
Last updated on 04th Jul 2020| 6374
The Oracle Data Integrator, or ODI, is a comprehensive platform for data integration that makes data movement between systems easy and effective. Organisations can use it to extract, transform, and load (ETL) data from a variety of platforms, databases, and apps. Productivity is increased by ODI’s declarative design methodology, which prioritises configuration over coding. It is a reliable option for managing intricate data workflows and guaranteeing data consistency throughout the organisation because of its modular architecture, sophisticated transformation capabilities, and support for real-time data integration.
1. What is an Oracle Data Integrator?
Ans:
Oracle Data Integrator (ODI) is an advanced ETL (Extract, Transform, Load) solution developed by Oracle for successful data integration across several platforms. The declarative design style of ODI allows developers to build data transformation algorithms without explicitly setting execution order. Knowledge Modules (KMs) are used by the platform to build reusable and configurable code snippets, boosting the adaptability of ETL techniques.
2. What makes ODI different from other ETL tools?
Ans:
E-LT is an innovative approach to extracting, loading and Transforming data. Typically ETL application vendors have relied on the costly heavyweight, mid-tier servers to perform transformations required when moving large volumes of data around the enterprise.
3. How does ODI support parallel processing?
Ans:
ODI supports parallel processing by enabling the execution of multiple tasks concurrently, leveraging the capabilities of the target database. This enhances performance and accelerates data integration processes, especially when dealing with large datasets.
4. What are components of Oracle Data Integrator?
Ans:
- A Oracle Data Integrator + Topology Manager + Designer + Operator + Agent
- A Oracle Data Quality for Data Integrator
- A Oracle Data Profiling
5. What systems does ODI extract and load data into?
Ans:
ODI brings true heterogeneous connectivity out-of-the-box, it can connect natively to Oracle, Sybase, MS SQL Server, MySQL, LDAP, DB2, PostgreSQL, and Netezza.
6. Difference between Conceptual design and Detailed implementation?
Ans:
| Aspect | Conceptual design | Detailed implementation | |
| Concerned with |
Relationships and Organization of Data |
DataTechniques for storing and gaining access | |
| Represents | symbolizes an abstract data model | The real storage arrangement | |
| Examples | Entity-relationship diagram | Indexing and file structures |
7. How does ODI support web services?
Ans:
The Oracle Data Integrator Public Web Service, lets execute a scenario (a published package) from the web service called Data Services, which provides the web service over ODI data store (i.e. a table, view or the other data source registered in ODI).
8. What is the role of ODI?
Ans:
Main responsibilities of the successful ODI Developer / Oracle Data Engineer:
Build and support data warehouses/data marts/data stores to facilitate data analytics and insights. Build and support the data integration and transformation routines from the source systems to target data stores using the Oracle Data Integrator (ODI).
9. What are load plans and types of load plans?
Ans:
A load plan is the process to run or execute the multiple scenarios as a Sequential or parallel or conditional-based execution of scenarios. And same can call three types of load plans, Sequential, parallel and Condition-based load plans.
10. What are agents in ODI?
Ans:
In Oracle Data Integrator (ODI), agents are components responsible for executing data integration processes designed in ODI Studio. They manage the communication between the ODI repository and the physical execution engines, coordinating the distribution and execution of data integration tasks across multiple servers.
11. How to write subqueries in ODI?
Ans:
Using the Yellow interface and sub-queries option can create subqueries in the ODI. Using VIEW can go for sub queries Or Using ODI Procedure can call direct database queries in ODI.
12. How to remove the duplicate in ODI?
Ans:
- Use the DISTINCT at IKM level.
- It will eliminate the duplicate rows while loading into the target.
13. Describe the ODI Repository and its significance in ODI.
Ans:
The ODI Repository is important because it keeps metadata management and storage within a standardised and well-managed framework. Version control is made easier, code and component reuse is encouraged, and development teams collaborate more effectively with this centralised approach.
14. Where can you use variables?
Ans:
Variables can be used in the all Oracle data integration expressions:
- Mapping
- Filters
- Joins
- Constraints
15. How to handle exceptions?
Ans:
Handling exceptions is the crucial aspect of developing robust and reliable data integration processes in the Oracle Data Integrator (ODI). ODI provides the various mechanisms to manage and handle exceptions during execution of interfaces, procedures, and packages.
16. How to know which interface failed if I have no access to the operator?
Ans:
If you do not have access to the ODI Operator and want to identify which interface failed within the package, you can use ODI logs and sessions to gather information.
17. How to implement logic in procedures?
Ans:
Use this query on Command on a target Delete from Target_table where not exists (Select ‘X’ From Source_table Where Source_table.ID=Target_table.ID).
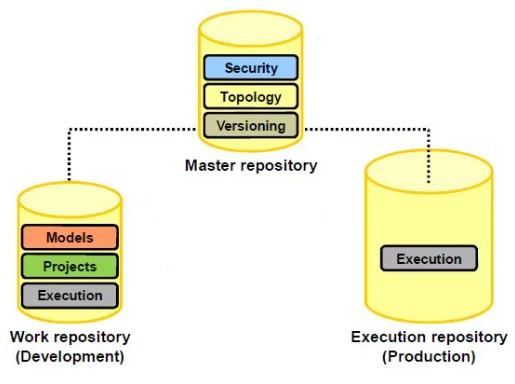
18. What is a master repository?
Ans:
A Master Repository in Oracle Data Integrator (ODI) serves as a central repository that stores metadata and configurations essential for managing and coordinating data integration projects. It acts as the control center for ODI, holding information about users, security settings, and the overall structure of ODI projects.
19. How to load data with one flat file and one RDBMS table using joins?
Ans:
Drag and drop both the File and Table into a source area and join as in the Staging area. If source and target are Oracle technology tell me process to achieve this requirement(interfaces, KMS, Models).
20. What do specify XML data server and parameters for connecting to an XML file?
Ans:
When working with the XML files, use an XML data server to define the connection details for accessing XML files. The XML data server allows to specify parameters that define connection properties.
21. How to reverse engineer views?
Ans:
Reverse engineering refers to a process of importing metadata from data sources into ODI. This metadata includes the information about tables, views, columns, constraints, and the other database objects.
22. What are the types of variables?
Ans:
A variable is the object that stores a single value. This value can be a string, a number or a date. The value is stored in the Oracle Data Integrator and can be updated at a run-time.
- Global
- Project
23. How to implement data validations?
Ans:
Implementing data validations is the crucial aspect of ensuring data quality and integrity in the Oracle Data Integrator (ODI). Data validations help identify and handle discrepancies, errors, or inconsistencies in a data being processed.
24. What is a work repository?
Ans:
Defining the connection to a work repository consists of defining the connection to a master repository, and then selecting one of the work repositories attached to the master repository.
25. How can you implement a package in a package?
Ans:
You can implement the package within another package. This capability allows to create a hierarchical structure of packages, providing the modular and organised approach to designing and managing the complex workflows.
26. What does procedure mean?
Ans:
An interface framework-uncovered set of activities may be combined using Procedures, which are reusable building blocks. Alternatively, load a datastore target from one or more sources.
27. What is a model?
Ans:
An Oracle Model is a collection of data stores that correlate to views and tables in an Oracle Schema. The Logical Schema is always the foundation of a model. Logical Schema relates to Physical Schema in a particular Context.
28. What is the definition of a package?
Ans:
The package is the Oracle Data Integrator’s largest execution unit. A package is made of a sequence of steps organised in the execution diagram.
29. What are User Parameters?
Ans:
- Oracle Data Integrator saves the user parameters such as default directories, windows positions, etc.
- User parameters are saved in an userpref.xml file in /bin.
30. What is a Project?
Ans:
In Oracle Data Integrator (ODI), a project is the fundamental organisational unit that serves as container for managing and organising the various objects related to the data integration and transformation.
31. What is Folder?
Ans:
A folder is the logical container used to organise and group related objects within a project. Folders provide a structured way to manage and categorise various ODI objects, like interfaces, procedures, packages, scenarios, variables, and more.
32. Explain ODI Operator.
Ans:
ODI Operator is the web-based interface for monitoring and managing ODI instances. It provides the real-time view of executing sessions, allows for viewing logs, managing schedules, and performing administrative tasks for a better control over ODI processes.
33. Explain ODI XML Driver.
Ans:
The ODI XML Driver is the technology used for integrating XML data. It allows for the reading and writing of XML files, defining XML structures, and transforming XML data within the ODI interfaces.
34. What are User Functions?
Ans:
User functions allow for the definition of customised functions or “function aliases,” which specify technology-dependent implementations. They may be applied to interfaces and operations.
35. What is Marker?
Ans:
Elements of the project may be flagged in order to reflect methodology or organisation of developments. Flags are defined using the markers. These markers are organised into the groups and can be applied to the most objects in a project.

Enroll in ODI Training with Industry Oriented Modules By Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
36. What is Context?
Ans:
A context is a collection of resources that enables the execution or simulation of one or more data processing applications. Contexts enable the execution of the same tasks (Reverse, Data Quality Control, Package, and so on) on multiple databases and/or schemas.
37. What are Sequences?
Ans:
A sequence is the variable that increments itself each time it is used. Between the two uses, the value can be stored in a repository or managed within an external RDBMS table.
38. Difference between Physical Schema and Logical Schema?
Ans:
In the context of databases, a logical schema refers to the way data is organized and presented at a conceptual level, independent of the physical implementation. It defines the structure of the database logically, including tables, relationships, and constraints. On the other hand, a physical schema represents the actual storage and organization of data on the physical hardware, specifying details like tablespaces, partitions, and indexes.
39. What are agents and different types of agents?
Ans:
An ODI agent is a run time component which orchestrates data integration processes.
They are the three types of Agents:
- Standalone Agent – Light Weight.
- J2EE Agent – High Availability , Scalability, Security and a better manageability.
- Colocated Standalone Agent – Combination both the standalone and J2EE agent.
40. What is Logical Schema?
Ans:
Logical schema is an alias for physical schemas and it will connect to the physical schemas through contexts. In Designer developer can access the only logical schemas he con not access the physical schemas, developer can access the logical schemas and context combination he can connect the physical schemas.
41. What is a Designer?
Ans:
Designer components are used for a complete development area. In design will work for development like creating interfaces, packages, procedures, variables, sequences and the other objects, after finishing development will generate scenarios and and can move this all scenarios into the production.
42. What is Scenario?
Ans:
A scenario is the compiled or executable object and it is not editable, in odi production environment will use only scenarios for maintaining security and hiding Because this scenario is not readable and not editable. this scenario only the schedules or executable.
43. What is Interface?
Ans:
An interface is used to load data from a source to target , here can apply all the transformations and validations and aggregations.In odi 11g interface can use only one target in a one interface, if want load data into the multiple target tables have to go for a multiple.
44. What is Yellow Interface?
Ans:
Yellow interface are using for without target tables and can create dynamically target table if don’t have a target table. For this need to enable CREATE_TARGET_TABLE option=> TRUE at IKM level.
45. What is the Simulation option at the interface?
Ans:
This option to show a complete interface process are LKM and IKM and CKM processes like creating all $tables and inserting into the target table queries everything it will give the report.
46. What is CDC?
Ans:
CDC change data capture using for to extract changed data from a source. If a source accepting Triggers on a source table will use this CDC feature if the source system they are not allowed to create the triggers can’t use this CDC feature will go for timestamp based filtering.
47. What is Oracle Data Integration Suite?
Ans:
Oracle data integration suite is the set of data management applications for a building, deploying, and managing enterprise:
- Oracle Data Integrator Enterprise Edition
- Oracle Data Relationship Management
- Oracle Service Bus (limited use)
- Oracle BPEL (limited use)
- Oracle WebLogic Server (limited use)
48. How does ODI infrastructure require an Oracle database?
Ans:
No, ODI modular repositories (Master + and one of multiple Work repositories) can be installed on any database engine that supports the ANSI ISO 89 syntax like Oracle, Microsoft SQL Server.
49. How does ODI support web services?
Ans:
- The Oracle Data Integrator Public Web Service, lets execute a scenario (a published package) from the web service call.
- Data Services, which provide the web service over an ODI data store (i.e. a table, view, or the other data source registered in ODI).
- The ODI Invoke Web Service tool can be added to the package to request the response from the web service.
50. Where does ODI sit with existing OWB implementation(s)?
Ans:
The ODI-EE licence includes the both ODI and OWB as separate products, both the tools will converge in time into “Oracle’s Unified Data Integration Product”.
51. How implement incremental loading in ODI?
Ans:
Incremental loading can be implemented using the CDC (Changed Data Capture) features such as Journalizing. Considerations for efficiency include using appropriate CDC techniques, optimising SQL queries, and leveraging indexes on the columns involved in incremental loading.
52. Explain ODI Variable?
Ans:
ODI Variables are the placeholders for dynamic values. They can be used in interfaces and packages to allow for dynamic configurations, such as changing connection details, schema names, or file paths during runtime.
53. What is ODI Topology Security?
Ans:
ODI Topology Security involves configuring access to data servers, technologies, and the other topology components. Security can be set up using ODI Topology Manager, where users and roles are granted specific privileges to control access.
54. Is ODI used by Oracle in products?
Ans:
Yes, many Oracle products use the ODI, but here are a few examples:
- Oracle Application Integration Architecture (AIA)
- Oracle Agile products
- Oracle Hyperion Financial Management
- Oracle Hyperion Planning
- Oracle Fusion Governance, Risk & Compliance
- Oracle Business Activity Monitoring
55. How will data quality be in ODI?
Ans:
In ODI, there are two methods for dealing with data quality.The first technique deals with dealing with erroneous data utilising the CKM. The second way employs the Oracle data quality tool (for enhanced quality settings).
56. What are Memos?
Ans:
A memo is the unlimited amount of text attached to virtually any object, visible on its Memo tab. When an object has the memo attached, the icon appears next to it.
57. How does ODI handle slowly changing dimensions in data warehouses?
Ans:
ODI provides built-in components and methodologies for handling Slowly Changing Dimensions (SCD). The SCD handling in ODI involves the use of specific knowledge modules and techniques like versioned CDC (Change Data Capture) to identify and manage changes in dimension tables over time.
58. What is ODI Topology Caching?
Ans:
ODI Topology Caching is the feature that allows ODI to cache topology information locally for the improved performance. It reduces need to query the repository for every operation. While it can enhance the performance, it’s essential to configure caching appropriately based on the environment.
59. What is SKM and when will you use this SKM?
Ans:
SKM (Service Knowledge Module) is used to produce the data service code. These are employed in data modelling. Data Services are specialised web services that enable access to application data in the datastores and to changes captured for these datastores using Changed Data Capture.

Get Certification Oriented ODI Course with In-Depth Practical
Weekday / Weekend BatchesSee Batch Details60. What are types of data quality control?
Ans:
There are two ways to the data quality control:
Static: will run the constraints on an existing target data. This is done after loading data into the target.
Flow: will run the constraints on the incoming data. This is done before loading data into the target.
61. What is a constraint?
Ans:
A constraint is the rule or condition applied to a set of data to ensure its accuracy, integrity, and consistency. Constraints are used to define and enforce certain properties or relationships within the database schema. They help maintain data quality and prevent entry of invalid or inconsistent data.
62. Explain Contextual Agents in ODI.
Ans:
Contextual Agents in ODI allow the users to define agent configurations specific to the different contexts, such as development, testing, or production. This is useful for managing parallel execution scenarios where different configurations are required based on context.
63. Explain step-by-step procedure to enable journalization.
Ans:
- The first step is to import the proper JKM.
- After creating the model and reverse engineering I have to add the model to the CDC and then need to subscribe to table want.
- This will enable Journalization.
64. What are the primary duties of a Data Integration Administrator?
Ans:
- Scheduling and executing a batch job.
- Configuring, starting, and stopping real-time services
- Adapters are configuration and managing them.
- Repository usage, Job Server configuration.
- Access the Server configuration.
- Batch job publishing.
65. Differentiate between ODI and traditional ETL tools.
Ans:
ODI follows an E-LT (Extract, Load, Transform) approach, where transformation is performed in a target database. Traditional ETL tools typically perform transformations in the separate ETL server before loading data into target.
66. What is the use of Topology in ODI?
Ans:
Topology in ODI defines a physical and logical architecture of a data integration environment. It includes the details such as database connections, technologies, data servers, and contexts necessary for executing interfaces and packages.
67. Explain “Interfaces” in ODI.
Ans:
Interfaces in ODI define a flow of data from source to target. They specify mapping, transformations, and loading logic for data integration processes. Interfaces can be created using the ODI Designer and executed as part of ODI Scenarios.
68. How does ODI support data quality in ETL processes?
Ans:
ODI supports the data quality through features like data profiling, data cleansing, and validation. Users can define data quality rules and implement them within ODI interfaces to ensure accuracy and reliability of data being processed.
69. What are different ways to promoting code?
Ans:
ODI can be integrated with the various Oracle tools and technologies, including the Oracle Database, Oracle Golden Gate, Oracle BI, and Oracle Warehouse Builder. This integration allows for a seamless data movement and transformation across the different components of Oracle technology stack.
70. Explain Master and Work Repositories in ODI.
Ans:
The Master Repository stores the development metadata, like projects, models, and datastores, while the Work Repository contains runtime metadata, execution logs, and scenarios. The Multiple Work Repositories can be associated with the single Master Repository, allowing for flexible architecture.
71. How does ODI handle incremental data extraction?
Ans:
ODI handles the incremental data extraction using its CDC (Changed Data Capture) features. Journalizing is the common method where changes in the source data are captured in the separate journal table. ODI can then use this information to extract only changed or new data during subsequent runs.
72. What is an ODI Agent?
Ans:
The ODI Agent is the lightweight Java process responsible for executing the ODI Scenarios. It communicates with the ODI Repository to fetch the necessary metadata and executes data integration tasks defined in the Scenarios on designated computing resources.
73. Explain “IKM” in ODI.
Ans:
The IKM (Integration Knowledge Module) in ODI is the type of Knowledge Module that focuses on handling integration aspects of data movement. It defines how data is loaded into a target, including the transformations and integrity constraints.
74. How can you implement parallel processing in ODI?
Ans:
Parallel processing in ODI can be achieved by configuring the “Degree of Parallelism” property at various levels, such as data server, physical schema, or interface. This allows ODI to parallelize the execution of tasks, improving performance.
75. What is ODI Topology?
Ans:
ODI Topology defines a physical and logical architecture of a data integration environment. It includes the configurations for data servers, physical and logical schemas, contexts, and technologies. ODI Topology is an essential for connecting to the various data sources and targets.
76. Explain Reusable Mapping in ODI.
Ans:
Reusable Mapping in ODI allows creation of modular mappings that can be shared across the multiple interfaces. It promotes reusability and simplifies maintenance by centralising common transformation logic.
77. How does ODI handle metadata versioning?
Ans:
ODI provides the versioning capabilities through its repository. Users can create versions of projects, interfaces, and other objects, allowing for the management of the changes over time. This is crucial for tracking and rolling back changes in the development environment.
78. What is Incremental Aggregation in ODI?
Ans:
Incremental Aggregation in ODI is the technique used to optimise the aggregation process by only aggregating new or changed data. It reduces the processing time by avoiding re-aggregation of the entire dataset. It is typically used in the scenarios where large datasets need periodic aggregation.
79. What is the significance of ODI Tools in ODI Studio?
Ans:
ODI Tools in ODI Studio include the components such as Designer, Operator, Topology Manager, Security Manager, and Load Plan. These tools collectively provide the comprehensive environment for designing, executing, and managing data integration processes.
80. Difference between ODI Scenario and ODI Session.
Ans:
An ODI Scenario is an instance generated from ODI Interface or Package and contains execution details. An ODI Session is the actual execution instance of an ODI Scenario. A Session is created when a Scenario is executed, and it contains runtime information, including the logs and statistics.
81. What is IKM in ODI, and how different from “LKM” and “CKM”?
Ans:
In ODI, IKM stands for an Integration Knowledge Module. It is primarily used for handling data integration aspects, including loading data into the target. LKM (Loading Knowledge Module) is used for the loading data from source to staging, and CKM (Check Knowledge Module) is used for the integrity checking.
82. What is ODI Procedure and how is it used in ODI Packages?
Ans:
ODI Procedure is the step in an ODI Package that allows execution of stored procedures or custom SQL commands. It provides a way to incorporate custom logic or perform specific tasks within the ODI Package.
83. How can ODI integrate with non-Oracle databases?
Ans:
ODI supports various technologies and data servers, allowing the integration with non-Oracle databases or systems. Topology configurations can be defined for a different data servers, enabling connectivity to the wide range of data sources and target.
84. What is Substitution API in ODI?
Ans:
The Substitution API in ODI allows dynamic substitution of values during the runtime. It is used to parameterize ODI objects and provide flexibility in configurations. The Substitution API can be employed in the variables, models, and other ODI components.
85. Explain ODI Topology Navigator in ODI Studio.
Ans:
ODI Topology Navigator in ODI Studio provides the graphical interface to view and manage ODI Topology. It allows the users to define and configure physical and logical architectures, data servers, technologies, and contexts required for connecting to the various data sources and targets.
86. What IKM SQL Control appears in ODI?
Ans:
The IKM SQL Control Append is Integration Knowledge Module in ODI used for the incremental data loading. It is designed to efficiently append new or changed records from the source to a target table using the SQL statements for control and performance.
87. How can execute ODI scenarios in parallel?
Ans:
ODI Scenarios can be executed in parallel by using multiple ODI Agents. The parallel execution can be configured at a different levels, such as execution plan, package, or load plan. This allows for a simultaneous execution of the multiple scenarios, improving performance.
88. Explain ODI top command in ODI Operator.
Ans:
The ODI Top command in ODI Operator provides the real-time view of the current sessions and scenarios being executed by the ODI Agents. It displays key information, like session status, elapsed time, and resource usage, allowing for the monitoring and troubleshooting.
89. How does ODI handle data integrity constraints during loading?
Ans:
ODI ensures data integrity during loading by allowing the users to define and enforce constraints in the interface. Constraints can be specified at a column level, and ODI will validate and enforce them during the data integration process.
90. What are different types of joins available in ODI?
Ans:
ODI supports the various types of joins, including the INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, and CROSS JOIN. These join types are used in the ODI interfaces to define relationships between the source and target datasets.




