
Last updated on 20th Dec 2021| 2890
MongoDB is a document database while Postgres is a relational database management system; MongoDB has a distributed architecture while PostgreSQL has a monolithic architecture; and Postgres uses SQL.
- Introduction
- MongoDB versus PostgreSQL
- Postgresql versus MongoDB Overview
- PostgreSQL versus MongoDB Terminology and Concepts
- Contrasting the MongoDB Query Language with SQL
- Settling on the Decision: MongoDB or PostgreSQL?
- Conclusion
- PostgreSQL is an open source object-social information base framework that utilises and expands the SQL language joined with many highlights that securely store and scale the most muddled information jobs. The beginnings of PostgreSQL date back to 1986 as a component of the POSTGRES project at the University of California at Berkeley and has over 30 years of dynamic advancement on the center stage.
- PostgreSQL has gained notoriety for its demonstrated design, unwavering quality, information respectability, vigorous list of capabilities, extensibility, and the devotion of the open source local area behind the product to reliably convey performant and imaginative arrangements. PostgreSQL runs on all major working frameworks, has been ACID-agreeable beginning around 2001, and has incredible additional items, for example, the famous PostGIS geospatial data set extender. It is nothing unexpected that PostgreSQL has turned into the open source social data set of decision for some individuals and associations.
Introduction:
MongoDB is an archive of NoSQL data set utilized for high volume information stockpiling. Rather than utilizing tables and columns as in the customary social data sets, MongoDB utilizes assortments and reports. Archives consist of key-esteem sets which are the fundamental unit of information in MongoDB. Assortments contain sets of archives and capacities which is what could be compared to social information base tables. MongoDB is an information base which came into light around the mid-2000s.
- PostgreSQL is an unshakable, open source, endeavor grade SQL data set that has been extending its abilities for a long time. All that you could at any point need from a social information base is available in PostgreSQL, which depends on a scale-up design. Assuming your interests are similarity, presenting a large number of questions from many tables, exploiting existing SQL abilities, and stretching SQL to the edge, PostgreSQL will work effectively.
MongoDB versus PostgreSQL:
MongoDB is the main archive information base. It is based on a conveyed, scale-out engineering and has turned into a thorough cloud-based stage for overseeing and conveying information to applications. MongoDB handles value-based, functional, and insightful jobs at scale. Assuming your interests are an ideal opportunity to showcase, engineer usefulness, supporting DevOps and nimble procedures, and building stuff that scales without functional vaulting, MongoDB is the best approach.
- Assuming you are toward the start of an improvement project and are trying to sort out your requirements and information model by utilizing a spry advancement process, MongoDB will sparkle since engineers can reshape the information all alone, when they need to. MongoDB empowers you to oversee information of any design, not simply plain constructions characterized ahead of time.
- Assuming you are supporting an application you realize should scale as far as volume of traffic or size of information (or both) and that should be conveyed across districts for information region or information sway, MongoDB’s scale-out design will address those issues naturally.
- Assuming you need a multi-cloud data set that works the same way in each open cloud, can store client information in explicit geographic districts, and backing the most recent serverless and portable improvement standards, MongoDB Atlas is the ideal decision.
- Assuming you are a SQL shop and presenting another worldview will cost more than some other advantages referenced will balance, PostgreSQL is a decision that will probably address every one of your issues.
- Assuming you need a social information base that will run complex SQL inquiries and work with loads of existing applications dependent on an even, social information model, PostgreSQL will do the work.
- To stretch SQL to the edge by utilizing progressed methods for ordering, putting away and looking through various organized information types, making client characterized capacities in an assortment of dialects, and tuning the data set as far as possible, you probably will actually want to go further with PostgreSQL than some other RDBMS.
- Thus, presently that the rest has been fulfilled, the patient can make a more profound jump into MongoDB, then, at that point, PostgreSQL, and afterward an examination.
- MongoDB: The Scalable Document Database That Has Become a Data Platform
- The Beauty of the Document Model MongoDB’s record information model guides normally to objects in application code, simplifying it for designers to learn and utilize. Reports enable you to address various leveled connections to store exhibits and other more complicated constructions without any problem. JSON records can store information in fields, as exhibits, or even as settled sub-archives. Thus, related data can be put away together for quick question access through the rich and expressive MongoDB inquiry language.
- MongoDB stores information as records in a double portrayal called BSON (Binary JSON). Fields can change from one record to another; there is no compelling reason to proclaim the construction of reports to the framework – archives are self-portraying. Assuming another field should be added to a report, then, at that point, the field can be made without influencing any remaining records in the assortment, without refreshing a focal framework index, refreshing an ORM, and without taking the framework disconnected. Alternatively, mapping approval can be utilized to uphold information administration powers over every assortment.
- This adaptability is gigantically valuable while solidifying data from different sources or obliging varieties in reports over the long run, particularly as new application usefulness is constantly conveyed.
Postgresql versus MongoDB Overview
Be that as it may, once more, for the individuals who need the story immediately, here is an outline of our overall direction:

Learn Advanced MongoDB Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details- PostgreSQL
- MongoDB
- Corrosive Transactions
- Corrosive Transactions
- Table
- Assortment
- Column
- Archive
- Segment
- Field
- Auxiliary Index
- Auxiliary Index
- JOINs, UNIONs
- Implanted reports, $lookup and $graphLookup, $unionWith
- Emerged Views
- On-request Materialized Views
- GROUP_BY
- Accumulation Pipeline
- Upgrades to the Document Model
- MongoDB permits you to store information in practically any construction, and each field – even those profoundly settled in subdocuments and clusters – can be recorded and effectively looked at
- MongoDB adds components to the archive model and the question motor to deal with both geospatial and time series labeling of information. This grows the kind of inquiries and investigations that can be performed on a data set.
- BSON incorporates information types not present in JSON information (e.g., datetime, int, long, date, drifting point, and decimal128, and byte exhibit) offering type-severe dealing with for quite some time types rather than a general “number” type.
- Outline approval empowers you to apply administration and information quality controls to your blueprint.
- Corrosive Transactions for Changes to Many Documents One of the most remarkable elements of social data sets that make composing applications simpler is ACID exchanges. The subtleties of how ACID exchanges are characterized and carried out fill numerous software engineering course readings. A large part of the conversation in the software engineering domain is about confinement levels in data set exchanges. PostgreSQL defaults to the read submitted disengagement level, and permits clients to adjust that to the serializable confinement level.
- The significant thing to recall is that exchanges permit many changes to a data set to be made in a gathering or moved back in a gathering.
- In a social information base, the information being referred to would be displayed across isolated parent-youngster tables in a plain composition. This implies that refreshing every one of the records without a moment’s delay would require an exchange.
- It could be said, record information bases make some simpler memories executing exchanges since they group information in an archive and composing and perusing a report is a nuclear activity so it needn’t bother with a multi-record exchange. At least one field might be written in a solitary activity, including updates to different subdocuments and components of an exhibit. MongoDB ensures total detachment as a record is refreshed. Any blunders will trigger the update activity to reign in, returning the change and guaranteeing that customers get a reliable perspective on the archive.
- MongoDB additionally upholds data set exchanges across many archives, so lumps of related changes can be submitted or moved back collectively. With its multi-archive exchanges capacity, MongoDB is one of only a handful of exceptional information bases to consolidate the ACID certifications of conventional social data sets with the speed, adaptability, and force of the record model.
- According to the software engineer point of view, exchanges in MongoDB feel very much like exchanges designers are now acquainted with in PostgreSQL. Exchanges in MongoDB are multi-articulation, with comparative punctuation (e.g., starttransaction and committransaction) with depiction isolation,and are thus simple for anybody with earlier exchange insight to add to any application.
PostgreSQL versus MongoDB Terminology and Concepts
A significant number of the terms and ideas utilized in MongoDB’s record model are something similar or like PostgreSQL’s plain model:
- To make this work, in PostgreSQL and any remaining SQL data sets, the information base blueprint should be made and information connections set up before the data set is populated with information. Related data might be put away in discrete tables, however related using Foreign Keys and JOINs. Most changes in composition require a relocation method that can take the data set disconnected or lessen application execution while it is running.
- The strength of SQL is its amazing and broadly known question language, with a huge biological system of devices.
- The test of utilizing a social information base is the need to characterize its construction ahead of time. Changing design subsequent to stacking information is frequently undeniably challenging, requiring different groups across advancement, DBA, and Ops to firmly facilitate changes.
- Presently in the report information base universe of MongoDB, the construction of the information doesn’t need to be arranged front and center in the data set and it is a lot simpler to change. Designers can conclude what’s required in the application and change it in the information base in a like manner.
- MongoDB doesn’t utilize SQL naturally. All things being equal, to work with reports in MongoDB and concentrate information, MongoDB gives its own question language (MQL) that offers the majority of a similar power and adaptability as SQL. For instance, as SQL, MQL permits you to reference information from numerous tables, change and total that information, and channel for the particular outcomes you really want. Dissimilar to SQL, MQL works in a way that is colloquial for each programming language.
- Inquiry execution in MongoDB can be sped up by making files on fields in archives and subdocuments. MongoDB permits any field of a record, incorporating those profoundly settled in exhibits and subdocuments, to be filed and effectively questioned.
- The accompanying outline thinks about the SQL and MongoDB ways to deal with questioning information and shows a couple of instances of SQL articulations and how they guide to MongoDB:
- MongoDB depends on a dispersed design that permits clients to scale out across many examples, and is demonstrated to control enormous applications, regardless of whether estimated by clients or information sizes. The scale-out procedure depends on utilizing a bigger number of more modest and generally economical machines. This methodology can extend to many machines.
- In PostgreSQL, the way to deal with scaling relies upon whether you are looking at composing or understanding information. For composes, it depends on a scale-up design, in which a solitary essential machine running PostgreSQL should be made as incredible as conceivable to scale. For peruses, it is feasible to scale-out PostgreSQL by making copies, however every imitation should contain a full duplicate of the information base.
- The pipes that make MongoDB versatile depend on the possibility of cleverly apportioning (sharding) information across cases in the bunch. MongoDB doesn’t split records up; reports are autonomous units which makes it more straightforward to convey them across different servers while saving information.
- In the completely made-up, worldwide MongoDB Atlas cloud administration, it’s not difficult to convey information across areas. Certain archives can be labeled so they will forever be truly put away in explicit nations or geographic districts. Such area mindfulness can:
- Decline inertness by putting away the information close to its interest group Help agree with laws concerning where information might be legitimately put away
- Each MongoDB shard runs as an imitation set: a synchronized bunch of at least three individual servers that constantly repeat information between them, offering repetition and insurance against personal time even with a framework disappointment or arranged upkeep. Reproductions can likewise be introduced across datacenters, offering flexibility against local blackouts. Making and designing such bunches is made much simpler and quicker in MongoDB Atlas.
- MongoDB has carried out a cutting edge set-up of network safety controls and reconciliations both for its on-reason and cloud adaptations. This incorporates amazing security ideal models like customer side field-level encryption, which permits information to be encoded before it is sent over the organization to the data set.
- PostgreSQL has a full scope of safety highlights including many kinds of encryption. PostgreSQL is accessible in the cloud on all significant cloud suppliers. While it is overall a similar data set, functional and designer tooling shifts by cloud seller, which makes relocations between various mists more perplexing. MongoDB Atlas runs similarly across each of the three significant cloud suppliers, working on movement and multi-cloud sending.
Contrasting the MongoDB Query Language with SQL
The social data set model that PostgreSQL utilizes depends on putting away information in tables and afterward utilizing Structured Query Language (SQL) for data set admittance.
- Heaps of information the board and BI apparatuses depend on SQL and programatically produce complex SQL explanations to get the perfect assortment of information from the data set. PostgreSQL does very well in such settings since it is a hearty, venture grade execution that is perceived by numerous engineers.
- Additionally, assuming you have a level, even information model that won’t change all the time and doesn’t have to scale-out, social data sets and SQL can be an amazing decision.
- Yet, the apparent advantages of SQL have costs that should be thought of. The disadvantage of PostgreSQL contrasted with MongoDB is that it depends on social information models that are antagonistic to the information structures designers work with in code, and that should be characterized ahead of time, easing back progress at whatever point prerequisites change.
- MongoDB upholds a fast, iterative pattern of advancement so well due to the way that an archive information base transforms information into code heavily influenced by designers. This speed is disturbed by the idea of inflexible, even information models utilized in social data sets, which generally should be reshaped by data set executives through an intermediated cycle, which eases back the whole course of improvement. Such bottlenecks can discourage advancement.
- At the point when an application goes live, PostgreSQL clients should be prepared to quarrel over adaptability. PostgreSQL utilizes a scale-up methodology. This implies that eventually, for superior execution use cases, you might reach a stopping point or need to redirect assets to tracking down alternate ways of scaling by means of reserving or denormalizing information or utilizing different methodologies.
- In MongoDB such strategies are typically not needed in light of the fact that versatility is inherent through local sharding, empowering a level scale-out approach. Later appropriately sharding a group, you can generally add more cases and continue to scale out. MongoDB Atlas has a wide multi-cloud, all around the world mindful stage primed and ready, all completely overseen for you.
- PostgreSQL can uphold replication yet further developed elements, for example, programmed failover should be upheld by outsider items grown freely of the information base. Such a methodology is more mind boggling and can work increasingly slow flawlessly than MongoDB’s in-assembled self-mending abilities.
Settling on the Decision: MongoDB or PostgreSQL?
Abandoning SQL implies leaving an enormous environment of innovation that as of now utilizes SQL. That is simpler to do assuming you are dealing with another application, or plan on modernizing a current one.
Conclusion :-
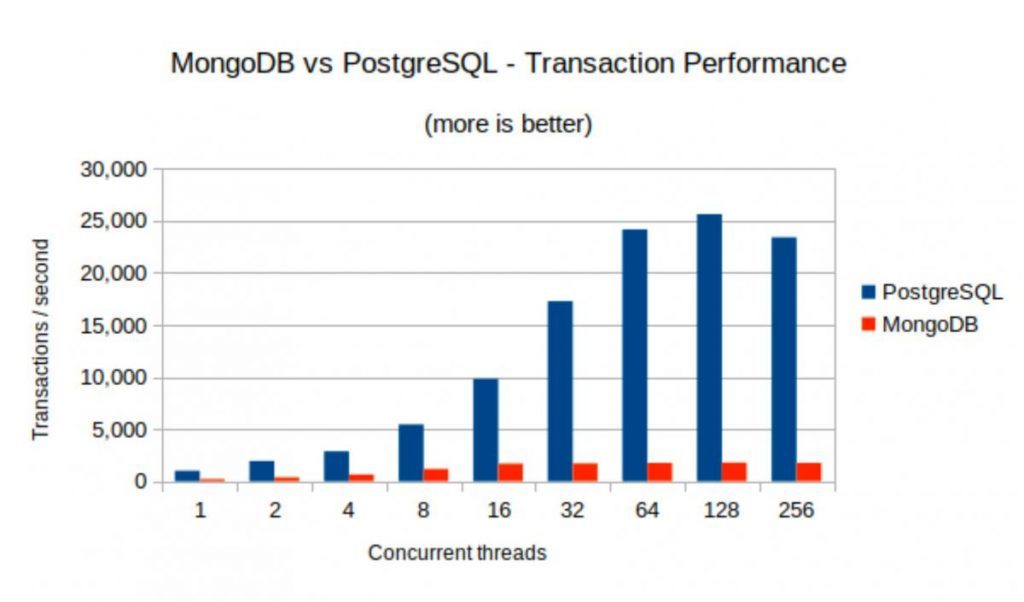
MongoDB is 130 times slower than Postgres because the only join tactic available is to iterate over employees, for each one performing a lookup in the department table. In contrast, Postgres can use this tactic (called iterative substitution) as well as merge join and hash join, and the Postgres query optimizer will pick the expected best strategy. MongoDB is constrained to a single strategy. Whenever (as is almost always the case) this single strategy is inferior, poor performance will result.




