Last updated on 10th Apr 2024| 6295
Amazon Simple Storage Service (Amazon S3) is a cloud storage service provided by Amazon Web Services. It offers a highly scalable, durable, and secure infrastructure for data storage and retrieval via the internet. Amazon S3 allows customers to store nearly endless quantities of data in the form of objects, each of which contains data and metadata. S3 is intended for dependability, with built-in redundancy and data durability to safeguard stored items from hardware failures and data loss.
1. What is Amazon S3, and how does it function?
Ans:
- Simple Storage Service (Amazon S3) is a scalable solution for object storage offered by Amazon Web Services (AWS). Users can save and retrieve any volume of data from any location at any time via the Internet.
- It functions by offering a web services interface for programmatic data storage and retrieval.
- Users can govern who can access their data by managing access rights and creating buckets or containers to hold their data.
- By distributing the data among several systems, S3 guarantees excellent availability and durability.
2. Explain the difference between S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and Glacier?
Ans:
| Storage Class | Description | Use Case |
|---|---|---|
| S3 Standard | Default storage class offering high durability, availability, and low latency for frequently accessed data. | Frequently accessed data, content distribution, dynamic websites. |
| S3-Intelligent-Tiering | Automatically moves data between two access tiers: frequent access and infrequent access, optimizing storage costs based on access patterns. | Data with changing or unknown access patterns, where optimization of storage costs is required. |
| S3 Standard-IA | Designed for data that is accessed less frequently but requires rapid access when needed. Offers lower storage costs compared to S3 Standard, with a slight retrieval fee for accessing data | Long-term storage of infrequently accessed data that requires immediate availability when accessed. |
| Glacier | Cold storage service for data archiving and long-term backup. Offers significantly lower storage costs but longer retrieval times and additional retrieval fees. | Archival data, regulatory compliance records, backups, data that is rarely accessed and can tolerate longer retrieval times. |
3. How does S3 achieve high durability?
Ans:
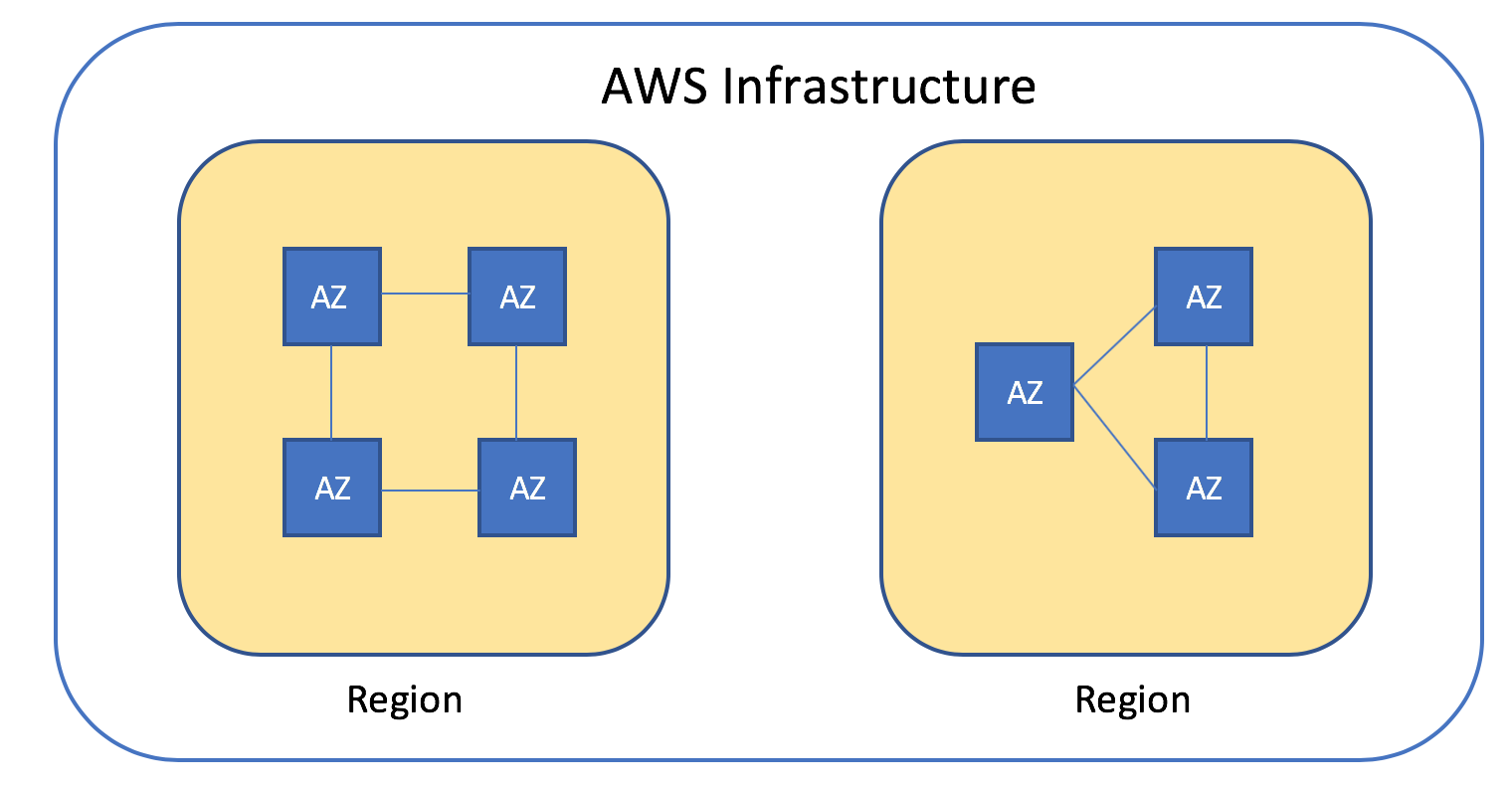
Amazon S3 achieves high durability by automatically replicating data across multiple facilities within an AWS Region. It is designed to provide 99.999999999% durability by storing copies of data on multiple devices across a minimum of three physical AZs (Availability Zones). This redundancy ensures that data is not lost due to hardware failures, natural disasters, or other incidents.
4. Describe how S3 and EBS vary from one another?
Ans:
- Amazon S3 and Amazon EBS (Elastic Block Store) are both storage services provided by AWS, but they serve different purposes.
- S3 is object storage suitable for storing and retrieving any amount of data at any time, ideal for static files, backups, and web content.
- In contrast, EBS offers block-level storage volumes that may be used with EC2 instances to store data persistently.
- EBS is designed for applications that need a database, file system, or access to raw block-level storage.
5. What is the S3 bucket policy?
Ans:
An S3 bucket policy is an Amazon Identity and Access Management (IAM) policy that is resource-based and connected to an S3 bucket. Permissions for the bucket and its contents are adjustable. Bucket policies take into account a range of criteria, including IP address, HTTP referrer, and whether or not requests are authenticated. They offer centralized access control to buckets and objects.
6. How to make an S3 bucket public?
Ans:
Yes, an S3 bucket can be made public by modifying its bucket policy or through the bucket ACL (Access Control List). To make a bucket public through the bucket policy, need to add a policy that grants the s3:GetObject permission to everyone, using “Principal.” However, making a bucket public should be done with caution to avoid unintended data exposure.
7. What is the S3 Lifecycle policy?
Ans:
- A collection of guidelines that specify actions on items within a bucket over time is called an S3 Lifecycle policy.
- These policies can automate moving objects between different storage classes (e.g., from S3 Standard to S3 Glacier for archival) or deleting old objects that are no longer needed.
- Lifecycle policies help reduce storage costs and manage data automatically by defining when objects expire or transition without manual intervention.
8. What are S3 Storage Classes?
Ans:
Data that is often accessed can be stored generally using the S3 Standard; S3 Intelligent Tiering is used for data whose access patterns are unpredictable or dynamic. S3 Standard-IA (Infrequent Access) is for data that is less frequently accessed but needs quick access when needed, and so on. Amazon S3 offers several storage classes tailored for various use cases.
09. Explain the S3 data consistency model?
Ans:
Amazon S3 automatically provides strong read-after-write consistency for all objects. This means that as soon as a write or delete operation is completed, the data is consistently visible to any subsequent read or write operations. This applies to both PUT operations for new objects and DELETES, overwriting existing objects or parts of a multipart upload.
10. How can data be secured in S3?
Ans:
Securing data in S3 involves using a combination of access control mechanisms and encryption methods. Access control can be managed through bucket policies, IAM policies, and Access Control Lists (ACLs) to define who can access the S3 resources. For encryption in transit, S3 uses HTTPS. For encryption at rest, S3 provides S3-managed keys (SSE-S3), AWS Key Management Service managed keys (SSE-KMS), and customer-provided keys (SSE-C).
11. What is Multipart Upload in Amazon S3, and what are its benefits?
Ans:
- Multipart upload allows to upload large files in parts, making the upload process more efficient and reliable.
- If a part fails to upload, can only re-upload that part without affecting the other parts. This feature is particularly useful for uploading large files over a less reliable network or when upload speed is a concern.
- By enabling the portions to be uploaded in concurrently, multipart uploads can also increase upload speed. Once all of the object’s components are uploaded, Amazon S3 puts them together to form a single object.
12. What are S3 Select and Glacier Select, and how do they differ?
Ans:
- S3 Select and Glacier Select allow users to retrieve only a subset of data from an object based on a simple SQL expression. Applications may filter and get only the data they want, which can greatly increase speed and lower costs when obtaining data from S3 and Glacier, respectively.
- The primary difference between the two is their use case, S3 Select is used for data stored in S3, providing quicker access for analysis and processing, while Glacier Select is for querying data archived in Glacier, which is not immediately accessible and is primarily used for data that is infrequently accessed.
13. How can large amounts of data be transferred to S3?
Ans:
- AWS provides many tools and services for bulk data transfers to S3. AWS S3 Transfer Acceleration accelerates file transfers across large distances between the client and an S3 bucket. Compared to internet-based connections, AWS Direct Connect creates a dedicated network link between the location and AWS.
- AWS Snowball and Snowmobile are services that enable to deliver massive volumes of data through physical storage devices without using the Internet at all for physical data transmission. This makes them perfect for initial large-scale data migrations or routine backups.
14. What is Cross-Region Replication (CRR) in S3, and when is it used?
Ans:
Cross-region replication (CRR) automatically replicates every object uploaded to a specific S3 bucket to another bucket located in a different AWS region. This feature is used for several purposes, including compliance and regulatory requirements, minimizing latency by locating data closer to users, and enhancing disaster recovery strategies by ensuring data is available in another region in the event of disaster.
15. How does Amazon S3 handle concurrency when multiple users are accessing the same object?
Ans:
Amazon S3 handles concurrency by providing the latest version of the object to all GET requests. When multiple write requests are made to the same object simultaneously, S3 serially processes them, ensuring that only one write request is handled at a time based on the internal timestamp, which determines the sequence of the requests. This ensures data integrity and consistency.
16. What is the difference between a PUT request and a POST request in the context of Amazon S3?
Ans:
- In the context of Amazon S3, a PUT request uploads an object to a specified bucket by providing the object key (name) and the data itself.
- With the same key, an existing object may be overwritten, or a new one can be created. A PUT request requires the full path to the resource, including the bucket name and the object key.
- POST requests are typically used with HTML forms and pre-signed URLs, allowing for file uploads directly from web browsers.
17. Explain the significance of object immutability in Amazon S3 and how it can be achieved?
Ans:
- Object immutability in Amazon S3 is crucial for ensuring that data cannot be altered or deleted after it has been written, providing a strong guarantee of data integrity and protection against accidental.
- This is particularly important for compliance with regulatory requirements in industries like finance and healthcare, where it’s necessary to retain original data for auditing purposes.
- Immutability can be achieved using S3 Object Lock, which allows users to store objects using a write-once-read-many (WORM) model.
18. Describe the process of enabling Versioning on an Amazon S3 bucket and its benefits?
Ans:
Versioning on an Amazon S3 bucket is enabled by changing the bucket’s properties using the AWS Management Console, AWS CLI, or SDKs. When enabled, S3 allows to access, retrieve, and restore any version of an object by keeping several copies of it in the same bucket. An object’s version ID is used to identify each version of the object. Versioning helps to save, retrieve, and restore every version of an item stored in a bucket.
19. How can the usage of Amazon S3 be monitored and analyzed?
Ans:
Monitoring and analyzing Amazon S3 usage can be achieved through various AWS services. AWS CloudWatch provides metrics for monitoring operational performance, such as the number of objects in a bucket, request rates, error rates, and data transfer metrics. AWS S3 also supports server access logging, which logs detailed requests made to a bucket, which is useful for security and access audits.
20. What strategies can be employed to optimize costs associated with Amazon S3?
Ans:
- Optimizing costs associated with Amazon S3 involves several strategies. First, understand the access patterns and choose the most cost-effective storage class for data. For infrequently accessed data, consider using S3 Infrequent Access or S3 One Zone-IA.
- Utilize S3 Intelligent Tiering for data with unknown or changing access patterns, as it automatically moves data to the most cost-effective access tier. Regularly review and clean up unused or unnecessary S3 buckets and objects.
21. What is Amazon S3 Transfer Acceleration, and how does it work?
Ans:
Versioning helps to save, retrieve, and restore every version of an item stored in a bucket, in addition to guarding against inadvertent overwrites and deletions. It works by utilizing the Amazon CloudFront globally distributed edge locations. When Transfer Acceleration is used, data is routed to S3 over an optimized network path that automatically adapts to changes in network conditions.
22. How can encryption in transit be enforced for Amazon S3?
Ans:
Versioning protects against accidental overwrites and deletions while assisting in saving, retrieving, and restoring every version of an object kept in a bucket. This can be achieved by configuring applications and services to use HTTPS endpoints for S3 rather than HTTP. AWS SDKs and the AWS CLI use HTTPS by default for all requests, and configure a bucket policy to deny any requests that are not made over HTTPS.
23. What is the AWS S3 “Event Notifications” feature, and how is it used?
Ans:
With Amazon S3 Event Notifications, may be notified when specific things occur in the S3 bucket, including an item being created, deleted, or restored. These notifications can be sent to Amazon SNS topics, Amazon SQS queues, or AWS Lambda functions, allowing for automated processing or workflows in response to changes in the S3 bucket, the feature is widely used for use cases like triggering image or video processing workflows.
24. Explain the use of Prefixes and Delimiters in Amazon S3?
Ans:
- In Amazon S3, prefixes and delimiters are used to organize and manage objects within a bucket logically. A prefix is a way to group objects under a common “folder” by their key names. For example, specifying a prefix of “photos/” will list all objects that have keys starting with “photos/.”
- A delimiter, such as “/,” simulates a hierarchical structure within S3 by grouping keys that share a prefix up to the delimiter. This can simplify navigation and object organization, making it easier to manage large numbers of objects in a bucket.
25. How does Amazon S3’s “Static Website Hosting” feature work?
Ans:
- Amazon S3’s Static Website Hosting feature allows to host static websites directly from an S3 bucket.
- To use it, enable the static website hosting option on the bucket, upload in HTML, CSS, JavaScript, and image files, and then configure the bucket to serve these files as a website.
- This feature allows websites to be hosted without the need for servers, making it an affordable and expandable method of hosting static material.
26. What are the best practices for securing Amazon S3 buckets?
Ans:
- Encrypt data at rest using S3-managed keys (SSE-S3), AWS KMS-managed keys (SSE-KMS), or client-side encryption for sensitive data.
- Regularly audit permissions with tools like AWS Trusted Advisor and Access Analyzer for S3.
- Never make a bucket publicly accessible unless necessary, and even then, limit the permissions as much as possible.
27. How can a lifecycle policy be configured for an S3 bucket?
Ans:
To configure a lifecycle policy for an S3 bucket, first identify the objects or prefixes within the bucket that the policy will apply to. Next, decide on the actions (transitions, expirations) and the timing for these actions. For example, user might transition objects to S3 Standard-IA after 30 days, then to Glacier after 90 days, and eventually expire (delete) them after 365 days.
28. How can accidental deletion of objects in Amazon S3 be prevented?
Ans:
- To prevent accidental deletion of objects in Amazon S3, can use versioning and Multi-Factor Authentication (MFA) Delete. By enabling Versioning, every object in the bucket can have multiple versions.
- MFA Delete adds a layer of security by requiring the authentication code from an MFA device to permanently delete an object version or change the versioning state of a bucket.
- This combination makes it much harder to accidentally or maliciously delete important data.
29. What is Amazon S3 Select, and how does it improve data retrieval?
Ans:
Amazon S3 Select is a feature that allows the retrieval of only a subset of data from an S3 object using simple SQL expressions. This is particularly useful for accessing data stored in CSV, JSON, or Parquet formats because it eliminates the need to download the entire file to find the data needed. By enabling applications to retrieve only the data needed from an S3 object, S3 Select can improve performance and reduce costs.
30. How can an Amazon S3 bucket be shared across AWS accounts?
Ans:
To share an Amazon S3 bucket across AWS accounts, can use bucket policies or Access Control Lists (ACLs). A bucket policy is the recommended approach, as it allows one to specify more granular permissions and apply them to different accounts. In the policy, can grant specific permissions (like s3:GetObject, s3:PutObject) to the AWS account IDs want to share with.
31. How does S3 Object Lock help with data compliance and governance?
Ans:
S3 Object Lock helps with data compliance and governance by preventing objects from being deleted or overwritten for a fixed amount of time, enforcing a Write Once, Read Many (WORM) model. This is crucial for meeting compliance requirements for regulatory archives, financial records, and other critical documents that must not be altered after they have been written.
32. What are the key features of Amazon S3?
Ans:
- Key features of Amazon S3 include high durability and availability,
- Secure storage through ACLs and bucket policies,
- Event notifications are used to react to bucket events, Versioning is used to save, retrieve, and restore each version of each item kept in a bucket, and lifecycle rules are used to manage the lifecycles of objects.
- It also supports MFA Delete for an additional security layer, and it is designed to deliver 99% durability.
33. How can the performance of data retrieval in Amazon S3 be improved??
Ans:
Improving data retrieval performance in S3 can be achieved by using techniques like caching frequently accessed data using CloudFront, leveraging S3 Select for retrieving only a subset of data from objects, and implementing concurrent connections or multipart downloads to increase throughput. Organizing data with indexing patterns, using hash prefixes in object names, can distribute objects more evenly across S3’s internal partitions.
34. What encryption options are available on Amazon S3?
Ans:
- Amazon S3 offers several encryption options to secure data at rest. S3 provides server-side encryption with three key management options: S3-managed keys (SSE-S3), AWS Key Management Service (KMS) keys (SSE-KMS), and customer-provided keys (SSE-C).
- Clients can encrypt data on the client side before uploading it to S3 for an extra layer of security. For data in transit, S3 uses HTTPS to encrypt the data as it travels between the client and S3.
35. How does Amazon S3 integrate with other AWS services?
Ans:
- Amazon S3 integrates seamlessly with a wide range of AWS services, enhancing its capabilities for various applications.
- For instance, S3 can trigger Lambda functions for serverless computing, serve as a data source for Amazon Athena for query processing, or be used with AWS Glue for data catalog and ETL operations.
- It also works with Amazon CloudFront for content delivery, AWS S3 Transfer Acceleration for faster data transfer, and Amazon Redshift for data warehousing, enabling comprehensive data management and analytics solutions.
36. Explain how AWS S3’s multi-tenancy model is secured?
Ans:
AWS S3’s multi-tenancy model is secured through rigorous isolation mechanisms, ensuring that data stored by one customer is completely inaccessible to other customers. Each S3 object is stored with metadata that includes the owner’s identity and access permissions. AWS employs a combination of logical and physical security measures, including network isolation, encryption, and identity and access management policies, to protect users’ data.
37. What is Amazon S3 Inventory, and how can it be used?
Ans:
Amazon S3 Inventory provides a scheduled report of S3 objects and their corresponding metadata for a specified bucket or shared prefixes. It can be configured to generate daily or weekly reports, which are then stored in a specified bucket. S3 Inventory is particularly useful for large buckets, enabling easier and more efficient object management, auditing, and operational tasks like ensuring compliance with retention policies.
38. What are AWS S3 Access Points?
Ans:
- AWS S3 Access Points simplify managing data access at scale for applications using shared data sets in S3.
- Each access point has distinct permissions and network controls and serves as a unique hostname with dedicated access policies tailored to different applications or user groups.
- This enables to create customized access points for high-throughput workloads, varied access patterns, or multi-tenant environments. Abstracting the access policy management from the underlying bucket improves security and manageability.
39. How does the Amazon S3 Storage Lens help with storage management?
Ans:
Amazon S3 Storage Lens provides a comprehensive view of storage usage and activity across entire S3 environment, including detailed metrics and trends at the account, bucket, and even prefix level. It offers insights and recommendations that can help optimize storage costs, improve security, and enforce data protection policies. With S3 Storage Lens, users can identify anomalies, understand access patterns, and make informed decisions.
40. What role does Amazon S3 play in disaster recovery planning?
Ans:
Amazon S3 is a key component in disaster recovery planning due to its high durability, availability, and scalability. By storing backups and critical data in S3, businesses can protect against data loss and guarantee that operations continue in the case of a crisis. S3’s versioning and cross-region replication features further enhance disaster recovery capabilities by providing additional layers of data protection and geographic redundancy.

Get JOB AWS-S3 Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. How can AWS S3 be used with AWS Lambda for serverless computing?
Ans:
AWS S3 can trigger AWS Lambda functions in response to events like object creation or deletion, enabling serverless computing workflows. Without the need to create or manage servers, this connection enables the automated execution of customized scripts or functions in response to S3 events. For example, when a new image is uploaded to an S3 bucket, a Lambda function could automatically resize the image or analyze its contents.
42. How does Versioning work in Amazon S3, and why is it important?
Ans:
- Versioning in Amazon S3 is a feature that keeps multiple versions of an object within the same bucket, enabling to preserve, retrieve, and restore every version of every object stored.
- Once enabled, S3 automatically generates a unique version ID for each object version. This is crucial for data recovery and protection against accidental overwrites and deletions.
- Versioning is important for maintaining data integrity and providing a clear history of object changes, supporting both compliance needs and enabling robust backup strategies.
43. Describe the process of hosting a static website on Amazon S3?
Ans:
Creating a new S3 bucket configured to serve static web content. Uploading website files (HTML, CSS, JavaScript, etc.). Setting the bucket’s permissions to allow public access. Enable the static website hosting feature on the bucket, which provides a bucket website endpoint URL for accessing the site. Configure a custom domain with Route 53 and secure site with HTTPS by using AWS Certificate Manager (ACM) and CloudFront.
44. Can Amazon S3 serve dynamic content, and if so, how?
Ans:
Amazon S3 is primarily designed to store and serve static content. Serving dynamic content—content that changes in response to user requests—directly from S3 is not possible because S3 does not execute application code. However, S3 can host dynamic websites indirectly by integrating with other AWS services like AWS Lambda and Amazon API Gateway. S3 stores the static elements of the website.
45. What is the Amazon S3 Intelligent-Tiering storage class, and when should it be used?
Ans:
Data with uncertain or fluctuating access patterns is intended for use with the Amazon S3 Intelligent-Tiering storage class. It automatically moves data between two tiers, a frequent access tier and a lower-cost infrequent access tier, which are determined by the frequency of data access. This storage class optimizes costs by ensuring data is stored in the most cost-effective tier without performance impact or operational overhead.
46. Explain the significance of the Amazon S3 bucket naming convention?
Ans:
- The Amazon S3 bucket naming convention is significant because it ensures that bucket names are unique globally across all AWS accounts.
- This uniqueness is required because every S3 bucket shares a common namespace visible in its URL. A well-thought-out naming convention helps prevent naming conflicts, facilitates organized data management, and can improve access and security.
- Following best practices for naming, such as using descriptive, readable names and avoiding sensitive information, can also enhance the manageability and scalability of S3 resources.
47. How can data replication be managed in Amazon S3?
Ans:
Amazon S3 offers two types of replication: Cross-Region Replication (CRR) and Same-Region Replication (SRR). To manage data replication, first enable versioning on both the source and destination buckets. Set up a replication rule on the source bucket, specifying which objects to replicate and where. Replicating all or a portion of the objects according to prefixes or tags is an option.
48. What are S3 Object Lock and WORM, and how do they enhance data security?
Ans:
S3 Object Lock enables to apply of a Write Once Read Many (WORM) model to S3 objects, preventing them from being deleted or modified for a fixed period or indefinitely. This feature enhances data security by protecting data against accidental or malicious deletions and alterations. It’s particularly useful for regulatory archives, digital preservation, and ensuring that critical data cannot be altered or deleted.
49. Discuss the security measures Amazon S3 provides to protect data?
Ans:
- Amazon S3 offers a comprehensive set of security measures to protect data, including encryption in transit and at rest, detailed access control policies, and secure access points.
- Data in transit is protected using SSL/TLS, and for data at rest, S3 offers server-side encryption with S3-managed keys (SSE-S3), AWS Key Management Service keys (SSE-KMS), or customer-provided keys (SSE-C).
- May have fine-grained control over who can access S3 resources by managing access control using bucket rules, IAM policies, access control lists (ACLs), and S3 Access Points.
50. What is the difference between Amazon S3 and Amazon Glacier?
Ans:
- Amazon Glacier is optimized for data archiving and long-term backup at a cheaper cost. It is now a component of the Amazon S3 Glacier and Glacier Deep Archive storage classes.
- S3 is made to provide fast and adaptable access to data for a variety of storage applications, including websites, mobile apps, backup and restore, archiving, corporate apps, Internet of Things devices, and big data analytics.
- It provides secure, durable, and extremely low-cost storage for data archiving and long-term backup, but at the expense of slower retrieval times, making it suitable for data that is infrequently accessed.
51. What is the difference between S3 Standard-IA and S3 One Zone-IA?
Ans:
Both S3 One Zone-Infrequent Access (One Zone-IA) and S3 Standard-Infrequent Access (Standard-IA) are intended for data that is accessed less frequently but has to be accessible quickly when necessary. The key difference is that Standard-IA stores data redundantly across multiple Availability Zones (AZs) for higher durability and availability, while One Zone-IA stores data in a single AZ for a lower cost.
52. Explain the process and benefits of using Amazon S3 with AWS CloudFront for content delivery?
Ans:
- Using Amazon S3 with AWS CloudFront for content delivery involves storing original content in an S3 bucket and then distributing it via CloudFront, an AWS content delivery network (CDN).
- This setup allows for caching content at edge locations closer to the end users, significantly reducing latency and improving website or application load times. It also reduces the load on S3 bucket, potentially lowering costs.
- CloudFront provides additional features like DDoS protection, SSL/TLS encryption, and detailed access controls, enhancing the security and performance of content delivery.
53. What is AWS S3 Analytics Storage Class Analysis, and how can it help with cost optimization?
Ans:
AWS S3 Analytics Storage Class Analysis is a tool that helps to analyze storage access patterns to identify cost-saving opportunities. It monitors data access patterns and provides recommendations on when to transition less frequently data to more cost-effective storage classes such as Standard-IA, and One Zone-IA, by analyzing the reports generated by S3 Analytics, can set up lifecycle policies that automatically move data to lower-cost storage classes.
54. Describe the S3 Inventory report and its use cases?
Ans:
The S3 Inventory report provides a scheduled report of all objects within an S3 bucket or a shared prefix (folder) with details on the metadata of each object. It includes information such as the object’s key, version ID, storage class, and encryption status. By enabling S3 Inventory, organizations can streamline operations and ensure consistency and compliance across vast amounts of data.
55. What are the implications of enabling Versioning on an S3 bucket?
Ans:
- Facilitating Versioning on an S3 bucket allows to store, retrieve, and restore all of the versions of any item that is stored within the same bucket. This is crucial for data recovery and protection against accidental deletions or overwrites.
- It can lead to increased storage costs as multiple copies of an object are stored.
- Managing lifecycle policies becomes more important with Versioning enabled, which automatically deletes older versions of objects or transitions them to more cost-effective storage classes.
56. Explain the difference between PUT and Multipart upload in Amazon S3?
Ans:
PUT upload in Amazon S3 is a single HTTP request to upload an object up to 5 GB in size. It is straightforward but may not be efficient for larger files or when the network is unreliable. This method is more efficient for large files (over 100 MB) as it allows for parallel uploads, reducing upload time, and if a part fails to upload, only need to re-upload that part, not the entire object.
57. What is the concept of pre-signed URLs in S3?
Ans:
Pre-signed URLs in S3 generate a temporary link that provides access to S3 objects for a limited time. This is particularly useful for giving users temporary access to a private object without having to change its permissions or expose AWS credentials. Generate a pre-signed URL by specifying the bucket name, object key, HTTP method (GET, PUT), and expiration time.
58. What tools does AWS offer for monitoring S3?
Ans:
- AWS offers several tools for monitoring Amazon S3, including Amazon CloudWatch, AWS CloudTrail, and S3 Access Logs. CloudWatch provides metrics for monitoring the operational health of S3 buckets, such as request rates, error rates, and data transfer metrics.
- CloudTrail logs actions made on S3 buckets by a user, role, or AWS service to provide insight into bucket activity. S3 Access Logs can log requests made to a bucket, providing detailed records of access requests, which is useful for security and access audits.
59. How To Host a Website In AWS S3? To host a website on AWS S3?
Ans:
First, create an S3 bucket and enable static website hosting on the bucket properties. Upload files in the website (HTML, CSS, JS, images) to the bucket. Set the bucket policy to make the content publicly readable. Then, configure an index document and an error document for the root webpage and error handling. Can use Amazon Route 53 to route domain to the S3 bucket and use AWS CloudFront for faster content delivery.
60. What is an IAM role, and how does it contribute to S3 security?
Ans:
AWS identities with authorization policies dictating what an identity can and cannot do in AWS are known as IAM roles. There are no typical, long-term credentials connected to roles. Rather, upon assuming a position, temporary security credentials are issued for that particular session. By enabling users or AWS services to take actions on S3 buckets in accordance with the set permissions, IAM roles contribute to increased security in the context of S3.

61. What are ACLs in AWS S3?
Ans:
- Access Control Lists (ACLs) in AWS S3 are one way to manage access to S3 resources. May define which AWS accounts or groups are permitted access as well as the type of access with ACLs, which offer a basic degree of control over access to buckets and objects.
- The resource owner has complete control over the default ACL created by Amazon S3 when the bucket or object is created. ACLs may be used to make items public or to allow other AWS accounts read and write access.
62. Explain CORS in the context of S3?
Ans:
Cross-Origin Resource Sharing (CORS) is a mechanism that allows web applications running at one origin to request resources from another origin. In the context of S3, CORS settings enable control of how S3 resources are shared with other web domains. S3 allows configuring CORS rules in an XML format, specifying allowed origins, HTTP methods (GET, PUT, POST), and headers, enhancing the security and flexibility of S3-hosted assets.
63. What is the maximum size of an object that can be stored in S3?
Ans:
The largest item size that may be stored on Amazon S3 is five terabytes. For uploading objects larger than 100 megabytes, Amazon recommends using the Multipart Upload capability. This feature allows to upload large files in smaller, manageable parts that can be uploaded independently and in parallel, improving the upload speed and reliability.
64. How does AWS ensure physical security?
Ans:
AWS ensures physical security across its data centers through multiple layers of protection, including custom-designed electronic access cards, alarms, vehicle access barriers, perimeter fencing, metal detectors, and biometrics. Security guards staff the data centers 24/7, and access is rigorously regulated by trained security personnel using video monitoring at building entry points as well as at the periphery.
65. What is S3 intelligent tiering?
Ans:
S3 Intelligent Tiering is a storage class that automatically moves data to the most economical access tier without affecting performance or adding overhead in order to maximize expenses. It moves data that hasn’t been accessed in 30 days straight to a lower-cost tier by using machine learning to examine access patterns. This is ideal for data with unknown or changing access patterns.
66. Why is Versioning not available in S3?
Ans:
- Versioning is actually available in Amazon S3 and is a feature that must be explicitly enabled on a per-bucket basis.
- When enabled, Versioning allows to keep several versions of an item in the same bucket, making it possible to reverse accidental deletions or overwrites. Each version of the object is uniquely identified by the version ID.
- The availability of Versioning enhances data security and backup capabilities by making every version of every item stored in the S3 bucket preserveable, retrievable, and reversible.
67. What is Amazon S3 Replication?
Ans:
Amazon S3 Replication is a feature that automatically copies objects across S3 buckets in the same or different AWS Regions. This feature is designed to provide enhanced data availability, redundancy, and cross-region data access. S3 Replication supports several types, including Cross-Region Replication (CRR) and Same-Region Replication (SRR) to meet diverse needs.
68. Describe the use of Object Tags in Amazon S3 and their benefits?
Ans:
Object Tags in Amazon S3 are key-value pairs applied to S3 objects, which can be used for organizing, managing, and controlling access to objects. Tags enable fine-grained access control and can be utilized for cost allocation, simplifying lifecycle management, and applying granular permissions at the object level. They are beneficial for managing and categorizing data, enforcing security policies.
69. How can I make an S3 bucket object list?
Ans:
- To list objects in an S3 bucket, can use the AWS management Console, AWS CLI, or SDK’s. With the AWS CLI, the command aws s3 ls s3://your-bucket-name–recursive lists all objects in a bucket and its subdirectories.
- In the console, navigate to the S3 service, select a bucket, and will see a list of objects. For programmatic access, SDKs like Boto3for Python offer methods to retrieve object lists.
- list_objects()
- list_objects_v2()
70. Describe how to mount an S3 drive to an EC2 instance.
Ans:
To mount an S3 bucket to an EC2 instance, can use a tool like Amazon S3FS or Goofys. These tools allow to mount the S3 bucket as if it were a local file system. After installing S3FS or Goofys on the EC2 instance, can mount the S3 bucket using a command that specifies the bucket name and the mount point. Keep in mind that this method works well for apps that need file system-like access; AWS SDKs or CLI are advised for direct S3 access.
71. How is the AWS S3 CLI installed?
Ans:
- The AWS S3 CLI is part of the AWS CLI tool, which can be installed on various operating systems.
- On most systems, can install it with pip by running pip install awscli or, for a more isolated setup, use a virtual environment.
- Once installed, configure it by running aws configure and entering AWS Access Key ID, Secret Access Key, default region name, and output format.
72. How do I empty the AWS S3 cache?
Ans:
AWS S3 itself does not use a cache that needs to be cleared. If need to clear cached versions of S3 content delivered through Amazon CloudFront, can do so by creating an invalidation request. This request can be submitted either via the AWS Management Console or by using the AWS CLI with the appropriate command to invalidate the cached content.
- aws cloudfront create-invalidation–distribution-id YOUR_DISTRIBUTION_ID –paths “/path/to/object.”
73. How can an AWS S3 bucket be deleted?
Ans:
- To delete an S3 bucket, it must be empty. Can empty a bucket by deleting all its objects, including versioned objects, and deleting markers. After emptying, use the AWS Management Console, AWS CLI, or SDKs to delete the bucket.
- With the CLI, use aws s3 rb s3://bucket-name –force to remove a bucket and all its contents. Always ensure have backed up necessary data before deleting.
74. How can I obtain my AWS S3 access key?
Ans:
AWS S3 access key is part of the AWS IAM user credentials used to access AWS services programmatically. To obtain a new access key, navigate to the IAM console, find the user for which need the key, and create a new access key under the “Security credentials” tab. If retrieving an existing key, note that AWS does not display secret access keys after creation for security reasons, so might need to create a new one if the existing key is lost.
75. What potential drawbacks can using Amazon S3 present?
Ans:
While Amazon S3 offers high durability, availability, and scalability, potential drawbacks include costs associated with data transfer and requests, especially for data-intensive applications. Managing large numbers of objects and access permissions can become complex, potentially leading to misconfigurations or security vulnerabilities. Performance tuning for access patterns requires understanding and effectively implementing S3 features.
76. How can scalability and reliability be configured for Amazon S3?
Ans:
- Amazon S3 is designed to offer exceptional scalability and reliability out of the box, handling virtually unlimited amounts of data and offering 99.9% (11 9’s) durability.
- Scalability does not require manual configuration, as S3 automatically scales to meet demand.
- Reliability is enhanced through features like Cross-Region Replication for geographic redundancy and Versioning to recover from accidental deletions or overwrites.
77. Describe the Snowball?
Ans:
- Using safe, physical devices, Amazon Snowball is a data transit solution that moves massive volumes of data into and out of the AWS cloud.
- It addresses the challenges such as high network costs, long transfer times, and security concerns.
- Snowball devices are rugged shipping containers equipped with storage and network connectivity, ideal for data transfer in settings with spotty or no internet access.
78. Which Storage Classes are offered by Amazon S3?
Ans:
Amazon S3 offers several storage classes: S3 Standard for all-purpose data storing that is often accessed; S3 Intelligent-Tiering for data whose access patterns are unpredictable or inconsistent; S3 Standard-IA and S3 One Zone-IA for long-lived, infrequently accessed data; S3 Glacier and S3 Glacier Deep Archive for low-cost archival data; and S3 Outposts for deploying S3 on-premises for a truly hybrid experience.
79. What are T2 times?
Ans:
AWS EC2 instances, known as T2 instances, provide a base level of CPU performance with the capacity to exceed it. “T2 times” are the times during which these instances run faster than their minimum CPU capacity. CPU Credits are what control this burstable performance; they build up gradually and are depleted during bursts. Workloads requiring bursts of higher CPU performance but not constant full CPU utilization are best suited for T2 instances
80. For what reason does Route 53 offer low latency and high availability?
Ans:
- Amazon Route 53 is designed to provide low latency and high availability for both AWS-hosted and external services.
- It achieves this through a global network of DNS servers, which ensures that DNS queries are answered by the nearest server location, reducing latency.
- Route 53 also offers health checks and automatic routing to healthy endpoints, improving the availability of web applications and services by directing traffic away from failed or unhealthy servers.
81. What makes using a Web Application Firewall necessary?
Ans:
To safeguard web applications from frequent online attacks and vulnerabilities, a Web Application Firewall is required. To guard against malicious attempts to hack the system or exfiltrate data, it filters, monitors, and stops HTTP/S traffic to and from a web application. A WAF helps safeguard applications against threats like SQL injection, cross-site scripting, and application-layer DDoS attacks.
82. Is it possible to ping the default gateway or router connecting subnets?
Ans:
- Yes, it is possible to ping the default gateway or router linking subnets within a VPC (Virtual Private Cloud) on AWS, assuming the security groups and network ACLs (Access Control Lists) are configured to allow ICMP traffic.
- Pinging the default gateway is a common troubleshooting step to ensure network connectivity between instances in different subnets and the Internet or other services.
83. Briefly describe the various types of virtualization available on AWS?
Ans:
- Hardware Virtual Machine (HVM) provides virtualization that is closer to physical hardware, allowing the guest VM to run without modifications.
- Paravirtual (PV) lightweight virtualization necessitates that the guest operating system be aware of the virtual environment.
- Containerization offers a method to virtualize the OS layer, allowing multiple workloads to run on a single OS instance, efficiently using system resources, and simplifying deployment.
84. Describe how SSE-KMS is used in S3?
Ans:
Server-Side Encryption with AWS Key Management Service (SSE-KMS) provides a way to encrypt S3 objects using keys managed in AWS KMS. Unlike SSE-S3, which uses a key for each S3 object, SSE-KMS allows for the use of customer master keys (CMKs) to provide an additional layer of control along with detailed auditing. Can choose to encrypt an item with an AWS KMS key ID when upload it.
85. Describe the S3 Batch Operations?
Ans:
- Amazon S3 Batch Operations allows to manage and apply operations across millions or even billions of objects stored in S3 with a single request.
- This service facilitates large-scale operations, including moving things across buckets, changing object tag sets, altering access restrictions, and recovering archived objects from S3 Glacier without requiring the writing and execution of proprietary application code.
- Users create a job by specifying the S3 bucket, the objects on which the operation will be performed, and the desired action.
86. What is Amazon S3’s consistency model?
Ans:
Amazon S3 offers strong read-after-write consistency for PUTS of new objects and DELETEs. This consistency model applies to both object data and metadata. For overwriting PUTS and DELETES (modifying existing objects), Amazon S3 provides eventual consistency, ensuring that if an object is updated or deleted, all subsequent read requests might not immediately reflect the change.
87. How do AWS Snowcone and AWS storage devices transfer data?
Ans:
Using the AWS Snow Cone service, data is gathered and handled at the source level after coming from sensors and other devices. The data is then transferred, either online or offline, onto Amazon storage devices like S3 buckets. Data sync options allow us to continuously transmit data to AWS sources. Data is transferred to AWS storage devices using the AWS Snowcone service after being processed via Amazon EC2 instances.
88. Is it possible to store data on Amazon S3 across several regions?
Ans:
By default, data stored in Amazon S3 is contained within a single region that specifies. To store data across multiple regions, can manually copy data to buckets in other regions or use Amazon S3’s Cross-Region Replication (CRR) feature. To improve data availability and redundancy, CRR automatically replicates data from one S3 bucket to another bucket situated in a separate AWS region.
89. Which Maven dependencies are necessary in order to use AWS S3?
Ans:
To use AWS S3 in a Java project managed with Maven, must include the AWS SDK for Java dependency for S3 in the pom.xml file. Here’s the correct Maven dependency to include:
com.amazonaws aws-java-sdk-s3 YOUR_DESIRED_VERSION
Replace YOUR_DESIRED_VERSION with the latest version of the SDK or the version that fits project requirements. And find the latest version on Maven Central or the AWS SDK for Java documentation.
90. What requirements must be met in order to use AWS SDK S3 with a Spring Boot application?
Ans:
- Provide AWS credentials through a credentials file, environment variables, or IAM roles if running on EC2 instances or AWS Lambda.
- Configure an AmazonS3 client bean in Spring application context, setting the region and any other required client configurations.
- Ensure AWS user or role has the necessary permissions to perform actions on S3 buckets and objects.