
Last updated on 29th May 2020| 3503
Utilizing Data Analytics Technology Has Several Benefits:
- Data-driven decision-making: Making educated decisions based on data-driven insights is made possible by data analytics technology, which helps businesses to develop more precise and efficient strategies that are in line with their objectives and those of their clients.
- Improved productivity and efficiency: Organisations may uncover inefficiencies, simplify processes, and optimize resource allocation by analyzing enormous volumes of data, which leads to improved productivity and lower operating costs.
- A better understanding of customers: Gaining a better knowledge of consumer behavior, interests, and demands using data analytics enables organizations to create personalized marketing campaigns and customer experiences that increase satisfaction and loyalty.
- Competitive edge: Employing data analytics gives businesses a competitive edge by assisting them in seeing market trends, forecasting client needs, and taking proactive actions to stay ahead of the competition.
- Real-time insights: Because real-time data processing and analysis are made possible by advanced data analytics technologies, organizations are better equipped to take advantage of new opportunities for agile decision-making and to react quickly to changing market circumstances.
- Risk management: Data analytics technology assists in locating possible dangers and spotting abnormalities, enabling businesses to put risk mitigation plans into place and strengthen security measures.
- Innovation and product development: Analysis of market trends and consumer input spurs innovation and directs product development activities, resulting in the production of goods that better satisfy consumer wants and preferences.
- Personal growth and development: People may use data analytics technology to manage their fitness objectives, handle their money, and measure their progress in picking up new skills.
- Data-driven marketing: By segmenting customers based on their behavior and preferences, data analytics allows focused marketing efforts, resulting in more successful campaigns and a greater return on investment.
- Enhanced operational effectiveness: Supply chain management, inventory control, and resource allocation are all enhanced by data analytics, which leads to increased operational effectiveness and cost savings.
- Predictive analytics: Organisations may use data analytics to forecast future trends, anticipate consumer behavior, and prepare for prospective issues by using historical data and statistical algorithms.
- Data visualization: The use of data visualization tools in data analytics technologies enables decision-makers to swiftly interpret complicated information in a simple and intelligible way.
Evolution of Data Science:
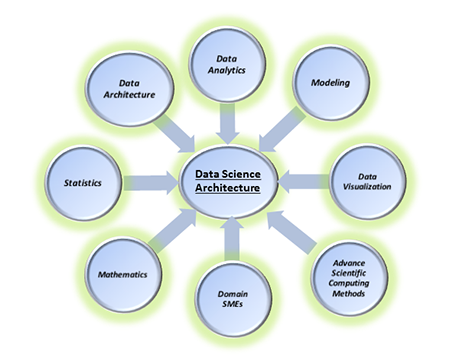
Data Science Components
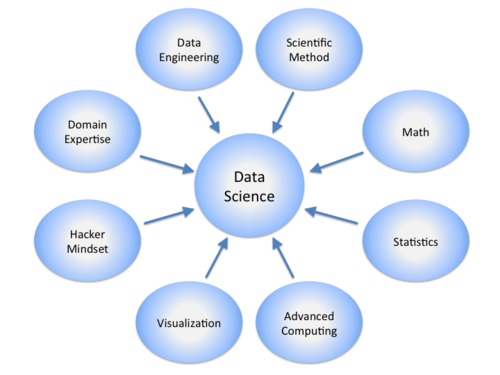
Statistics:
Statistics is data science’s most crucial component. The science or method utilized to draw wise judgments is the collection and analysis of massive amounts of numerical data.
Visualization:
You may access enormous amounts of data in digestible visuals by using visualization techniques.
Machine Learning:
The creation and research of machine learning algorithms is to figure out how to predict unknown or future data.
Deep Learning:
Deep learning is a novel approach to machine learning that selects the appropriate analytical model using an algorithm.
Data Science Methodology:
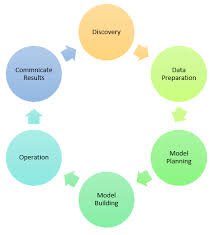
1.Discovery:
In the discovery stage, you gather information from all specified internal and external sources to assist you respond to the business issue.
Data might include:
- Website server logs
- Information gleaned through social media
- Data from censuses
- Data transmitted using APIs from web resources
2.Data Preparation:
Numerous discrepancies in data, such as missing values, blank columns, and improper data formats, need to be cleaned. Before modeling, data has to be processed, explored, and conditioned. Your forecasts will be more accurate the more pure your data is.
3.Model Planning:
You must choose a method and a technique at this point to relate the input variables. Different statistical formulae and visualization techniques are used to plan a model. Among the programs used for this are SAS/access, R, and SQL Analysis Services.
4. Model Building:
The process of actually creating the model begins at this stage. Here, data scientists disperse training and test datasets. On the training data set, methods including association, classification, and clustering are used. Once created, the model is evaluated using the “testing” dataset.
5. Operationalize:
Deliver the final baselined model together with reports, code, and technical papers at this step. After extensive testing, the model is introduced into a live production setting.
6. Communicate Results:
At this step, all stakeholders are informed of the major results. Using the inputs from the model enables you to determine if the project’s outcomes are a success or a failure.

Advance Your Career with Data Science Training By World Class Faculty
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Data Science Tools:

Programming Languages:
- Python: Python is widely used for data processing, analysis, and machine learning because of its broad library of tools, including NumPy, pandas, sci-kit-learn, TensorFlow, and PyTorch.
- R: With tools like ggplot2, dplyr, and caret, R is a well-liked platform for statistical analysis, data visualization, and machine learning.
- SQL: Used to manage structured data, notably for searching databases and retrieving data.
Integrated Development Environments (IDEs):
- Jupyter Notebook / JupyterLab: Interactive and adaptable environments that enable code, visualizations, and explanatory text to be mixed in a single document including Jupyter Notebook and JupyterLab.
- RStudio: RStudio is a potent IDE with capabilities made especially for data science projects and R programming.
Data Visualization Tools:
- Tableau: With Tableau, users can easily build aesthetically appealing dashboards and reports that are interactive.
- Matplotlib / Seaborn (Python): Python libraries for producing static, interactive, and publication-quality visualizations include Matplotlib and Seaborn.
- ggplot2 (R): A flexible and potent visualization software built on the language of graphics concepts is ggplot2 (R).
Machine Learning Libraries:
- Scikit-learn (Python): A complete library for several machine learning methods, such as classification, regression, clustering, and more, is available in Scikit-learn (Python).
- Caret (R): A unified framework for developing and testing machine learning algorithms.
Big Data and Distributed Computing Tools:
- Apache Hadoop: Using the Hadoop Distributed File System (HDFS) and MapReduce, Apache Hadoop is a system for the distributed archiving and processing of big datasets.
- Apache Spark: A quick and adaptable large data processing engine that supports sophisticated analytics and in-memory data processing.
Data Science Technology Challenges:
- Privacy concerns
- Absence of a prominent domain expert
- The talent pool for data science is insufficient.
- It’s challenging to explain data science to other people.
- A data science team is not financially supported by management.
- An extremely tiny organization cannot have a data science team.
- A wide range of facts and information are necessary for thorough analysis.
- Data not available or is difficult to acquire Data Science. outputs not being properly utilized by corporate decision-makers.
Challenges of Machine learning
Here, are primary challenges of Machine learning method:
- It lacks data or diversity in the dataset.
- Machine can’t learn if there is no data available. Besides, a dataset with a lack of diversity gives the Machine a hard time.
- A machine needs to have heterogeneity to learn meaningful insight.
- It is unlikely that an algorithm can extract information when there are no or few variations.
- It is recommended to have at least 20 observations per group to help the Machine learn.
- This constraint may lead to poor evaluation and prediction.
Applications of Machine learning
Here, are Application of Machine learning:
Automation:
Machine learning, which works entirely autonomously in any field without the need for any human intervention. For example, robots performing the essential process steps in manufacturing plants.
Finance Industry:
Machine learning is growing in popularity in the finance industry. Banks are mainly using ML to find patterns inside the data but also to prevent fraud.

Learn On-Demand Data Science Course from Real Time Experts
Weekday / Weekend BatchesSee Batch DetailsGovernment organization:
The government makes use of ML to manage public safety and utilities. Take the example of China with massive face recognition. The government uses Artificial intelligence to prevent jaywalkers.
Healthcare industry:
Healthcare was one of the first industries to use machine learning with image detection.
Which is Better?
The machine learning method is ideal for analyzing, understanding, and identifying a pattern in the data. You can use this model to train a machine to automate tasks that would be exhaustive or impossible for a human being. Moreover, machine learning can take decisions with minimal human intervention.
On the other hand, data science can help you to detect fraud using advanced machine learning algorithms. It also helps you to prevent any significant monetary losses. It helps you to perform sentiment analysis to gauge customer brand loyalty.
What is Machine learning?
Machine Learning is a system that can learn from data through self-improvement and without logic being explicitly coded by the programmer. The breakthrough comes with the idea that a machine can singularly learn from the example (i.e., data) to produce accurate results.
Machine learning combines data with statistical tools to predict an output. This output is then used by corporations to make actionable insights. Machine learning is closely related to data mining and Bayesian predictive modeling. The Machine receives data as input, uses an algorithm to formulate answers.

Roles and Responsibilities of a Data Scientist
Here, are an important skill required to become Data Scientist
- Knowledge about unstructured data management
- Hands-on experience in SQL database coding
- Able to understand multiple analytical functions
- Data mining used for Processing, cleansing, and verifying the integrity of data used for analysis
- Obtain data and recognize the strength
- Work with professional DevOps consultants to help customers operationalize models
Role and Responsibilities of Machine Learning Engineers
Here, are an important skill required to become Machine learning Engineers
- Knowledge of data evolution and statistical modelling
- Understanding and application of algorithms
- Natural language processing
- Data architecture design
- Text representation techniques
- In-depth knowledge of programming skills
- Knowledge of probability and statistics
- Design machine learning systems and knowledge of deep learning technology
- Implement appropriate machine learning algorithms and tools
Difference Between Data Science and Machine Learning
Here are major differences between Data Science and Machine learning:
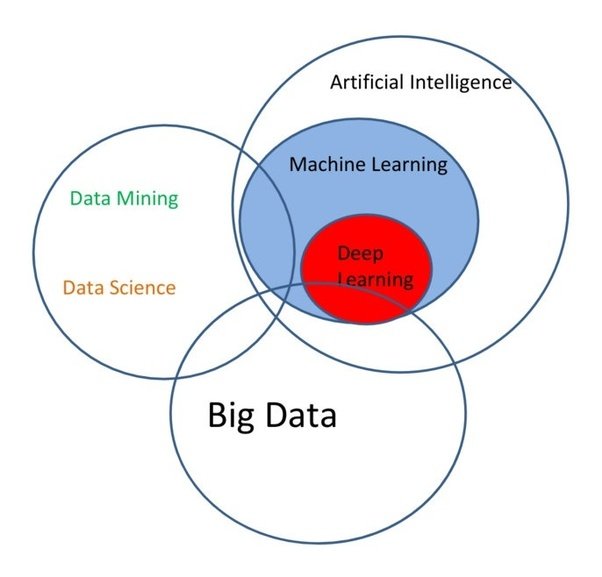
Conclusion of data science :
In this article,The principal purpose of Data Science is to find patterns within data. It uses various statistical techniques to analyze and draw insights from the data. The goal of a Data Scientist is to derive conclusions from the data.Hope you have found all the details that you were looking for, in this article.




