
Existing options for a sinks and sources for Mapping Data Flow include Azure SQL Data Warehouse and Azure SQL Database, as well as specified text files from Azure Blob storage or Azure Data Lake Storage Gen2 and Parquet files from either Blob storage or a Data Lake Storage Gen2.
74. What prerequisites Data Factory SSIS execution require?
Ans:
Either Azure SQL Managed Instance or Azure SQL Database must be used as hosting location for SSIS IR and SSISDB catalogue.
75. What are “Datasets” in ADF framework?
Ans:
The pipeline activities will make use of inputs and outputs that are contained in a dataset, which contains those activities. A connected data store can be any kind of the file, folder, document, or anything else imaginable; datasets frequently represent an organization of information within such a store.
76. What is Azure Databricks?
Ans:
Azure Databricks is analytics platform that is built on the Apache Spark and has been fine-tuned for Azure. It is fast, simple, and can be used in the collaboration with others. Apache Spark was developed in the collaboration with its creators. Azure Databricks is the service that combines the most beneficial aspects of Databricks and Azure to enable a rapid deployment. This service is designed to assist the customers in accelerating innovation.
77. What is Azure SQL Data Warehouse?
Ans:
It is the vast storehouse of knowledge that may be mined for useful insights and utilized to guide the management decisions. Using this strategy, the data from numerous different databases that either located in different physical places or spread across a network can be aggregated into the single repository.
78. Why does Auto Resolve Integration ?
Ans:
AutoResolveIntegration: The runtime environment will make every attempt to perform tasks in the same physical location as the sink data source, or as close to it as possible. Productivity may be increased by doing the same.
79. What is Azure Data Factory’s connected service, and how does it work?
Ans:
In Azure Data Factory, connection method that is utilized to join external source is referred to as “connected service,” and the phrase is used interchangeably. It not only serves as a connection string, but it also saves user validation data.
80. What is the “breakpoint” in conjunction with ADF pipeline?
Ans:
The commencement of testing step of the pipeline is indicated by placement of a debugging breakpoint. Before committing to the particular action, can make use of breakpoints to check and make sure that pipeline is operating as it should.
81. How does Data Factory support Hadoop and Spark computing environments when it comes to carrying out transform operations
Ans:
The On-Demand Computing Environment provided by I ADF is the solution that is ready to use and includes the full management. A cluster is created for computation to carry out transformation, and this cluster is afterwards removed once transformation has been carried out.
Bring a Own Equipment: If already possess the computer gear and software required to deliver the services on-premises,and can use ADF to manage computing environment in this situation.
82. Which activity should be performed if goal is to make use of the results are acquired by performing a query?
Ans:
A lookup operation can be used to acquire a result of a query or a stored process. The end result might be single value or an array of attributes that can be utilized in ForEach activity or some other control flow or transformation function. Either way, it could be the single value.
83. Is it feasible to interface with the pipeline by passing data in the form of parameters?
Ans:
In Data Factory, parameter is handled just like the any other fully-fledged top-level notion would be. The defining of a parameters at the pipeline level enables a passage of arguments during on-demand or triggered execution of a pipeline.
84. What is a “data flow map”?
Ans:
Visual data transformations are referred to as a mapping data flows when working in Azure Data Factory. Because of a data flows, data engineers can construct logic for altering data without having to write any code at all. After data flows have been generated, they are implemented as activities inside of scaled-out Apache Spark clusters that are contained within the Azure Data Factory pipelines.
85. How does Data Flow Debug work?
Ans:
Data flow debugging in Azure Data Factory and Synapse Analytics is achievable while concurrently observing a real-time change of the data shape. The versatility of debug session is beneficial to both Data Flow design sessions as well as pipeline debug execution.
86. What method to address null values in output of an activity?
Ans:
The @coalesce construct in an expressions can be used to handle the null values effectively.
87. Is it possible for activity within a pipeline to utilize arguments passed to a pipeline run?
Ans:
Yes, it is possible for activity within a pipeline to utilize arguments passed to a pipeline run. This allows activity to access and use values of the arguments during its execution, providing a flexibility and customization within pipeline workflow.
88. What way does write attributes in cosmos DB in same order as specified in a sink in ADF data flow?
Ans:
Order is not guaranteed in the Cosmos DB since each document is saved as a JSON object, which is an unordered collection of name/value pairs.
89. What is the best way to parameterize column name in dataflow?
Ans:
Similar to the other characteristics, arguments can be sent to columns. Customers can utilize derived columns
- $ColumnNameParam = toString(byName($myColumnNameParamInData))
90. Is activity output property be consumed in the another activity?
Ans:
Yes. An activity output can be consumed in the subsequent activity with the @activity construct.
91.What is Azure Table Storage?
Ans:
Azure Table Storage is the service that helps users to store structured data ina cloud and also provides a Keystore with schemas designed. It is swift and effective for a modern-day applications.
92. Does need coding knowledge for Azure Data Factory?
Ans:
No, coding knowledge is not required for a Azure Data Factory. With Azure Data Factory, can leverage its 90 built-in connectors and mapping data flow activities to transform a data without the need for programming skills or knowledge of Spark clusters. It enables to create a workflows efficiently and quickly, simplifying a data integration and transformation process.
93. What has changed from private preview to limited public preview regarding data flows?
Ans:
- There is no need to bring the own Azure Databricks clusters now.
- Data Factory will handle the cluster creation and deletion.
- can still use Data Lake Storage Gen 2 and Blob Storage to store files. may use the appropriate linked services. may also use the associated services that are appropriate for the services of the storage engines.
94. Explain two levels of security in ADLS Gen2?
Ans:
Role-based Access Control :It includes the built-in Azure rules such as reader, contributor, owner or customer roles. It is indicated for a two reasons. The first is who can manage service themselves, and the second is to providethe users with built-in data mining tools.
Access Control Lists :Azure Data Lake Storage specifies exactly which data objects are users can read, write, or execute.
95. What is Blob Storage in Azure?
Ans:
Blob storage is specially designed for a storing a huge amount of unstructured data like text, images, binary data. It helps make data available public globally. The most common use of a blob storage is to stream audios and videos, store data for a backup, analysis etc. And can also work with data lakes to perform analytics using the blob storage.
96. Does have trigger error notification email in Azure Data Factory?
Ans:
Can trigger email notifications using logic app and Web activity. Can define the workflow in logic app and then can provide a Logic App URL in Web activity with other details. can send the dynamic message also using the Web activity after failure or completion of any event in a Data Factory Pipeline.
97. How many Chart of Accounts can company code have?
Ans:
A Chart of Accounts in SAP is the list of general ledger (G/L) accounts that are used by a one or several company codes. It contains all accounts that are used for posting within company code.
98. What does options in SAP for Fiscal years?
Ans:
Fiscal year in SAP is a way financial data is stored in system. In SAP, and have 12 periods and 4special periods. These periods are stored in the fiscal year variant that is:
a) Calendar Year: From Jan-Dec, April-March. b) Year dependent fiscal year.99. What does ‘year shift’ in SAP calendar?
Ans:
SAP system does not know what is broken a fiscal year e.g April 2012 to March 2013 and only understand a calendar year. If, for any business, the fiscal year is not a calendar year but combination of the different months of two different calendar year and then one of calendar year has to classified as fiscal year for SAP and the month falling in the another year has to be adjusted into fiscal year by shifting the year by using sign -1 or +1. This shift in year is known as ‘year shift’.
100. What does application areas that use validation and substitutions?
Ans:
- a) FI- Financial accounting
- b) CO-Cost accounting
- c) AM-Asset accounting
- d) GL-Special purpose ledger
- e) CS-Consolidation.