Last updated on 18th Apr 2024| 4463
Amazon DynamoDB, an AWS-managed NoSQL database service, provides seamless scalability, high performance, and low latency for applications needing fast and consistent performance at any scale. It is tailored to handle substantial data volumes and can dynamically adjust its capacity based on demand, making it suitable for various applications, including web and mobile apps, gaming, and IoT. DynamoDB’s features, such as automatic data replication across multiple Availability Zones for enhanced availability and integrated security measures, streamline database management, enabling developers to concentrate on application development rather than infrastructure maintenance.
1. What is Amazon DynamoDB?
Ans:
Amazon Web Services (AWS) provides a fully managed NoSQL database solution called Amazon DynamoDB, which offers smooth scalability and quick, predictable performance. Because it supports both document and key-value data types, it can be used for a wide range of application requirements. With no need for human intervention, DynamoDB can automatically scale up or down in response to demand, even with massive data volumes and high request rates.
2. What are the critical features of DynamoDB?
Ans:
AWS offers a fully managed NoSQL database service called Amazon DynamoDB, which is intended to offer excellent performance and scalability with no administrative burden. One of its primary characteristics is that it is fully managed, meaning that AWS takes care of installing, configuring, and maintaining databases as well as dynamically scaling to meet fluctuating demands. For both read and write operations, DynamoDB provides single-digit millisecond latency, guaranteeing quick and reliable performance even in situations with heavy traffic.
3. How does DynamoDB achieve scalability?
Ans:
- Amazon DynamoDB is scalable thanks to a number of important techniques that guarantee its capacity to effectively manage a wide range of workloads.
- The service distributes data and request loads among several servers and partitions using horizontal scalability to handle growing traffic.
- Its fundamental architecture makes this possible by automatically dividing data among several nodes as the dataset expands, guaranteeing that read and write operations can be completed without experiencing a decrease in speed.
4. What is the difference between provisioned throughput and on-demand capacity modes in DynamoDB?
Ans:
| Feature | Provisioned Throughput | On-Demand Capacity |
|---|---|---|
| Usage Model | Fixed capacity provisioned in advance, suitable for predictable workloads | Pay-per-request model, ideal for unpredictable workloads or when starting with unknown usage patterns |
| Cost Structure | Pay for provisioned capacity regardless of usage | Pay per request and data storage, no upfront commitments |
| Scaling | Manual scaling required to adjust provisioned capacity | Automatically scales up or down based on actual usage |
| Performance Guarantees | Offers consistent performance regardless of traffic spikes or fluctuations | Performance may vary based on usage patterns, no guaranteed minimum throughput |
5. Explain DynamoDB’s data consistency models.
Ans:
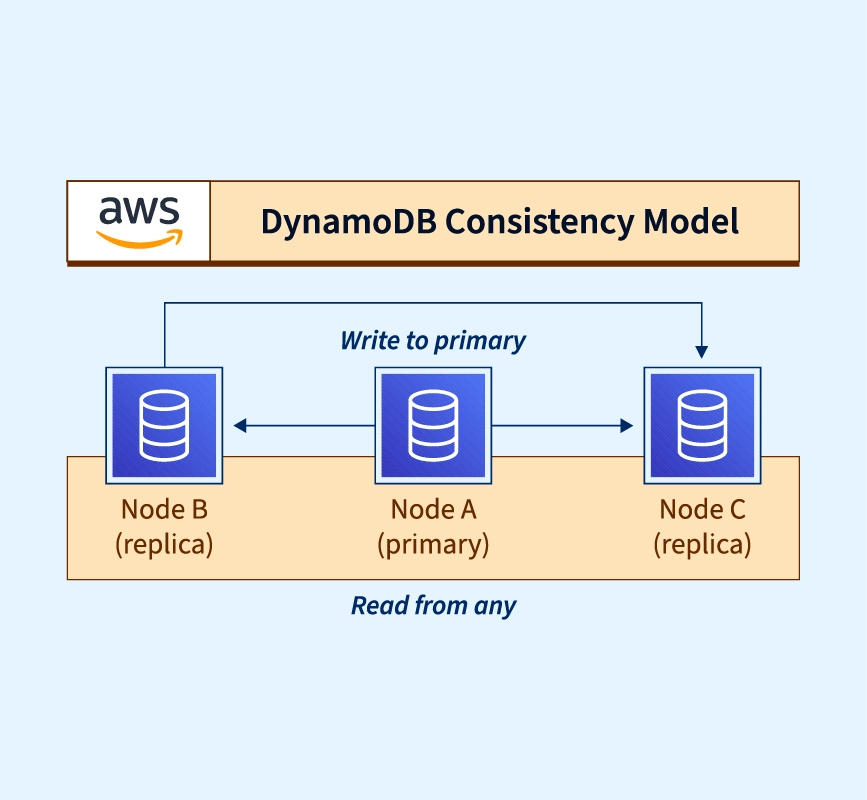
In DynamoDB, the default model for read operations is eventual consistency. Because updates haven’t reached every node yet, DynamoDB may return data that is a little stale when you conduct a read operation under this model. However, because it permits more flexible replication and data delivery, this approach offers high availability and low latency.
6. How does DynamoDB handle indexes?
Ans:
DynamoDB supports global secondary indexes (GSI) and local secondary indexes (LSI). GSIs allow querying on non-primary critical attributes with eventual or strong consistency. In contrast, LSIs allow querying on non-primary vital attributes only within the same partition as the base table.
7. What is the importance of partition keys in DynamoDB?
Ans:
Partition keys are essential for performance and data distribution in Amazon DynamoDB. They control the distribution of data among several partitions, which serve as DynamoDB’s fundamental building blocks for performance and storage expansion. A partition key and, if desired, a sort key are used to uniquely identify each entry in a table. To identify which partition the data will be kept in, the value of the partition key is hashed.
8. How does DynamoDB handle data backups and restores?
Ans:
A wide range of intuitive features that guarantee data protection and recovery are used by Amazon DynamoDB to manage data backups and restores. Users can generate complete backups of their tables whenever they want thanks to the service’s on-demand backup feature. This feature makes sure you can take a snapshot of your data whenever you need it and store it for as long as you’d like.
9. Explain DynamoDB’s capacity planning and auto-scaling features.
Ans:
- The capacity planning and auto-scaling capabilities of DynamoDB are intended to assist in controlling database performance and affordably managing a range of workloads.
- Choosing the right read and write throughput capacity in DynamoDB capacity planning entails meeting the needs of the application.
- You can regulate throughput and manage expenses based on projected traffic levels by specifying the required read and write capacity units in the provided capacity mode for workloads that are predictable.
- Applications with consistent and well-understood traffic patterns are best suited for this mode.
10. How does DynamoDB ensure data durability and availability?
Ans:
Using multiple important techniques, Amazon DynamoDB guarantees data availability and durability. Across several Availability Zones in a region, data is automatically replicated using multi-AZ replication. With this, high availability and resilience are maintained even in the event of an Availability Zone failure, since data is still available from other zones. Along with point-in-time recovery which lets you restore data to any moment in the previous 35 days automatic backups and data corruption prevention are other features offered by DynamoDB.
11. How does DynamoDB support the different types of primary keys?
Ans:
DynamoDB supports two types of primary keys: partition keys and composite keys. Partition keys are single attributes uniquely identifying items in a table and determining the partition in which the item is stored. Composite keys consist of a partition key and a sort key (also known as a range key), allowing multiple items with the same partition key to be stored in the same partition while maintaining uniqueness.
12. Explain the concept of throughput capacity in DynamoDB.
Ans:
Throughput capacity in DynamoDB refers to the provisioned read and write capacity units (RCUs and WCUs) allocated to a table. RCUs represent the number of strongly consistent reads per second, while WCUs represent the number of writes per second. DynamoDB provisions throughput capacity based on these units, which determines how much data can be read from or written to the table per second.
13. How does DynamoDB handle schema changes and evolving data models?
Ans:
- Dynamic Schema
- Attribute Updates
- Secondary Indexes
- Provisioned Throughput Adjustment
- Data Migration
- Schema Evolution Tools
- Zero-Downtime
14. What is the difference between a scan and a query operation in DynamoDB?
Ans:
A scan operation in DynamoDB reads every item in a table, filtering results based on specified conditions. It’s suitable for retrieving all items or large subsets of data but can be inefficient for large tables due to the need to examine every item. On the other hand, a query operation retrieves items based on primary vital attributes or secondary indexes, making it more efficient for targeted retrieval of specific items.
15. How does DynamoDB handle transactions?
Ans:
- Multi-item Support: Handles transactions across multiple items, tables, and partitions.
- Transactional Read/Write: Guarantees atomicity for both read and write operations.
- Conditional Checks: Allows for conditional writes to ensure data consistency.
- Isolation: Changes remain isolated and not visible until fully committed.
- Idempotency: Ensures the same transaction executed multiple times produces the same result.
16. Explain DynamoDB’s global tables feature.
Using multiple important techniques, Amazon DynamoDB guarantees data availability and durability. Across several Availability Zones in a region, data is automatically replicated using multi-AZ replication. With this, high availability and resilience are maintained even in the event of an Availability Zone failure, since data is still available from other zones. Along with point-in-time recovery—which lets you restore data to any moment in the previous 35 days—automatic backups and data corruption prevention are other features offered by DynamoDB.
17. What is the significance of DynamoDB Streams?
Ans:
DynamoDB Streams is a real-time feature that captures changes to items in a table, allowing you to react to database events and trigger actions asynchronously. It provides:
- A time-ordered sequence of item-level changes.
- Enabling use cases such as real-time data processing.
- Change tracking.
- Data synchronization across multiple services or systems.
18. How does DynamoDB handle conflicts in concurrent write operations?
Ans:
DynamoDB uses optimistic concurrency control to handle conflicts in concurrent write operations. When multiple clients attempt to modify the same item simultaneously, DynamoDB compares the client’s expected values with the current values in the database. Suppose a mismatch indicates that another client has modified the item. In that case, DynamoDB rejects the write operation and returns a concurrency exception, allowing clients to retry or handle the conflict accordingly.
19. Explain the concept of item collections in DynamoDB.
Ans:
- Definition
- Primary Key Structure
- Group of Related Items
- Efficient Queries
- Global Secondary Indexes (GSI)
- Storage Limit
- Use Case
20. How does DynamoDB handle access control and authentication?
Ans:
DynamoDB integrates with AWS Identity and Access Management (IAM) for access control and authentication. IAM allows you to define fine-grained access policies to control who can access DynamoDB resources and what actions they can perform. You can restrict access at the API level, table level, or even down to the level of individual items using IAM policies and roles.
21. What are the different types of secondary indexes in DynamoDB, and how do they differ?
Ans:
DynamoDB supports two secondary indexes: global secondary indexes (GSI) and local secondary indexes (LSI). GSIs allow querying on non-primary critical attributes with eventual or strong consistency and can span multiple partitions. In contrast, LSIs only allow querying on non-primary critical characteristics within the same partition as the base table and have the same partition key as the base table.
22. How does DynamoDB handle the pagination of query results?
Ans:
- Depending on the Limit parameter included in the query or scan request, DynamoDB paginates query results by returning a maximum amount of items per response.
- A subset of the results together with a LastEvaluatedKey will be returned if the result set exceeds the given limit or the maximum size that DynamoDB permits per request (1 MB of data).
- By using this key as the ExclusiveStartKey in a subsequent request, you can receive the next set of results by knowing where the last response ended.
23. Explain the concepts of read and write capacity units (RCUs and WCUs) in DynamoDB.
Ans:
Read capacity units (RCUs) represent the number of strongly consistent reads per second or twice that of eventually consistent reads per second. In contrast, write capacity units (WCUs) represent the number of writes per second. RCUs and WCUs are used to provision throughput capacity for a DynamoDB table and determine how much data can be read from or written to the table per second.
24. How does DynamoDB handle data encryption at rest and in transit?
Ans:
DynamoDB automatically encrypts data at rest using AWS Key Management Service (KMS), ensuring that data is encrypted before it’s written to disk and decrypted when read from disk. Additionally, DynamoDB supports encrypted connections using Transport Layer Security (TLS) to encrypt data in transit between clients and the DynamoDB service endpoint, providing end-to-end encryption for data in motion.
25. What are the best practices for designing efficient DynamoDB data models?
Ans:
Some best practices for designing efficient DynamoDB data models include choosing appropriate partition keys to evenly distribute workload, using composite keys to support rich query patterns, leveraging secondary indexes for efficient querying, denormalizing data to minimize the number of queries, and optimizing access patterns based on application requirements.
26. Explain DynamoDB’s Time to Live (TTL) feature and its use cases.
Ans:
- Users can define expiration dates for individual objects in a table using DynamoDB’s Time to Live (TTL) functionality, which enables items to be automatically deleted when they run out of time.
- To utilize TTL, you include a unique characteristic in your database that has a timestamp (in Unix epoch time format) that indicates the appropriate expiration date of an item.
- During DynamoDB’s background cleanup procedure, the expired item is immediately deleted once the current time exceeds the timestamp.
- This elimination contributes to effective storage management without consuming any write throughput.
27. How does DynamoDB handle backups and point-in-time recovery?
Ans:
Users can always create full backups of your DynamoDB tables using on-demand backups. When capturing a table’s state for long-term storage, compliance, or data migration, this functionality comes in handy. Because only changes made since the last backup are preserved in these incremental backups, storage is optimized and processing times are sped up. These backups can be kept forever and creating them has no effect on table performance or availability.
28. What are the different ways to interact with DynamoDB programmatically?
Ans:
- Software development kits, or SDKs: are available from AWS for a number of well-known programming languages, including Java, Python (Boto3), JavaScript (Node.js),.NET, Ruby, PHP, Go, and others.
- AWS Command Line Interface (CLI): Using terminal commands, customers can communicate with DynamoDB through the AWS CLI.
- AWS Management Console: To communicate with DynamoDB, use the graphical user interface (GUI) offered by the web-based AWS Management Console.
- AWS SDK for JavaScript in the Browser: If you’re developing web apps, you can also use the AWS SDK for JavaScript to communicate with DynamoDB straight from the browser.
- AWS Amplify: For front-end developers creating mobile or web applications, AWS Amplify offers simple-to-use tools for interacting with DynamoDB.
29. Explain DynamoDB’s adaptive capacity feature and how it works.
Ans:
DynamoDB’s adaptive capacity is a feature that automatically adjusts provisioned throughput to manage traffic spikes and ensure performance stability. The goal of adaptive capacity is to help avoid performance bottlenecks caused by uneven data access patterns.
Here’s how it works:
- Cost Efficiency: By dynamically adjusting the allocation of capacity units based on real-time usage, adaptive capacity ensures cost efficiency, as you do not have to over-provision capacity just to handle potential traffic spikes.
- Hot Partitions: DynamoDB divides tables into partitions and distributes data across them.
- Automatic Adjustment: When DynamoDB detects a partition is under heavy load (hot), adaptive capacity kicks in and redistributes unused capacity from less utilized partitions to the heavily accessed partition.
- Granular Control: Adaptive capacity ensures that capacity is allocated at a granular level, allowing even specific keys within a partition to receive more throughput without over-allocating resources for the entire table.
30. What are some everyday use cases for DynamoDB?
Ans:
Because of its excellent performance, scalability, and flexible data model, DynamoDB is adaptable and can handle a variety of common use cases. In order to efficiently handle expanding user bases, it is frequently used in web and mobile apps to manage user profiles, authentication tokens, and session data. DynamoDB is a great tool for processing and storing massive amounts of data from a variety of sources, including web apps and Internet of Things devices, for real-time analytics and recording.
31. What are the main differences between DynamoDB and traditional relational databases?
Ans:
There are notable architectural and use case distinctions between DynamoDB and conventional relational databases. DynamoDB is a NoSQL database that is ideal for high-performance applications that use dynamic data structures because of its flexible schema and horizontally scalable architecture. DynamoDB offers a schema-less approach that accepts a variety of properties and data types, in contrast to relational databases, which depend on a set schema with pre-established tables and relationships.
32. How does DynamoDB handle capacity planning for read-heavy and write-heavy workloads?
Ans:
Users may define and manage throughput individually for read and write operations using DynamoDB, which helps with capacity planning for workloads that are heavy on reading and writing. You can set the number of Write Capacity Units (WCUs) and Read Capacity Units (RCUs) in provisioned capacity mode based on the demands of your business. You can assign additional RCUs to read-heavy apps in order to effectively manage a large number of read requests.
33. Explain DynamoDB’s billing model and how costs are calculated.
Ans:
DynamoDB’s billing model is based on provisioned throughput capacity, storage usage, and additional features such as backups and global tables. You are charged for the provisioned RCUs and WCUs and the amount of data stored in DynamoDB tables, indexes, and backups. There are additional charges for features such as data transfer, global tables replication, and PITR.
34. What are the different types of consistency models supported by DynamoDB, and when should each be used?
DynamoDB supports two consistency models: eventual consistency and firm consistency. Eventual consistency is suitable for cases where the most recent data is not critical, such as caching or analytics. Strong consistency should be used for cases where immediate and accurate data access is required, such as financial transactions or real-time bidding systems.
35. Explain DynamoDB Accelerator (DAX) and its benefits.
Ans:
The purpose of DynamoDB Accelerator (DAX), an entirely managed in-memory caching solution, is to improve DynamoDB table performance. Through the provision of a high-performance, highly accessible cache, DAX dramatically shortens database query response times.
Advantages of DAX consist of:
- Low Latency: When compared to conventional DynamoDB reads, DAX’s microsecond response rates for cached data result in substantially faster read operations.
- Increased Throughput: DAX facilitates the efficient handling of increased read traffic by lowering the amount of direct queries to DynamoDB, hence increasing throughput overall.
- Automated Scaling: DAX adapts automatically to workload fluctuations, guaranteeing steady performance without the need for human intervention.
- Ease of Integration: It offers a simple performance improvement with minimal application code changes and connects effortlessly with existing DynamoDB tables.
36. How does DynamoDB handle hot partitions, and what are the consequences of hot partitioning?
Ans:
Hot partitions occur when a disproportionate amount of traffic is directed to a single partition, leading to uneven workload distribution and potential throughput bottlenecks. DynamoDB mitigates hot partitioning by automatically partitioning data across multiple partitions based on the partition key, but poorly chosen partition keys can still lead to hot partitions and performance issues.
37. Explain DynamoDB’s capacity reservation feature and its benefits.
Ans:
User can pre-purchase read and write capacity units for a particular table or global secondary index for a predetermined amount of time, usually one or three years, using DynamoDB’s capacity reservation function.
There are various advantages to this feature:
- Cost Savings: Compared to on-demand pricing, you may frequently save a lot of money by booking capacity in advance.
- Reliable Performance: Applications with regular and heavy traffic patterns benefit greatly from capacity reservations, which guarantee that the provided throughput will be available when needed.
- Budget Management: Since the cost of booked capacity is fixed for the duration of the reservation, it helps you better forecast and control your spending.
38. What are the different access patterns supported by DynamoDB, and how should tables be designed to optimize performance for each pattern?
Ans:
DynamoDB supports access patterns, including point queries, range queries, scans, and batch operations. Tables should be designed with access patterns in mind, optimizing partition keys, sort keys, and secondary indexes to efficiently support the required queries while minimizing read and write operations and maximizing throughput capacity.
39. How does DynamoDB handle conflicts in distributed transactions?
Ans:
DynamoDB uses conditional writes and optimistic concurrency control to handle conflicts in distributed transactions. When multiple clients attempt to modify the same item simultaneously, DynamoDB checks for disputes based on conditional expressions and version numbers, ensuring data integrity and consistency across distributed transactions.
40. What are the different methods for backing up and restoring DynamoDB tables, and when should each method be used?
Ans:
DynamoDB offers continuous backups and point-in-time recovery (PITR) to back up and restore tables. Continuous backups provide full backups of tables and can be used to restore tables to any point within the retention period. At the same time, PITR allows you to restore tables to specific points in time, providing additional granularity for data recovery and rollback operations.

Get JOB SAS BI Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Explain DynamoDB’s support for atomic counters and its use cases.
Ans:
DynamoDB supports atomic counters, allowing you to increment or decrement numeric attributes atomically without needing conditional writes or transactions. Nuclear counters help implement features such as counters, vote tallies, and performance metrics, where you need to update numeric values concurrently without risking race conditions or conflicts.
42. What is the significance of DynamoDB’s single-digit millisecond latency, and how is it achieved?
Ans:
- TLS Encryption: Data is safely transported over the network thanks to DynamoDB’s usage of Transport Layer Security (TLS) to encrypt data as it moves between your application and DynamoDB.
- Security against Interception: TLS encryption shields private data from prying eyes and manipulators by preventing illegal parties from reading or intercepting it while it’s in transit.
- Compliance: DynamoDB assists enterprises in adhering to data security-related regulations and compliance standards, including GDPR and HIPAA, by encrypting data while it is in transit.
- Data Integrity: By preventing data from being changed or modified while in transit, encryption guarantees data integrity.
- Automatic Encryption: Security management is made easier by the encryption process’s automatic nature, which eliminates the need for people to configure it further.
Multiple crucial mechanisms work together to produce this high-speed performance:
- DynamoDB: uses in-memory caching to speed up data retrieval by minimizing the number of disk accesses that are required.
- Distributed design: To balance the load and reduce bottlenecks, it employs a distributed design with several partitions and nodes that handle various data segments.
- Effective Data Access Patterns: By efficiently indexing and splitting data, DynamoDB improves read and write speed by optimizing data access patterns.
- Automatic Scaling: The service adapts automatically to changing traffic patterns and workloads, guaranteeing steady performance even during surges in volume of traffic.
43. Explain the concepts of item size limits and partition throughput limits in DynamoDB.
Ans:
DynamoDB imposes limits on the size of individual items and the throughput capacity of separate partitions. The maximum length of an item is 400 KB, including attribute names and values. In contrast, the maximum throughput capacity of a partition is determined by the provisioned read and write capacity units (RCUs and WCUs) allocated to the table.
44. What are the different strategies for optimizing DynamoDB performance and minimizing costs?
Ans:
Strategies for optimizing DynamoDB performance and minimizing costs include:
- Users can choose appropriate partition keys to distribute the workload evenly.
- Optimizing item sizes to reduce read and write costs.
- We leverage caching mechanisms such as DAX and monitor and adjust provisioned throughput capacity based on workload patterns.
45. Explain DynamoDB’s support for time-to-live (TTL) attributes and their use cases.
Ans:
The single-digit millisecond latency of DynamoDB is noteworthy because it guarantees remarkably quick and reliable response times for read and write operations, which are essential for high-performance applications. Multiple design optimizations are used to attain this low latency. DynamoDB speeds up data storage and retrieval by utilizing effective indexing techniques and data access patterns. By sending queries to the closest server and distributing loads among several servers and locations, its distributed architecture lowers latency. Automatic scaling, which modifies throughput capacity in real-time to manage fluctuating workloads without sacrificing performance, is another advantage of the service.
46. How does DynamoDB handle high availability and fault tolerance?
Ans:
DynamoDB achieves high availability and fault tolerance through synchronous replication across multiple Availability Zones within a region. Data is replicated across multiple storage nodes within each AZ, ensuring redundancy and durability. In the event of AZ failures or hardware issues, DynamoDB automatically fails over to healthy nodes to maintain availability and data integrity.
47. Explain DynamoDB’s support for data encryption in transit and its benefits.
Ans:
DynamoDB encrypts data in transit using Transport Layer Security (TLS), ensuring data is encrypted between clients and the DynamoDB service endpoint. Encryption in transit protects data from interception and tampering, providing end-to-end security for data transmission over insecure networks or public internet connections.
48. What are the different consistency levels supported by DynamoDB, and how do they impact performance and data consistency?
Ans:
DynamoDB supports two consistency levels: eventual consistency and firm consistency. Eventual consistency provides higher throughput and lower latency. Still, it may return stale data under heavy load, while strong consistency ensures data freshness and accuracy but may incur higher latency and reduced throughput due to additional coordination overhead.
49. Explain DynamoDB’s adaptive capacity feature and how it helps manage sudden spikes in workload.
Ans:
DynamoDB’s adaptive capacity feature automatically adjusts throughput capacity in response to changing workload patterns and traffic spikes. It dynamically scales provisioned RCUs and WCUs based on usage metrics, such as consumed capacity and request rates, ensuring optimal performance and cost efficiency without manual intervention during sudden changes in workload.
50. How does DynamoDB handle data archiving and long-term retention?
Ans:
DynamoDB supports data archiving and long-term retention through continuous backups and point-in-time recovery (PITR). Continuous backups automatically capture incremental table changes and store them in Amazon S3 for long-term retention. At the same time, PITR allows you to restore tables to specific points within the retention period, providing data durability and compliance with regulatory requirements.
51. Explain how DynamoDB handles schema evolution and versioning.
Ans:
- Data model updates may be made smoothly and without interruption because to DynamoDB’s flexible and schema-less handling of schema evolution and versioning.
- DynamoDB does not impose a set schema for tables, in contrast to typical relational databases where schema alterations frequently necessitate intricate migrations.
- Instead, because objects in the same table might have varied structures, it allows you to add, remove, or edit attributes at any moment.
52. What are the different strategies for optimizing DynamoDB performance for read-heavy workloads?
Ans:
Strategies for optimizing DynamoDB performance for read-heavy workloads include choosing appropriate partition keys to evenly distribute read traffic, leveraging secondary indexes for efficient querying, caching frequently accessed data using services like DynamoDB Accelerator (DAX), and optimizing query patterns to minimize the number of read operations.
53. Explain the benefits of using DynamoDB Accelerator (DAX) for caching.
- Decreased Latency: DAX considerably improves read speed over conventional DynamoDB operations by caching frequently requested data, resulting in microsecond response times.
- Enhanced Throughput: By shifting read requests from DynamoDB to the DAX cache, it lessens the database’s workload and facilitates the effective handling of larger query volumes.
- Smooth Integration: There aren’t many modifications needed to your current application for DAX and DynamoDB to work together seamlessly.
- Cost Efficiency: DAX can reduce read capacity unit costs, especially for high-read workloads, by minimizing the number of read operations that are performed directly against DynamoDB.
- Automatic Cache Management: By handling cache evictions and updates automatically, DAX makes sure that data is always current and reliable without requiring human interaction.
54. How does DynamoDB handle table and index sizing limits, and what are the implications for large-scale deployments?
- Large-scale deployments are supported by DynamoDB’s scalable architecture, which manages table and index sizing limitations.
- As data volume increases, each DynamoDB table and its corresponding indexes are automatically divided among several servers, assisting in the management of storage and performance constraints.
- The system divides data and traffic among these partitions, ensuring that tables and indexes can withstand growing volumes of data without reaching fixed size restrictions.
55. Explain DynamoDB’s support for fine-grained access control and its integration with AWS Identity and Access Management (IAM).
DynamoDB integrates with AWS IAM to provide fine-grained access control, allowing you to define access policies and permissions at the API, table, or even down to individual items. IAM policies can restrict access based on conditions such as IP address, user identity, or time of day. They provide granular control over who can access DynamoDB resources and what actions they can perform.
56. What are the different types of backups supported by DynamoDB, and how do they differ?
Ans:
- On-Demand Backups: Users can manually create full backups of your tables whenever necessary with DynamoDB’s on-demand backups. You can use this feature to save the current status of your table data for tasks like data migration, compliance, and long-term storage.
- Point-in-Time Recovery (PITR): Point-in-Time Recovery (PITR) allows you to restore your data to any point during the last 35 days by providing continuous, automated backups of your DynamoDB tables.
57. Explain DynamoDB’s support for the JSON document data model and its benefits.
Ans:
- The JSON document data model is supported by DynamoDB, giving customers the ability to store and manage semi-structured data in an adaptable and hierarchical format.
- Applications can now store intricate data structures like arrays and nested objects straight inside of DynamoDB tables thanks to this capability.
- The flexibility of the JSON model is beneficial since it permits dynamic schema modifications without necessitating table migrations or schema modifications.
- Applications with changing data requirements or a variety of data formats can benefit greatly from DynamoDB’s ability to handle complicated relationships and varied data properties inside a single item thanks to its support for JSON.
- Strong querying features for JSON data are also offered by DynamoDB.
- These features include the capacity to query nested attributes, execute conditional searches, and filter results according to particular JSON routes.
58. How does DynamoDB handle disaster recovery and data replication across multiple regions?
Ans:
DynamoDB supports cross-region replication through global tables, allowing you to replicate data across multiple AWS regions for disaster recovery and high availability. Global tables automatically replicate data asynchronously and provide eventual consistency across regions, ensuring data availability and resilience in the event of regional outages or disasters.
59. Explain the importance of choosing the right partition key in DynamoDB and how it impacts performance and scalability.
Ans:
Choosing the right partition key is crucial for achieving optimal performance and scalability in DynamoDB. A well-designed partition key evenly distributes workload across partitions, preventing hot partitions and ensuring efficient use of provisioned throughput capacity. Poorly chosen partition keys can lead to uneven distribution of workload, throughput bottlenecks, and degraded performance.
60. What are the different encryption options for DynamoDB, and how do they provide data security?
Ans:
DynamoDB offers encryption at rest using AWS Key Management Service (KMS), ensuring that data is encrypted before it’s written to disk and decrypted when read from disk. Additionally, DynamoDB supports encryption in transit using Transport Layer Security (TLS), encrypting data transmitted between clients and the DynamoDB service endpoint, providing end-to-end encryption for data security and compliance.

61. Explain the concept of composite primary keys in DynamoDB and their advantages.
Ans:
Composite primary keys in DynamoDB consist of partition and sort keys, allowing for richer query patterns and more flexible data modelling. Combining these keys will enable you to organize data hierarchically and efficiently query items within a partition based on the sort key. This helps support range queries, sorting, and efficient retrieval of related items.
62. What are the different strategies for optimizing DynamoDB performance for write-heavy workloads?
Ans:
Strategies for optimizing DynamoDB performance for write-heavy workloads include:
- Choosing appropriate partition keys to distribute write traffic evenly.
- Batching write operations to reduce the number of requests.
- Leveraging conditional writes and batch operations for efficient updates.
- Using DynamoDB Streams for asynchronous processing of write events.
63. Explain DynamoDB’s support for transactions and their benefits.
Ans:
DynamoDB supports ACID-compliant transactions, allowing you to group multiple read and write operations into a single, all-or-nothing transaction. Transactions ensure data integrity and consistency across various items or tables, providing guarantees of atomicity, consistency, isolation, and durability. This benefits complex data manipulations and ensures data correctness in critical operations.
64. How does DynamoDB handle the throttling of read and write operations, and what are the implications for application performance?
Ans:
DynamoDB throttles read and write operations when the provisioned throughput capacity is exceeded or when the service encounters resource constraints. Throttling can impact application performance by slowing response times and potentially causing errors. To mitigate throttling, you can monitor performance metrics, adjust provisioned throughput capacity, implement exponential backoff, and optimize query patterns.
65. Explain DynamoDB’s support for parallel scans and its benefits.
Ans:
DynamoDB supports parallel scans, allowing you to divide a large scan operation into multiple segments that can be processed concurrently. Parallel scans improve scan performance by distributing the workload across numerous partitions and leveraging the parallel processing capabilities of DynamoDB, reducing scan latency and improving throughput for large datasets.
66. What are the considerations for designing efficient partition keys in DynamoDB, and how do they impact performance and scalability?
Ans:
Considerations for designing efficient partition keys in DynamoDB include:
- Choosing attributes with high cardinality to distribute workload evenly.
- Avoiding sequential or monotonically increasing keys to prevent hot partitions.
- Selecting keys that support the required query patterns and access patterns.
Well-designed partition keys optimize performance and scalability by evenly distributing the workload across partitions and minimizing contention.
67. Explain DynamoDB’s support for point-in-time recovery (PITR) and how it helps protect against data loss.
Ans:
DynamoDB’s point-in-time recovery (PITR) feature allows you to restore tables to any point within the retention period, typically up to 35 days in the past. PITR helps protect against data loss caused by accidental deletion, corruption, or malicious actions by providing a mechanism to restore tables to a previous consistent state, ensuring data durability and compliance with regulatory requirements.
68. How does DynamoDB handle data migration and importing/exporting data from/to external sources?
Ans:
DynamoDB supports data migration and importing/exporting data from/to external sources through various methods, including AWS Data Pipeline, AWS Glue, AWS Database Migration Service (DMS), and custom scripts using DynamoDB APIs. These tools and services facilitate seamless data transfer between DynamoDB tables and other storage systems, enabling data integration and synchronization for diverse use cases.
69. Explain DynamoDB’s support for conditional writes and how they help ensure data integrity.
Ans:
DynamoDB supports conditional writes, allowing you to specify conditions that must be met for write operations to succeed. Conditional writes help ensure data integrity by preventing conflicting updates, enforcing business rules, and implementing optimistic concurrency control. If the conditions are unmet, DynamoDB rejects the write operation, ensuring only valid changes are applied to the database.
70. What are the best practices for monitoring and optimizing DynamoDB performance in production environments?
Ans:
Best practices for monitoring and optimizing DynamoDB performance in production environments include monitoring key performance metrics such as consumed capacity, provisioned throughput, and error rates, using Amazon CloudWatch alarms to detect performance issues, optimizing query patterns and access patterns to minimize read and write operations, and periodically reviewing and adjusting provisioned throughput capacity based on workload patterns and performance metrics.
71. Explain how DynamoDB handles data consistency in multi-region deployments and the trade-offs involved.
Ans:
In multi-region deployments, DynamoDB uses eventually consistent replication to replicate data across regions asynchronously. This means that updates made in one area may not immediately propagate to other regions, resulting in eventual consistency. While this approach provides low-latency access within regions and improves fault tolerance, it may introduce latency and potential inconsistencies across regions during replication.
72. What are the benefits of using DynamoDB Streams, and how can they be leveraged in application architectures?
Ans:
DynamoDB Streams capture real-time changes to items in a table and provide a time-ordered sequence of item-level changes. The benefits of using DynamoDB Streams include:
- Enabling event-driven architectures.
- Implementing data pipelines for processing and analysis.
- Triggering downstream actions based on database events.
- Synchronizing data across multiple services or systems.
73. Explain the difference between DynamoDB Local and DynamoDB Global Tables, and when each should be used.
Ans:
DynamoDB Local is a downloadable version of DynamoDB that simulates the DynamoDB service environment locally on your computer, allowing for the development and testing of applications without incurring AWS costs. DynamoDB Global Tables, on the other hand, are fully managed multi-region deployments of DynamoDB that provide automatic replication and eventual consistency across regions for global applications. DynamoDB Local is suitable for local development and testing, while DynamoDB Global Tables are designed for production deployments requiring global data replication and high availability.
74. How does DynamoDB handle capacity planning and scaling in response to changing workload patterns?
Ans:
DynamoDB provides flexible scaling options to accommodate changing workload patterns. In provisioned throughput mode, you can adjust the read and write capacity units (RCUs and WCUs) to scale up or down based on anticipated workload changes. In on-demand capacity mode, DynamoDB automatically scales capacity in response to actual usage, provisioning capacity dynamically to match the workload without requiring manual intervention.
75. Explain DynamoDB’s support for multi-item transactions and how they are implemented.
Ans:
DynamoDB supports multi-item transactions, allowing you to group multiple read and write operations across numerous items or tables into a single, all-or-nothing transaction. Transactions are implemented using conditional writes and optimistic concurrency control, where DynamoDB checks for conflicts and ensures data consistency and atomicity across all operations within the transaction.
76. What are the considerations for designing efficient secondary indexes in DynamoDB?
Ans:
Considerations for designing efficient secondary indexes in DynamoDB include:
- Selecting attributes frequently used in queries.
- Choosing appropriate partition keys and sort keys to support query patterns.
- Considering the impact on storage costs and performance.
- Evaluating trade-offs between query flexibility and index size.
Well-designed secondary indexes optimize query performance and enable efficient data retrieval for diverse use cases.
77. Explain DynamoDB’s support for fine-grained access control using IAM policies and roles.
Ans:
DynamoDB integrates with AWS Identity and Access Management (IAM) to provide fine-grained access control, allowing you to define access policies and permissions at the API level, table level, or even down to individual items. IAM policies and roles enable you to restrict access based on user identity, IP address, time of day, or other conditions, providing granular control over who can access DynamoDB resources and what actions they can perform.
78. What are the different options for data modelling in DynamoDB, and how do they impact performance and scalability?
Ans:
Data modelling options in DynamoDB include using single-table designs, multiple tables with relationships, and denormalized designs with nested attributes. Each option has trade-offs in query flexibility, data duplication, and storage efficiency and should be chosen based on the application’s requirements, access patterns, and performance considerations.
79. Explain DynamoDB’s support for auto-scaling and how it helps manage workload fluctuations.
Ans:
DynamoDB’s auto-scaling feature automatically adjusts provisioned throughput capacity in response to changing workload patterns. It continuously monitors usage metrics such as consumed capacity and request rates and dynamically adjusts RCUs and WCUs up or down to match the workload. Auto-scaling helps manage workload fluctuations and ensures optimal performance and cost efficiency without manual intervention.
80. What are the different methods for exporting data from DynamoDB, and when should each method be used?
Ans:
DynamoDB provides several data export methods, including the Data Pipeline service, the AWS Command Line Interface (CLI), AWS Glue, and custom scripts using DynamoDB Streams and APIs. The choice of export method depends on factors such as the volume of data, frequency of exports, integration requirements, and desired destination format.
81. Explain how DynamoDB supports time-series data storage and querying.
Ans:
DynamoDB supports time-series data storage and querying by using timestamps as sort keys. You can organize data by time intervals (e.g., hours, days) and use time-based queries to retrieve data within specific time ranges. By leveraging composite keys and secondary indexes, you can efficiently query time-series data for analytics, monitoring, and reporting purposes.
82. What are the considerations for optimizing DynamoDB performance when working with large items or datasets?
Ans:
When working with large items or datasets in DynamoDB, considerations for optimizing performance include minimizing item size to avoid exceeding the 400 KB limit, distributing large datasets across multiple partitions using appropriate partition keys, using streaming or batch processing for large data imports or exports, and leveraging compression techniques to reduce storage and throughput costs.
83. Explain DynamoDB’s support for conditional expressions and how they help ensure data integrity.
Ans:
DynamoDB’s conditional expressions allow you to specify conditions that must be met for write operations to succeed. These conditions can include attribute values, existence checks, and logical operators, providing fine-grained control over data modifications. Conditional expressions help ensure data integrity by enforcing business rules, preventing conflicting updates, and implementing optimistic concurrency control.
84. How does DynamoDB handle index updates and maintenance for global secondary indexes (GSIs) and local secondary indexes (LSIs)?
Ans:
DynamoDB automatically handles index updates and maintenance for GSIs and LSIs, ensuring consistency and efficiency. When you create, update, or delete items in a table, DynamoDB automatically updates the corresponding indexes to reflect the changes. For GSIs, updates are propagated asynchronously across partitions and regions, while for LSIs, updates are handled within the same partition as the base table.
85. Explain DynamoDB’s capacity planning and cost optimization support in on-demand capacity mode.
Ans:
In on-demand capacity mode, DynamoDB automatically scales capacity in response to actual usage, provisioning capacity dynamically to match the workload without requiring manual intervention. This helps optimize costs by eliminating the need to provision and manage capacity upfront while still providing the performance and scalability benefits of DynamoDB.
86. What are the best practices for designing DynamoDB tables for efficient query performance?
Ans:
Best practices for designing DynamoDB tables for efficient query performance include:
- Choosing appropriate partition keys to distribute workload evenly.
- Composite keys and secondary indexes are used to support query patterns.
- Denormalizing data to minimize joins and reduce query complexity.
- Optimizing access patterns based on application requirements and usage patterns.
87. Explain DynamoDB’s support for backups and restore operations in cross-region replication scenarios.
Ans:
In cross-region replication scenarios, DynamoDB backups and restore operations are supported for global tables. Continuous backups and point-in-time recovery (PITR) are available for global tables, allowing you to create full backups of tables and restore them to any point within the retention period across regions. This provides data durability and disaster recovery capabilities for global applications.
88. How does DynamoDB handle partition splits and merges, and what are the implications for performance and scalability?
Ans:
- DynamoDB automatically handles partition splits and merges to accommodate workload patterns and data distribution changes.
- When a partition reaches its storage limit, DynamoDB splits it into multiple partitions, and when the workload decreases, DynamoDB merges partitions to reduce overhead.
- While these operations are transparent to users, they can impact performance and scalability, so carefully designing partition keys is essential to minimize disruptions.
89. Explain DynamoDB’s support for auto-scaling read and write capacity and how it helps manage unpredictable workloads.
Ans:
DynamoDB’s auto-scaling feature automatically adjusts provisioned read and write capacity units (RCUs and WCUs) based on actual usage metrics, such as consumed capacity and request rates. This helps manage unpredictable workloads by dynamically scaling capacity up or down to match demand, ensuring optimal performance and cost efficiency without manual intervention.
90. What are the considerations for optimizing DynamoDB performance when using conditional writes and transactions?
Ans:
When using conditional writes and transactions in DynamoDB, considerations for optimizing performance include:
- Minimizing the number of conditional expressions to reduce latency and throughput consumption.
- Batching multiple operations into a single transaction to minimize round-trip latency.
- Carefully designing partition keys and indexes to avoid contention and conflicts.
91. Explain DynamoDB’s support for custom indexes using AWS Lambda and its benefits.
Ans:
DynamoDB supports custom indexes using AWS Lambda through DynamoDB Streams and AWS Lambda triggers. With this feature, you can implement custom indexing logic in Lambda functions to create and maintain secondary indexes based on specific business requirements. This allows for flexible indexing strategies tailored to unique use cases, improving query performance and data access patterns.
92. What are the considerations for optimizing DynamoDB performance when working with global tables spanning multiple regions?
Ans:
When working with global tables spanning multiple regions in DynamoDB, considerations for optimizing performance include:
- Minimizing cross-region latency by colocating application servers and DynamoDB clients in the same area.
- Using DynamoDB Accelerator (DAX) for caching to reduce latency for read-heavy workloads.
- Carefully designing partition keys to minimize cross-region traffic and replication delays.
93. Explain DynamoDB’s support for Time to Live (TTL) indexes and how they can expire data.
Ans:
- DynamoDB’s TTL indexes allow you to specify a time-to-live attribute for items in a table, automatically deleting expired items after a specified duration. By enabling TTL indexes,
- DynamoDB manages data expiration automatically, reducing storage costs and maintenance overhead.
- TTL indexes manage transient data such as session records, temporary notifications, and cache entries.
94. How does DynamoDB handle schema evolution and versioning in single-table designs?
Ans:
In single-table designs in DynamoDB, schema evolution and versioning are managed through flexible data modelling and attribute evolution. New attributes can be added to items without modifying existing items, and attribute names can evolve to accommodate changes in data requirements. This allows for seamless schema evolution and versioning without disrupting existing data.
95. Explain DynamoDB’s support for transactions across multiple items and tables and its benefits.
Ans:
DynamoDB supports transactions across multiple items and tables, allowing you to group various read and write operations into a single, all-or-nothing transaction. Transactions provide data integrity and consistency guarantees across numerous items or tables, ensuring atomicity, consistency, isolation, and durability. This benefits complex data manipulations and ensures data correctness in critical operations spanning multiple entities.
96. What are the considerations for optimizing DynamoDB performance when using conditional expressions for updates and deletes?
Ans:
When using conditional expressions for updates and deletes in DynamoDB, considerations for optimizing performance include:
- Minimizing the number of conditional expressions to reduce latency and throughput consumption.
- Carefully designing partition keys and indexes to avoid contention and conflicts.
- Using efficient query patterns to identify and update/delete items based on conditions.
97. Explain DynamoDB’s support for continuous backups and point-in-time recovery (PITR) and their benefits.
Ans:
DynamoDB’s continuous backups and point-in-time recovery (PITR) feature allows you to create full backups of tables and restore them to any point within the retention period, typically up to 35 days in the past. Continuous backups provide data durability and disaster recovery capabilities. At the same time, PITR helps protect against accidental deletion, corruption, or malicious actions by providing a mechanism to restore tables to a previous consistent state.
98. How does DynamoDB handle access control and authorization using IAM policies, and what are the best practices for securing DynamoDB resources?
Ans:
DynamoDB integrates with AWS Identity and Access Management (IAM) to provide access control and authorization using IAM policies. Best practices for securing DynamoDB resources include granting least privilege access, using IAM roles and policies to control access at the API level, encrypting data at rest and in transit, enabling VPC endpoints for private access, and monitoring and auditing access using AWS CloudTrail and CloudWatch.
99. What are the considerations for optimizing DynamoDB performance when using batch operations for bulk data operations?
Ans:
When using batch operations for bulk data operations in DynamoDB, considerations for optimizing performance include:
- Batching multiple operations into a single request reduces round-trip latency and improves throughput efficiency.
- Using parallel processing for concurrent batch operations to maximize throughput.
- Carefully managing throughput capacity to avoid throttling and optimize cost efficiency.