
Last updated on 18th Oct 2024| 5510
Google is a renowned technology leader best known for its search engine, which allows users to find information swiftly and easily. Founded in 1998, the company has broadened its range of products and services to include Google Maps, Google Drive, and YouTube. Committed to innovation and enhancing user experience, Google plays a pivotal role in shaping the digital landscape, making information accessible to millions globally.
1. How might one explain an API to a child?
Ans:
An API, or Application Programming Interface, is a server in a restaurant. When food is needed, the customer informs the waiter of their request, who then visits the kitchen to fulfil it. Similarly, an API allows different computer applications to communicate with each other. For example, while a recreation desires to reveal a rating, it can ask the API to fetch it from anywhere else. The API knows the request and brings lower back the information.
2. Describe the OSI Reference Model.
Ans:
The OSI Reference Model is a framework to apprehend how exceptional networking protocols interact. It includes seven layers, every serving a selected function. From pinnacle to bottom, the layers are the Application, Presentation, Session, Transport, Network, Data Link, and Physical. The Application layer is where personal interactions happen, even as the Physical layer includes the real hardware and information transmission.
3. What precisely are the HTTP and HTTPS protocols?
Ans:
- HTTP, or Hypertext Transfer Protocol, is the basis of information verbal exchange on the Internet. It defines how messages are formatted and transmitted, permitting internet browsers and servers to communicate.
- HTTPS is the stable model of HTTP, wherein the ‘S’ stands for ‘Secure.’ It uses encryption (like SSL/TLS) to shield information exchanged between a person and a website, making it more difficult for hackers to intercept the information.
- While HTTP is appropriate for many uses, HTTPS is vital for handling touchy information, like passwords or credit card information. In summary, HTTP is for normal internet traffic, while HTTPS provides a layer of protection for more secure browsing.
4. How does a scheduler paint in a running gadget?
Ans:
- A scheduler in a running gadget manages the execution of tactics by determining which system runs at any given time.
- To ensure equity and efficiency, it allocates CPU time to every system primarily based on precise algorithms, including First-Come, First-Served, or round-robin.
- The scheduler also prioritizes tactics, permitting important duties to run earlier than those of less important ones. It enables maintaining gadget responsiveness by minimizing wait instances and maximizing CPU utilization.
5. What is the distinction between a stack and a queue?
Ans:
A stack and a queue are each records systems used to shop collections of items, however they function differently. A stack uses a Last-In, First-Out (LIFO) approach, which means the ultimate object delivered is the primary one to be removed, just like a stack of plates. In contrast, a queue operates on a First-In, First-Out (FIFO) basis, wherein the primary object delivered is the primary one to be removed, like a line of human beings watching for a bus.
6. What is a graph?
Ans:
A graph is a set of nodes (or vertices) linked via edges (or links). It symbolizes symbolizes among objects, making it a flexible shape for modelling numerous real-global situations. For example, a social community may be modelled as a graph wherein every person is a node, and friendships are edges connecting them. Graphs may be directed, wherein edges have a direction (like following a person on social media), or undirected, wherein connections are bidirectional. They also can be weighted, assigning values to edges that could constitute distances or costs.
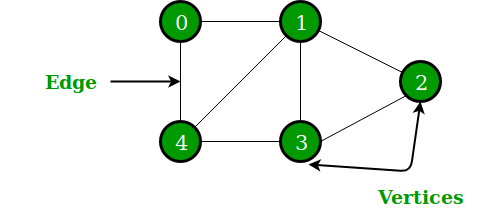
7. What is normalizatnormalizationis it critical in database design?
Ans:
- Normalization is a process of organizing to lessen redundancy and enhance record integrity. It involves dividing huge tables into smaller, associated tables and defining relationships among them.
- The essential purpose is to ensure that every record is saved in the best place, preventing inconsistencies and anomalies during record updates, deletions, or insertions.
- By following normalizatnormalizationcluding the ones described in regular forms, designers can create a greater green and dependable database shape.
8. What is denormalization in database design?
Ans:
- Denormalization is deliberately introducing redundancy into a database by combining tables or including reproduction records.
- While normalization lessens record redundancy and enhances integrity, denormalizationates overall performance in positive situations.
- For instance, while study operations are more common than write operations, denormalization denormalizes record retrieval by minimizing the need for complexity among tables.
- It is frequently utilized in records warehousing utilizing structures, where quick access to aggregated records is crucial.
9. How does a binary search tree (BST) differ from a B-tree?
Ans:
| Feature | Binary Search Tree (BST) | B-tree |
|---|---|---|
| Structure | Nodes with at most two children (left and right) | Nodes can have multiple children |
| Balance | Can become unbalanced | Always balanced |
| Height | Can be high if unbalanced | Generally low due to balancing |
| Search Complexity | O(h), where h is the height of the tree | O(log n), where n is the number of keys |
| Insertion Complexity | O(h) for unbalanced trees | O(log n) |
10. What is the characteristic of congestion management in TCP protocol?
Ans:
Congestion management within the TCP (Transmission Control Protocol) is critical for dealing with community site visitors and ensuring dependable statistics transmission. It prevents overwhelming the community by regulating how much statistics may be despatched earlier than requiring an acknowledgement. TCP uses algorithms like Slow Start, Congestion Avoidance, Fast Retransmit, and Fast Recovery to dynamically modify the statistics transmission fee primarily based on community conditions.
11. What is the distinction between an array and a connected listing?
Ans:
- An array is a set of factors saved at contiguous reminiscence locations. It permits immediate get right of entry to factors via way of the index, making it perfect to use instances in which want random get right of entry.
- However, resizing an array is expensive because it regularly requires purchasing the complete array. On the other hand, a required listing includes nodes consisting of a fee, each with a node.
- Linked lists are dynamic, considering green insertions and deletions. However, getting access to a detail requires traversing the listing sequentially, which is slower than getting access to an array.
12. When might one operate a stack as opposed to a queue?
Ans:
- Stacks and queues are each summary statistics structures, however they function differently. A stack follows a Last In First Out (LIFO) approach, which means the remaining detail brought is the primary to be eliminated.
- It is beneficial for troubles related to recursion, such as undo operations in textual content editors or parsing expressions.
- On the other hand, a queue follows a First-in-First-out (FIFO) approach, which means factors are eliminated in the equal order in which they were brought.
- It is usually utilized in assignment schedulinutilizedadth-first search (BFS) in graph traversal.
13. What are hash tables, and the way do they work?
Ans:
A hash table (or hash map) is an information shape that shops key-fee pairs and permits immediate information retrieval. It uses a hash feature to map a key to an index in an array, in which the fee related to the secret is stored. The essential gain of hash tables is their average-case O(1) time complexity for insertions, deletions, and lookups. However, they can be afflicted by collisions, in which keys hash to the equal index.
14. How does a binary seek tree (BST) work, and is it beneficial?
Ans:
A binary seek tree (BST) is a tree information shape in which every node has the most children. For each node, all values in its left subtree are smaller, and all in its proper subtree are larger. This shape permits green searching, insertion, and deletion operations with an average-case time complexity of O(log n). BSTs are mainly beneficial for taking care of factors and short lookups. However, if the tree turns unbalanced (like in the case of taking care of information), overall performance can degrade to O(n).
15. What are the pros and cons of using a heap for precedence queues?
Ans:
- A heap is a specialized tree-primarily basedspecializedformation shape that satisfies the heap property: a max-heap (in which the determined node is more than or identical to its children) or a min-heap (in which the determined node is smaller than or identical to its children).
- Heaps are usually used to implement precedence queues, where the best or lowest precedence detail is generally on the root.
- The essential benefit of using a heap is that it permits immediate access to the concern detail (O(1)) and green insertion and deletion (O(log n)).
16. Explain the benefits of a trie and when it might be used.
Ans:
- A trie (prefix tree) is a tree-like information shape used to shop a dynamic set of strings, in which every node represents an unmarried man or woman of a string.
- Tries mainly benefit prefix-primarily based seek operations, including auto-completion, spell-checkers, and dictionary implementations.
- The essential gain of a trie is that it affords rapid lookups and insertions of words (O(m), in which m is the duration of the word).
- Additionally, it effectively handles not unusual place prefixes by storing them once, decreasing area usage.
17. What is a dynamic array, and how does it fluctuate from a static array?
Ans:
A dynamic array is an array that may develop and decrease in length at some stage in runtime, not like a static array, which has a set size. In a dynamic variety, if the ability is exceeded, the array is resized (generally doubled in size), and the factors are copied to a brand-new location. This permits flexibility in handling collections wherein the dimensions aren’t recognized upfront. However, it recognized steeply-priced operation because it calls for copying all factors.
18. What is a round queue, and why might it be used?
Ans:
A round queue is the shape of a linear record that follows a First In, First Out (FIFO) principle; however, unlike a well-known queue, it connects the quit of the queue lower back to the front, forming a round buffer. This shape correctly manipulates fixed-length buffers without requiring extra reminiscence for brand-spanking new factors while the queue is full. Circular queues are best for programs like visitors manipulating structures or CPU scheduling, wherein reminiscence reuse is critical.
19. Explain the distinction between depth-first search (DFS) and breadth-first search (BFS) in graphs.
Ans:
DFS and BFS are each algorithms used for traversing or looking through graph record structures. DFS explores some distance down a department as feasible earlier than backtracking, using a stack (or recursion) to discover one department completely earlier than transferring to the subsequent. This benefits programs like fixing mazes or locating related additives in a graph. BFS, on the other hand, explores all acquaintances of a node earlier than transferring to the subsequent level, the usage of a queue.
20. What is a hash collision, and how can it be handled?
Ans:
- A hash collision happens when specific keys in a hash desk hash to the equal index. Since the hash desk shops key-cost pairs, collisions can cause wrong lookups or overwriting of records.
- There are no unusual place strategies to deal with collisions, such as chaining, wherein more than one factor is saved on the same index using a connected list, and open addressing, wherein probe or look for the after be-had index.
- Chaining is easy to implement and no longer requires resizing; however, it can slow down lookups if lists become long.
- Open addressing may be a greater area green; however, it calls for cautious coping with deletions and probing strategies.
21. What is a balanced binary seek tree (BST), and why is balancing important?
Ans:
- A balanced BST is a binary seek tree wherein the peak distinction among any node’s left and proper subtrees is minimal (generally now no longer multiple levels).
- Balancing is essential because the overall performance of operations like seek, insertion, and deletion in a BST relies upon the tree’s height, which should preferably be O(log n).
- If a BST becomes unbalanced (degenerating into a related list), its operations can degrade to O(n), making it inefficient.
22. What is a graph adjacency matrix, and how does it fluctuate from an adjacency list?
Ans:
An adjacency matrix is a 2D array used to symbolize a graph, wherein the symbol symbolizes position (i, j), suggesting whether there’s a side among nodes i and j. It is beneficial for dense graphs as it presents O(1) time complexity for checking the life of a side. However, it consumes O(n²) area, making it inefficient for sparse graphs. On the other hand, an adjacency list shops every node and its friends as a list, lowering area complexity to O(V + E), wherein V is the range of vertices and E is the range of edges.
23. What is a Deque (Double-Ended Queue), and when might it be used?
Ans:
A deque, short for double-ended queue, is a linear record structure that allows entries and removals from both the front and the rear. This makes it more flexible than a normal queue, which operates in a First In First Out (FIFO) manner or a stack that’s Last In First Out (LIFO). Deques are beneficial in situations wherein factors want to be accessed from each end, including enforcing sliding window algorithms, palindrome checking, or retaining records of operations in a browser.
24. Describe a worry queue and explain how it differs from a regular queue.
Ans:
- A precedence queue is a queue wherein every detail is related to a concern, and factors with better priorities are queued earlier than people with lower priorities.
- In contrast, a normal queue follows the FIFO principle, wherein factors are dequeued within the order they were enqueued. Priority queues are typically applied using heaps, permitting green retrieval of the highest (or lowest) precedence detail in O(log n) time.
- They are utilized in situations like Dijkutilizedules for shortest direction finding, CPU scheduling, and event-pushed simulations, where factors should be processed primarily based on their importance instead of the order of arrival.
25. Explain the distinction between shallow and deep replicas in records structures.
Ans:
- A shallow replica of a record shape creates a new example that could be a replica of the original; however, its simplest copies reference nested items instead of duplicating them.
- This way, adjustments to nested items inside the replica will replicate inside the original and vice versa. On the other hand, a deep replica creates a new example and recursively copies all items, including nested ones, ensuring no shared references.
- Shallow copies are quicker and use less memory; however, they can cause accidental facet outcomes when running with mutable items.
26. What is the purpose of a Bloom filter, and when might it be used?
Ans:
A Bloom clear is a probabilistic record shape used to check whether a detail is a fixed member in for exceedingly area-green garage; however, on the free of fake positives (it could incorrectly imply that a detail is present). However, it does not generate fake negatives, which means it isn’t if the clear-out says a detail is only sometimes within the set. Bloom filters are perfect for packages wherein area performance is critical, caching, community protection for blocklist checking, and database question optimization.
27. What is a secoptimizationnd whilst is it beneficial?
Ans:
A section tree is a tree records shape used for storing periods or segments, and it lets in a green variety of queries and updates. It is specifically beneficial for answering queries approximately sums, minimums, or maximums over quite several array indices, making it perfect for c language problems. Operations like variety queries or factor updates may be completed in O(log n) time. Segment bushes are typically utilized in aggressive programmiutilizedackages like c language scheduling, a variety of sum queries, and photo processing.
28. What is a disjoint-set (Union-Find) records shape, and where is it used?
Ans:
- A disjoint set, additionally referred to as the shape of a Union-Find record, is used to preserve the music of a fixed of factors partitioned into disjoint (non-overlapping) subsets.
- It helps operations: find, which determines which subset a specific detail is in, and union, which merges subsets. This shape is exceedingly green, with almost steady time complexity through course compression and union with the aid of rank.
- It is frequently utilized in packages like Kruskautilizedof rules for locating the Minimum Spanning Tree, community connectivity, and determining if nodes are within the equal linked factor of a graph.
29. Explain the idea of amortized evaluation in statistics.
Ans:
- The amortized evaluation compares the time complexity of operations throughout a series of processes rather than analyzing each action independently. This analysis is specifically beneficial when a costly operation (e.g., resizing an array) occurs infrequently; however, many inexpensive operations manifest extra frequently.
- For example, in dynamic arrays, resizing (O(n)) occurs best occasionally, while maximum insertions (O(1)) take steady time. Amortized evaluation allows for Amortizedpertise of the general fee of those operations, regularly decreasing the plain worst-case time complexity.
30. How do cookies flow alongside via the HTTP protocol?
Ans:
Cookies are small portions of statistics saved via a person’s net browser, not to forget facts approximately their go-toto website. When a person visits a website, the server can ship cookies at the side of the HTTP response, teaching the browser to keep them. In the next requests to the equal server, the browser routinely consists of the applicable cookies inside the HTTP headers, permitting the server to get the right of entry to saved facts, like person alternatives or consultation IDs.
31. What is a Fibonacci heap, and what are its advantages?
Ans:
A Fibonacci heap is a specialized fact shape with inclusive specialized bushes and helps green heap operations like insertions, deletions, and decrease-key operations. Its maximum first-rate benefit is its extraordinarily rapid decrease-key operation (O(1)), which makes it especially beneficial in algorithms like Dijkstra’s shortest route and Prim’s minimal spanning tree. Fibonacci lots provide amortized time complexity for maamortizedrations, quicker than binary or binomial lots in many cases.
32. Explain the heap belongings and how lots are utilized in precedence queues.
Ans:
- Utilized a binary tree based on a total fact shape that satisfies the heap belongings: in a max-heap, every discern node is greater than or identical to its children; at the same time, in a min-heap, every discern node is smaller than or identical to its children.
- Heaps are frequently used to enforce precedence queues, wherein the detail with the highest (or lowest) precedence is continually on the root, considering green retrieval in O(1) time.
- Inserting and deleting factors in a heap takes O(log n) time, making it a green desire for troubles like scheduling tasks, occasion simulation, and algorithms like Dijkstra’s shortest route.
33. What is a Skip List, and how does it enhance upon a related listing?
Ans:
- A bypass listing is a layered, probabilistic facts shape that allows instant search, insertion, and deletion operations.
- Unlike a fashionable related listing, which requires O(n) time to look for details, a bypass listing uses layers of related lists, wherein e, a very better layer skips over numerous factors.
- This reduces the time complexity of seek operations to O(log n), just like binary or balanced bushes. The bypass listing is simple to enforce and regulate dynamically; however makes use of more reminiscence for the extra layers.
34. What is the cause of a Red-Black Tree, and how does it preserve stability?
Ans:
A Red-Black Tree is a self-balancing binary seek tree (BST) wherein every node has an additional bit that suggests whether or not the node is purple or black. This colouring guarantees that the tree stays balanced by implementing policies that save lengthy branches, including no consecutive purple nodes and identical black peaks on all paths from the root to the leaf. Red-Black Trees assure O(log n) time complexity for seek, insertion, and deletion, making them beneficial in database indexing and reminiscence management situations.
35. Explain the trade-offs between using a Hash Table and a TreeMap.
Ans:
Hash tables provide average-case O(1) time complexity for insertions, deletions, and lookups, making them ideal for situations requiring constant-time operations. However, they do not maintain order, and performance can degrade to O(n) in the worst case due to collisions. In contrast, treemaps, often implemented as balanced binary trees like Red-Black Trees, offer O(log n) time complexity for these operations while maintaining order, making them suitable for scenarios requiring ordered traversal or range queries.
36. What is a Multimap, and how does it vary from an ordinary Map?
Ans:
- A multimap is an information shape that lets in a couple of values related to an unmarried key, in contrast to an ordinary map (or dictionary), which enforces precise keys with an unmarried cost consistent with the key.
- This is particularly beneficial in situations where key collisions are expected or when a key certainly maps to a couple of values, such as in database indexing or graph adjacency lists.
- Operations like insertion, deletion, and research in multimaps may be barely slower than in an ordinary map because extra values must be handled. However, it gives greater flexibility when a one-to-many courting is needed.
37. What is the distinction between ordered and unordered information shapes?
Ans:
- An ordered information shape continues the relative positioning or sorting of its factors primarily based on a few criteria, allowing for green variety queries or ordered traversal.
- Examples include taking care of arrays, tree maps, and related lists. These systems permit operations like locating the smallest or biggest detail in O(1) or O(log n) time.
- In contrast, unordered information systems, su37.h such as hash tables or ordinary queues, er hold any inherent order special and in speedy insertions, deletions specialize, and lookups.
38. What is a Ternary Search Tree, and how can it be operated?
Ans:
A ternary seek tree (TST) is a tree that shops characters in nodes but lets in 3 children: left, middle, and right. It is much like a binary seek tree; however is used for storing strings, wherein every node holds a character, and paths constitute words. TSTs benefit green prefix-primarily based total searches, autocomplete systems and dictionary implementations. Unlike ordinary tries, TSTs use much less area because they shop characters compactly, and the shape is balanced. However, they’re barely greater complicated to implement.
39. What are the benefits of using an AVL Tree over a Red-Black Tree?
Ans:
An AVL Tree is a self-balancing binary seek tree wherein heights of the 2 toddler subtrees of any node range using at maximum one. This strict balancing guarantees that AVL bushes are extra rigidly balanced than Red-Black bushes, main to quicker lookups (O(log n)) in situations wherein read-heavy operations are not unusual. However, this strictness comes with a cost: AVL bushes require extra rotations at some stage in insertion and deletion operations, making them slower in write-heavy packages.
40. What is a Self-Organizing List, and how does it optimize overall performance?
Ans:
An optimized sizing listing is the sself-organizingd that reorders its factors primarily based totally on getting entry to styles to enhance overall performance over timeCommon tactics include the move-to-the-front heuristic, which places frequently accessible variables at the front and the transpose heuristic, which switches adjacent factors while accessed. These techniques lessen the common seek time in instances wherein positive factors are accessed more frequently than others.

Get JOB SAS BI Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What is the distinction between a Min-Heap and a Max-Heap?
Ans:
- A Min-Heap and a Max-Heap are each binary thousands. However, they vary with considering they maintain. Every component in a Min-Heap is smaller than or the same as its offspring, and the basis node has the tiniest detail.
- This shape permits green retrieval of the minimal detail in O(1) time. In a Max-Heap, the basis includes the biggest detail, and every discernment is greater than or identical to its children, making it best for retrieving the most detail.
- Both thousands aid insertions and deletions in O(log n) time. However, the preference of Min-Heap or Max-Heap depends on whether want rapid access to the smallest or biggest detail.
42. What is a Patricia Trie, and how does it range from a general trie?
Ans:
- A Patricia tree (Practical Algorithm to Retrieve Information Coded in Alphanumeric) is a compressed model of a general trie, wherein nodes with the most effective toddler are merged with their discern.
- This reduces the reminiscence overhead that general attempts can have, specifically whilst the saved keys proportion lengthy, not unusual place prefixes.
- Patricia’s attempts are specifically beneficial for storing sparse binary records, like IP routing tables, wherein decreasing area is critical.
43. Describe how to enforce an LRU (Least Recently Used) cache.
Ans:
The least recently used object is deleted when the LRU cache’s capacity is reached. It may be applied using a mixture of a doubly related listing and a hash map. The hash map presents O(1) getting admission to cached factors, whilst the related listing continues the order of usage, in which the maximum lately accessed object is at the pinnacle and least lately used on the tail. When a detail is accessed, its miles are moved to the pinnacle, and if the cache exceeds capacity, the detail on the tail is removed.
44. How can one discover the smallest detail in an unsorted array?
Ans:
To discover the kth biggest detail in an unsorted array, a not unusualplace technique is to apply a min-heap of length okay. The heap shops the biggest okay factors determined so far, and as iterate through the array, every new detail is compared with the smallest detail within the heap. If the brand-new detail is larger, it replaces the smallest detail, retaining the biggest factors. After processing all aspects, the foundation of the min-heap consists of the biggest detail. This technique runs in O(n log okay) time, that’s green for big datasets.
45. How can one discover a cycle in a related listing?
Ans:
Use Floyd’s Tortoise and Hare rules to discover a cycle in a related listing. This set of regulations entails a gradual pointer (the tortoise) that actions one step at a time and a quick pointer (the hare) that actions steps at a time. The short pointer will trap as much as a gradual pointer, confirming the cycle if there is one in the related listing set of rules that runs in O(n) time and uses O(1) greater space, making it a green answer for cycle detection.
46. How can one layout a URL shortening service like bit.ly?
Ans:
- To set up a URL shortening service, a database is needed to maintain the mapping between authentic and shortened URLs.
- To generate a unique hash for every URL, usually using a base using a base-sixty-two (with 26 uppercase letters, 26 lowercase letters, and 10 digits).
- This hash is stored in the database together with the actual URL. When a consumer inputs a shortened URL, the hash is decoded, and the corresponding authentic URL is retrieved.
- To ensure a certain area of expertise and manage to scale, could rent strategies like sharding, steady hashing, and caching mechanisms to optimize performance.
47. How might one oppose a related list?
Ans:
- To oppose a related list, may use an iterative technique with 3 pointers: prev, cutting-edge, and subsequent. Start with prev initialized to null and cutting-edge pointing to the list’s pinnacle.
- At every step, save the subsequent node (subsequent = cutting-edge).subsequent), extrude the cutting-edge node’s subsequent pointer to factor to prev, pass prev to cutting-edge, and pass cutting-edge to subsequent.
- Repeat this until cutting-edge becomes null. At this point, the factor priced could be the brand-new head of the reversed list. This set of rules runs in O(n) time and uses the O(1) area, making it best for reversing related lists.
48. What is the distinction between quicksort and Mergesort?
Ans:
Though their methods differ, quicksort and Mergesort are both divide-and-overcome sorting algorithms. Quicksort achieves an average-case time complexity of O(n log n) by walling the array around a pivot detail and iteratively sorting the subarrays; if the pivot is poorly chosen, its worst-case time complexity is O(n²). Conversely, Mergesort splits the array into halves, recursively kinds every half, after which merges the taken care of halves, continually accomplishing O(n log n) time complexity.
49. How might one layout a scalable notification system?
Ans:
A scalable notification gadget desires to deal with diverse notification channels (email, SMS, push notifications) and help hundreds of thousands of customers in real time. The gadget may be divided into components: a front-cease API to obtain requests, a message queue (like Kafka or RabbitMQ) to decouple request processing, and employee offerings that supply notifications through third-celebration offerings (like Twilio or SendGrid). For scalability, horizontal scaling is essential, bringing extra employees as calls for increases.
50. How might one layout a price limit for an API?
Ans:
- A price limiter controls the wide variety of requests a consumer could make to an API within a particular time window. To implement it, may use algorithms like the token bucket or leaky bucket, which control request quotas.
- An allotted gadget could use Redis to efficiently store consumer request counts in memory, ensuring low-latency checks. Each time a request is made, the counter is checked and updated.
- If the restriction is exceeded, API returns a Too Many Requests(429) response. For a worldwide scale, may partition the price-restricting good judgment by using areas or servers, ensuring the price restriction is enforced continually throughout allotted nodes.
51. How could one layout a distributed storage system like Google Drive?
Ans:
- A disbursed record garage gadget like Google Drive should manage storing, retrieving, and syncing documents throughout a couple of devices. The structure could depend upon chunking massive documents into smaller portions and storing them throughout disbursed nodes.
- Record chunks must be replicated to ensure information availability, with copies saved on exclusive servers or information facilities. Metadata about documents (consisting of name, region of chunks, and permissions) is saved in a centralized or disbursed metadata service.
52. How could one lay out a global search engine?
Ans:
A worldwide seek engine calls for 3 important components: net crawlers, an indexing gadget, and a question processor. Web crawlers systematically test the net and shop the facts in a disbursed database. The indexing gadget then strategies the uncooked facts into an optimized, searchable layout using algorithms like inverted indexes. When a consumer submits a question, the question processor parses it, retrieves applicable files from the index, and ranks them primarily based on relevance and the usage of a rating set of rules like PageRank.
53. How could one lay out a recommendation system?
Ans:
An advice gadget indicates objects to customers primarily based on their possibilities or behaviour. Collaborative filtering and content material-primarily based total filtering may be two important processes. Collaborative filtering analyzes consumer behaviour (e.g., what comparable customers have liked) to make tips; at the same time, content material-primarily based filtering appears on objects’ attributes (e.g., film genres).
54. How could one lay out a real-time chat application?
Ans:
- Real-time chat software requires low-latency conversations and scalability to address hundreds of thousands of concurrent customers.
- At the core, may use WebSockets to keep continual connections among customers and servers, permitting real-time message transport.
- Messages may be saved in a database (e.g., NoSQL like MongoDB) for persistence, and use message queues like Kafka or Redis Pub/Sub to address high-throughput messaging.
- The gadget could need load balancing and horizontal scaling of chat servers for scalability. Features like message transport status, examine receipts, and push notifications may be added, and security features like cease-to-cease encryption could ensure consumer privacy.
55. How could one lay out a content delivery network (CDN)?
Ans:
- A CDN is designed to correctly distribute content (e.g., videos, images) by caching it on several geographically dispersed servers.
- When a person requests content material, the request is routed to the closest server (facet area), using DNS or IP-primarily-based total routing to lessen latency and enhance load times.
- The beginning servers keep the number one content material, and facet servers cache regularly asked content material for short shipping. The CDN should have purge techniques and time-to-live (TTL) settings to handle cache invalidation and updates.
56. How could one lay out a payment processing system?
Ans:
A fee-processing gadget should cope with touchy records and make certain secure, dependable transactions. The structure could consist of front-quit APIs for traders to provoke payments, a gateway to direct transactions to the correct fee networks, and a database to keep transaction details. Security is critical, so encryption (e.g., the usage of TLS) and compliance with requirements like PCI-DSS are required. The gadget should aid some fee methods (e.g., credit score cards, virtual wallets) and cope with fraud detection with real-time threat analysis.
57. How could one lay out a ride-sharing system like Uber?
Ans:
A ride-sharing gadget calls for matching riders with drivers in real-time, primarily based on area and availability. The gadget includes a couple of components: a GPS-primarily based totally area monitoring gadget, a real-time dispatch gadget, and pricing algorithms that regulate primarily based totally on demand (surge pricing). The structure can use a microservices method with offerings dealing with person requests, motive force locations, and experience management.
58. How might one format a leaderboard system for a gaming platform?
Ans:
- A leaderboard machine ranks game enthusiasts based on their real-time scores. To address many clients and not unusual place score updates, the machine can use a managed data form like a Redis Sorted Set, which allows for inexperienced score and retrieval in O(log n) time.
- The machine should, moreover, use resource sharding to distribute the weight among more than one server at some point. Players` scores can be batched and processed periodically to reduce write contention.
- To scale globally, leaderboards can be partitioned with the resource of the usage of regions or time zones.
59. How could one develop a logging and tracking system for large-scale applications?
Ans:
- A logging and tracking gadget collects, processes, and stores logs generated using allotted offerings. The gadget should deal with huge volumes of information in real-time, which may be executed using log aggregation gear like Elasticsearch or Splunk.
- Logs from diverse offerings are despatched to a centralized garage gadget wherein they’re listed and made searchable. Logs may be processed in batches or use circulation processing frameworks like Apache Kafka and Apache Flink to save from overwhelming the gadget.
- For tracking, metrics are accumulated through dealers and despatched to tracking gear like Prometheus or Grafana, wherein dashboards may be created to visualize gadget fitness and installation indicators for anomalies.
60. How could one lay out a social media feed?
Ans:
A social media feed shows posts from customers in a well-timed manner, requiring a green manner to retrieve and show content. The structure can contain a database for consumer posts, likes, comments, and metadata like timestamps. An allotted database (like Cassandra or DynamoDB) can handle excessive write and examine loads to control scalability. A caching layer (Redis or Memcached) can keep often accessed feeds for short retrieval.

61. How might one lay out a file-sharing system like Dropbox?
Ans:
A record-sharing device permits customers to upload, keep, and percentage documents securely and efficiently. The structure might consist of a front-stop for consumer interaction, a back-end carrier for coping with documents, and a garage device for recording the garage (e.g., Amazon S3 or a disbursed record device). To ensure excessive availability, the device must force redundancy and statistics replication throughout multiple regions.
62. How might one lay out an event logging system?
Ans:
- An occasion logging device captures and shops logs from diverse packages and offerings for tracking and troubleshooting.
- To accommodate big volumes of statistics, the device can use a disbursed log control answer like ELK (Elasticsearch, Logstash, Kibana) or a cloud carrier like AWS CloudWatch.
- Logs may be streamed in real-time using a message dealer like Kafka, taking into account decoupled event processing. For statistics retention, logs may be saved in a time-collection database or kept as an item with configurable retention policies.
63. How would one design a SaaS application with multiple tenants?
Ans:
- Designing a multi-tenant Software as a Service (SaaS) software requires separating client statistics while maximizing aid efficiency.
- The structure can use a shared database version with tenant identifiers to split statistics logically or a separate database in keeping with the tenant for more potent isolation.
- To manipulate scalability, offerings must be stateless to permit horizontal scaling, with load balancers dispensing visitors evenly. Features like tenant provisioning, consumer authentication, and billing structures should be designed to address multiple tenants seamlessly.
64. How might one lay out an online auction system?
Ans:
An online public sale device allows bidding for gadgets in actual time and calls for a dependable and scalable structure. The middle additives consist of a front for customers to browse gadgets, a back end for coping with bids, and a database for storing object information and bid history. WebSockets may be used to offer actual-time updates to customers as bids are placed. To ensure fairness, the device wishes to put time synchronization in force to manipulate bid time limits accurately.
65. How could one lay out a search engine for a large e-commerce website?
Ans:
Designing a seek engine for an e-trade web page entails indexing a good-sized quantity of product information to offer rapid and applicable seek effects. The structure usually consists of an internet crawler feting product information from the database and methods it. It indexes the usage of a seek engine like Elasticsearch or Apache Solr. A question parser translates consumer-seek queries and retrieves effects from the index, rating them primarily based totally on the relevance of the usage of algorithms like TF-IDF or BM25.
66. How could one lay out a video streaming service like YouTube?
Ans:
Designing a video streaming carrier calls for coping with many video uploads, processing, and real-time streaming. The structure should encompass a back-end for consumer control and video uploads, a transcoding carrier to transform films into specific formats, and a content material shipping network (CDN) to make certain easy playback throughout the globe. Video metadata ought to be saved in a database, at the same time as real video documents may be saved in an allotted document device or cloud garage like Amazon S3.
67. How could one specify a ticketing system for event booking?
Ans:
- A price tag reserving device ought to cope with excessive site visitors all through price tag income, requiring an efficient, scalable structure.
- The device should have a front-end interface for customers to browse events, a back-end for handling occasion details, and a database for consumer and tag information shopping.
- When customers request tickets, a locking mechanism is essential to save from overselling, likely using allotted locks or database transactions.
- The device can also force a queue to manipulate requests caused by excessive demand, ensuring equity in price tag allocation.
68. How could one lay out a collaborative document-editing tool like Google Docs?
Ans:
- A collaborative file-enhancing device calls for real-time synchronization to permit a couple of customers to edit files simultaneously.
- The structure could encompass a front-stop software for customers to create and edit files, a back-end carrier to manipulate file garages, and a real-time conversation layer, likely using WebSockets or operational transformation algorithms.
- Document adjustments may be saved incrementally to limit bandwidth and facilitate warfare resolution. User access to manage is vital to manipulating permissions and protecting sensitive files.
69. How might one lay out a distributed project scheduling system?
Ans:
A disbursed venture scheduling machine manages task execution throughout several servers, ensuring green, useful resource usage and reliability. The structure can encompass a centralized venture queue (using message agents like RabbitMQ or Kafka) where duties are enqueued through customers and dequeued through employee nodes for processing. Workers may be dynamically scaled primarily based totally on the workload, and tracking equipment can music venture execution and failure rates.
70. How might one lay out a health monitoring application?
Ans:
A health monitoring utility video displays unit customers` bodily sports and gives insights into their health. The structure might encompass a cellular app for customers to log sports, a back-end provider to save facts, and integration with wearable gadgets for actual-time monitoring. Data garage may be dealt with using an aggregate of SQL (for facts like person profiles) and NoSQL databases (for unstructured hobby logs).
71. How might one lay out an online multiplayer gaming platform?
Ans:
- An online multiplayer gaming platform calls for low-latency verbal exchange and actual-time synchronization among players.
- The structure might encompass sports servers that deal with sports kingdoms and logic, customer programs for personal interaction, and a matchmaking machine to connect players.
- WebSockets or UDP may be used for actual-time verbal exchange to lessen latency, while databases save participant profiles, scores, and sports history.
- To scale, the platform needs to enforce sharding based solely on areas or sport types, making allowance for disbursed load handling.
72. How might one lay out a restaurant reservation system?
Ans:
- A restaurant reservation machine lets clients book tables online while efficiently managing availability. The structure might encompass a front-end person interaction, a back-end to control reservations, and a database to save stock availability and consumer information.
- The machine needs to enforce a locking mechanism to save from double bookings and permit customers to look at actual-time availability. Features like electronic mail or SMS confirmations beautify the person’s experience.
- Load balancing can distribute incoming requests to a couple of servers to reduce peak times.
73. How could one lay out a climate forecasting system?
Ans:
A climate forecasting gadget collects and strategies statistics from diverse assets to offer real-time climate updates. The structure can encompass statistics ingestion pipelines to collect data from meteorological sensors, satellites, and APIs. A statistics processing layer analyzes uncooked statistics using gadget-mastering algorithms to generate forecasts. The gadget should save ancient climate statistics in a time-collection database for evaluation and comparison.
74. How could one lay out a cryptocurrency exchange?
Ans:
A cryptocurrency alternate permits customers to buy, sell, and exchange virtual property securely and effectively. The structure could encompass a front for personal buying and selling interfaces, a back end for dealing with trades, and a sturdy database to save personal accounts, transactions, and order books. The gadget must ensure excessive availability and occasional latency, as trades frequently arise in milliseconds. Security functions like two-aspect authentication (2FA) and bloodless garage for price range are essential to defend a person’s property.
75. How could one lay out a blog publishing platform?
Ans:
- A weblog publishing platform allows customers to create, edit, and share articles easily. The structure could encompass a user-friendly front end for content creation, a back end for dealing with customers and posts, and a database to save content and metadata.
- Caching may be applied to regularly accessed articles to optimize performance. The gadget should help with functions like tags, categories, and remarks to enhance personal engagement.
- User authentication is critical for managing permissions and protecting content. Additionally, analytics gear can record personal interactions, imparting insights into famous content and personal conduct for future enhancements.
76. How could one lay out a photo-sharing application like Instagram?
Ans:
- A photo-sharing utility allows customers to upload, share, and engage with pictures and videos. The structure could encompass a mobile app for personal interactions, a back-end for handling media uploads, and an allotted garage gadget for images and videos (e.g., cloud garage).
- To ensure speedy loading times, a content material transport network (CDN) can cache media documents in the direction of customers. The utility should enforce functions like likes, remarks, and follows to decorate personal engagement.
77. How might one lay out a payment gateway system?
Ans:
A charge gateway device enables steady online transactions among traders and clients. The structure consists of APIs for traders to combine charge processing into their applications, a back-end for handling transactions, and a steady database for storing charge facts and consumer accounts. The device has to observe protection requirements like PCI-DSS to make certain touchy facts are protected. It must aid multiple charge methods, including credit score cards, virtual wallets, and financial institution transfers.
78. How might one lay out a notification system for a mobile application?
Ans:
A notification device keeps customers engaged by imparting well-timed updates and alerts. The structure must consist of a back-end provider that manages notification delivery, a database to save consumer options, and a message queue (like RabbitMQ or Kafka) to address excessive notifications. The device can aid extraordinary notifications push, email, or SMS permitting customers to select their preferred method.
79. How might one lay out a loyalty program for a retail store?
Ans:
- A loyalty application encourages repeat clients by supplying rewards primarily based totally on buy conduct.
- The structure might consist of a cellular app or net interface for customers to view their factors and redeem rewards, in conjunction with a back-end provider to song consumer purchases and factor accumulation.
- A database can save consumer profiles, transaction histories, and praise tiers. The device must put in force actual-time updates to mirror factor adjustments without delay after a transaction.
- Analytics may be used to monitor consumer developments and optimize praise services based primarily on consumer options.
80. How might one lay out a real estate listing platform?
Ans:
- An actual property list platform connects customers, sellers, and dealers to facilitate belongings transactions.
- The structure must consist of a consumer-pleasant front-end for surfing and looking at listings, a back-end to control belongings facts, and a database to save listings, consumer profiles, and transaction histories.
- Implementing superior search functions like filtering by location, price, and belongings kind complements the consumer experience.
- A map integration can visualize belongings locations, while a messaging device enables conversation among customers and sellers. Additionally, the platform can consist of functions for digital excursions and opinions to offer greater facts about properties.
81. How could one lay out an online learning management system (LMS)?
Ans:
An online mastering control machine permits instructional establishments to supply publications and music scholar progress. The structure could encompass a front for college kids and instructors, a back end for route control, and a database to shop route content material, personal data, and grades. The machine must help with multimedia content like videos, quizzes, and assignments and facilitate real-time communique via dialogue boards or chat functions.
82. How could one lay out a supply chain management system?
Ans:
A delivery chain control machine optimizes the waft of products and data from providers to customers. The structure must consist of an internet interface for customers to control stock, a back-end for music shipments and orders, and a database to shop dealer data, product details, and order histories. Real-time monitoring of shipments may be applied using APIs that combine with logistics providers. Analytics can disclose stock phases and are expected to limit stockouts and overstock situations.
83. How could one lay out a cloud-based file storage system?
Ans:
- A cloud-primarily based record garage machine permits customers to upload, shop securely, and proportion files.
- The structure could consist of a user-friendly front end for record control, a back end for handling record uploads and downloads, and a scalable cloud garage solution (like AWS S3 or Google Cloud Storage) for record storage.
- The machine must support versioning to permit customers to revert to preceding record versions. Implementing person authentication and gaining access to manipulation guarantees record privacy and security.
- The platform can also include collaboration functions like real-time modification and feedback.
84. How could one lay out a forum or discussion board?
Ans:
- A discussion or dialogue board allows person-generated content and interactions around precise subjects.
- The structure must have a user-friendly front end for posting and analyzing discussions, a back-end provider for managing threads, and a database for shopping person profiles, posts, and feedback.
- Features like person authentication, moderation gear, and tagging can beautify the person revel in and preserve network standards. Real-time updates may be completed via WebSockets, permitting customers to look at new posts or feedback without refreshing the page.
85. How might one lay out an image-editing utility?
Ans:
An image modifying utility lets customers upload, edit, and percentage photographs with numerous filters and results. The structure needs a front-end for personal interactions, a back-end to control image uploads and processing, and a scalable cloud garage answer for storing photographs. Image processing may be done using server-facet libraries or cloud-primarily based totally APIs to use filters and results efficiently. The machine must assist with real-time collaboration capabilities, allowing more than one customer to edit pictures simultaneously.
86. How might one lay out a personal finance management application?
Ans:
A private finance control utility facilitates customers to manage their income, expenses, and budgets effectively. The structure needs a steady front-end for personal interactions, a back-end carrier to control monetary statistics, and a database to shop person profiles, transaction histories, and price range categories. Integration with banking APIs can permit customers to sync their monetary statistics automatically. The utility must offer capabilities for visualizing spending trends, setting price range goals, and producing reports.
87. How might one lay out a streaming music service like Spotify?
Ans:
- A streaming track carrier lets customers discover, play, and percentage track seamlessly. The structure needs a person-pleasant front-end for surfing and looking at songs, a back-end for handling track catalogues, and a scalable garage answer for audio files.
- Streaming needs to be handled using bitrate streaming to offer the best quality based totally on individual bandwidth. The machine needs to assist individual playlists, pointers, and social capabilities for sharing tracks with friends.
- Implementing strong person authentication and licensing control is important to conform with copyright laws.
88. How might a wearable fitness tracker be designed?
Ans:
- A fitness tracking device collects and analyzes data from wearable gadgets to tune customers` fitness metrics, such as coronary heart rate, steps, and sleep patterns.
- The structure needs a cell app for customers to view their fitness facts, a back-end carrier to manner and shop facts, and a database to manipulate person profiles and fitness records.
- Real-time facts synchronization may be via APIs connecting to wearable gadgets. The device needs to enforce system-gaining knowledge of algorithms to investigate developments and offer customized fitness insights or alerts.
89. How could one lay out a web voting system?
Ans:
An online vote casting device needs to make certain security, transparency, and reliability at the same time as permitting customers to forge votes remotely. The structure needs a steady front-end for voter registration and poll submission, a back-end carrier to manipulate elections, and a database to shop voter records and votes. Strong authentication mechanisms and two-issue authentication are critical to affirm voter identities and save from fraud.
90. How could one lay out a subscription-based video service?
Ans:
A subscription-primarily based totally video carrier permits customers to get the right of entry to a library of content material for a habitual fee. The structure needs a person-pleasant front-end for surfing and streaming videos, a back-end for dealing with personal subscriptions and content material shipping, and a scalable cloud garage answer for video files. Implementing a content material shipping network (CDN) guarantees clean streaming throughout diverse geographical locations.




