
Last updated on 22nd Oct 2024| 7262
Infosys interviews often assess both technical and behavioral skills. Candidates can expect questions on programming languages, data structures, and algorithms for technical roles. Behavioral questions may focus on teamwork, problem-solving, and adaptability. It’s essential to prepare examples from past experiences that showcase your skills and align with Infosys’s core values, emphasizing your ability to learn and collaborate effectively.
1. What are Java’s 4 foremost OOP standards, and how do they work?
Ans:
The four foremost OOP standards in Java are Encapsulation, Abstraction, Inheritance, and Polymorphism. Encapsulation restricts direct access to iteSaaS is a pattern in which software applications are delivered over the Internet, so no local installations are required. PaaS makes platforms available for developers to write and deploy applications raw computing resources of servers and storage fall under the IaaS category, Infrastructure as a Service.
2. Is it feasible to enforce a couple of inheritance in Java, and if so, how?
Ans:
Java no longer aids a couple of inheritance at once through training to avoid ambiguity troubles, just like the Diamond Problem. An elegance can enforce a couple of interfaces, thereby inheriting the summary techniques described in each. This technique permits builders to gain the blessings of a couple of inheritances even as retaining simplicity and warding off conflicts in technique resolution. Java eight brought default techniques in interfaces, permitting interfaces to also offer technique implementations.
3. What distinguishes Method Overloading and Method Overriding in Java?
Ans:
- Method Overloading happens whilst a couple of techniques inside the identical elegance have the tical call calls unique parameter lists.
- It is a compile-time polymorphism, permitting techniques to address unique enter sorts or quantities. Overriding guarantees that a infant elegance can enlarge or adjust the conduct of the determine elegance.
- Method Overriding happens whilst a subclass presents its implementation in a way already described in its superclass.
4. How do Classes and Interfaces vary in Java?
Ans:
An elegance in Java is a blueprint for growing gadgets incorporating each field and techniques. It can offer complete implementations of methods and may be instantiated to create gadgets. An interface is a reference that includes the most effective summary techniques or default/static techniques. Interfaces are used to outline an agreement that imposing training should follow.
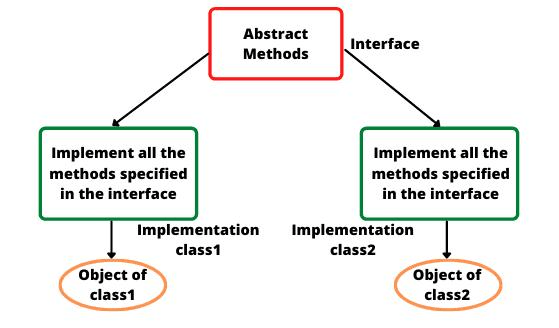
5. What is the distinction between SQL’s TRUNCATE and DELETE instructions?
Ans:
The TRUNCATE command is a DDL operation that removes all rows from a desk and resets any related indexes; however, it no longer generates man or woman row delete logs, making it quicker than DELETE. TRUNCATE is non-transactional and can not be rolled returned in maximum databases. On the other hand, DELETE is a DML operation that gets rid of rows separately primarily based totally on a circumstance and may be rolled returned if inside a transaction. DELETE lets in for selective row removal, while TRUNCATE clears the whole desk.
6. What is the main distinction between the purposes of DDL and DML?
Ans:
| Feature | DDL | DML |
|---|---|---|
| Definition | Complete SAP software installation | Single running copy of SAP system |
| Purpose | Defines database schema and structure | Manages and manipulates data within the schema |
| Commands | CREATE, ALTER, DROP, TRUNCATE | SELECT, INSERT, UPDATE, DELETE |
| Data Focus | Structure of the database (tables, schemas) | Actual data in the database |
| Execution Effect | Changes the database structure | Changes the data within the database |
| Transaction Control | No transaction control, immediate effects | Support transactions (BEGIN, COMMIT, ROLLBACK) |
| Examples of Use | Creating a new table or modifying an existing one | Adding new records or querying data |
7. What is the reason for indexing in SQL, and why is it beneficial?
Ans:
Indexing in SQL enhances the rate of fact retrieval operations on a desk. An index creates a taken care of shape of the facts, permitting the database to locate and retrieve facts greater efficaciously than scanning the whole desk. With an index, querying huge datasets may be faster. While indexes accelerate study operations, they could slow down INSERT, UPDATE, and DELETE operations because the index should be updated.
8. What are the Left and Right outer parts in SQL?
Ans:
A Left Outer Join returns all rows from the left desk and the matching rows from the proper desk. If no shape is found, NULL values are again for columns from the appropriate desk. A Right Outer Join is the opposite, returning all rows from the proper desk and matching rows from the left desk, with NULLs for non-matching left desk rows. Both joins are used to mix facts from tables, ensuring that non-matching rows from one aspect are nonetheless protected within the result.
9. What is a Database Schema, and the way does it work?
Ans:
- A Database Schema is a logical shape that defines the business enterprise of information in a database, consisting of tables, views, indexes, relationships, and constraints.
- Schemas outline what information could be saved inside the tables, the kinds of information for every column, and the relationships among extraordinary tables.
- Database schemas ensure information consistency and integrity by implementing guidelines through number one, overseas, and different constraints.
10. What are Clustered indexes in SQL, and the way do they vary from Non-Clustered indexes?
Ans:
- The body order of information in a desk is determined by a clustered index, which implies that the desk rows are recorded on the disk in an equal order according to the index.
- Each desk may have the most effective clustered index, normally on a number one key. Non-clustered indexes are greater flexible, as a desk may have a couple of non-clustered indexes.
- A Non-Clustered index creates a separate shape from the information rows and factors to the real information saved elsewhere.
11. What are SQL triggers, and the way do they work?
Ans:
- SQL triggers are unique processes which can be robotically performed or fired while precise activities arise in a database, consisting of INSERT, UPDATE, or DELETE operations.
- Triggers are used to implement commercial enterprise guidelines, keep audit trails, or automate obligations like updating associated tables.
- While beneficial for ensuring information integrity and automation, overuse can result in overall performance troubles because of delivered processing overhead.
12. What is the Difference between a Socket and a Session in networking?
Ans:
A socket refers to the endpoint of a bidirectional conversation hyperlink among packages over a network. The aggregate of an IP copes with, and a port quantity helps information change. Alternatively, a consultation refers to the complete conversation change or verbal exchange among gadgets or packages over several socket connections. While a socket is precise to the shipping layer, a consultation is an application-stage abstraction representing a sequence of associated interactions over time.
13. Define SDLC (Software Development Life Cycle).
Ans:
The Software Development Life Cycle (SDLC) is based on growing software programs, including planning, analysis, design, implementation, trying out, deployment, and maintenance. Each segment performs a critical function in ensuring that the software program meets a person’s necessities, is introduced on time, and is of excessive quality. SDLC methodologies vary, from linear processes like the Waterfall version to iterative processes like Agile.
14. What are the hazards of the Waterfall version in software program improvement?
Ans:
The Waterfall version is a linear, sequential technique wherein every segment needs to be finished before shifting to the next. Its primary downside is its inflexibility; once a segment is completed, it’s easier to head again and make changes, which may be complex if new necessities emerge. It is likewise time-consuming, as trying out on the end increases the danger of locating fundamental problems past due in the improvement manner.
15. What is the Stored Procedure?
Ans:
- A saved manner is a fixed of precompiled SQL statements which can be saved and done at the database server. They offer a delivered layer of protection by controlling the right of entry to records.
- They permit builders to execute complicated operations, consisting of conditional good judgment, loops, without delay in the database.
- Stored approaches can also enhance overall performance by the number of records transferred between the customer and the server.
16. What is Polymorphism?
Ans:
- Polymorphism is one of the central standards of Object-Oriented Programming (OOP) that allows items of various training to be handled as items of a not-unusual place superclass.
- Technique overloading (compile-time polymorphism) and technique overriding are two methods of performing polymorphism.
- Overloading happens whilst more than one techniques have an equal call, take place whilst a subclass gives a particular implementation of a way inside the superclass.
17. Explain recommendations.
Ans:
- Pointers are closely utilized in languages like C and C++ to reference records indirectly, bearing in mind extra green reminiscence manipulation and dynamic reminiscence allocation.
- By using recommendations, applications can get entry to and adjust the contents of reminiscence places directly, dynamic systems like connected lists, or whilst passing massive items to functions.
- However, mistaken recommendations can cause reminiscence leaks, crashes, or protection vulnerabilities.
18. What to apprehend approximately the period overfitting in the system gaining knowledge?
Ans:
Overfitting takes place whilst a system gaining knowledge of version learns no longer most effective the underlying sample inside the schooling records; however, the noise, main to excessive accuracy on schooling records but terrible generalization to unseen records. This occurs whilst the version could be more complicated or too long. Techniques to remedy overfitting include regularization, cross-validation, pruning in choice trees, and decreasing version complexity.
19. Explain the idea of characteristic engineering. Why is it crucial in records science?
Ans:
Feature engineering is making new enter functions or reworking present ones to enhance a system, gaining knowledge of the version’s performance. Effective characteristic engineering complements the version’s potential to come across styles and relationships inside the records, making it critical for enhancing accuracy and predictive power. It can also assist in lessening dimensionality and computational complexity, ensuring the version is extra interpretable and green.
20. What is a firewall? How does it boom cybersecurity?
Ans:
A firewall is a community protection tool that video displays units and controls incoming and outgoing community site visitors primarily based on predetermined protection rules. Firewalls are a barrier between inner steady networks and outside untrusted sources, including the internet, stopping unauthorized entry and cyberattacks. Firewalls are essential for protecting networks from outside threats like malware, denial-of-service (DoS) attacks, and unauthorized intrusions, hence improving the general protection posture of the system.
21. What is a reality desk in a records warehouse?
Ans:
- A reality desk is avaluable in a celeb or snowflake schema of a records warehouse, storing quantitative records (facts) for analysis.
- It normally consists of metrics, which include income revenue, quantity, or profit, and overseas keys that hyperlink to associated size tables which offer context to the facts.
- Fact tables are designed to seize and keep big volumes of records from transactional structures for analytical queries.
- They are regularly optimized for read-heavy operations like reporting and records mining, without delay, helps aggregation and computation of facts.
22. What is ETL in Datawarehouse?
Ans:
- ETL is a records integration method utilized in records warehousing to acquire records from multiple sources.
- Rework them into the favoured format, and cargo them into a goal database or records warehouse.
- The Extract segment retrieves uncooked records from supply structures.
- The Transform segment includes cleaning, filtering, and restructuring the records to make them well-matched with the goal system.
- Finally, within the Load segment, the processed records are saved withinrehouse and prepared for analysis.
- ETL guarantees that records are accurate, consistent, and on hand for commercial enterprise intelligence applications.
23. Explain the Dynamic Host Configuration Protocol method.
Ans:
DHCP is a community control protocol that dynamically assigns IP addresses to gadgets in a community. When a tool connects, it sends a DHCP Discover broadcast to discover DHCP servers. The customer sends a DHCP Request to accept the offer, and the server recognizes it with a DHCP Acknowledgment, confirming the assignment. This automatic method simplifies IP deal with control, lowering guide configuration, and permitting gadgets to enrol in the community with minimum effort.
24. Explain the idea of broadcasting in NumPy.
Ans:
Broadcasting in NumPy allows arrays of various shapes for use in mathematics operations by routinely increasing the smaller variety to fit the size of the bigger variety. This removes the need to reshape arrays while performing operations explicitly. Broadcasting follows unique policies that align dimensions for detail-smart operations, making it green and memory-pleasant for responsibilities like matrix operations without copying or replicating records unnecessarily.
25. How to merge DataFrames in Pandas?
Ans:
In Pandas, the merge() characteristic is used to mix DataFrames primarily based totally on non-unusual place columns or indices. This is just like SQL joins, wherein may specify sorts of joins: internal, outer, left, or proper joins. By offering the column(s) to merge on, Pandas aligns the facts from each data frame, growing a brand new data frame that consists of the merged information. For instance, pd. merge(df1, df2, on=`key_column’) plays an internal part of the column key_column.
26. What is the distinction between shallow and deep replicasicas in Python?
Ans:
- The factors inside that item reference the identical reminiscence places because of the original.
- This way adjustments to mutable gadgets within the copied item have an effect on the original.
- A deep replica creates a brand new item and recursively copies all nested gadgets, ensuring no shared references.
- This prevents adjustments to the copied item from affecting the original.
- Python’s replica module presents replica() for shallow copies and deep copy () for deep copies.
27. What is a subnet, and why is it essential in networking?
Ans:
A subnet is a logical subdivision of an IP community, permitting a corporation to phase a huge community into smaller, extra possible parts. Subnetting enhances overall performance by lowering congestion, as visitors are constrained inside every subnet. Community directors can effectively isolate and manage visitors by assigning exceptional subnets to exceptional departments or geographical places.
28. What are the programs of SQL?
Ans:
- This capability is vital for preserving correct and cutting-edge information, which is crucial for enterprise operations.
- SQL is used to create and manipulate database structures, which include tables, indexes, views, and relationships.
- Many enterprise intelligence gears use SQL to fetch and mixture information for reporting purposes.
- SQL queries may be hired to generate insights, conduct statistical analyses, and create dashboards for information visualization.
29. What to do with lacking values (NaN) in Pandas DataFrame?
Ans:
- In Pandas, lacking values (NaN) may be dealt with in numerous methods relying on statistics and analysis.
- Use df. Drop () to remove rows or columns with NaN values or df. Fill () to update them with a selected value and the mean, median, or default value.
- For imputation, we could use greater state-of-the-art strategies like filling with ahead or backward fill (fill () or fill ()).
- Identifying and dealing with lacking statistics is important for making sure that analyses and fashions are correct and reliable.
30. What is a subnet mask, and how is it utilized in community communication?
Ans:
- A subnet mask is a 32-bit variety that divides an IP deal into the community and host portions, used to decide which part of the IP deal identifies the community and which component identifies the host.
- Subnet masks assist in outlining the scale of the community and decide whether or not an IP deal is in the equal subnet or if site visitors ought to be routed to a one-of-a-kind community.
- It is expressed in dotted decimal format, like 255.255.255.0. They are vital for green IP deals with allocation and community routing.
31. Explains using the Python stack’s __init__ technique.
Ans:
In Python, the __init__ technique is unique for initializing a newly created class item. When enforcing a stack class, the __init__ technique may be applied to install an empty listing to keep the stack elements. This technique lets in to outline the preliminary kingdom of the stack, along with its potential or any default values. The __init__ technique guarantees that each example of the stack begins off evolved in a constant and described kingdom, making it simpler to manipulate and manipulate.
32. What are the one of a kind degrees of a statistics warehouse?
Ans:
The degrees of a statistics warehouse commonly consist of statistics sourcing, statistics staging, statistics integration, statistics garage, and statistics presentation. In the statistics sourcing degree, uncooked statistics are accumulated from numerous operational sources. Next, the statistics staging section entails cleaning, transforming, and preparing the statistics for analysis. In the statistics integration degree, statistics is regularly consolidated into a unified format via ETL processes.
33. What does an IP cope with? Explain the distinction between IPv4 and IPv6.
Ans:
An IP cope with is a unique identifier assigned to every tool related to a network, permitting gadgets to speak with each other. IPv4 is the maximum extensively used version, which includes a 32-bit cope with expressed in 4 octets, making an allowance for about 4. In contrast, IPv6 uses a 128-bit cope with the format, represented in 8 corporations of hexadecimal digits, presenting an infinite wide variety of specific addresses. IPv6 became advanced to cope with the restrictions of IPv4 and cope with exhaustion and the want for progressed routing efficiency.
34. What is the ROC curve? What is its significance in device gaining knowledge of?
Ans:
- The ROC curve (Receiver Operating Characteristic curve) is a graphical illustration used to assess the overall performance of a binary category version.
- It plots the proper advantageous charge (sensitivity) in opposition to the fake advantageous charge at diverse threshold settings.
- The location beneath the ROC curve (AUC) gives an unmarried cost-to-degree version of overall performance, with better values indicating higher class discrimination.
- The ROC curve is essential in gaining knowledge because it enables examining exclusive fashions, and picking out the ultimate threshold for category tasks.
35. Explain the idea of ensemble gaining knowledge.
Ans:
- Ensemble gaining knowledge is a device gaining knowledge of approach that mixes a couple of fashions to enhance average overall performance compared to personal fashions.
- The idea is that the ensemble can lessen mistakes and increase accuracy by aggregating predictions from numerous fashions.
- Common ensemble strategies consist of bagging, which creates a couple of subsets of the education information and trains a version for every, adjusts their weights primarily based on preceding mistakes.
- Ensemble gaining knowledge enables mitigating overfitting, decorating robustness, and frequently yielding higher generalization on unseen information.
36. What is the curse of dimensionality, and how does it affect device gaining knowledge of algorithms?
Ans:
- Information factors grow to be greater remote from each other, making it hard for devices gaining knowledge of algorithms to locate significant patterns.
- This sparsity can cause overfitting, wherein fashions carry out proper education information rather than poorly on unseen details.
- The curse of dimensionality additionally will increase computational complexity and the want for large quantities of education information.
- Techniques like dimensionality reduction and function choice are frequently used to cope with this issue.
37. What is clustering in statistics mining, and the way is it extraordinary from classification?
Ans:
Clustering in statistics mining is an unmanaged mastering method used to organization comparable statistics factors primarily based totally on their features, growing clusters of gadgets much like every apart from those in different groups. Unlike classification, where statistics factors are assigned to predefined classes primarily based on classified education statistics, clustering discovers the underlying shape inside the statistics without earlier labels.
38. What is a sorting set of rules, and explain the distinction between bubble kind and merge kind.
Ans:
A sorting set of rules is a way of rearranging a listing or array of factors in a special order, usually ascending or descending. Bubble type is a simple comparison-based set of rules that repeatedly steps through the listing, evaluating adjoining factors and swapping them if they are within the incorrect order. In contrast, merge kind is an extra green divide-and-triumph over a set of rules that divides the array into smaller subarrays, kinds them individually, and then merges them again.
39. What is a graph and explain extraordinary graph traversal algorithms.
Ans:
A graph is a group of nodes related through edges, symbolizing relationships in statistics systems. Graphs may be directed or undirected they can incorporate cycles or be acyclic. DFS explores as a ways as feasible alongside a department earlier than backtracking, whilst BFS explores all associates at the existing intensity previous to shifting directly to nodes at the following intensity level. These algorithms locate paths, related components, and community flow.
40. What is recursion, and why is it beneficial in algorithms?
Ans:
- Recursion is a programming method in which a feature calls itself to clear up a smaller example of an identical problem, which allows complicated issues to be broken down into easier subproblems.
- This method is beneficial in algorithms for obligations like searching, sorting, and traversing statistics systems together with timber and graphs.
- Recursive algorithms frequently bring about cleanser and extra readable code compared to iterative solutions.
- However, they are able to result in troubles like stack overflow if the recursion intensity is too excessive or if there may be no right base case to terminate the recursion.
41. Explain the time complexity of a set of rules and offer examples of unusual place time complexities.
Ans:
- Time complexity is a computational degree that describes the quantity of time a set of rules takes to finish as a feature of the dimensions of its entry.
- Common time complexities encompass O(1) (steady time), wherein the set of rules runs inside the identical time no matter the entered size, O(n) (linear time).
- Wherein time grows proportionally with the entered size O(n^2) (quadratic time), normal in algorithms with nested loops and O(log n) (logarithmic time), not unusual place in binary seek algorithms.
42. Explain the idea of a connected listing and evaluate connected and doubly lists.
Ans:
- A connected listing is a record shape along with a series of elements, every containing a reference (or pointer) to the following detail inside the sequence.
- This permits dynamic reminiscence allocation and green insertion and deletion operations.
- In a singly connected listing, every node consists of a records discipline and a connection with the following node even in a doubly connected listing.
- While doubly connected lists provide extra flexibility and simplicity of navigation, they require extra reminiscence consistent with node because of the extra pointer.
43. Explain the idea of dynamic programming.
Ans:
Dynamic programming is a way of fixing complicated issues by bringing them down into less difficult subproblems and storing the consequences of those subproblems to keep avoidant computations. It is particularly beneficial for optimization issues, wherein it systematically builds up answers to large times primarily based on formerly solved smaller times. Dynamic programming is generally utilized in algorithms like the Fibonacci sequence, substantially enhancing performance with decreasing time complexity.
44. Explain a few vital variations among C and C++.
Ans:
C is a procedural programming language centred on feature and technique calls, even as C++ is an object-orientated programming language that extends C by instructions and objects. This allows C++ to help ideas like encapsulation, inheritance, and polymorphism, improving code reusability and modularity. C++ additionally helps feature overloading, templates, and operator overloading, imparting extra flexibility in code design. These variations make C++ extra perfect for large packages requiring state-of-the-art records modelling.
45. What are the variations among TCP and UDP protocols?
Ans:
Transmission Control Protocol and User Datagram Protocol are essential network delivery layer protocols. TCP is connection-oriented, setting up a dependable connection earlier than facts transfer, ensuring facts are are integrity via error-checking and retransmitting misplaced packets. This makes TCP appropriate for packages like internet surfing and record transfers, wherein reliability is crucial. In contrast, UDP is connectionless, permitting facts to be despatched without setting up a connection and ensuring delivery.
46. What is the Agile version in software program improvement?
Ans:
- The Agile version is a software program improvement technique emphasizing iterative improvement, collaboration, and flexibility.
- It encourages groups to paint in small increments, generally known as sprints, allowing non-stop remarks and variation to convert necessities.
- This technique permits common releases of practical software programs, allowing groups to reply quickly to consumer remarks and marketplace demands.
- Agile methodologies, which include Scrum and Kanban, have won a reputation because they recognize turning in cost and enhancing venture control performance.
47. What do software programs trying out verification and validation entail?
Ans:
- Verification guarantees that the software program meets exact necessities and is constructed in keeping with layout specifications.
- Conversely, validation assesses whether or not the software program meets the wishes and expectancies of the end-users, answering “Are we constructing the proper product?”.
- Validation includes executing the software program in real-global situations and accomplishing consumer reputation trying out (UAT).
48. What is the distinction among DLL and EXE record extensions?
Ans:
- DLL (Dynamic Link Library) and EXE (Executable) are records extensions utilized in Windows running systems. It consists of the software’s code, resources, and essential facts to execute a selected task.
- An EXE record is an executable record consisting of software that may be run simultaneously through the running system.
- In contrast, a DLL record is a library that consists of code and facts that may be utilized by a couple of applications simultaneously.
- DLLs facilitate code reuse and modularization, permitting packages to a proportion, which complements the performance and decreases reminiscence usage.
49. What is the distinction between White and Black fields trying out?
Ans:
White field trying out and black field trying out are awesome software programs trying out methodologies. In the white field trying out, testers can enter the software program’s inner structure, code, and algorithms, letting them look at instances primarily based totally on the code’s common sense. This technique is useful for figuring out logical errors, protection vulnerabilities, and overall performance problems. In contrast, the black field compares the software program’s capability without understanding its inner workings.
50. What is supposed via way of means of Case manipulation features? Explain their different sorts in SQL.
Ans:
Case manipulation features in SQL are used to govern and compare situations primarily based totally on the case of strings. These features consist of UPPER(), which converts a string to uppercase LOWER(), which converts it to lowercase, and INITCAP(), which capitalizes the primary letter of every phrase in a string. Case manipulation features enhance information first-class and facilitate less difficult evaluation and reporting by standardizing textual content formats.
51. What is the distinction between HashMap and ConcurrentHashMap?
Ans:
HashMap is sometimes thread-secure, which means that if more than one threads get the right to enter it concurrently, information inconsistencies can occur. In contrast, ConcurrentHashMap lets secure concurrent get right of entry from more than one thread without outside synchronization. It divides the map into segments, permitting more than one thread to examine and write in extraordinary segments. However, ConcurrentHashMap doesn’t permit null keys or values, in contrast to HashMap.
52. What is the Java Memory Model (JMM), and why is it essential in multithreading?
Ans:
- The Java Memory Model (JMM) defines how threads interact through reminiscence and the policies for analyzing and writing variables.
- Without JMM, a thread won’t see the maximum latest updates to shared variables because of caching or CPU optimizations.
- JMM guarantees happens-before relationships to maintain a predictable multi-threaded environment.
- Understanding JMM is critical to avoid synchronization problems like race situations or stale information in concurrent programming.
53. Explain the variations among synchronized and Lock interfaces in Java.
Ans:
- Synchronized is a keyword in Java that gives implicit locking on a block of code or technique, ensuring mutual exclusion.
- It is straightforward to apply, however inflexible; it routinely releases the lock whilst the method exits.
- The Lock interface from Java.util.concurrent.locks bundle gives greater manipulation over the lock’s behaviour.
- Including looking to accumulate a lock with a timeout or interrupting a thread expecting a lock.
- Locks may be more flexible, permitting fine-grained manipulation, but are more complicated to apply correctly.
54. What is the distinction between very last, sooner or later, and finalize in Java?
Ans:
- Sooner or later is a block utilized in exception management that guarantees code execution irrespective of whether or not an exception is thrown, usually to aid cleanup.
- Finalize is a technique in Object elegance referred to as through the rubbish collector before an item is destroyed, permitting the item to smooth up assets.
- It’s not often used because of performance problems and unpredictable execution, with different mechanisms like try-with-assets being preferred.
55. How does rubbish series painting in Java, and what are specific GC algorithms?
Ans:
Garbage series in Java is a computerized reminiscence control that reclaims reminiscence utilized by gadgets no longer in use. Java uses numerous GC algorithms, including Serial, Parallel, CMS, and G1. These algorithms vary in their techniques for balancing throughput, pause instances, and normal efficiency. The JVM divides reminiscence into old and young generations, with specific strategies for accumulating gadgets primarily based totally on their lifecycle.
56. What are the unstable keywords and keywords? How does it vary from synchronization?
Ans:
The unstable keywokeywordantees that a variable’s price is usually studied from foremost memory instead of a thread’s neighbourhood cache, ensuring visibility of modifications throughout threads. It’s perfect for studying and writing variables through multiple threads without complicated locking. Operations requiring atomicity, like incrementing a counter, unstable on my own is insufficient, and mechanisms like synchronized or atomic lessons are needed.
57. What are Lambda expressions, and how do they contribute to purposeful programming in Java?
Ans:
Lambda expressions, introduced in Java 8, allow treating capabilities as first-rate citizens, permitting the skip of behaviour rather than simply data. They simplify the syntax for enforcing purposeful interfaces, leading to more concise and readable code. Lambdas are critical for purposeful programming constructs, like streams, permitting greater declarative operations on collections, filtering, mapping, and decreasing.
58. What is a CompletableFuture, and how does it enhance asynchronous programming in Java?
Ans:
- CompletableFuture is part of Java’s Java. Util. Concurrent bundle that lets in writing asynchronous, non-blocking off code.
- It represents a destiny result of asynchronous computation and gives strategies to chain a couple of responsibilities using thenApply, thenAccept, or thenCompose.
- Unlike the older Future interface, CompletableFuture gives a higher guide for composing a couple of futures, dealing with exceptions, and reacting to project completion.
- It simplifies writing multi-threaded code that doesn’t block looking forward to the effects of long-strolling operations.
59. Explain the distinction between ExecutorService and Fork/Join Framework.
Ans:
- ExecutorService is a part of the Java concurrency API designed to manipulate and manage the lifecycle of thread pools.
- It facilitates running responsibilities asynchronously but only cuts them into smaller subtasks.
- The Fork/Join framework, brought in Java 7, is optimized for parallelism and designed for responsibilities that may be damaged into smaller subtasks (recursive project division).
- Fork/Join uses a work-stealing algorithm in which idle threads can “steal” responsibilities from busy threads` queues, enhancing aid usage in divide-and-overcome responsibilities.
60. What are WeakReference, SoftReference, and PhantomReference in Java, and how are they used?
Ans:
These are reference kinds utilized in Java to interact with the rubbish collector. A WeakReference allows the item to be rubbish amassed if no sturdy references exist, which is beneficial in caches where items have to be amassed whilst reminiscence is low. SoftReference is comparable; however, much less aggressive, maintaining the item till reminiscence is low. They offer the best management over reminiscence control in unique scenarios.
61. What is a recursive CTE?
Ans:
A recursive Common Table Expression (CTE) is a CTE that references itself in its question definition. It is used to carry out hierarchical or tree-like queries, locate organizational structures, record directories, or parent-toddler relationships. The recursive part of the CTE executes repeatedly, beginning with an anchor question and keeping until a termination situation is met. Recursive CTEs are more readable and maintainable than conventional self-joins. They are especially beneficial for querying hierarchical statistics in a database.
62. What is the distinction among RANK(), DENSE_RANK(), and ROW_NUMBER()?
Ans:
- ROW_NUMBER() assigns a unique sequential quantity to rows, no matter duplicates, making it perfect for producing particular row numbers.
- RANK() gives the identical quantity to rows with the same values but leaves gaps within the numbering if duplicates are found.
- DENSE_RANK() also offers an identical rank to duplicates but no longer leaves gaps within the rank numbering.
- These capabilities are a part of window capabilities and are beneficial for rating results, paginating statistics, or dealing with tie instances in ordering results.
63. How to optimize a question that uses a couple of JOIN operations?
Ans:
- Query optimization with a couple of JOINs may be executed by inspecting execution plans, indexing applicable columns, and ensuring selective filtering is carried out early inside the question.
- Placing suitable indexes on columns utilized in JOIN situations improves performance. It’s also beneficial to lessen needless joins and subqueries by using EXISTS or IN in place of JOIN while applicable.
- Analyzing the part of the order is crucial, as SQL question planners could reorder joins for efficiency, and rearranging the joins manually can result in advanced performance.
64. What is a correlated subquery, and how does it range from a normal subquery?
Ans:
- A correlated subquery relies upon values from the outer question, which means it’s far re-evaluated for every row processed through the outer question.
- This differs from a normal subquery, which is unbiased and completed once, imparting a result.
- Correlated subqueries may be slower because of repeated execution; however, they are beneficial for complicated row-through-row comparisons.
65. Explain the distinction between HAVING and WHERE clauses in SQL.
Ans:
The WHERE clause filters rows before any groupings are made in an SQL query, while the HAVING clause filters corporations after the GROUP BY operation. WHERE is used for row-degree filtering, using situations immediately to person rows. AlternaotherING is carried out to mixture fea atures of grouped facts, permitting situations on summarsummarized. Both may be used collectively inside the identical query, with WHERE filtering rows earlier than aggregation and HAVING using post-aggregation filtering.
66. What is a window characteristic, and how is it one of a kind from mixture features?
Ans:
- A window characteristic in SQL plays a calculation throughout a hard and fast of rows that might be associated with the contemporary row, in contrast to mixture features.
- It no longer organizes the organization into an unmarried output row. Instead, the window characteristic returns the result for every row while keeping the unique row set.
- Functions like ROW_NUMBER(), RANK(), and LAG() are window features that may be used for obligations like ranking, strolling totals, and calculating variations among rows.
67. How do UNION and UNION ALL vary in SQL?
Ans:
UNION combines the result units of or greater queries and eliminates reproduction rows, while UNION ALL combines the result units without eliminating duplicates. UNION plays a further sorting and evaluation operation to dispose of duplicates, which could make it slower than UNION ALL. If the result units won’t be recognized, otherwise need to preserve duplicates for analysis. UNION ALL is the greater green choice. Both operators require various columns and their facts to fit throughout the combined result units.
68. Define CROSS JOIN.
Ans:
A CROSS JOIN produces the Cartesian fabricated from tables, meaning every row from the primary desk is paired with each row from the second desk. It results in many rows and is commonly used without being part of the specified circumstance. While only sometimes utilized in practice, CROSS JOIN may produce look-at facts, develop various categories, or read relationships in which all viable mixtures want to be considered. Care must be taken because of the capability length of the ensuing dataset.
69. Explain database normalization and the unique regular normalization, 3NF.
Ans:
Database normalization is the method of organinormalization to decrease redundanorganizingendency issues. All columns incorporate atomic values in 1NF, no reparent groups exist. The desk should adhere to the requirements of 1NF in 2NF, and all non-key columns must completely rely on the number one key. 3NF (Third Normal Form), Higher regular forms (like BCNF) address extra complicated varieties of dependency removal.
70. What is an impasse in working structures, and how can it not be prevented?
Ans:
- An impasse takes place whilst a hard and fast of techniques are blocked due to the fact every method is protecting an aid.
- Looking forward to every other aid held via way of means of every other method, growing a round dependency.
- Deadlock prevention involves ensuring you the followinguations no longer hold.
- A method hasst all assholdsat once, stopping protection of one aid even as looking forward to others.
- Resources have to be preempted from a method of protecting them. Make assets sharable.
- Impose a complete ordering of all aid sorts to avoid cyclic dependencies.
71. Explain ACID residences in databases.
Ans:
- ACID stands for Atomicity, Consistency, Isolation, and Durability, which are important residences of database transactions.
- Ensures that every one operations inside a transaction are finished effectively or none are. Makes certain that each transaction proceeds on its own without affecting the others.
- Ensures that a transaction brings the database from one legitimate country to every other, retaining database rules.
- It guarantees that when a transaction has been committed, it’ll continue to be within the machine even if there is a crash.
72. Explain the variations between a relational and a non-relational database.
Ans:
Relational Databases (RDBMS) store facts in dependent tables with predefined schemas. Data is accessed through SQL, and table relationships are mounted through overseas keys. Examples include MySQL, PostgreSQL, and Oracle. Non-relational Databases (NoSQL) store unstructured or semi-dependent facts without a hard and fast schema. They are extra flexible and scalable for huge data applications.
73. What is the distinction between a summary elegance and an interface in Java?
Ans:
Both urban techniques and summary methods are possible. Urban techniques permit defining a few default conducts and are extended through subclasses. They help unmarried inheritance. They can best have summary methods and are carried out through classes. Starting with Java 8, interfaces can also have default and static methods. Multiple interfaces may be carried out through an unmarried elegance, permitting more than one inheritance of conduct.
74. Difference between multithreading and multiprocessing?
Ans:
Multithreading means to more than one thread inside an unmarried procedure sharing the equal reminiscence area and resources. It’s typically used to acquire parallelism inside an unmarried utility. Multiprocessing refers to more than one approach strolling on more than one core or CPU, wherein every procedure has its personal reminiscence area. With extra overhead compared to multithreading because of procedure introduction and inter-procedure verbal exchange.
75. Explain the idea of layout styles in software program engineering.
Ans:
- Design styles are reusable answers to not unusualplace software program layout problems.
- They offer general terminology and are high-quality practices for fixing ordinary troubles in software program structure.
- Design styles fall into 3 principal categories Creational, which copes with item introduction mechanisms.
- They assist in enhancing code readability, maintainability, and scalability by selling layout consistency throughout projects.
76. What are microservices, and how do they range from monolithic structures?
Ans:
- Microservices is an architectural fashion that systems a utility as a group of small, loosely coupled offerings, every strolling independently and specializing in a particular enterprise capability.
- Microservices provide extra scalability, maintainability, and versatility as man or woman offerings may be developed, deployed, and scaled independently.
- They introduce complexities in inter-carrier verbal exchange and deployment phrases, making them extra appropriate for large, complicated systems.
77. What are the blessings and drawbacks of the use of RESTful APIs?
Ans:
- RESTful APIs (Representational State Transfer) are famous for designing networked packages because of their simplicity, scalability, and fashionable HTTP strategies like GET POST, PUT and DELETE.
- Advantages include stateless communication, smooth caching, and platform independence. They are lightweight, making them appropriate for cell and internet packages.
- However, dangers include loss of integrated protection and boundaries on complicated operations because of the restrictions of the HTTP protocol.
78. Define software program refactoring and why it is crucial.
Ans:
Refactoring is the technique of restructuring present code without converting its outside behaviour to enhance its readability, maintainability, and performance. It includes cleansing up code, casting off redundancies, simplifying complicated sections, and ensuring the code adheres to high-satisfactory practices. Refactoring is crucial as it saves technical debt from accumulating, which could make the device more difficult to keep and make bigger over time.
79. What is the distinction between coupling and brotherly love in software program design?
Ans:
Coupling is the degree of dependence between distinct modules or additives in a device. Low coupling is ideal as it reduces the danger that modifications in a single module will affect others, making the device less difficult to keep and scale. Cohesion, on the other hand, refers to how carefully associated and centred the duties of an unmarried module are. High brotherly love is prime because the module efficiently plays a selected undertaking, enhancing readability and reusability.
80.. What is Test-Driven Development (TDD), and how does it enhance software programs first-rate?
Ans:
Test-driven development (TDD) is a software program improvement exercise in which builders write exams for brand-spanking new capabilities earlier than writing the real code. The technique includes:
- Writing a failing test.
- Writing simply sufficient code to skip the test and.
- Refactoring the code to ensure excessive first-rate.
TDD improves software programs first-rate by ensuring that every code block has related tests, decreasing the variety of bugs, and inspiring builders to write clean, green code.
81. What are the benefits of using MVC structure in software program layout?
Ans:
MVC (Model-View-Controller) is a layout sample that separates software into 3 interconnected components:
- The Model (which manages statistics).
- The View (which handles the presentation layer).
- The Controller (which procedures consumer enter and updates the Model).
The essential benefits of MVC are the reusability of components, progressed corporation of code, higher testability, and the capacity to independently regulate the consumer interface without affecting commercial enterprise logic.
82. What is Continuous Testing, and how does it relate to DevOps?
Ans:
Continuous Testing checks software programs at each degree of the improvement lifecycle, beginning from the early improvement section and persevering through deployment and operation. It entails automating assessments and integrating them into the CI/CD pipeline to ensure that code adjustments are robotically validated. In a DevOps environment, Continuous Testing is vital for ensuring that the software program stays dependable and practical as new functions are constantly deployed.
83. What is technical debt, and in the way can it affect software program improvement?
Ans:
Technical debt refers to the greater paintings required to restore shortcuts or suboptimal answers to fulfil time limits or lessen preliminary improvement efforts. Accumulating technical debt can gradually improve destiny as builders spend extra time-solving issues, refactoring code, or managing unscalable systems. To manipulate technical debt, groups must frequently refactor code, prioritize long-time period answers over short fixes, and ensure that improvement practices emphasize code quality.
84. What is the distinction between REST and SOAP internet services?
Ans:
- REST (Representational State Transfer) and SOAP (Simple Object Access Protocol) are specific strategies for constructing Internet services.
- REST is lightweight, stateless, and uses general HTTP methods (GET, POST, PUT, DELETE) for communication. It usually exchanges statistics in codecs like JSON or XML.
- SOAP is extra rigid, uses XML for all messages, and comprises integrated protection and transaction support, making it appropriate for complex, enterprise-degree applications.
- REST is desired for simplicity and scalability, while SOAP is used when there are particular necessities like protection or ACID transactions.
85. What is load balancing, and why is it crucial in software program systems?
Ans:
- Load balancing dispenses incoming community visitors throughout multiple servers to ensure no unmarried server is overwhelmed, enhancing gadget reliability, scalability, and overall performance.
- Load balancers may be hardware- or software-program-based and use algorithms like round-robin, least connections, or IP hash to distribute requests.
- Load balancing facilitates attaining excessive availability via way of means of making sure redundancy and dispensing the workload efficiently.
86. What are the important thing variations among horizontal and vertical scaling?
Ans:
- Horizontal scaling entails including extra servers to distribute the load, at the same time as vertical scaling method growing the resources of an unmarried server.
- Horizontal scaling gives higher fault tolerance and might deal with a large increase in visitors because the load is shared throughout more than one machine.
- In current allotted systems, horizontal scaling is favoured because of its flexibility, cost-effectiveness, and potential to deal with large-scale applications.
87. Define the CAP Theorem in allotted systems.
Ans:
The CAP Theorem states that in an allotted gadget, it’s impossible to attain Consistency, Availability, and Partition Tolerance all at once. In the consistency method, all nodes see equal information at equal time availability guarantees that each request gets a response, and in the Partition Tolerance method, the gadget keeps functioning no matter community screw ups. Due to community screw ups in real global allotted systems, a trade off should be made between consistency and availability.
88. What is the distinction between vital and declarative programming?
Ans:
Imperative programming makes a speciality of a way to attain a venture by specifying a chain of instructions that alternate the program’s kingdom step via way of means of step. Common vital languages consist of C, Java, and Python. SQL and useful programming languages like Haskell are examples of declarative languages. Declarative programming allows for extra summary and concise code however may also conceal info on overall performance optimizations.
89. What is the motive of middleware in software program improvement?
Ans:
- Middleware is a software program that acts as a bridge among extraordinary programs or structures, allowing them to talk and control statistics efficiently.
- It sits among the working machine and the application, facilitating responsibilities like database entry, message brokering, authentication, and statistics transformation.
- By coping with those not-unusual place functions, middleware simplifies the improvement procedure and lets builders be cognizant of enterprise good judgment.
90. What are the benefits and drawbacks of cloud computing?
Ans:
Cloud computing gives numerous benefits, such as scalability, wherein sources may be scaled up or down primarily based totally on demand; price savings, as companies best pay for what they use and accessibility, permitting customers to get entry to sources from everywhere with a web connection. Capability downtime if cloud offerings face outages, and seller lock-in, wherein migrating offerings among vendors may be complicated and costly.




