
Last updated on 09th Jul 2025| 10087
- What is Apache Cassandra?
- History and Background
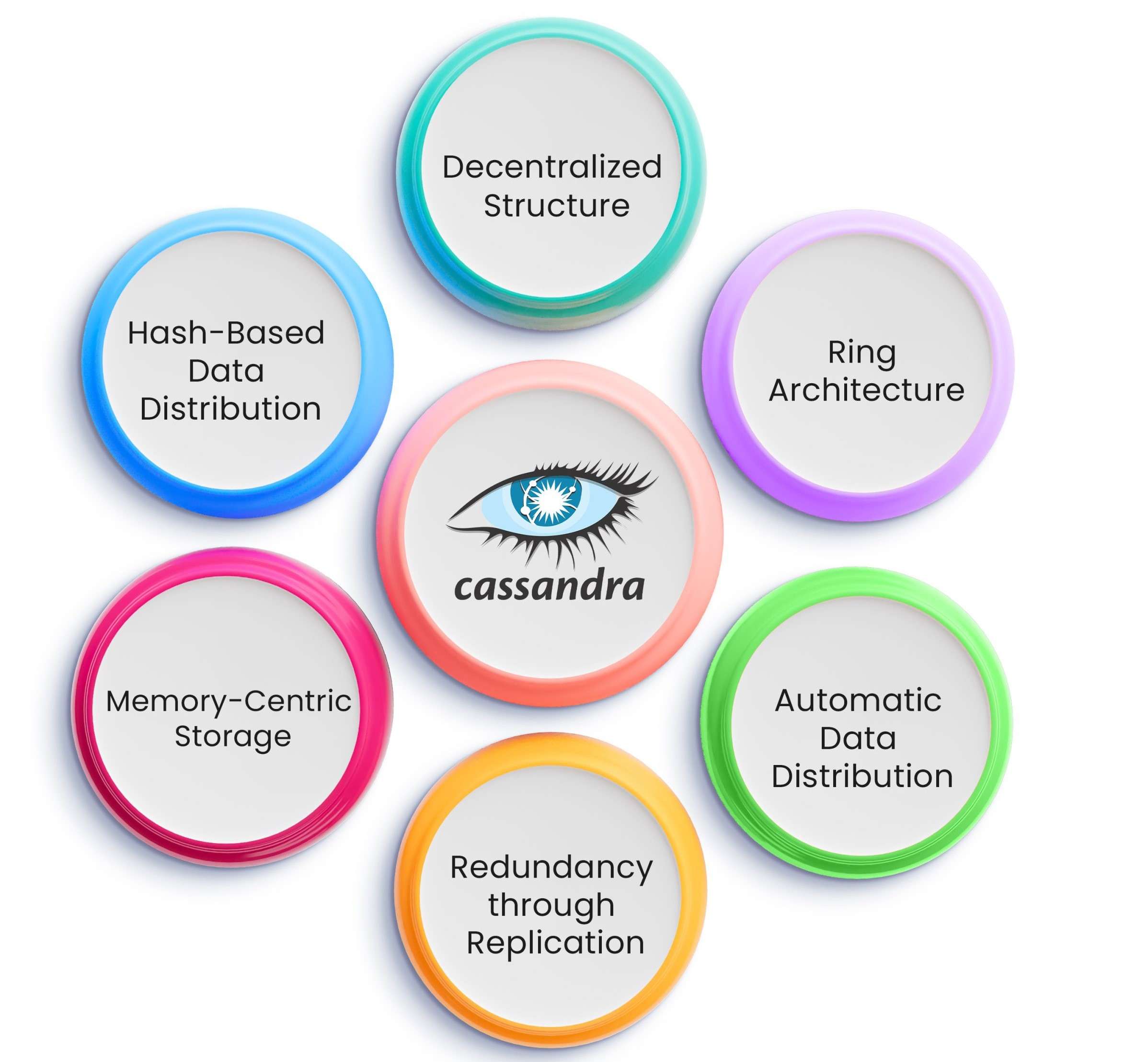
- Key Features
- Column-Family Data Model
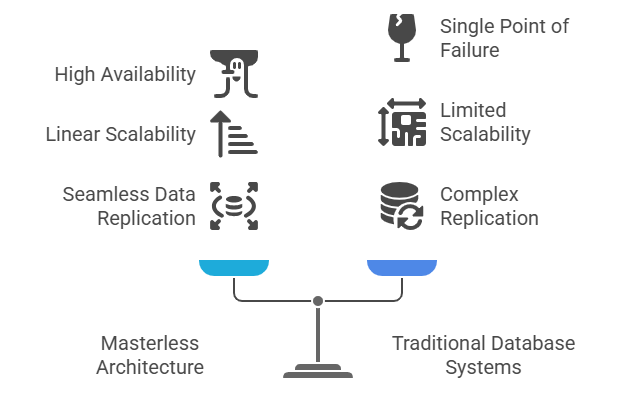
- Masterless Architecture
- Partitioning and Replication
- Use Cases in Big Data
- CQL Cassandra Query Language
What is Apache Cassandra?
Apache Cassandra is an open-source, distributed NoSQL database management system designed to handle massive volumes of structured data across many servers without a single point of failure. Known for its high availability and fault tolerance, Cassandra is ideal for applications that require scalability and continuous uptime, such as real-time analytics and IoT platforms. It uses a peer-to-peer architecture and stores data in a wide-column format, making it highly efficient for write-heavy workloads an essential concept covered in Database Developer Training. One of its core features is the Cassandra Query Language (CQL), which simplifies interaction with the database using an SQL-like syntax. Apache Cassandra AWS integration allows deployment using Amazon Keyspaces or EC2 instances, providing flexibility for cloud-native applications. Additionally, Google Cloud Big Data and Machine Learning services can leverage Cassandra’s powerful data-handling capabilities for training models, building pipelines, and running analytics at scale. With its robust architecture and compatibility with modern cloud ecosystems, Apache Cassandra continues to be a go-to solution for enterprises looking to manage large, distributed datasets efficiently while ensuring high performance and resilience.
Are You Interested in Learning More About Database Certification? Sign Up For Our Database Administration Fundamentals Online Training Today!
History and Background
- Origins at Facebook (2007): Cassandra was initially created by Facebook engineers to power their inbox search feature. It was built to overcome limitations in scalability and availability faced by traditional databases.
- Open-Sourced via Apache (2008): In 2008, Facebook open-sourced Cassandra, and it quickly became an Apache Incubator project. By 2010, it graduated to a top-level Apache project due to strong community adoption.
- NoSQL Movement Rise: Cassandra became a key player in the Cassandra NoSQL ecosystem, offering flexible schema management, distributed architecture, and high write throughput features essential for handling web-scale data making it a valuable point of comparison in MongoDB vs SQL discussions.
Apache Cassandra has evolved into one of the most reliable NoSQL databases used for managing large-scale data with minimal latency. Originally developed to solve scalability challenges at Facebook, Cassandra has grown to power mission-critical applications across industries. Its masterless architecture and decentralized design have made it a preferred choice for cloud-native solutions and big data platforms.
- Cloud Adoption and AWS Integration: With growing cloud usage, AWS Cassandra options like Amazon Keyspaces enable easier deployment and management of Cassandra in the cloud with full compatibility.
- Big Data and Machine Learning Use: Enterprises began integrating Cassandra with Google Big Data services and Google Cloud Dataflow for real-time analytics, ETL processing, and machine learning workflows.
- Masterless Architecture Advantages: Cassandra’s masterless architecture ensures no single point of failure, making it ideal for high-availability applications across distributed environments.
Key Features
Apache Cassandra offers a rich set of key features that make it a powerful choice for handling massive volumes of real-time data across distributed environments. As a leading Cassandra NoSQL database, it provides high availability, linear scalability, and fault tolerance, making it ideal for applications that cannot afford downtime. One of its standout strengths is its masterless architecture, which ensures that all nodes are equal, eliminating single points of failure and allowing seamless scaling by simply adding more nodes. This architecture is a key reason why Cassandra is widely used in mission-critical systems across industries. On the cloud front, AWS Cassandra services like Amazon Keyspaces allow organizations to deploy and manage Cassandra workloads with ease, ensuring high performance and low-latency access. Its wide-column data model offers flexibility for developers building dynamic applications. Cassandra also integrates smoothly with modern data ecosystems; for instance, it works efficiently with Google Big Data solutions to process large scale datasets highlighting important contrasts often explored in MongoDB Vs MySQL comparisons. Additionally, with Google Cloud Dataflow, users can build data pipelines that leverage Cassandra’s real-time capabilities for streaming analytics and machine learning tasks. These features collectively make Apache Cassandra a robust, scalable, and cloud-friendly database ideal for today’s data-driven enterprises.
Are You Interested in Learning More About Database Certification? Sign Up For Our Database Administration Fundamentals Online Training Today!
Column-Family Data Model
- Structure Similar to Tables: A column family in Cassandra is similar to a table in relational databases, but more flexible. Each row can have a different set of columns, allowing for dynamic data modeling.
- High Read and Write Efficiency: The column-family model supports efficient read and write operations, especially when dealing with large volumes of data. This makes it perfect for time-series data and logging systems.
- Seamless Cloud Integration: Using Apache Cassandra AWS, users can deploy column-family models on Amazon Keyspaces or EC2, enabling scalable and reliable cloud-based applications.
- CQL Support: The Cassandra Query Language (CQL) allows developers to interact with column families using an SQL-like syntax, simplifying data operations without sacrificing flexibility an approach that aligns closely with foundational concepts taught in What Is Database Administration.
- Big Data Applications: The column-family model integrates well with Google Cloud Big Data and Machine Learning services for storing and analyzing complex, high-volume datasets.
- Customizable Data Structures: Developers can design column families tailored to application-specific needs, supporting features like composite keys and wide rows for optimal performance.
The column-family data model is at the heart of Apache Cassandra’s architecture. Unlike traditional relational databases that use rows and tables, Cassandra stores data in column families, offering greater flexibility and performance for large-scale distributed applications. This model is well-suited for handling diverse and evolving data structures, making it ideal for modern cloud and big data use cases.

Masterless Architecture
The masterless architecture of Apache Cassandra is one of its most powerful and defining features, setting it apart from traditional database systems. In a masterless setup, every node in the cluster has the same role and capabilities, which eliminates any single point of failure and ensures continuous availability even if multiple nodes go offline. This architecture is particularly advantageous for businesses requiring high availability and fault tolerance across geographically distributed data centers. Cassandra NoSQL leverages this design to enable seamless data replication, allowing any node to handle read and write requests efficiently. With its ability to scale linearly by simply adding more nodes, Cassandra is perfectly suited for large-scale, data-intensive applications an architecture thoroughly covered in Database Administration Fundamentals Online Training. On the cloud front, AWS Cassandra services such as Amazon Keyspaces allow users to benefit from this masterless architecture while enjoying the scalability and flexibility of the cloud. In the realm of advanced analytics and automation, integration with Google Big Data platforms and Google Cloud Dataflow enables developers to build powerful real-time pipelines and analytics workflows. By supporting a decentralized model and distributed processing, Cassandra empowers modern enterprises to handle massive workloads with speed, reliability, and efficiency, making it a go-to solution for next-gen applications and global-scale systems.
Partitioning and Replication
Partitioning and replication are core mechanisms in Apache Cassandra that enable it to manage large volumes of distributed data with high performance and fault tolerance. Partitioning in Cassandra involves distributing data across multiple nodes using a consistent hashing algorithm, which ensures an even load and efficient access patterns. Each piece of data is assigned to a specific partition key, and this key determines the node responsible for storing that data. Replication, on the other hand, ensures data durability and availability by copying data to multiple nodes within a cluster. The replication factor can be configured based on the desired level of fault tolerance and consistency. Using Cassandra Query Language (CQL), developers can define how data should be partitioned and replicated through keyspace configurations, making it easier to control data distribution similar in purpose to defining a Primary Key In SQL for ensuring structured and reliable data access. Apache Cassandra AWS implementations, such as on Amazon Keyspaces, maintain these core functionalities, enabling businesses to build highly available and scalable applications in the cloud. Moreover, integration with Google Cloud Big Data and Machine Learning platforms allows organizations to perform real-time analytics and intelligent data processing on partitioned and replicated datasets. This approach ensures fast data access, resilience, and seamless scalability, making Cassandra a preferred choice for enterprise-grade, cloud-native applications.
Use Cases in Big Data
Apache Cassandra is widely adopted in big data environments due to its ability to handle large-scale, high-velocity data across distributed systems with exceptional reliability. One of its standout features, the masterless architecture, allows every node in the cluster to perform read and write operations independently, ensuring zero downtime and high availability, ideal for real-time analytics and globally distributed applications. In the context of Cassandra NoSQL, this architecture supports flexible schema designs and massive write throughput, making it suitable for use cases like IoT data ingestion, social media analytics, fraud detection, and time-series monitoring. AWS Cassandra solutions, such as Amazon Keyspaces, extend these benefits to the cloud, allowing businesses to scale seamlessly without managing infrastructure an advantage that contrasts with performance tuning techniques like Types Of SQL Indexes used in traditional relational databases. Cassandra also integrates well with Google Big Data tools, supporting large-scale analytics pipelines and data lakes. Additionally, Google Cloud Dataflow can be used alongside Cassandra to build powerful stream and batch processing pipelines, enabling real-time insights and intelligent decision-making across sectors like finance, healthcare, and e-commerce. Its ability to store and serve petabytes of data with low latency and high reliability positions Cassandra as a core technology for modern big data strategies, empowering organizations to act on data faster and more efficiently than ever before.
Are You Preparing for Database Developer Jobs? Check Out ACTE’s DBMS Interview Questions and Answers to Boost Your Preparation!
CQL Cassandra Query Language
Cassandra Query Language (CQL) is the primary interface for interacting with Apache Cassandra, offering a familiar, SQL-like syntax tailored for the Cassandra NoSQL architecture. Unlike traditional SQL, CQL is designed specifically to work with Cassandra’s distributed, masterless architecture, allowing users to define schemas, insert, update, and query data efficiently across large clusters. CQL simplifies complex operations by abstracting the underlying data model, such as column families and partitions, making it easier for developers to manage and retrieve data without deep knowledge of Cassandra’s internal mechanics a key topic explored in Database Administration Fundamentals Online Training. In AWS Cassandra environments like Amazon Keyspaces, CQL is fully supported, enabling cloud-native applications to execute powerful queries with high availability and scalability. CQL also plays a critical role in building real-time data applications that integrate with Google Cloud Dataflow, supporting dynamic pipelines and streaming analytics. Combined with Google Big Data solutions, CQL allows organizations to query vast datasets stored in Cassandra while maintaining performance and fault tolerance. Whether it’s logging user activity, tracking sensor data, or supporting recommendation systems, CQL offers the flexibility and control needed to manage big data workloads in modern, distributed environments, making it a cornerstone in the evolving landscape of scalable data processing.




