
Last updated on 03rd Jan 2022| 3051
Azure Databricks gives the most recent variants of Apache Spark and permits you to flawlessly coordinate with open source libraries. Turn up groups and construct rapidly in a completely overseen Apache Spark climate with the worldwide scale and accessibility of Azure.
- Introduction
- Azure Databricks SQL Analytics
- Azure Databricks Workspace
- How are Azure Databricks associated with Spark?
- Components of Azure Databricks?
- Create an Azure Databricks Service
- 6 Reasons to Use Azure Databricks
- Features of Azure Databricks
- Conclusion
Introduction :-
On the remote possibility that you are a youngster at Azure Databricks then this article will guide you about the stray pieces of Azure Databricks and its various parts. nowadays we deal with a colossal proportion of data in gigabytes, petabytes, or significantly more and it is reliably creating at an astounding rate. Tremendous data comes from a wide scope of sources and it is any place around us. As of now to make huge information from this data we need to work with this data naturally and quicker.
Purplish blue Databricks is a help given by the Azure Cloud organization Step for data assessment. Purplish blue Databricks has two conditions for making data concentrated applications for instance Azure Databricks SQL assessment and Azure Databricks work area.
Azure Databricks SQL Analytics :-
It is significant for the people who need to execute SQL orders on data lake and make distinctive data discernment in reports, make and proposition dashboards.
Azure Databricks Workspace :-
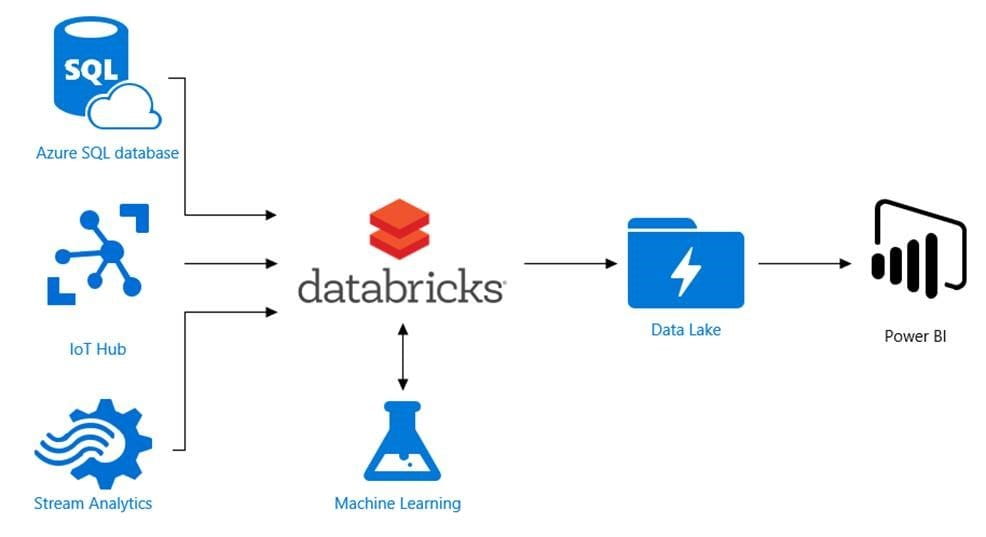
It is used to empower coordination between Azure data engineers, originators, scientists, and AI engineers. To make a pipeline through colossal data, the unrefined data is ingested into Azure through Azure Data Factory using Apache Kafka, Event Hub, or IoT Hub. Purplish blue data block is used to bring data from different sources and change it into headway encounters using Spark.
Apache Spark is an open-source, rapid bundle taking care of design and an eminent structure for enormous data examination. This system gauges the data in comparable that assists with supporting the show. It is written in Scala, a basic level language, and also keeps up with APIs for Python, SQL, Java, and R.
How are Azure Databricks associated with Spark?
In Azure, we can execute Apache Spark using Azure Databricks. Purplish blue Databricks is used to deal with tremendous data with the absolutely directed glimmer pack similarly used in data planning, data exploring, and portrayal of data using AI. Purplish blue Databricks is a very amazing Step for examination and planner neighborly. it is in like manner really versatile easily to use APIs like python, R, thus on.
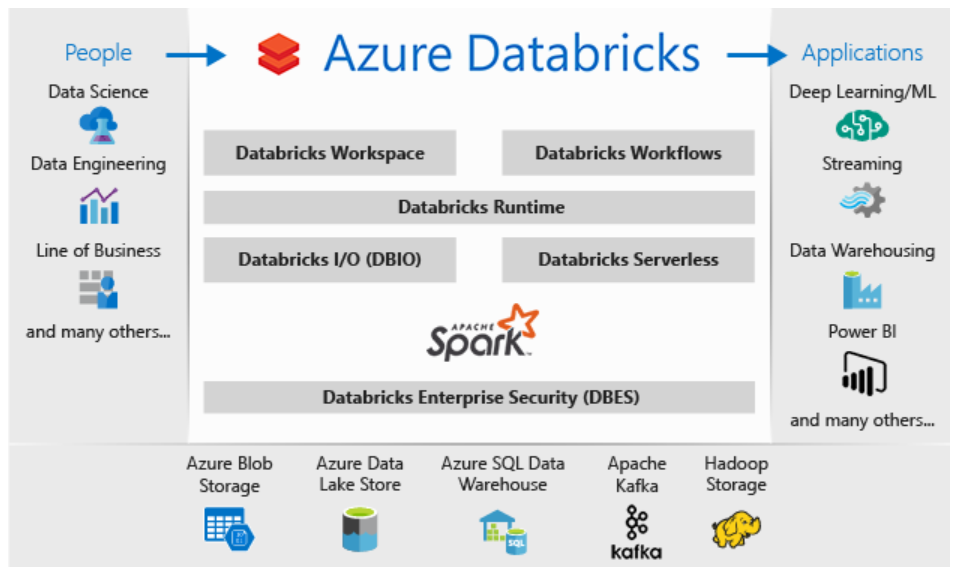
Elements and Component of Azure Databricks :-
Purplish blue Databricks has transformed into the fashioner’s most ideal choice for tremendous data assessment and Databricks maintains various vernaculars furthermore allows us to arrange many Azure organizations like data lake store, mass amassing, SQL server and clever instrument power BI, scene, etc It is an unfathomable accommodating Step letting information experts share bundles and workspaces, which prompts higher productivity.
Databricks Workspace :
It offers a sharp workspace that empowers information investigators, information fashioners, and relationship to team up and work eagerly together on diaries and dashboards.
Databricks Runtime :
Counting Apache Spark, they are an extra arrangement of parts and updates that guarantees upgrades like execution and security of gigantic information commitments and assessment. These versions are passed on reliably
As alluded to beforehand, it orchestrates essentially with different associations like Azure associations, Apache Kafka, and Hadoop Storage and you can in addition pass on the information into AI, stream evaluation, Power BI, thus forth
Since it is a completely overseen association, different resources like Storage, virtual association, and so forth are given to a launch asset pack. You can also pass on this help with your own virtual affiliation. We will see 0074his later in the article Databricks File System (DBFS)
This is a contemplating layer on top of article amassing. This licenses you to mount amassing objects like Azure Blob Storage that grants you to get to information like they were on the nearby report structure. I will show this completely in my next article in this course of action
Create an Azure Databricks Service :-
You need to follow the under referred to fundamental development to make Azure Databricks.
Step 1: Go to the Azure passage. login on portal.azure.com.
Step 2: Click on ‘+Create a resource on the arrival page.
Step 3: Here you can look ‘Sky blue Databricks’ then, press enter.
Step 4: Purplish blue Databricks page has now opened. Click ‘eager for advancement’ button to make an Azure Databrick.
Step 5: Later snap on ‘make’, you truly need to give essential information about Azure Databricks like select your enrollment, resource bundle name, workspace name which is the name of your Azure Databricks organization you want. Moreover, select your Region and assessing level. as usual it is ‘standard’ but here I am picking ‘Starter’ as I am using a free Azure participation. Then, click on straightaway.
Step 6: You want to keep away from the accompanying 3 tabs of ‘frameworks organization’, ‘advanced’, and ‘names’. Click on ‘Review+create.’ After endorsement has completed snap on make.

Develop Your Skills with Advanced windows Azure Certification Training
Weekday / Weekend BatchesSee Batch Details6 Reasons to Use Azure Databricks :-
Reason 1: Familiar dialects and climate
While Azure Databricks is Spark based, it permits ordinarily utilized programming dialects like Python, R, and SQL to be utilized. These dialects are changed over in the backend through APIs, to cooperate with Spark. This saves clients learning another programming language, like Scala, for the sole reason for conveyed examination.Recognizable programming dialects utilized for AI (like Python), factual investigation (like R), and information handling (like SQL) can undoubtedly be utilized on Spark. Slight adjustments of the dialects (like bundle names) are required for the language to communicate with Spark. The beneath table gives the name of the language API utilized.
Reason 2: Higher usefulness and cooperation
Creation Deployments: Deploying work from Notebooks into creation should be possible quickly simply by tweaking the information sources and result catalogs.Work areas: Databricks establishes a climate that gives work areas to coordinated effort (between information researchers, designers, and business investigators), conveys creation occupations (counting the utilization of a scheduler), and has an improved Databricks motor for running. These intuitive work areas permit numerous individuals to team up for information model creation, AI, and information extraction.
Rendition Control: Version control is consequently implicit, with extremely continuous changes by all clients saved. Investigating and checking is an easy undertaking on Azure Databricks.
Reason 3: Integrates effectively with the entire Microsoft stack
Purplish blue Databricks utilizes the Azure Active Directory (AAD) security structure. Existing certifications approval can be used, with the comparing security settings. Access and personality control are totally done through a similar climate. Utilizing AAD permits simple combination with the whole Azure stack including Data Lake Storage (as an information source or a result), Data Warehouse, Blob stockpiling, and Azure Event Hub.
Reason 4: Extensive rundown of information sources
Beside those Azure-based sources referenced, Databricks effectively associates with sources remembering for premise SQL servers, CSVs, and JSONs. Different information sources incorporate MongoDB, Avro records, and Couchbase. A full rundown of information sources can be viewed as here.
Reason 5: Suitable for little positions as well
While Azure Databricks is great for monstrous positions, it can likewise be utilized for more limited size occupations and improvement/testing work. This permits Databricks to be utilized as an all in one resource for all investigation work. We don’t really have to establish separate conditions or VMs for improvement work.
Reason 6: Extensive documentation and backing accessible
While Databricks is a later expansion to Azure, it has really existed for a long time. Broad documentation and backing are accessible for all parts of Databricks, including the programming dialects required. Documentation exists from Microsoft (explicit for the Azure Databricks stage) and from Databricks (coding explicit documentation for SQL, Python, and R).
Azure Databricks is strong and modest. As the current computerized unrest keeps, involving large information advancements will turn into a need for some associations. Purplish blue Databricks is incredibly adaptable and simple to get everything rolling on, making dispersed examination a lot more straightforward to utilize.
- We have seen what Azure Databricks is and the motivations behind why it is the best investigation device. Presently, let us move further with a couple of more insights regarding the examination instrument. Here are a portion of the rich elements of Azure Databricks,
- Improved Apache Spark climate: It has a solid and dependable creation climate that is overseen and upheld by Spark specialists. It permits you to flawlessly incorporate with open source libraries by giving the most recent forms of Apache Spark. It can give you a zero-administration cloud stage that incorporates completely oversaw Spark groups, intuitive work area for investigation and representation, and a stage for fueling your beloved Spark-based applications.
- Intelligent work area: You can team up viably and support usefulness by utilizing intuitive work area and scratch pad insight. This intuitive work area include empowers information researchers, information specialists, and business experts to team up and work productively. The cooperative and coordinated climate of Azure Databricks smoothes out the most common way of investigating information, prototyping, and running information driven applications in Spark.
- Databricks Runtime: Natively worked for the Azure cloud, the serverless choice aides information researchers repeat rapidly collectively by totally eliminating the foundation intricacy and the requirement for specific aptitude to set up and arrange your information framework.
- AI Integration: Through the rich mix with Power BI, it permits you to find and share your significant experiences rapidly and without any problem. You can Access progressed mechanized AI capacities utilizing the coordinated Azure Machine Learning to distinguish appropriate calculations and hyperparameters quickly. It additionally gives a focal vault to your examinations, AI pipelines, and models.
Features of Azure Databricks :-
Conclusion:-
At this point, you’d have understood that your quest for the best enormous information investigation device/arrangement closes here. Purplish blue Databricks is an adaptable help by Microsoft that can permit you to dissect huge information responsibilities all the more proficiently.




