
Last updated on 19th Jul 2020| 2346
Machine learning is an application of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. Machine learning focuses on the development of computer programs that can access data and use it learn for themselves.
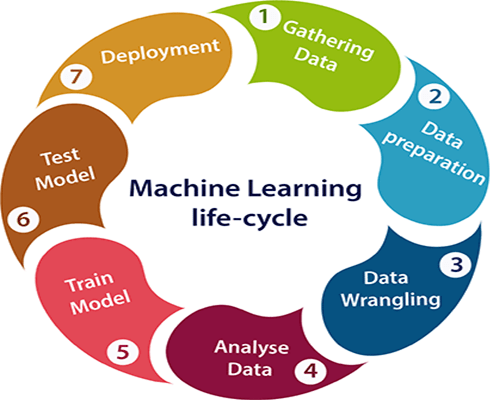
Machine learning Life cycle
Machine learning has given the computer systems the abilities to automatically learn without being explicitly programmed. But how does a machine learning system work? So, it can be described using the life cycle of machine learning. Machine learning life cycle is a cyclic process to build an efficient machine learning project. The main purpose of the life cycle is to find a solution to the problem or project.
Machine learning life cycle involves seven major steps, which are given below:
- Gathering Data
- Data preparation
- Data Wrangling
- Analyse Data
- Train the model
- Test the model
- Deployment
The most important thing in the complete process is to understand the problem and to know the purpose of the problem. Therefore, before starting the life cycle, we need to understand the problem because the good result depends on the better understanding of the problem.
In the complete life cycle process, to solve a problem, we create a machine learning system called “model”, and this model is created by providing “training”. But to train a model, we need data, hence, life cycle starts by collecting data.
1. Gathering Data:
Data Gathering is the first step of the machine learning life cycle. The goal of this step is to identify and obtain all data-related problems.
In this step, we need to identify the different data sources, as data can be collected from various sources such as files, database, internet, or mobile devices. It is one of the most important steps of the life cycle. The quantity and quality of the collected data will determine the efficiency of the output. The more will be the data, the more accurate will be the prediction.
This step includes the below tasks:
- Identify various data sources
- Collect data
- Integrate the data obtained from different sources
By performing the above task, we get a coherent set of data, also called as a dataset. It will be used in further steps.
2. Data preparation
After collecting the data, we need to prepare it for further steps. Data preparation is a step where we put our data into a suitable place and prepare it to use in our machine learning training.
In this step, first, we put all data together, and then randomize the ordering of data.
This step can be further divided into two processes:
- Data exploration:
It is used to understand the nature of data that we have to work with. We need to understand the characteristics, format, and quality of data.
A better understanding of data leads to an effective outcome. In this, we find Correlations, general trends, and outliers. - Data pre-processing:
Now the next step is preprocessing of data for its analysis.
3. Data Wrangling
Data wrangling is the process of cleaning and converting raw data into a useable format. It is the process of cleaning the data, selecting the variable to use, and transforming the data in a proper format to make it more suitable for analysis in the next step. It is one of the most important steps of the complete process. Cleaning of data is required to address the quality issues.
It is not necessary that data we have collected is always of our use as some of the data may not be useful. In real-world applications, collected data may have various issues, including:
- Missing Values
- Duplicate data
- Invalid data
- Noise
So, we use various filtering techniques to clean the data.
It is mandatory to detect and remove the above issues because it can negatively affect the quality of the outcome.
4. Data Analysis
Now the cleaned and prepared data is passed on to the analysis step. This step involves:
- Selection of analytical techniques
- Building models
- Review the result
The aim of this step is to build a machine learning model to analyze the data using various analytical techniques and review the outcome. It starts with the determination of the type of the problems, where we select the machine learning techniques such as Classification, Regression, Cluster analysis, Association, etc. then build the model using prepared data, and evaluate the model.
Hence, in this step, we take the data and use machine learning algorithms to build the model.
5. Train Model
Now the next step is to train the model, in this step we train our model to improve its performance for better outcome of the problem.
We use datasets to train the model using various machine learning algorithms. Training a model is required so that it can understand the various patterns, rules, and, features.
6. Test Model
Once our machine learning model has been trained on a given dataset, then we test the model. In this step, we check for the accuracy of our model by providing a test dataset to it.
Testing the model determines the percentage accuracy of the model as per the requirement of project or problem.
7. Deployment
The last step of machine learning life cycle is deployment, where we deploy the model in the real-world system.
If the above-prepared model is producing an accurate result as per our requirement with acceptable speed, then we deploy the model in the real system. But before deploying the project, we will check whether it is improving its performance using available data or not. The deployment phase is similar to making the final report for a project.
Algorithms
For the majority of newcomers, machine learning algorithms may seem too boring and complicated subject to be mastered. Well, to some extent, this is true. In most cases, you stumble upon a few-page description for each algorithm and yes, it’s hard to find time and energy to deal with each and every detail. However, if you truly, madly, deeply want to be an ML-expert, you have to brush up your knowledge regarding it and there is no other way to be. But relax, today I will try to simplify this task and explain core principles of 10 most common algorithms in simple words (each includes a brief description, guides, and useful links). So, breath in, breath out, and let’s get started!
1. Principal Component Analysis (PCA)/SVD
This is one of the basic machine learning algorithms. It allows you to reduce the dimension of the data, losing the least amount of information. It is used in many areas, such as object recognition, computer vision, data compression, etc. The computation of the principal components is reduced to calculating the eigenvectors and eigenvalues of the covariance matrix of the original data or to the singular decomposition of the data matrix.
We can express several signs through one, merge, so to speak, and work already with a simpler model. Of course, most likely, it will not be possible to avoid information loss, but the PCA method will help us to minimize it.
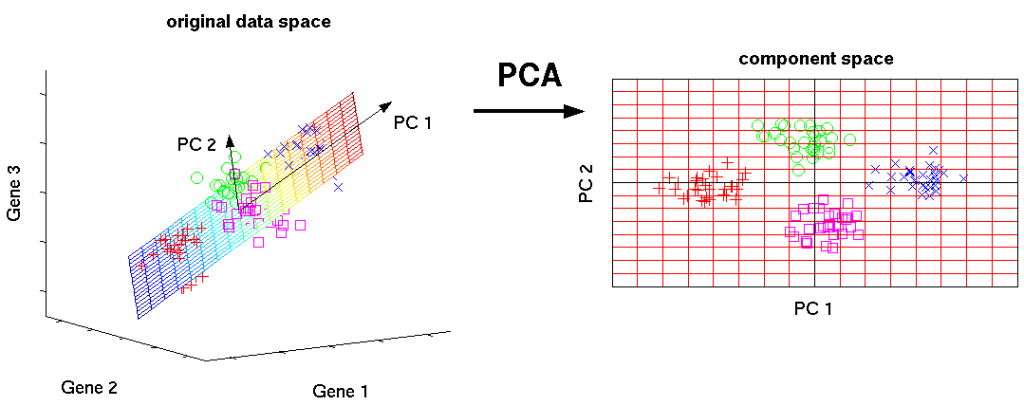
SVD — this is a way to calculate ordered components.
2a. Least Squares and Polynomial Fitting
The method of least squares is a mathematical method used to solve various problems, based on minimizing the sum of squares of deviations of some functions from the desired variables. It can be used to “solve” overdetermined systems of equations (when the number of equations exceeds the number of unknowns), to search for solutions in the case of ordinary (not overdetermined) nonlinear systems of equations, as well as to approximate the point values of a certain function.
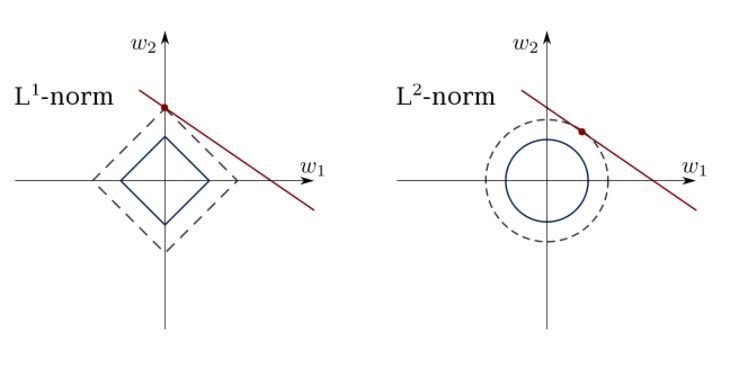
2b. Constrained Linear Regression
The least squares method can confuse overshoots, false fields, etc. Restrictions are needed to reduce the variance of the line that we put in the data set. The correct solution is to match the linear regression model, which ensures that the weights do not behave “badly”.
Models can be L1 (LASSO) or L2 (Ridge Regression) or both (elastic regression).
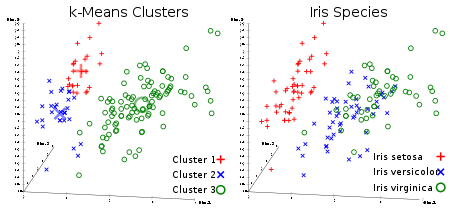
3. K-Means Clustering
Everyone’s favorite uncontrolled clustering algorithm. But, let’s clarify what clustering is:
Clustering (or cluster analysis) is the task of breaking up a set of objects into groups called clusters. Inside each group, there should be “similar” objects, and the objects of different groups should be as different as possible. The main difference between clustering and classification is that the list of groups is not clearly defined and is determined during the operation of the algorithm.
The k-means algorithm is the simplest, but at the same time, rather inaccurate clustering method in the classical implementation. It splits the set of elements of a vector space into a previously known number of clusters k.
The algorithm seeks to minimize the standard deviation at the points of each cluster. The basic idea is that at each iteration the center of mass is recalculated for each cluster obtained in the previous step, then the vectors are divided into clusters again according to which of the new centers was closer in the selected metric. The algorithm terminates when no cluster changes at any iteration.
4. Logistic Regression
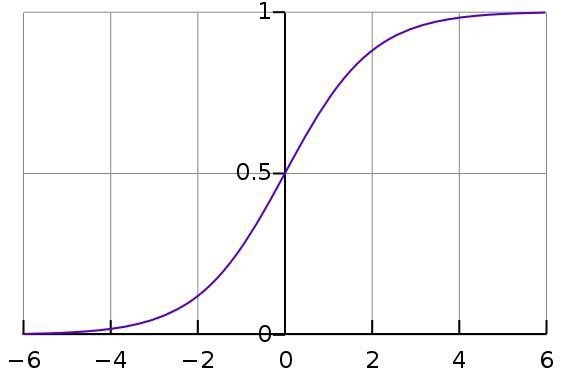
Logistic regression is limited to linear regression with non-linearity (sigmoid function or tanh is mainly used) after applying weights, therefore, the output limit is close to + / — classes (which equals 1 and 0 in the case of sigmoid). Cross-entropy loss functions are optimized using the gradient descent method.
Note for beginners: logistic regression is used for classification, not regression. In general, it is similar to a single-layer neural network. Learned using optimization techniques such as gradient descent or L-BFGS. NLP developers often use it, calling it “the maximum entropy classification method”.

Get On-Demand Machine Learning Training to Enhance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
This is what a sigmoid looks like:
5. Support Vector Machines (SVM)
SVM is a linear model, such as linear/logistic regression. The difference is that it has a margin-based loss function. You can optimize the loss function using optimization methods, for example, L-BFGS or SGD.
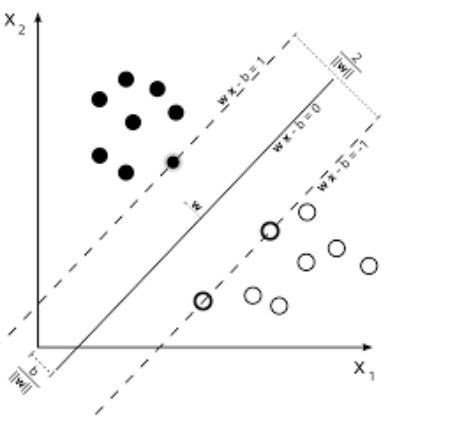
One unique thing that SVMs can do is to study classifier classifiers.
6. Feed-Forward Neural Networks
Basically, these are multi-level logistic regression classifiers. Many layers of scales are separated by non-linearities (sigmoid, tanh, relu + softmax and cool new selu). They are also called multilayer perceptrons. FFNN can be used for classifying and “learning without a teacher” as autoencoders.
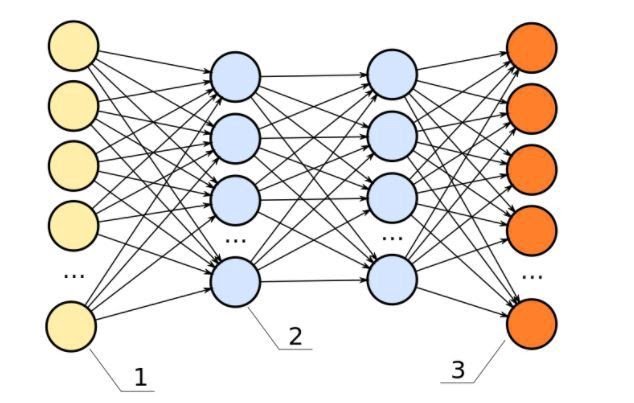
FFNN can be used to train a classifier or extract functions as autoencoders.
7. Convolutional Neural Networks
Practically all modern achievements in the field of machine learning were achieved by dint of convolutional neural networks. They are used for image classification, object detection, or even image segmentation. Invented by Jan Lekun at the beginning of the 1990s, networks have convolutional layers that act as hierarchical object extractors. You can use them for working with text (and even for working with graphics).
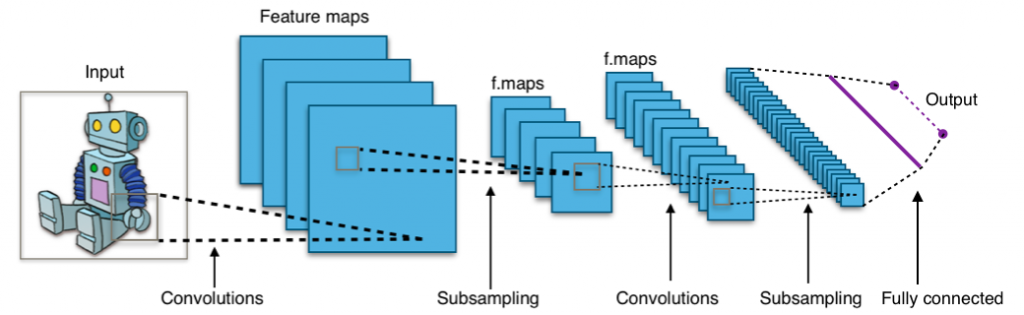
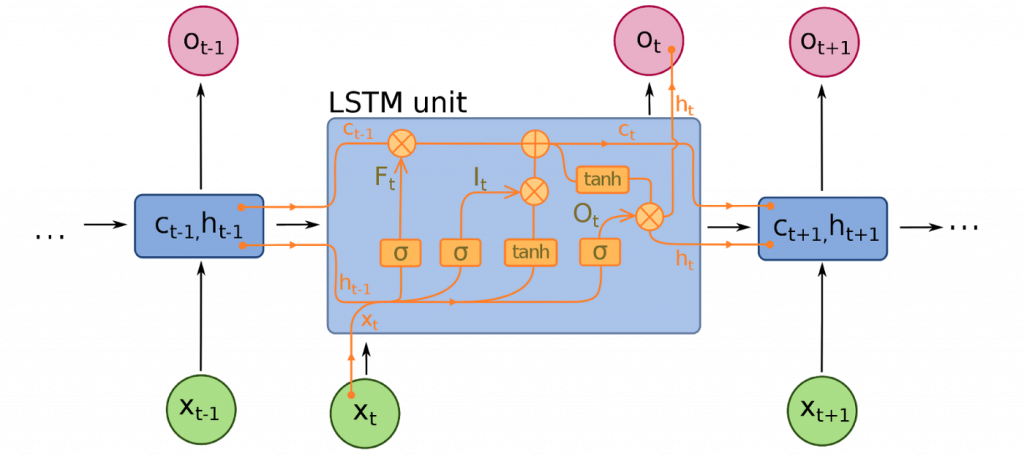
8. Recurrent Neural Networks (RNNs)
RNNs model sequences by applying the same set of weights recursively to the state of the aggregator at time t and input at time t. Pure RNNs are rarely used now, but its analogs, for example, LSTM and GRU, are the most up-to-date in most sequence modeling problems.
LSTM, which is used instead of a simple dense layer in pure RNN.
9. Conditional Random Fields (CRFs)
They are used to simulate a sequence like an RNN and can be used in conjunction with an RNN. They can also be used in other tasks of structured prediction, for example, in image segmentation. CRF models each element of the sequence (say, a sentence), so that the neighbors affect the label of the component in the sequence, and not all labels that are independent of each other.

Best JOB Oriented Machine Learning Training Course from Real-Time Experts
Weekday / Weekend BatchesSee Batch Details10. Decision Trees
One of the most common machine learning algorithms. Used in statistics and data analysis for predictive models. The structure represents the “leaves” and “branches”. Attributes of the objective function depend on the “branches” of the decision tree, the values of the objective function are recorded in the “leaves”, and the remaining nodes contain attributes for which the cases differ.
To classify a new case, you need to go down the tree to the leaf and give the appropriate value. The goal is to create a model that predicts the value of the target variable based on several input variables.
Applications of Machine learning
Machine learning is a buzzword for today’s technology, and it is growing very rapidly day by day. We are using machine learning in our daily life even without knowing it such as Google Maps, Google assistant, Alexa, etc. Below are some most trending real-world applications of Machine Learning:
1. Image Recognition:
Image recognition is one of the most common applications of machine learning. It is used to identify objects, persons, places, digital images, etc. The popular use case of image recognition and face detection is, Automatic friend tagging suggestion:
Facebook provides us a feature of auto friend tagging suggestion. Whenever we upload a photo with our Facebook friends, then we automatically get a tagging suggestion with name, and the technology behind this is machine learning’s face detection and recognition algorithm.
It is based on the Facebook project named “Deep Face,” which is responsible for face recognition and person identification in the picture.
2. Speech Recognition
While using Google, we get an option of “Search by voice,” it comes under speech recognition, and it’s a popular application of machine learning.
Speech recognition is a process of converting voice instructions into text, and it is also known as “Speech to text”, or “Computer speech recognition.” At present, machine learning algorithms are widely used by various applications of speech recognition. Google assistant, Siri, Cortana, and Alexa are using speech recognition technology to follow the voice instructions.
3. Traffic prediction:
If we want to visit a new place, we take help of Google Maps, which shows us the correct path with the shortest route and predicts the traffic conditions.
It predicts the traffic conditions such as whether traffic is cleared, slow-moving, or heavily congested with the help of two ways:
- Real Time location of the vehicle form Google Map app and sensors
- Average time has taken on past days at the same time.
Everyone who is using Google Map is helping this app to make it better. It takes information from the user and sends back to its database to improve the performance.
4. Product recommendations:
Machine learning is widely used by various e-commerce and entertainment companies such as Amazon, Netflix, etc., for product recommendation to the user. Whenever we search for some product on Amazon, then we started getting an advertisement for the same product while internet surfing on the same browser and this is because of machine learning.
Google understands the user interest using various machine learning algorithms and suggests the product as per customer interest.
As similar, when we use Netflix, we find some recommendations for entertainment series, movies, etc., and this is also done with the help of machine learning.
5. Self-driving cars:
One of the most exciting applications of machine learning is self-driving cars. Machine learning plays a significant role in self-driving cars. Tesla, the most popular car manufacturing company is working on self-driving car. It is using unsupervised learning method to train the car models to detect people and objects while driving.
6. Email Spam and Malware Filtering:
Whenever we receive a new email, it is filtered automatically as important, normal, and spam. We always receive an important mail in our inbox with the important symbol and spam emails in our spam box, and the technology behind this is Machine learning. Below are some spam filters used by Gmail:
- Content Filter
- Header filter
- General blacklists filter
- Rules-based filters
- Permission filters
Some machine learning algorithms such as Multi-Layer Perceptron, Decision tree, and Naïve Bayes classifier are used for email spam filtering and malware detection.
7. Virtual Personal Assistant:
We have various virtual personal assistants such as Google assistant, Alexa, Cortana, Siri. As the name suggests, they help us in finding the information using our voice instruction. These assistants can help us in various ways just by our voice instructions such as Play music, call someone, Open an email, Scheduling an appointment, etc.
These virtual assistants use machine learning algorithms as an important part.
These assistant record our voice instructions, send it over the server on a cloud, and decode it using ML algorithms and act accordingly.
8. Online Fraud Detection:
Machine learning is making our online transaction safe and secure by detecting fraud transaction. Whenever we perform some online transaction, there may be various ways that a fraudulent transaction can take place such as fake accounts, fake ids, and steal money in the middle of a transaction. So to detect this, Feed Forward Neural network helps us by checking whether it is a genuine transaction or a fraud transaction.
For each genuine transaction, the output is converted into some hash values, and these values become the input for the next round. For each genuine transaction, there is a specific pattern which gets change for the fraud transaction hence, it detects it and makes our online transactions more secure.
9. Stock Market trading:
Machine learning is widely used in stock market trading. In the stock market, there is always a risk of up and downs in shares, so for this machine learning’s long short term memory neural network is used for the prediction of stock market trends.
10. Medical Diagnosis:
In medical science, machine learning is used for diseases diagnoses. With this, medical technology is growing very fast and able to build 3D models that can predict the exact position of lesions in the brain.
11. Automatic Language Translation:
Nowadays, if we visit a new place and we are not aware of the language then it is not a problem at all, as for this also machine learning helps us by converting the text into our known languages. Google’s GNMT (Google Neural Machine Translation) provide this feature, which is a Neural Machine Learning that translates the text into our familiar language, and it called as automatic translation.
The technology behind the automatic translation is a sequence to sequence learning algorithm, which is used with image recognition and translates the text from one language to another language.
Conclusion
Well, if you read all the information and even click on a few guides, I sincerely congratulate you for having done a good job. Now is the right time to add some useful advice. Well, it’s quite a typical situation when newcomers ask questions like this: Which algorithm to use? Is it possible to focus on a specific algorithm, and not to consider the rest at all? The answer to this always sounds as follows: ‘it’s all depends on the circumstances’.
What does this mean? For example, one cannot say that neural networks always work better than decision trees, and vice versa. The effectiveness of algorithms is influenced by many factors, such as the size and structure of the data set and more. So, do not expect to dive into the best algorithm, cause it simply does not exist.




