
Last updated on 04th Jul 2020| 3189
Netezza, initially an independent company and subsequently acquired by IBM, is a pioneering data warehousing and analytics appliance renowned for its exceptional high-performance and scalability. The platform is characterised by its shared-nothing architecture, distributing data across multiple nodes for parallel processing, resulting in rapid query execution. Netezza optimises storage and enhances query performance through innovative techniques such as zone maps and compression.
1. What exactly is Netezza?
Ans:
Netezza is a data warehouse appliance intended for high-performance analytics on large amounts of data. It uses a massively parallel processing (MPP) architecture to provide fast query response times.
2. Explain Massively Parallel Processing (MPP) in terms of Netezza.
Ans:
MPP is a computing architecture in which multiple processors work together on a set of tasks. MPP is used by Netezza to distribute and process data across multiple nodes at the same time, allowing for high-speed data processing.
3. What is a Netezza Zone Map?
Ans:
In Netezza, a Zone Map is a metadata structure that stores information about a table’s column minimum and maximum values. It improves query performance by eliminating unnecessary data scans.
4. Explain the purpose of the NZLOAD utility.
Ans:
- Efficiently loads large volumes of data into a Netezza table.
- Utilizes parallel processing for high-performance data loading.
- Designed for quick and optimized handling of substantial data sets.
5. What are the different states of Netezza?
Ans:
Operational State:
- Normal operating condition.
- System functions as expected.
Maintenance State:
- Entered for performing system maintenance tasks.
- Allows administrators to apply updates or perform necessary operations.
Quiescent State:
- User queries are blocked.
- Used during specific system maintenance activities.
- Ensures data consistency.
6. Can you insert duplicate rows in the Netezza table?
Ans:
- Netezza does not permit the insertion of duplicate rows.
- Constraint for data integrity.
- Aligns with the platform’s focus on high-performance analytics and efficient data storage.
7. How does Netezza distribute data across its nodes?
Ans:
Netezza uses a distribution key to distribute data among its nodes. When creating a table, you specify the distribution key, which determines how data is distributed for optimal performance.
8. How can you improve the performance of a Netezza database?
Ans:
Performance in Netezza can be improved by using appropriate distribution keys, optimizing queries, creating indexes, and ensuring that statistics are up-to-date. Regular maintenance tasks such as vacuuming and reorganizing tables also contribute to performance improvement.
9. Explain FPGA and how it improves query performance.
Ans:
Field-Programmable Gate Arrays (FPGAs) in Netezza are used for hardware acceleration, enhancing query performance by offloading specific query operations to dedicated hardware. This approach optimizes resource utilization, resulting in improved query processing speeds and overall system efficiency.
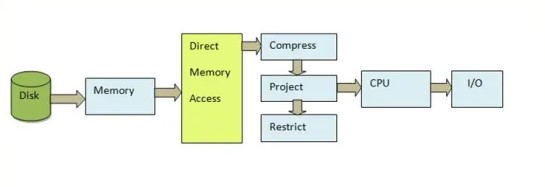
10. What are the limitations of materialised views?
Ans:
Maintenance Overhead:
- Materialized views require regular maintenance to keep them synchronized with the underlying data, leading to increased overhead.
Storage Requirements:
- Materialized views consume additional storage space as they store precomputed results, impacting overall database storage.
Refresh Complexity:
- Refreshing materialized views can be complex, especially in scenarios involving large datasets or frequent updates, leading to potential performance issues.
Real-Time Data:
- Materialized views may not always reflect real-time data as they need to be refreshed periodically, introducing a latency between changes in the source data and updates in the materialized view.
11. What data type is best suited for zone maps?
Ans:
- Numeric Data Types
- Date and Time Data Types
- Ordered Data Types
- High Cardinality Columns
- Avoid using low cardinality columns for join conditions.
- Use numeric ranges for compression and evaluate query patterns.
12. What is NZSQL in Netezza?
Ans:
NZSQL is the command-line interface in Netezza used for executing SQL queries and managing the Netezza database. It provides a direct way to interact with the database, allowing users to perform SQL operations and manage database objects through a command-line interface.
13. How do you monitor and troubleshoot performance issues in Netezza?
Ans:
Performance monitoring in Netezza can be done using system views and utilities like nzstats and nz_performance. Troubleshooting involves analyzing query plans, identifying slow queries, and optimizing the distribution and indexing strategies.
14. Explain the difference between a clustered base table and a non-clustered base table in Netezza.
Ans:
| Feature | Clustered Base Table | Non-Clustered Base Table | |
| Data Storage Order | Physically stored in the order of the distribution key | Not stored in any specific order | |
| Query Performance | Improved performance for queries that leverage the distribution key | May require more scanning for certain queries | |
| Storage Efficiency | May provide better storage efficiency for certain types of queries | No specific advantage in terms of storage efficiency | |
| Data Retrieval | Faster data retrieval for queries that align with the distribution key | Retrieval speed may vary depending on the nature of the query | |
| Usage Scenarios | Ideal for tables frequently queried based on the distribution key | Suitable for tables where the order of data retrieval is not critical |
15. What is a snippet?
Ans:
In Netezza, a snippet is a piece of custom code that can be integrated into SQL queries. Snippets are valuable for incorporating custom processing logic or transformations directly into queries, allowing users to tailor their data processing requirements within the SQL context.
16. How are the zone maps created and updated?
Ans:
Zone maps in Netezza are automatically created and updated as data is loaded or modified in a table. This automated process ensures that the metadata reflecting the minimum and maximum values for each column is always current, optimising query performance by facilitating data pruning during query execution.
17. What is a collocated join?
Ans:
A collocated join in Netezza involves joining two tables that share the same distribution key. This strategy enhances query performance by minimising data movement between nodes, as the data needed for the join operation is already co-located based on the distribution key, reducing query execution time.
18. Which statement holds true for database users and groups?
Ans:
In Netezza, database users are associated with specific roles or groups. This association streamlines access management and permissions, allowing administrators to efficiently control user privileges by assigning roles or group memberships, simplifying the overall security and access control framework.
19. Explain the purpose of Netezza’s NZ CHECK utility.
Ans:
- Verifies the integrity and consistency of the Netezza database.
- Identifies and resolves potential issues with database health.
- A tool for ensuring data integrity and overall system stability.
20. What is the purpose of the Netezza NZ_REPL_HISTORY table?
Ans:
Replication Event Logging:
- NZ_REPL_HISTORY stores replication events in Netezza.
- Contains information about both successful and unsuccessful replication attempts.
Event Information:
- Captures replication-related metadata, such as timestamps, replication status, and event details.
- Provides a historical record for monitoring and analyzing replication performance.
Troubleshooting:
- Provides insights into the replication history, assisting administrators in diagnosing and resolving replication issues.
Audit Trail:
- Serves as an audit trail for tracking changes and ensuring data consistency across replicated instances of the Netezza database.
21. What is a Materialised View in Netezza?
Ans:
A Materialised View in Netezza is a precomputed result set that is stored in the database. It can be used to improve query performance by avoiding the need to repeatedly compute the same result set.
22. What happens to records that were loaded during the nzload process but not committed?
Ans:
During the nzload process in Netezza, records are loaded into a staging area. If the transaction is committed, the records are permanently stored in the database. However, if the transaction is rolled back or not committed, the loaded records are discarded, ensuring data consistency and integrity.
23. What is a Netezza distribution key, and how does it affect query performance?
Ans:
In Netezza, the distribution key plays a crucial role in determining the distribution of data across nodes in a cluster. It acts as a mechanism for organizing data, ensuring that related information is stored on the same node. This strategic distribution minimizes data movement during query execution, enhancing performance by allowing the system to access and process data locally on each node.
24. Explain the concept of zone maps and how they help with query optimization.
Ans:
Zone maps in Netezza serve as metadata structures that store information about the ranges of values within columns. These maps enable efficient data pruning during query execution by identifying and skipping irrelevant data blocks, significantly enhancing query optimization. By providing insights into the distribution of data values, zone maps allow the query planner to skip unnecessary data scans, reducing I/O operations and accelerating query processing.
25. Explain the purpose of the Netezza NZBACKUP utility.
Ans:
- Comprehensive Data Protection
- Full and Incremental Backups
- Data Recoverability
- Point-in-Time Recovery
- Operational Continuity
26. What is the importance of the Netezza NZ_PURGE utility?
Ans:
NZ_PURGE is used to permanently remove data from the Netezza system.
- Storage Management: Effectively manages storage space by removing obsolete data.
- Data Hygiene: Ensures accurate and current information in the database.
- Permanent Deletion: Deletes specified data permanently, freeing up storage resources for future use.
- Optimizing database performance involves removing unnecessary data, reducing storage overhead, and optimizing retrieval operations.
- Administrative Control is a tool that helps administrators manage and streamline data retention while adhering to compliance policies.
27. What is the purpose of the Netezza NZ_MIGRATE utility?
Ans:
Netezza’s NZ_MIGRATE utility facilitates the seamless migration of data from one table to another. This utility helps to ensure efficient data movement by allowing for data reorganisation and restructuring within the Netezza database. By providing a streamlined mechanism for transferring data, NZ_MIGRATE helps to optimise data storage and overall system performance, allowing administrators to effectively manage and restructure their data.
28. What is the purpose of the NZRECLAIM utility in Netezza?
Ans:
The NZRECLAIM utility in Netezza is critical to optimizing disk space utilization within the database. NZRECLAIM helps to reclaim valuable disk space by identifying and removing deleted or unused data. This utility is critical for efficient storage management, as it prevents unnecessary space consumption and ensures that storage resources are used wisely. NZRECLAIM helps to maintain a well-organized and optimized database environment by freeing up disk space, which improves overall storage efficiency and system performance in Netezza.
29. How can you track the performance of Netezza queries in real time?
Ans:
To monitor Netezza query performance in real time, use tools like the Netezza Performance Portal and system views. The Netezza Performance Portal provides a comprehensive interface for monitoring and analysing query performance metrics, while system views such as _V_QE, _V_STATS, and _V_PROFILE provide detailed real-time information about query execution, resource utilisation, and overall system health.
30. How does Netezza handle data distribution during an ALTER TABLE ADD COLUMN operation?
Ans:
Netezza’s ALTER TABLE ADD COLUMN operation efficiently manages data distribution to minimise impact. Netezza maintains the distribution of existing data across nodes while redistributing only the new column’s values. This approach ensures that adding a column does not necessitate the complete redistribution of all data, preserving the system’s performance and scalability.

Get Hands-On Practical Netezza Training to Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
31. Explain the purpose of Netezza’s NZ_RELOAD utility.
Ans:
Data Reloading Following Reorganisation:
- The NZ_RELOAD utility in Netezza is used to reload data into a table after it has been reorganized.
- This process aids in the restoration of data integrity and performance after table reorganization activities.
Rebuilding Tables Effectively:
- Following structural changes or optimizations, NZ_RELOAD facilitates data reloading, ensuring that the table is efficiently reconstructed.
- Contributes to keeping the database in a consistent and organized state.
Performance Restoration:
- By reloading data, NZ_RELOAD helps to restore optimal performance, which is consistent with the platform’s emphasis on high-performance analytics.
32. What are the benefits of using external tables in Netezza?
Ans:
External tables allow for seamless integration with data stored outside the Netezza system, providing easy access to various external data sources.
Querying external data:
- Users can query and analyze data stored in external sources directly from Netezza, eliminating the need for data duplication or complex data transfer procedures.
Reduced Storage Overhead:
- External tables reduce storage overhead by allowing Netezza to reference data without physically importing it, which saves storage resources.
Real-time Data Access:
- Real-time access to external data ensures that Netezza users can incorporate the most recent information from external sources into their analyses.
33. How does Netezza handle data distribution in the event of a UPDATE operation?
Ans:
When you perform a UPDATE operation on a distributed key column in Netezza, the system redistributes the rows that were affected by the update based on the new distribution key values. This ensures that the updated data is properly redistributed across nodes, preserving the distribution strategy and optimizing query performance for subsequent operations.
34. What is the purpose of Netezza’s NZLOAD-READRANGE option?
Ans:
The -READRANGE option in Netezza’s NZLOAD utility serves the purpose of providing flexibility in data loading. This option allows users to load only a specific range of rows from the source data, enabling selective loading based on criteria such as a specified range of values or conditions. The -READRANGE option enhances control over the loading process, allowing for efficient and targeted data ingestion in scenarios where loading a subset of data is preferable.
35. Explain Netezza’s NZSQL \timing command.
Ans:
The NZSQL \timing command is a tool within the Netezza SQL interface that enables or disables the display of query execution time. When activated (\timing on), it shows the elapsed time for query execution, aiding in performance analysis and benchmarking. This command is valuable for assessing the efficiency of queries and understanding the time taken for their execution, providing insights into optimization opportunities and facilitating the evaluation of query performance in the Netezza database environment.
36. How does Netezza handle data distribution in the event of a JOIN operation between two tables?
Ans:
- Dynamic redistribution: Netezza dynamically redistributes data during a JOIN operation between tables with different distribution keys.
- Alignment Based on Join Keys: Redistribution ensures that the tables are aligned according to the keys specified in the JOIN operation.
- Optimizing query performance: Netezza aims to improve query performance by adjusting data distribution strategies.
- Efficient Join Processing: Ensures that data relevant to the JOIN conditions is distributed correctly across nodes for efficient processing.
37. How does Netezza handle data distribution in the event of a DELETE operation on a distributed key column?
Ans:
- When Netezza performs a DELETE operation on a distributed key column, the platform dynamically redistributes the remaining rows across nodes. This redistribution mechanism is critical for maintaining an optimal data distribution strategy by ensuring that the remaining data is distributed properly for efficient query performance.
- Netezza’s ability to handle data distribution during DELETE operations improves the platform’s scalability and performance, allowing for effective data management across the distributed architecture without sacrificing overall system efficiency.
38. What is the meaning of the Netezza NZMIGRATE -MATCH_COLUMNS option?
Ans:
The NZMIGRATE utility in Netezza includes the -MATCH_COLUMNS option, which is useful during data migration. When enabled, this option ensures that columns in the source and target tables are matched according to their names. This is critical for accurate and precise data migration, as it aligns the corresponding columns in the source and target tables and ensures a smooth transfer of data.
39. Describe the purpose of the Netezza NZDU utility.
Ans:
The Netezza NZDU utility serves the purpose of providing insights into disk space utilization within the system. Administrators use NZDU to display information about how disk space is allocated, helping them manage storage resources efficiently. By presenting a comprehensive overview of disk usage, NZDU aids in identifying storage bottlenecks, optimizing data placement, and ensuring the effective utilization of disk space in the Netezza environment.
40. What is the purpose of the Netezza NZ CHECKPOINT utility?
Ans:
The NZCHECKPOINT utility in Netezza plays a crucial role in facilitating database recovery. By creating a checkpoint in the transaction log, NZCHECKPOINT enables the system to recover to a specific point in time in the event of system failures. This utility enhances data resilience and system reliability by providing a reference point for recovery operations, allowing administrators to restore the database to a consistent state following unexpected disruptions or failures.
41. How does Netezza handle data distribution in the event of a MERGE operation?
Ans:
During a MERGE operation in Netezza, the platform redistributes data based on the conditions and actions specified in the MERGE statement. This ensures that the data is appropriately distributed across nodes in accordance with the MERGE operation’s criteria. Netezza’s ability to dynamically adjust data distribution after a MERGE operation supports the platform’s focus on maintaining efficient query performance, even when dealing with complex data integration scenarios involving updates, inserts, and deletes.
42. How does Netezza handle data distribution during a COPY operation with the -APPEND option?
Ans:
- Efficient Data Loading: Netezza optimizes the data loading process with the -APPEND option in COPY.
- New Rows Addition: Instead of redistributing existing data, the -APPEND option adds new rows to the target table.
- Minimized Impact on Existing Distribution: Existing data distribution is maintained, minimizing the impact on the existing distribution strategy.
- Optimized for Incremental Loading: Ideal for scenarios where new data is added incrementally, ensuring efficient and scalable data loading operations.
43. Explain the purpose of the Netezza NZ_CONCAT function.
Ans:
- String Concatenation: NZ_CONCAT is a Netezza function designed for concatenating strings.
- Text Value Combination: Provides a convenient way to combine text values within the database.
- Enhanced Data Manipulation: Useful for data manipulation tasks where combining or concatenating text fields is required.
- Simplifies String Operations: Simplifies string manipulation tasks by offering a straightforward and efficient method for combining text values.
- Flexible Usage: Can be employed in various contexts where the combination of text values is necessary.
44. Explain the purpose of Netezza’s NZ_LOAD_COPY utility.
Ans:
The NZ_LOAD_COPY utility in Netezza serves the purpose of efficiently copying data between tables within the same Netezza system. This utility provides a quick and resource-efficient method for duplicating data, facilitating streamlined data replication or migration processes within the Netezza database environment.
45. What is the importance of the Netezza NZEXPORT utility?
Ans:
NZEXPORT holds significance in Netezza for its role in exporting data from Netezza tables to external files. This utility enables the interchange of data with other systems or applications, supporting data sharing and integration across different platforms. NZEXPORT enhances the versatility of Netezza by providing a means to extract and utilize data in various external contexts.
46. How does Netezza handle data distribution following a TRUNCATE operation?
Ans:
In the case of a TRUNCATE operation in Netezza, the platform redistributes the remaining data to maintain a balanced distribution across nodes. This redistribution ensures that data is efficiently managed and evenly distributed after the TRUNCATE operation, supporting optimal performance and maintaining the integrity of the distributed architecture.
47. Explain the purpose of Netezza’s NZSECURITY utility.
Ans:
The NZSECURITY utility in Netezza is employed for managing security settings within the system. This utility enables administrators to configure user authentication and authorization settings, ensuring a robust and controlled security environment in Netezza. NZSECURITY plays a crucial role in defining and enforcing security policies to protect the integrity of the database.
48. What is the significance of the Netezza NZSQL -quiet option?
Ans:
- Suppressing Informational Messages: The -quiet option in NZSQL suppresses informational messages during script execution.
- Cleaner Output for Automation: Particularly useful for scripting and automation, as it provides a cleaner output without additional informational clutter.
- Focus on Essential Results: Enables users to focus on essential results and outcomes without being inundated with extraneous information.
- Improved Script Readability: Enhances script readability by reducing verbosity, making it easier to interpret and analyze results.
- Efficient Automation: Facilitates efficient automation by streamlining the output for scripts and command-line operations.
49. What is the purpose of the Netezza _V_TABLE system view?
Ans:
The _V_TABLE system view in Netezza plays a pivotal role by providing comprehensive information about tables within the system. This includes details such as table size, distribution characteristics, and storage-related information. _V_TABLE offers administrators insights into the structure and properties of tables, aiding in performance optimization, capacity planning, and overall management of the Netezza database environment.
50. Explain the use of the Netezza NZMIGRATE -TARGET_PATH option.
Ans:
The NZMIGRATE utility offers the -TARGET_PATH option, allowing users to specify the destination path for migrating data. This option provides flexibility in data migration scenarios by enabling users to define the target location for the migrated data. The -TARGET_PATH option enhances control over the migration process, allowing for customized data placement. It accommodates various migration requirements, supporting optimized data storage and organization based on specific preferences or operational needs.
51. How does Netezza handle data distribution in the event of a COPY operation without the -APPEND option?
Ans:
- When performing a COPY operation in Netezza without the -APPEND option, the platform undergoes a redistribution of existing data to ensure an even distribution across nodes.
- This redistribution strategy aims to maintain a balanced distribution of data, particularly in scenarios where a complete reload of data is required.
- While this approach ensures optimized data distribution, it may have performance implications, especially for large datasets, as existing data is reorganized to align with the system’s distribution strategy.
52. What is the purpose of the Netezza _V_DATABASE system view?
Ans:
The _V_DATABASE system view in Netezza plays a crucial role in providing administrators with an overview of information related to databases in the system. It offers details on database size, space utilization, and configuration settings, serving as a valuable tool for monitoring database health, planning capacity, and assessing space usage. With insights into the characteristics and configurations of databases, administrators can effectively manage and optimize the performance of the Netezza database environment.
53. How does Netezza handle data distribution following a CREATE TABLE AS SELECT (CTAS) operation?
Ans:
During a CREATE TABLE AS SELECT (CTAS) operation in Netezza, data redistribution occurs based on the specified distribution key. This dynamic redistribution ensures that the distribution of data in the newly created table is optimized for efficient query performance. Netezza adapts the distribution to align with the characteristics of the new table, supporting scalability and maintaining a balanced distribution across nodes.
54. Explain the purpose of Netezza’s NZLOAD -NULL_AS option.
Ans:
- NZLOAD provides the -NULL_AS option, allowing users to specify a replacement value for NULLs during the data loading process.
- This option offers flexibility in handling missing or NULL values, enabling users to customize the treatment of NULLs based on specific requirements.
- It supports efforts to enhance data quality by providing a mechanism for customizing the handling of NULLs during the loading process.
55. What is the significance of the Netezza NZ_SQL_HISTORY table?
Ans:
The NZ_SQL_HISTORY table holds significance as a repository for storing information about executed SQL statements in Netezza. It serves as a valuable tool for query analysis, optimization, and historical tracking. By providing a historical record of SQL statements, administrators can gain insights into query execution patterns, troubleshoot issues, and perform auditing tasks. The NZ_SQL_HISTORY table contributes to the overall management of the Netezza database environment by offering a comprehensive view of SQL statement execution over time.

Enroll in Best Netezza Certification Courses and Get Hired By TOP MNCs
Weekday / Weekend BatchesSee Batch Details56. How does Netezza handle data distribution in the event of a CREATE INDEX operation?
Ans:
- Distribution Key-Based Redistribution: Netezza dynamically redistributes data based on the distribution key during a CREATE INDEX operation.
- Efficient Index Distribution: Ensures that the newly created index is efficiently distributed across nodes, aligning with the underlying data distribution strategy.
- Optimizing Query Performance: By adapting the distribution to the index creation process, Netezza aims to optimize query performance for indexed operations.
57. Explain the purpose of Netezza’s _V_PROC system view.
Ans:
- Process Information Overview: _V_PROC provides an overview of information related to processes running on Netezza nodes.
- Details on Resource Utilization: Includes details on resource utilization, execution status, and process IDs for each running process.
- Monitoring Node Activity: Essential for monitoring node activity and understanding resource utilization patterns in the Netezza system.
58. Describe the purpose of the Netezza NZ SHELL utility.
Ans:
NZSHELL serves as a command-line interface utility in Netezza, providing a convenient platform for interacting with the Netezza system. It facilitates system administration tasks and scripting by offering a command-line interface, allowing administrators to execute commands and scripts efficiently. NZSHELL enhances the user’s ability to manage and administer the Netezza system directly from the command line, streamlining operational tasks and scripting procedures for effective system management.
59. What is the use of the Netezza _V_EXTERNAL_COLUMNS system view?
Ans:
The _V_EXTERNAL_COLUMNS system view in Netezza holds significance by providing detailed information about external tables. This includes column definitions, data types, and storage attributes associated with external tables. _V_EXTERNAL_COLUMNS is valuable for administrators and users working with external data sources, offering insights into the structure and characteristics of columns within external tables, aiding in data integration and management.
60. How does Netezza handle data distribution in the event of a REORG TABLE operation?
Ans:
During a REORG TABLE operation in Netezza, data redistribution occurs to eliminate fragmentation and optimize storage. This redistribution aligns data more efficiently across nodes, contributing to enhanced query performance. The REORG TABLE operation is instrumental in maintaining system health by restructuring tables and ensuring that data is organized and distributed optimally, thereby supporting the overall efficiency of the Netezza database environment.
61. Explain the purpose of Netezza’s _V_QUERIES system view.
Ans:
The _V_QUERIES system view provides comprehensive information about currently executing queries in Netezza. It includes details on query plans, resource utilization, and unique query IDs. _V_QUERIES aids administrators in monitoring and analyzing query performance, identifying resource-intensive queries, and troubleshooting issues. This system view is crucial for optimizing query execution, managing system resources, and gaining insights into the ongoing activity within the Netezza database.
62. What is the purpose of the Netezza NZDDL utility?
Ans:
- DDL Statement Generation: NZDDL is a utility designed for generating Data Definition Language (DDL) statements.
- Capture and Reproduction of Definitions: Provides a convenient way to capture and reproduce database object definitions.
- Supports Object Definition Management: Enables administrators to manage database objects effectively by creating, modifying, and reproducing DDL statements.
- Useful for Schema Versioning: Supports schema versioning and script-based database management by facilitating the creation of DDL statements for database objects.
63. How does Netezza handle data distribution following an ALTER TABLE DROP COLUMN operation?
Ans:
- Redistribution of Remaining Columns: Netezza redistributes the remaining columns after an ALTER TABLE DROP COLUMN operation.
- Maintenance of Data Distribution: This redistribution ensures that proper data distribution is maintained across nodes in the Netezza system.
- Optimizing Storage and Performance: By adjusting the data distribution, Netezza optimizes storage and query performance after removing a column.
- Adaptation to Altered Table Structure: Dynamic redistribution aligns the table structure with the distributed architecture, accommodating changes introduced by column removal.
64. What is the significance of the Netezza NZMIGRATE -KEY_MATCH option?
Ans:
The -KEY_MATCH option in NZMIGRATE is designed to ensure accurate and efficient data transfer during migration by specifying matching key columns. This option aligns the migration process based on matching key columns, enhancing the precision of data transfer and maintaining data integrity between source and target tables. NZMIGRATE, with the -KEY_MATCH option, provides administrators with a powerful tool for managing data migration scenarios, ensuring a seamless transfer of data while adhering to specified key matching criteria.
65. How does Netezza handle data distribution in the event of a CREATE TABLE AS SELECT (CTAS)?
Ans:
During a CREATE TABLE AS SELECT (CTAS) operation with a WHERE clause in Netezza, data redistribution takes place based on the specified distribution key. The conditions outlined in the WHERE clause influence which data is included in the new table, and Netezza dynamically adjusts data distribution to optimize storage and query performance.
66. Explain the purpose of Netezza’s _V_INDEXES system view.
Ans:
The _V_INDEXES system view in Netezza serves the purpose of providing detailed information about indexes within the system. This includes information on index types, sizes, and relationships with associated tables. _V_INDEXES is instrumental for administrators and users in managing and optimizing database performance by offering insights into the characteristics and usage of indexes.
67. What is the importance of the Netezza NZSAMPLING utility?
Ans:
NZSAMPLING holds significance as a utility in Netezza used for generating statistical samples from large datasets. This utility is valuable in scenarios where analyzing a full dataset is impractical, providing a representative subset for data analysis and query optimization. NZSAMPLING enables users to draw meaningful insights from large datasets efficiently, contributing to data-driven decision-making and performance optimization in situations where processing the entire dataset may be resource-intensive or time-consuming.
68. How does Netezza handle data distribution in the event of a CREATE EXTERNAL TABLE operation?
Ans:
- Distribution Key-Based Redistribution: Netezza dynamically redistributes data during a CREATE EXTERNAL TABLE operation.
- Efficient Storage and Retrieval: Redistribution is based on the specified distribution key, optimizing data storage and retrieval for external tables.
- Alignment with Distribution Strategy: Ensures that the distribution strategy aligns with the distributed architecture of Netezza, supporting efficient query processing.
- Optimizing Performance: Facilitates performance optimization by adapting data distribution to the characteristics of external tables.
69. Explain the purpose of Netezza’s NZ_GENSTATS utility.
Ans:
- Statistics Generation for Columns: NZ_GENSTATS is a utility used for generating statistics on table columns in Netezza.
- Query Optimizer Support: Aids the query optimizer in making informed decisions about query plans based on column statistics.
- Enhanced Query Performance: Contributes to enhanced query performance by providing valuable insights into column data distribution.
- Dynamic Optimization: Supports dynamic optimization of queries by allowing the query optimizer to utilize relevant statistics during query planning.
70. What is the purpose of creating materialized views?
Ans:
Creating materialized views in Netezza improves query performance by storing precomputed results from complex or frequently executed queries. Materialized views serve as aggregated or transformed snapshots of data, allowing for faster retrieval of information without having to recompute the results with each query execution. This improves overall system efficiency, particularly in scenarios where specific analyses or aggregations are frequently requested, resulting in a more responsive and efficient data access environment.
71. What is the purpose of the Netezza _V_QUERY_METRICS system view?
Ans:
- Detailed Query Metrics: _V_QUERY_METRICS provides detailed metrics and performance statistics for executed queries in Netezza.
- Analysis and Optimization: Supports query analysis and optimization efforts by offering insights into query execution characteristics.
- Historical Performance Tracking: Aids in tracking historical query performance metrics, facilitating performance analysis over time.
- Resource Utilization Insights: Provides information on resource utilization, execution time, and other metrics critical for assessing query efficiency.
72. What are the table constraints that are enforced?
Ans:
Netezza imposes numerous constraints on tables, including:
- Primary Key Constraints: Ensure that each record is uniquely identified.
- Foreign key constraints: Create relationships between tables.
- Unique constraints ensure that the values in the specified columns are unique.
- Check constraints: Validate data using predefined conditions.
73. How many columns can you specify in the distributing clause?
Ans:
Netezza allows you to specify up to 32 columns in the DISTRIBUTING ON clause. This clause is critical for defining the distribution key, which controls how data is distributed among SPU nodes. Selecting an appropriate distribution key is critical for improving query performance and ensuring balanced data distribution throughout the system.
74. What partitioning methods are available in Netezza?
Ans:
Distribution Key-based Partitioning: Distributes data across nodes based on a distribution key. This method optimizes data retrieval by matching distribution to query patterns, improving performance.
Random Partitioning: Data is distributed randomly across nodes without using predefined keys. Random partitioning, while less predictable than distribution key-based partitioning, can be useful for certain workloads by promoting load balancing across the system.
75. How does one redistribute a table?
Ans:
To redistribute a table in Netezza, use the ALTER TABLE statement with the DISTRIBUTE ON clause. For example:
- ALTER TABLE your_table_name DISTRIBUTE ON (column1, column2);
This command redistributes the table according to the specified columns, allowing for dynamic data distribution to meet changing requirements.
76. How do you determine whether the rows in a table are distributed equally across all SPUs?
Ans:
To see if rows are evenly distributed across all SPUs in Netezza, use the system view _V_TABLE_DISTRIBUTION:
- SELECT * FROM _V_TABLE_DISTRIBUTION WHERE table_name = ‘your_table_name’;
This query returns information on the distribution of rows across SPUs, allowing you to evaluate the balance and effectiveness of data distribution.
77. How do you delete logically deleted records?
Ans:
In Netezza, logically deleted records are removed using the ‘NZRECLAIM’ utility. This utility is designed to free up disk space by removing logically deleted or unused data from tables. The command syntax is straightforward.
- NZRECLAIM -t your_table_name;
Netezza uses this command to efficiently manage storage space, which improves overall system performance. The utility identifies and removes records that have been logically deleted, thereby ensuring optimal storage utilization.
78. How does the NOT NULL specification on a column improve Netezza performance?
Ans:
- Specifying NOT NULL on a column improves Netezza performance and reduces storage requirements.
- Avoiding the unnecessary processing of NULL values.
- Improving query optimization by removing NULLs, which simplifies data manipulation.
79. What are the best ways to create materialized views?
Ans:
When creating materialized views in Netezza, it is important to consider several best practices:
- Query Patterns: Customize materialized views to reflect common query patterns.
- Data Volatility: Assess data volatility to determine the best refresh strategies.
- Storage Optimization: Improve storage and indexing for faster query processing.
- Partitioning: Use effective partitioning methods to improve maintenance.
80. What are the options for loading data from a table into a file?
Ans:
Netezza provides several options for loading data from a table into a file. One common method is to use the ‘EXPORT’ statement within ‘NZSQL:’. This command saves data from the specified table as a CSV file. Alternatively, the ‘NZLOAD’ utility offers a high-performance solution: ‘NZLOAD’ allows you to efficiently load data into a file while specifying delimiters and other options. These methods provide flexibility for data extraction by supporting a wide range of file formats and use cases, including data interchange, backups, and additional analysis outside of the Netezza system.
81. What is the command for displaying/monitoring the status of a reclaim?
Ans:
To monitor the status of a reclaim in Netezza, you can use the nzreclaim command with the -status option:
- `nzreclaim` -status;
This command displays real-time information about the progress and status of ongoing reclaims, allowing administrators to monitor and assess the reclaim process.
82. Which is the best data appliance?
Ans:
The best data appliance is determined by specific requirements; however, Netezza, which was acquired by IBM, has been recognized for its high-performance analytics and simplicity. Appliances such as IBM Netezza are valued for their integrated hardware and software, which provide a purpose-built solution for data warehousing and analytics, with quick deployment and optimized query processing.
83. How is load handled in Netezza, and why is it so quick/fast?
Ans:
Netezza’s unique architecture enables rapid data load. The secret lies in parallel processing across multiple SPU nodes, allowing for simultaneous loading of data. Furthermore, zone maps and distribution keys simplify data placement while optimizing storage and retrieval. This parallel, distributed approach ensures rapid data loading by leveraging the entire system’s processing power.
84. When are we likely to get incorrect (aggregate) results?
Ans:
Incorrect aggregate results can occur when queries involve non-distributive functions and are executed on large-scale datasets in Netezza. Functions like COUNT DISTINCT or AVG might yield inaccurate results, as they require cross-node communication and processing. Understanding the limitations of certain functions and their impact on distribution is crucial to avoiding potential inaccuracies.
85. What two characteristics define the materialized view?
Ans:
Two key characteristics of materialized views are:
- Precomputed Results: Materialized views store precomputed results of complex or frequently executed queries, allowing for rapid data retrieval without recomputation.
- Snapshot of Data: They provide a snapshot of data at a specific point in time, capturing aggregated or transformed data for improved query performance.
86. What CREATE DATABASE attributes are required?
Ans:
When creating a database in Netezza, essential attributes include:
- Database Name: Specifies the name of the new database.
- Owner: Identifies the owner or administrator of the database.
- Encoding: Defines the character encoding scheme for the database, ensuring compatibility with data storage and retrieval.
87. Explain how data is stored in Netezza, and how SPU failover occurs.
Ans:
Data in Netezza is stored across multiple SPU nodes based on a distribution key, ensuring even distribution and efficient query processing. In the event of an SPU failure, Netezza’s failover mechanism redirects queries to other available SPUs, maintaining system integrity. The distributed architecture with failover capabilities enhances system resilience and minimizes disruptions during hardware failures.
88. Does Netezza allow for concurrent updates to the same record?
Ans:
Netezza does not support the concurrent update of the same record by multiple transactions. Netezza employs a shared-nothing architecture, and concurrent updates to the same record could lead to conflicts and compromise data integrity. To ensure consistency, Netezza relies on a locking mechanism to prevent simultaneous modifications to a single record by multiple transactions.
89. How does Netezza update records and provide an overview of how transactions are maintained?
Ans:
Netezza updates records using the `UPDATE` statement. This operation modifies existing data based on specified conditions. The system ensures data consistency by managing locks and maintaining transactional integrity. Transactions in Netezza are maintained using a combination of locking mechanisms, commit, and rollback operations. Each transaction is isolated from others to ensure data integrity. Netezza follows the principles of Atomicity, Consistency, Isolation, and Durability (ACID) to manage and maintain the correctness and reliability of database transactions.
90. What are the four environment variables that are required?
Ans:
Four essential environment variables in a Netezza environment include:
- NZ_HOST: Specifies the hostname or IP address of the Netezza system.
- NZ_DATABASE: Identifies the name of the database within the Netezza system.
- NZ_USER: Defines the username used for connecting to the Netezza database.
- NZ_PASSWORD: Provides the password associated with the specified user, ensuring secure authentication and access to the Netezza system.




