
Last updated on 08th Jul 2025| 10688
- Introduction to Cassandra
- Background and Development
- Key Features and Benefits
- Architecture Overview
- Data Model and CQL
- Replication and Partitioning
- Read and Write Path
- Consistency and CAP Theorem
- Use Cases and Applications
- Tools and Ecosystem
- Final Thoughts
Introduction to Cassandra
Apache Cassandra is an open-source, distributed NoSQL database designed to handle large volumes of data across many commodity servers, providing high availability and no single point of failure. It was originally developed at Facebook to power the inbox search feature and later became an Apache top-level project. Cassandra is known for its decentralized design and scalability, making the apache cassandra architecture ideal for fault-tolerant systems.
Are You Interested in Learning More About Database? Sign Up For Our Database Online Training Today!
Background and Development
Cassandra combines elements from Amazon’s Dynamo and Google’s Bigtable to offer a unique and powerful platform for distributed data management. It was open-sourced by Facebook in 2008 and became an Apache Incubator project the same year. Over time, it has evolved through contributions from major tech companies and a robust open-source community, making it one of the most popular NoSQL databases in use today. Facebook originally created Cassandra to solve the challenge of storing and retrieving large volumes of user data with high performance and reliability. This design need led to a system that could remain operational even during network partitions or hardware failures. The database’s architecture allows it to run on low-cost hardware, making it economically viable for organizations of all sizes.
Key Features and Benefits
- Decentralized Architecture: All nodes are equal; no master-slave configuration.
- High Availability: Ensures continuous uptime even if some nodes fail.
- Linear Scalability: Easily add new nodes without downtime.
- Tunable Consistency: Choose between eventual and strong consistency.
- Flexible Schema: Ideal for dynamic or semi-structured data.
These features make Cassandra well-suited for applications that demand high write throughput and no single point of failure, a defining feature of apache cassandra architecture that sets it apart from traditional systems. Its write-optimized nature also allows for quick ingestion of data without bottlenecks, and the ability to fine-tune consistency levels gives developers control over data accuracy versus speed trade-offs.
To Explore Database in Depth, Check Out Our Comprehensive Database Online Training To Gain Insights From Our Experts!
Architecture Overview
Cassandra uses a peer-to-peer architecture where each node communicates with others through a protocol called Gossip. It employs consistent hashing to distribute data evenly across the cluster. Data is stored in keyspaces, which contain column families (tables), and each piece of data is replicated based on the defined replication strategy. Key architectural components include:
- Gossip Protocol: For node communication.
- Anomaly Detection: Determine the topology of nodes.
- Snitches: Replication Strategy:
- Replication Strategy: Determines how data is copied across nodes.
- Token Ring: These components are often illustrated in an apache cassandra architecture diagram to show node interactions and data flow.
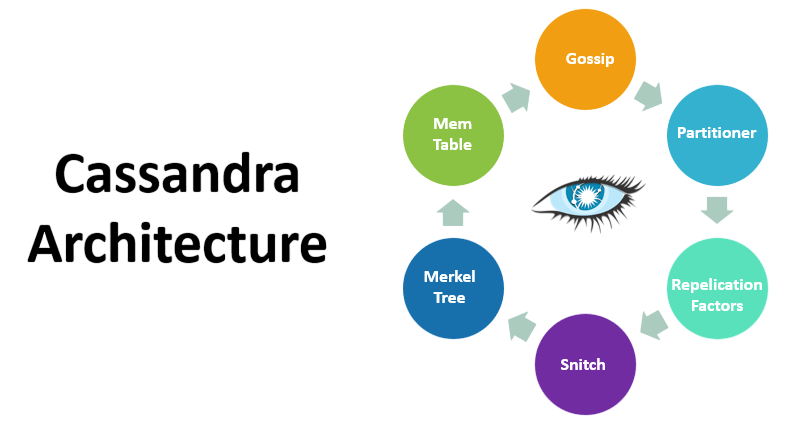
Cassandra uses a Log-Structured Merge Tree (LSM Tree) mechanism for managing data on disk, optimizing write operations, and ensuring data integrity. Each write operation is first logged in a commit log, written into a memory structure (Memtable), and periodically flushed into immutable SSTables on disk.

Data Model and CQL
Apache Cassandra data modeling uses a wide-column approach that supports flexibility and denormalized designs. Cassandra employs a wide-column data model, enabling the storage of large datasets in a tabular format with rows and columns. Its data model supports the nesting of data and the addition of new columns at runtime.
- Keyspace: Equivalent to a database.
- Table: Stores data in rows and columns.
- Row: Uniquely identified by a primary key.
- Column: Data field within a row.
- CREATE TABLE users (
- user_id UUID PRIMARY KEY,
- name TEXT,
- email TEXT
- );
- The client sends a write request to a coordinator node.
- Data is recorded in the commit log.
- Written to an in-memory Memtable.
- When the Memtable is full, it is flushed to disk as an SSTable.
- The coordinator node identifies which replica has the data.
- It checks the Memtable and row cache.
- Uses Bloom filters, partition index, and SSTables to find data.
- Merges data from different sources and returns the result.
- ONE: Fast but less consistent.
- QUORUM: Balanced approach.
- ALL: Most consistent but slowest.
- IoT Platforms: Store time-series data from sensors.
- Social Media Analytics: Analyze large volumes of unstructured user-generated content.
- Real-Time Recommendation Engines: Personalize content based on real-time user behavior.
- Financial Fraud Detection Systems: Detect anomalies across globally distributed data.
- Healthcare Data Platforms: Maintain patient records and device telemetry data.
- DataStax Enterprise: Commercial distribution with enterprise support.
- Cassandra Reaper: For repair management.
- Cassandra Medusa: Backup and restore.
- Apache Spark: For real-time analytics.
- OpsCenter: Management and monitoring UI.
- CQLSH: Command-line shell for interacting with Cassandra.
- JMX: Java Management Extensions for performance metrics.
- Nodetool: Utility for maintenance operations.
Cassandra allows for denormalized data modeling, where related information is stored together to optimize reads. Unlike traditional relational models, relationships between tables are minimized. CQL (Cassandra Query Language) resembles SQL and is used for creating schemas and performing CRUD operations. Example:
CQL (Cassandra Query Language) resembles SQL and is used for creating schemas and performing CRUD operations. Example:Replication and Partitioning
It distributes data with a partition key and a consistent hashing method, making sure the load is shared evenly. This method of partitioning is crucial for the data modeling strategies in Apache Cassandra to support high performance at scale. To keep data safe and always accessible, Cassandra makes several copies of the same data, a process called replication. There are two main strategies: SimpleStrategy for single data center setups and NetworkTopology Strategy for multiple data centers. The replication factor determines how many copies are stored, balancing availability with storage needs. Choosing the right replication method is important for creating strong data modeling strategies in Apache Cassandra that effectively manage both performance and resilience.
Read and Write Path
Write Path:
Read Path:
The process is optimized through techniques like speculative retries, hinted handoff, and read repair to maintain data integrity and reduce latency. These mechanisms are part of what makes Apache Cassandra architecture highly optimized for large-scale workloads.
Want to Learn About Database? Explore Our Database Interview Questions and Answers Featuring the Most Frequently Asked Questions in Job Interviews.
Consistency and CAP Theorem
Cassandra follows the AP (Availability and Partition Tolerance) model of the CAP theorem. However, its tunable consistency allows configurations to favor consistency as needed.
You can define the consistency level for reads and writes:
The ability to set different levels for different operations makes Cassandra flexible for varying business needs. The consistency is ensured through features like Read Repair, Hinted Handoff, and Anti-Entropy repairs.
Use Cases and Applications
Cassandra is ideal for applications requiring massive data writes, fault tolerance, and geographic distribution. Common use cases include
Large enterprises like Netflix, Instagram, and eBay have adopted Cassandra for its reliability and performance under heavy load. Its scalability makes it suitable for use cases that demand customized Apache Cassandra data modeling.
Tools and Ecosystem
Apache Cassandra architecture is supported by a range of powerful tools for monitoring, backup, and performance optimization.
Sometimes, displaying an Apache Cassandra architecture diagram helps in monitoring health and understanding system behavior more clearly.
Limitations and Challenges
Working with Apache Cassandra presents unique challenges that need careful planning. One of the biggest problems is the complexity of data modeling. Because Cassandra uses a denormalized approach, developers must design the schema around specific queries. This makes data modeling strategies crucial from the beginning. Another issue is write amplification. Cassandra often compacts SSTables, which increases disk I/O and affects performance. Routine maintenance, like running repairs and compactions, adds to the operational workload. Although Cassandra supports secondary indexes, they have limited functionality and are not suitable for complex queries. Understanding Cassandra data modeling strategies helps reduce these problems and ensures your system works reliably over time. Despite these challenges, Cassandra continues to evolve with improvements in compaction strategies, especially during apache cassandra data modeling. Where schema design impacts read and write efficiency. new query optimizations and better management tools.
Final Thoughts
Apache Cassandra architecture continues to evolve with a focus on resilience, scale, and performance. Apache Cassandra remains a powerful solution for businesses needing robust, high-performance databases with no downtime. It excels in environments where high throughput, fault tolerance, and scalability are critical. Whether you’re building IoT solutions, social networks, or financial systems, Cassandra offers the tools and flexibility to scale with your business. Understanding an apache cassandra architecture diagram helps teams manage nodes and replication strategies better. With continuous community contributions and new enterprise integrations, Cassandra’s future as a NoSQL leader looks promising. Mastering Cassandra requires time and effort, but the payoff is a resilient and performant data infrastructure capable of supporting mission-critical applications across the globe.




