
Last updated on 17th Dec 2021| 3138
A data pipeline is a service or set of actions that process data in sequence. This means that the results or output from one segment of the system become the input for the next.
- Introduction to data pipelining
- Why Is Building a Data Pipeline Important?
- Data pipeline components
- When do you need a data pipeline?
- Implementation options for data pipelines
- 6 Steps to Building an Efficient Data Pipeline
- Data Pipeline Best Practices
- Architecture Examples
- Data Pipeline vs ETL
- Conclusion
- A information pipeline is a chain of information processing steps. If the information isn’t always presently loaded into the information platform, then it’s miles ingested at the start of the pipeline. Then there are a chain of steps wherein every step promises an output this is the enter to the following step. This maintains till the pipeline is complete. In a few cases, unbiased steps can be run in parallel.
- Data pipelines include 3 key elements: a supply, a processing step or steps, and a vacation spot. In a few information pipelines, the vacation spot can be known as a sink. Data pipelines permit the go with the drift of information from an utility to a information warehouse, from a information lake to an analytics database, or right into a charge processing system, for example. Data pipelines additionally may also have the equal supply and sink, such that the pipeline is only approximately enhancing the information set. Any time information is processed among factor A and factor B (or factors B, C, and D), there may be a information pipeline among the ones factors.
Introduction to data pipelining
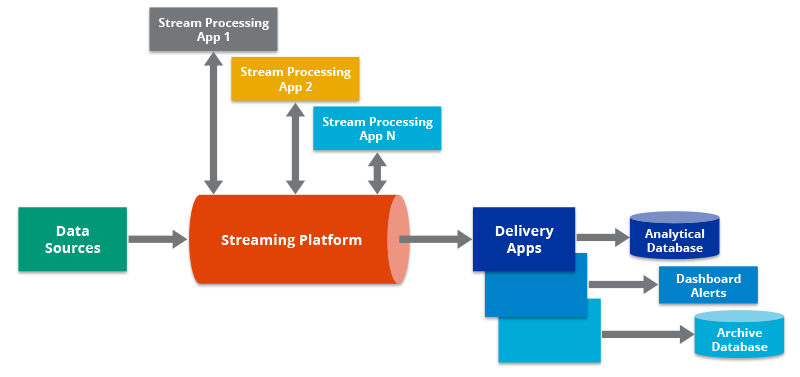
- Building a resilient cloud-local facts pipeline facilitates corporations swiftly pass their facts and analytics infrastructure to the cloud and boost up virtual transformation.
- Deploying the facts pipeline will assist agencies construct and control workloads withinside the cloud efficiently. Organizations can enhance facts quality, connect with numerous facts sources, ingest established and unstructured facts right into a cloud facts lake, and control complicated multi-cloud environments. Data scientists and facts engineers want dependable facts pipelines to get right of entry to high-quality, relied on facts for his or her cloud analytics and AI/ML tasks in an effort to force innovation and offer a aggressive part for his or her corporations.
Why Is Building a Data Pipeline Important?
Data pipeline components
To recognize how the records pipeline works in general, let’s see what a pipeline generally is composed of. Senior studies analyst of Eckerson Group David Wells considers 8 varieties of records pipeline components. Let’s speak them in brief:-
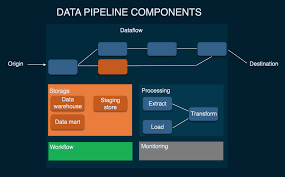
Origin:
Origin is the factor of records access in a records pipeline. Data reassets (transaction processing utility, IoT tool sensors, social media, utility APIs, or any public datasets) and garage structures (records warehouse, records lake, or records lakehouse) of a company’s reporting and analytical records surroundings may be an foundation.

Learn Advanced Data Warehousing and ETL Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsDestination:
The very last factor to which records is transferred is known as a vacation spot. Destination relies upon on a use case: Data may be sourced to energy records visualization and analytical gear or moved to garage like a records lake or a records warehouse. We’ll get again to the varieties of storages a chunk later.
Dataflow:
That’s the motion of records from foundation to vacation spot, along with the modifications it undergoes alongside the manner in addition to records shops it is going thru. One of the techniques to dataflow is known as ETL, which stands for extract, transform, and load:
Extract – getting/consuming records from original, disparate supply structures.
Transform – transferring records in a brief garage called a staging area. Transforming records to make sure it meets agreed codecs for similarly makes use of, including analysis.
Load – loading reformatted records to the very last garage vacation spot.
Storage:
Storage refers to structures wherein records is preserved at special levels because it movements thru the pipeline. Data garage picks depend upon diverse factors, for example, quantity of records and frequency and quantity of queries to a garage system, makes use of of records, etc. (think about the web bookstall example).
Processing:
Processing consists of sports and steps for consuming records from reassets, storing it, transforming, and turning in to a vacation spot. While records processing is associated with dataflow, it specializes in a way to put into effect this motion. For instance, you possibly can ingest records via way of means of extracting it from supply structures, copying from one database to some other one (database replication), or via way of means of streaming records. We point out simply 3 alternatives, however there are greater of them.
Workflow:
Workflow defines a series of strategies (responsibilities) and their dependence on every different in a records pipeline. Knowing numerous concepts – jobs, upstream, and downstream – might assist you here. A process is a unit of labor or execution that plays designated work – what’s being completed to records on this case. Upstream approach a supply from which records enters a pipeline, at the same time as downstream approach a vacation spot it is going to. Data, like water, flows down the records pipeline. Also, upstream jobs are those that have to be correctly accomplished earlier than the following ones – downstream – can begin.
Monitoring:
The intention of tracking is to test how the records pipeline and its levels are working: whether or not it stays green with developing records load, records stays correct and regular because it is going thru processing levels, or whether or not no records is misplaced alongside the manner.
Technology:
These are gear and infrastructure in the back of records flow, garage, processing, workflow, and tracking. Tooling and infrastructure alternatives depend upon many factors, including enterprise length and industry, records volumes, use instances for records, budget, protection requirements, etc. Some of the constructing blocks for records pipeline are:
ETL gear, along with records guidance and records integration gear (Informatica Power Center, Apache Spark, Talend Open Studio).
Records warehouses – significant repositories for relational records transformed (processed) for a selected purpose (Amazon Redshift, Snowflake, Oracle). Since the principle customers are commercial enterprise professionals, a not unusualplace use case for records warehouses is commercial enterprise intelligence.
Records lakes – storages for raw, each relational and non-relational records (Microsoft Azure, IBM). Data lakes are basically utilized by records scientists for system studying projects.
Batch workflow schedulers (Airflow, Luigi, Oozie, or Azkaban) that permit customers to programmatically specify workflows as responsibilities with dependencies among them, in addition to automate and reveal those workflows.
Gear for processing streaming records – records that’s constantly generated via way of means of reassets like equipment sensors, IoT devices, transaction structures (Apache Spark, Flink, Storm, Kafka). programming languages (Python, Ruby, Java) to outline pipeline strategies as a code.
When do you need a data pipeline?
Reliable infrastructure for consolidating and coping with facts facilitates groups electricity their analytical gear and assist day by day operations. Having a facts pipeline is vital in case you plan to apply facts for unique purposes, with as a minimum one in every of them requiring facts integration, for example, processing and storing transaction facts and engaging in a income fashion evaluation for the entire quarter. To perform the evaluation, you may have to tug facts from some of sources (i.e., a transaction system, CRM, a internet site analytics tool) to get right of entry to it from a unmarried garage and put together it for the evaluation. So, a facts pipeline permits for solving “origin-destination” problems, particularly with big quantities of facts.Also, the greater use cases, the greater bureaucracy facts may be saved in, the greater methods it may be processed, transmitted, and used.
- On-premises records pipeline. To have an on-premises records pipeline, you purchase and installation hardware and software program on your personal records middle. You additionally must hold the records middle yourself, looking after records backup and recovery, doing a fitness take a look at of your records pipeline, or growing garage and computing capabilities. This technique is time- and resource-in depth however will provide you with complete manipulate over your records, that is a plus.
- Cloud records pipeline. Cloud records infrastructure approach you don’t have bodily hardware. Instead, you get entry to a provider’s garage area and computing strength as a provider over the net and pay for the assets used. This brings us to a dialogue of the professionals of a cloud-primarily based totally records pipeline.
- You don’t manipulate infrastructure and fear approximately records protection due to the fact it’s the supplier’s responsibility, Scaling garage extent up and down is an issue of some clicks.
- You can alter computational strength to fulfill your wishes.
- Downtime dangers are near zero.
- Cloud guarantees quicker time-to-market.
- Disadvantages of cloud encompass the risk of a supplier lock: It could be pricey to exchange companies if one of the many pipeline answers you use (i.e., a records lake) doesn’t meet your wishes or in case you discover a inexpensive alternative. Also, you ought to pay a supplier to configure settings for cloud offerings except you’ve got got a records engineer for your team.
- If you war to assess which alternative is proper for you in each the fast and lengthy run, don’t forget speaking to records engineering consultants.
Implementation options for data pipelines
You can put into effect your records pipeline the usage of cloud offerings through companies or construct it on-premiseson:-
6 Steps to Building an Efficient Data Pipeline
Building an green facts pipeline is a easy six-step method that includes:-
1. Cataloging and governing the facts, permitting get admission to to depended on and compliant facts at scale throughout the employer.
2. Efficiently eating the facts from diverse reassets together with on-premises databases or facts warehouses, SaaS programs, IoT reassets, and streaming programs right into a cloud facts lake.
3. Integrating the facts via way of means of cleansing, enriching, and reworking it via way of means of growing zones together with a touchdown zone, enrichment zone, and an employer zone.
4. Applying facts exceptional policies to cleanse and manipulate facts whilst making it to be had throughout the employer to help DataOps.
5. Preparing the facts to make certain that subtle and cleansed facts movements to a cloud facts warehouse for permitting self-carrier analytics and facts technological know-how use cases.
6. Stream processing to derive insights from real-time facts coming from streaming reassets together with Kafka after which transferring it to a cloud facts warehouse for analytics consumption.
- Seamlessly install and method any information on any cloud atmosphere consisting of Amazon Web Services (AWS), Microsoft Azure, Google Cloud, and Snowflake for each batch and actual-time processing.
- Efficiently ingest information from any supply, consisting of legacy on-premises systems, databases, CDC reassets, applications, and IoT reassets into any goal, consisting of cloud information warehouses and information lakes.
- Detect schema flow in RDBMS schema withinside the supply database or a amendment to a table, consisting of including a column or editing a column length and mechanically replicating the goal adjustments in actual time for information synchronization and actual-time analytics use cases.
- Provide a easy wizard-primarily based totally interface with out a hand-coding for a unified experience.
- Incorporate automation and intelligence talents consisting of auto-tuning, auto-provisioning, and auto-scaling to layout time and runtime.
- Deploy in a totally controlled superior serverless surroundings for enhancing productiveness and operational efficiency.
- Apply information first-class policies to carry out cleaning and standardization operations to remedy not unusualplace information first-class problems.
Data Pipeline Best Practices
When enforcing a information pipeline, corporations have to bear in mind numerous nice practices early withinside the layout section to make certain that information processing and transformation are robust, efficient, and clean to maintain. The information pipeline have to be up to date with the ultra-modern information and have to cope with information extent and information first-class to deal with DataOps and MLOps practices for handing over quicker results. To assist next-gen analytics and AI/ML use cases, your information pipeline have to have the ability to:-
- Another instance is a streaming statistics pipeline. In a streaming statistics pipeline, statistics from the factor of income device might be processed as it’s far generated. The move processing engine ought to feed outputs from the pipeline to statistics stores, advertising and marketing applications, and CRMs, amongst different applications, in addition to lower back to the factor of sale device itself.
- A 1/3 instance of a statistics pipeline is the Lambda Architecture, which mixes batch and streaming pipelines into one structure. The Lambda Architecture is famous in huge statistics environments as it permits builders to account for each real-time streaming use instances and historic batch analysis. One key element of this structure is that it encourages storing statistics in uncooked layout so you can usually run new statistics pipelines to accurate any code mistakes in previous pipelines, or to create new statistics locations that allow new forms of queries.
Architecture Examples
Data pipelines can be architected in numerous special ways. One not unusualplace instance is a batch-primarily based totally statistics pipeline. In that instance, you can have an utility which include a factor-of-sale device that generates a huge range of statistics factors which you want to push to a statistics warehouse and an analytics database. Here is an instance of what that could appearance like:-
Data Pipeline vs ETL
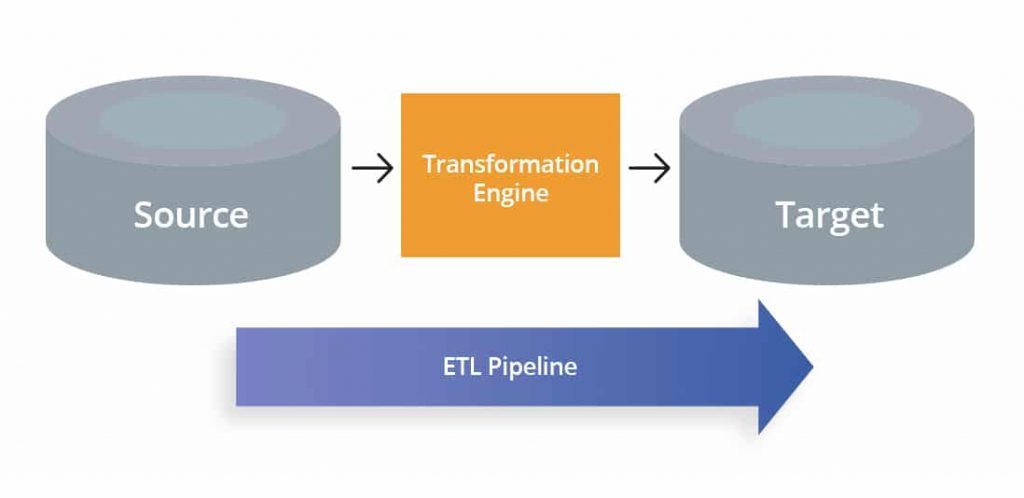
As said above, the term “records pipeline” refers back to the large set of all approaches wherein records is moved among structures. ETL pipelines are a specific sort of records pipeline. Below are 3 key variations among the two:-
1. First, records pipelines don’t should run in batches. ETL pipelines typically circulate records to the goal machine in batches on a ordinary schedule. But sure records pipelines can carry out real-time processing with streaming computation, which permits records units to be constantly updated. This helps real-time analytics and reporting and might cause different apps and structures.
2. Second, records pipelines don’t should remodel the records. ETL pipelines remodel records earlier than loading it into the goal machine. But records pipelines can both remodel records after loading it into the goal machine (ELT) or now no longer remodel it at all.
3. Third, records pipelines don’t should prevent after loading the records. ETL pipelines stop after loading records into the goal repository. But records pipelines can movement records, and consequently their load method can cause approaches in different structures or allow real-time reporting.
Conclusion
Pipelining is a effective method to take gain of OpenACC’s asynchronous competencies to overlap computation and statistics switch to hurry up a code. On the reference gadget including pipelining to the code outcomes in a 2.9× speed-up and lengthening the pipeline throughout six gadgets will increase this speed-as much as 7.8× over the original. Pipelining is simply one manner to put in writing asynchronous code, however. For stencil forms of codes, together with finite distinction and spectral detail methods, asynchronous conduct can be used to overlap the alternate of boundary situations with calculations on indoors elements. When operating on very massive datasets, it could be viable to apply asynchronous coding to divide the paintings among the host CPU and accelerator or to carry out out-of-middle calculations to move the statistics thru the accelerator in smaller chunks. Writing asynchronous code calls for quite a few forethought and cautious coding, however the stop end result is regularly higher usage of all to be had gadget assets and progressed time to solution.




