Last updated on 09th Jul 2020| 2152
Amazon Simple Storage Service (Amazon S3) is storage for the internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web. You can accomplish these tasks using the AWS Management Console, which is a simple and intuitive web interface.
To get the most out of Amazon S3, you need to understand a few simple concepts. Amazon S3 stores data as objects within buckets. An object consists of a file and optionally any metadata that describes that file. To store an object in Amazon S3, you upload the file you want to store to a bucket. When you upload a file, you can set permissions on the object and any metadata.
Buckets are the containers for objects. You can have one or more buckets. For each bucket, you can control access to it (who can create, delete, and list objects in the bucket), view access logs for it and its objects, and choose the geographical region where Amazon S3 will store the bucket and its contents.
Advantages of using Amazon S3
Amazon S3 is intentionally built with a minimal feature set that focuses on simplicity and robustness. Following are some of the advantages of using Amazon S3:
- Creating buckets: Create and name a bucket that stores data. Buckets are the fundamental containers in Amazon S3 for data storage.
- Storing data: Store an infinite amount of data in a bucket. Upload as many objects as you like into an Amazon S3 bucket. Each object can contain up to 5 TB of data. Each object is stored and retrieved using a unique developer-assigned key.
- Downloading data: Download your data or enable others to do so. Download your data anytime you like, or allow others to do the same.
- Permissions: Grant or deny access to others who want to upload or download data into your Amazon S3 bucket. Grant upload and download permissions to three types of users. Authentication mechanisms can help keep data secure from unauthorized access.
- Standard interfaces: Use standards-based REST and SOAP interfaces designed to work with any internet-development toolkit.
Amazon S3 concepts
This section describes key concepts and terminology you need to understand to use Amazon S3 effectively. They are presented in the order that you will most likely encounter them.
Topics
- Buckets
- Objects
- Keys
- Regions
- Amazon S3 data consistency model
Buckets
A bucket is a container for objects stored in Amazon S3. Every object is contained in a bucket. For example, if the object named photos/puppy.jpg is stored in the awsexamplebucket1 bucket in the US West (Oregon) Region, then it is addressable using the URL https://awsexamplebucket1.s3.us-west-2.amazonaws.com/photos/puppy.jpg.
Buckets serve several purposes:
- They organize the Amazon S3 namespace at the highest level.
- They identify the account responsible for storage and data transfer charges.
- They play a role in access control.
- They serve as the unit of aggregation for usage reporting.
You can configure buckets so that they are created in a specific AWS Region. For more information, see Accessing a Bucket. You can also configure a bucket so that every time an object is added to it, Amazon S3 generates a unique version ID and assigns it to the object. For more information, see Using Versioning.
Amazon S3 features
This section describes important Amazon S3 features.
Topics
- Storage classes
- Bucket policies
- AWS identity and access management
- Access control lists
- Versioning
- Operations
Storage classes
Amazon S3 offers a range of storage classes designed for different use cases. These include Amazon S3 STANDARD for general-purpose storage of frequently accessed data, Amazon S3 STANDARD_IA for long-lived, but less frequently accessed data, and S3 Glacier for long-term archive.
Bucket policies
Bucket policies provide centralized access control to buckets and objects based on a variety of conditions, including Amazon S3 operations, requesters, resources, and aspects of the request (for example, IP address). The policies are expressed in the access policy language and enable centralized management of permissions. The permissions attached to a bucket apply to all of the objects in that bucket.
Both individuals and companies can use bucket policies. When companies register with Amazon S3, they create an account. Thereafter, the company becomes synonymous with the account. Accounts are financially responsible for the AWS resources that they (and their employees) create. Accounts have the power to grant bucket policy permissions and assign employees permissions based on a variety of conditions. For example, an account could create a policy that gives a user write access:
- To a particular S3 bucket
- From an account’s corporate network
- During business hours
An account can grant one user limited read and write access, but allow another to create and delete buckets also. An account could allow several field offices to store their daily reports in a single bucket. It could allow each office to write only to a certain set of names (for example, “Nevada/*” or “Utah/*”) and only from the office’s IP address range.
Unlike access control lists (described later), which can add (grant) permissions only on individual objects, policies can either add or deny permissions across all (or a subset) of objects within a bucket. With one request, an account can set the permissions of any number of objects in a bucket. An account can use wildcards (similar to regular expression operators) on Amazon Resource Names (ARNs) and other values. The account could then control access to groups of objects that begin with a common prefix or end with a given extension, such as .html.
Only the bucket owner is allowed to associate a policy with a bucket. Policies (written in the access policy language) allow or deny requests based on the following:
- Amazon S3 bucket operations (such as PUT ?acl), and object operations (such as PUT Object, or GET Object)
- Requester
- Conditions specified in the policy
An account can control access based on specific Amazon S3 operations, such as GetObject, GetObjectVersion, DeleteObject, or DeleteBucket.
The conditions can be such things as IP addresses, IP address ranges in CIDR notation, dates, user agents, HTTP referrer, and transports (HTTP and HTTPS).
Amazon S3 Bucket
Step 1: Create an Amazon S3 Bucket
First, you need to create an Amazon S3 bucket where you will store your objects.
- Sign in to the preview version of the AWS Management Console.
- Under Storage & Content Delivery, choose S3 to open the Amazon S3 console.If you are using the Show All Services view, your screen looks like this: If you are using the Show Categories view, your screen looks like this with Storage & Content Delivery expanded:From the Amazon S3 console dashboard, choose Create Bucket.
- In Create a Bucket, type a bucket name in Bucket Name.The bucket name you choose must be globally unique across all existing bucket names in Amazon S3 (that is, across all AWS customers). For more information, see Bucket Restrictions and Limitations.
- In Region, choose Oregon.
- Choose Create.When Amazon S3 successfully creates your bucket, the console displays your empty bucket in the Buckets pane.
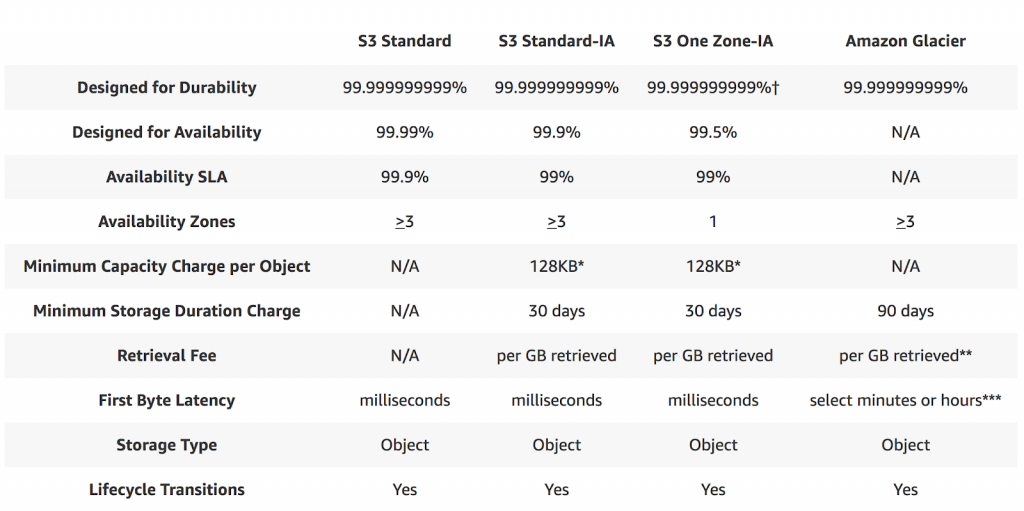
Availability and Durability
When we look for any service to integrate into our application, the major thing we look for is the reliability (and durability) of the service? How frequently the service goes down and what happens to our data if something goes wrong? To keep those things in mind, I am going to list out S3 availability and durability standards first, before we dive into the other features.
- S3 Standard offers 99.99% availability and 99.999999999% durability (Yes, that many 9s)
- S3 IA offers 99.9% availability and 99.99% durability
- S3 One Zoned-IA offers 99.5% availability and 99.999999999% durability, but data will be lost in the event of Availability Zone destruction (data center site failure)
- Glacier offers 99.99% availability and 99.999999999% durability
- S3 RRS is designed to provide 99.99% durability and 99.99% availability
Object Store
Amazon S3 is a simple key, value store designed to store as many objects as you want. You store these objects in one or more buckets. An object consists of the following:

Enroll in Instructor-led Amazon S3 Training Course to UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details- Key: The name that you assign to an object. You use the object key to retrieve the object.
- Version ID: Within a bucket, a key and version ID uniquely identify an object
- Value: The content that we are storing
- Metadata: A set of name-value pairs with which you can store information regarding the object.
- Sub resources: Amazon S3 uses the subresource mechanism to store object-specific additional information.
- Access Control Information: We can control access to the objects in Amazon S3.
Data Bucket
Before we store any data into S3, we first have to create a Bucket. A bucket is similar to how we create a folder on the local system, but with a catch that the bucket name has to be unique across all of the AWS accounts. So for example, if someone has created a S3 bucket, my-backup-files, then no other AWS account can create the S3 bucket with similar name.Inside the bucket, we can have folders or files. There is no limit on how much of data that we can store inside a bucket.Amazon S3 creates buckets in a region we specify. To optimize latency, minimize costs, or address regulatory requirements, we can choose any AWS Region that is geographically close to our requirement. For example, if we reside in Europe, then we should create buckets in the EU (Ireland) or EU (Frankfurt) regions.
By default, you can create up to 100 buckets in each of your AWS accounts. If you need additional buckets, you can increase your bucket limit by submitting a service limit increase.
S3 Bucket is HTTP(s) enabled, so we can access the objects stored inside them with a unique URL. For example, if the object named image/logo.jpg is stored in the appgambit bucket, then it is addressable using the URLhttp://appgambit.s3.amazonaws.com/images/logo.jpg. However, the file is only accessible if it has public-read permission.
Version Control
Versioning allows us to preserve, retrieve, and restore every version of every object stored inside an Amazon S3 bucket. Once you enable Versioning for a bucket, Amazon S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them.
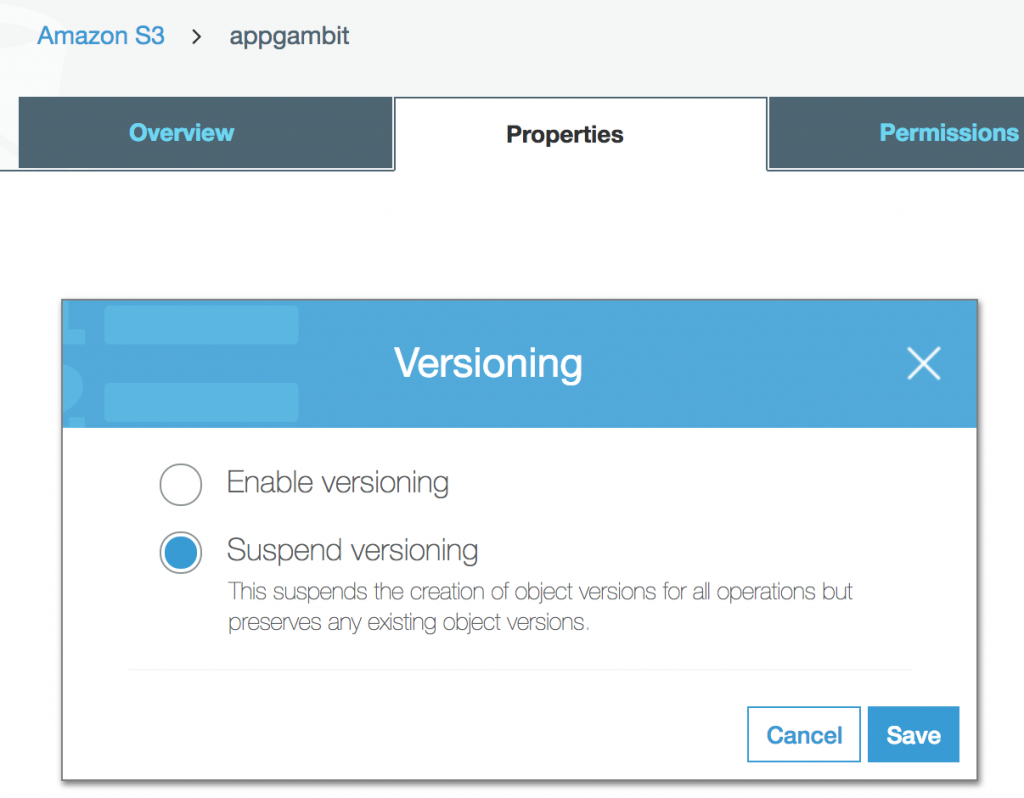
Versioning option for a bucket:
By default, GET requests will retrieve the latest written version object. Older versions of an overwritten or deleted object can be retrieved by specifying a version in the request.
Versioning also gives an additional layer of protection to avoid accidental deletion of objects. When a user performs a DELETE operation on an object, subsequent simple (un-versioned) requests will no longer retrieve the object. However, all versions of that object will continue to be preserved in your Amazon S3 bucket and can be retrieved or restored. Only the owner of an Amazon S3 bucket can permanently delete a version.
Once the Versioning is enabled, it can only be suspended but cannot be disabled. S3 considers each version of the object as a separate object for billing, so make sure you are enabling the Versioning for a particular reason.
Static Web Hosting
Static Web Hosting is one of the most powerful features of the AWS S3. Single Page Applications or Pure JavaScript Applications are in trend nowadays and with AWS S3 we can easily deploy an application and start using immediately without setting up any machine anywhere.
This is one of the important building blocks for developing Serverless Web Application.
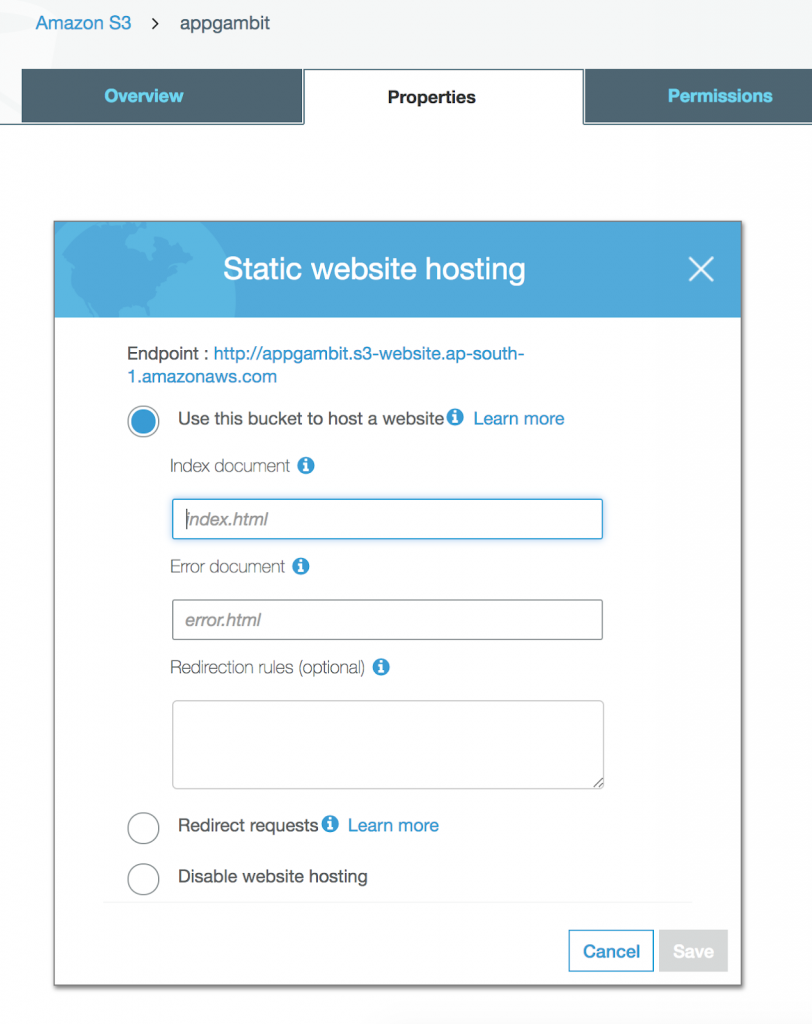
Enable Static Web Hosting for a bucket
Once the Static Web Hosting is enabled, it will generate a URL which we can use to start accessing our application.
Because AWS S3 buckets are placed regionally, by default Web Site will also be serving from the same region. If you are deploying the application for a specific region, then make sure the S3 bucket is created in that region.
If you are deploying the application globally, then you can serve AWS S3 content with AWS CloudFront which works as a CDN to distribute the files on AWS Edge Locations network. This will make sure application is taking minimum latency for loading anywhere in the world.
Backup & Recovery
By default, the AWS S3 provides the same level of durability and availability across all the regions. But then also the things can go wrong, so most organisations when they use Cloud to host their data, would like to have backup and recovery in their plan.
AWS S3 provides a simple mechanism to create a backup for data, Cross Region Replication. Cross-region Replication enables automatic and asynchronous copying of objects across buckets in different AWS regions. This is useful in case we want to fast access our data in different regions or create a general backup of the data.
Cross Region Replication requires Versioning enabled, so this will have an impact on your AWS billing amount as well. The CRR includes Versioning cost as well as the Data Transfer cost.
Security
Amazon takes security very seriously. Being in Cloud and serving to the thousands of organizations using these services means an exceptional level of security is required. AWS provides multiple levels of security, let’s go through them one by one to understand in detail.
Let’s divide the overall security part into two: Data Access Security and Data Storage Security.
Data Access Security
By default when you create a new bucket, only you have access to Amazon S3 resources they create. You can use access control mechanisms such as bucket policies and Access Control Lists (ACLs) to selectively grant permissions to users and groups of users. Customers may use four mechanisms for controlling access to Amazon S3 resources.
Identity and Access Management (IAM) policies
IAM policies are applicable to specific principles like User, Group, and Role. The policy is a JSON document, which mentions what the principle can or can not do.
An example IAM policy will look like this. Any IAM entity (user, role, group) having below policy can access the appgambit-s3access-test bucket and objects inside that.
- {
- “Version”: “2012-10-17”,
- “Statement”:[{
- “Effect”: “Allow”,
- “Action”: “s3:*”,
- “Resource”: [“arn:aws:s3:::appgambit-s3access-test”,
- “arn:aws:s3:::appgambit-s3access-test/*”]
- }
- ]
- }
Bucket policies
Bucket policy uses JSON based access policy language to manage advanced permissions. If you want to make all the objects inside a bucket publicly accessible, then following simple JSON will do that. Bucket policies are only applicable to S3 buckets.
- {
- “Version”: “2012-10-17”,
- “Statement”: [
- {
- “Sid”: “MakeBucketPublic”,
- “Effect”: “Allow”,
- “Principal”: “*”,
- “Action”: “s3:GetObject”,
- “Resource”: “arn:aws:s3:::appgambit-s3access-test/*”
- }
- ]
- }
Bucket policies are very versatile and has lot of configuration options. Let’s say the bucket is service web assets and it should only serve content to request originated from a specific domain.
- {
- “Version”:”2012-10-17″,
- “Id”:”Allow Website Access”,
- “Statement”:[
- {
- “Sid”:”Allow Access to only appgambit.com”,
- “Effect”:”Allow”,
- “Principal”:”*”,
- “Action”:”s3:GetObject”,
- “Resource”:”arn:aws:s3:::appgambit-s3access-test/*”,
- “Condition”:{
- “StringLike”:{
- “aws:Referer”:[
- “https://www.appgambit.com/*”,
- “https://appgambit.com/*”
- ]
- }
- }
- }
- ]
- }
Access Control Lists (ACLs)
ACL is a legacy access policy option to grant basic read/write permissions to other AWS account.
Query String Authentication
Imagine you have private content which you want to share with your authenticated users out of your application, like sending the content link via Email which only that user can access.
AWS S3 allows you to create a specialised URL which contains information to access the object. This method is also known as a Pre-Signed URL.
You can get more detail about generating pre-signed URLs from here.

Get Amazon S3 Training with Advanced Topics From Real-Time Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Uploading from UI
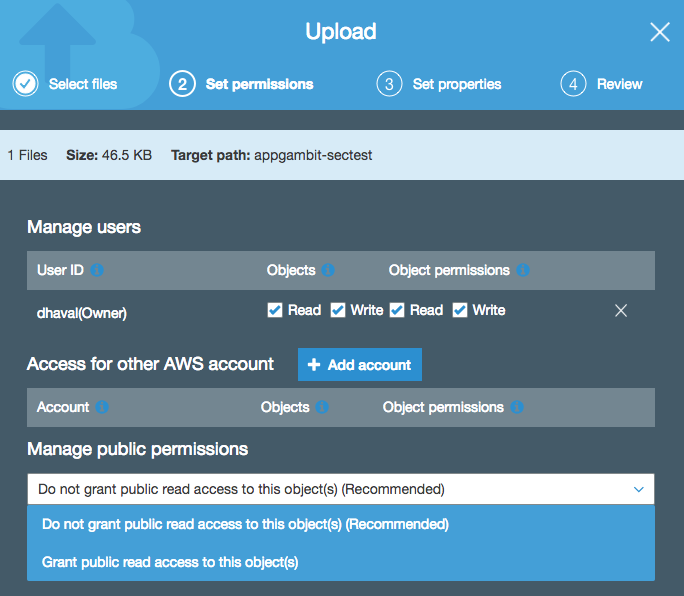
Permissions UI while uploading new object in S3
Each object in the bucket carries their own permission, so if the bucket is set to private, you can still add publicly accessible files inside that bucket.
If you have set the Bucket Policy to make every object publicly accessible, then even the object uploaded with private or no permission, it will still be accessible.
Data Storage Security
Besides Data Access Security, AWS S3 provides Storage level security as well, alternatively known as data-at-rest, while it is stored on disks in Amazon S3 data centers. There are two options for protecting data at rest in AWS S3.
Server-side Encryption
In Server-side encryption, Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers and decrypts it for you when you access it. As long as you authenticate your request and you have access permissions, there is no difference in the way you access encrypted or unencrypted objects.
The entire process is handled by the AWS S3, and the user does not have to do anything with regards to encryption. You can use one of the three available options to encrypt your data.
S3-Managed Keys (SSE-S3)
With S3 managed keys, each object is encrypted with a unique key employing strong multi-factor encryption. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. The AES-256 algorithm is used to encrypt all the data.
AWS KMS-Managed Keys (SSE-KMS)
AWS Key Management Service is similar to SSE-S3, but with some additional benefits. It provides centralised access to create and control the encryption keys used to encrypt your data. Most importantly AWS KMS is integrated with AWS CloudTrail to provide encryption key usage logs to help meet your auditing, regulatory and compliance needs.
Here is a comprehensive list of things AWS KMS can manage for you.
Customer-Provided Keys (SSE-C)
With customer provided keys, we can upload our own keys and the S3 will use that for encryption/decryption.
Client-side Encryption
Client-side encryption is the standard way of encrypting data before sending it to Amazon S3. Similar to how we use that in a Non-Cloud environment where we encrypt the data first and then send to storage, and fetch data from storage and then decrypt before we use it.
Events
Most of the AWS services are designed in a way to integrate with other AWS services and create a flow channel. AWS S3 has Events, imagine you want to run a piece of code when a new file is Added, Updated or Removed. It can be easily done using Events.
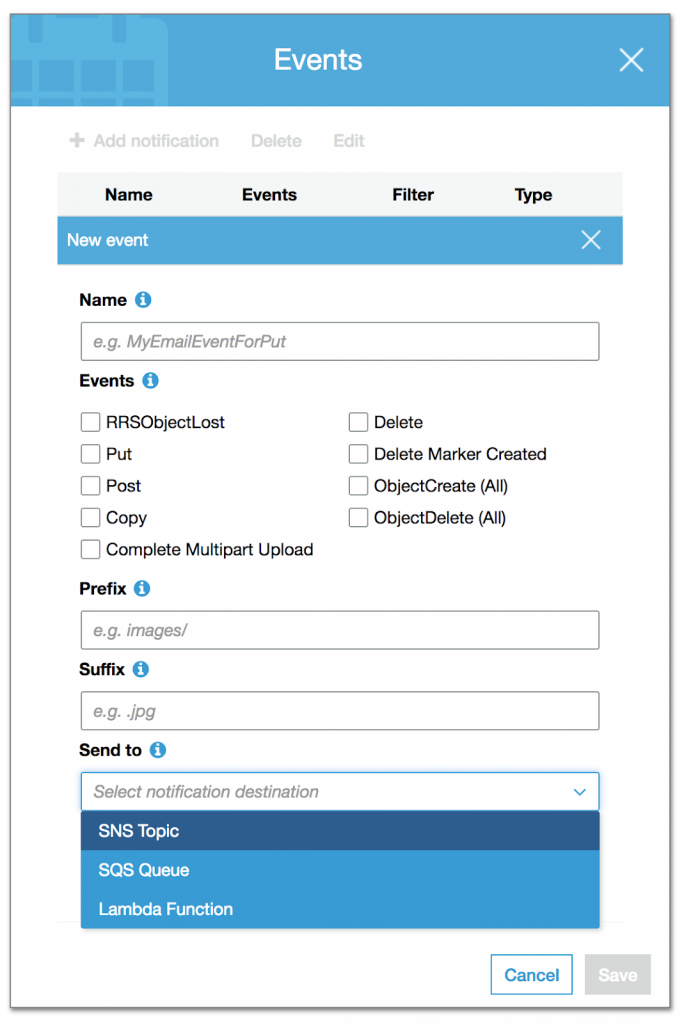
S3 Events Configuration
We can configure things like Events to identify an operation, Prefix/Suffix for object targeting and event target with Send To. As of now, S3 can publish an event to SNS Topic, SQS Queue or invoke a Lambda function.
The common use case for S3 Events is to upload a media file, and does the transformation for different devices like Desktop, Mobile or Tablet to consume or create Thumbnail images.
BitTorrent Support
BitTorrent is an open, peer-to-peer protocol for distributing files. You can use the BitTorrent protocol to retrieve any publicly-accessible object in Amazon S3. Amazon S3 supports the BitTorrent protocol so that developers can save costs when distributing content at high scale.
Every anonymously readable object stored in Amazon S3 is automatically available for download using BitTorrent. To download any file using the BitTorrent protocol, just add ?torrent at the end of the URL request. This either generate the .torrent file for the object or will serve an existing .torrent file.
It is possible to disable the BitTorrent based access by disabling the anonymous access however, we can not prevent the usage of the objects downloaded previously using BitTorrent as they can be served from a peer-to-peer network without the need of the AWS S3.
Pricing
AWS S3 like the other AWS services offers the pay-per-use model. The pricing slightly differs from a region to another region and storage class.
Here is a sample calculation for 1TB of storage with 100K Read and 100K write requests. As you can see on the top right, the usage will cost you around $23.40 / per month.
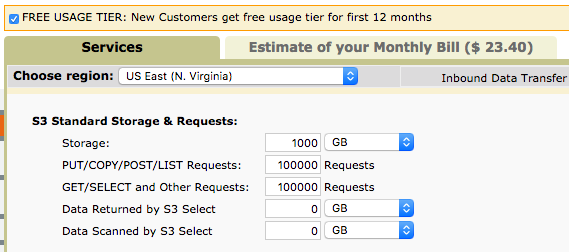
Sample Usage Calculation
You can use the AWS cost calculator from here.