
Last updated on 16th Jul 2020| 3352
What is MapReduce?
MapReduce in simple terms can be explained as a programming model that allows the scalability of multiple servers in a Hadoop cluster. It can be used to write applications to process huge amounts of data in parallel on clusters of commodity hardware. It is inspired by the map and reduce functions commonly used in functional programming.
A MapReduce program usually executes in three stages — map stage, shuffle stage and reduce stage.
- Map stage – In this stage, the input data is split into fixed sized pieces known as input splits. Each input split is passed through a mapping function to produce output values.
- Shuffle stage – The output values from the map stage is consolidated in the next stage, which is the shuffle stage.
- Reduce stage – The output from the shuffle stage is are combined to return a single value and is stored in the HDFS.
MAPREDUCE is a software framework and programming model used for processing huge amounts of data. MapReduce program work in two phases, namely, Map and Reduce. Map tasks deal with splitting and mapping of data while Reduce tasks shuffle and reduce the data.
Hadoop is capable of running MapReduce programs written in various languages: Java, Ruby, Python, and C++. MapReduce programs are parallel in nature, thus are very useful for performing large-scale data analysis using multiple machines in the cluster.
The input to each phase is key-value pairs. In addition, every programmer needs to specify two functions: map function and reduce function.
The strengths of MapReduce
Apache Hadoop usually has two parts, the storage part and the processing part. MapReduce falls under the processing part. Some of the various advantages of Hadoop MapReduce are:
- Scalability – The biggest advantage of MapReduce is its level of scalability, which is very high and can scale across thousands of nodes.
- Parallel nature – One of the other major strengths of MapReduce is that it is parallel in nature. It is best to work with both structured and unstructured data at the same time.
- Memory requirements – MapReduce does not require large memory as compared to other Hadoop ecosystems. It can work with minimal amount of memory and still produce results quickly.
- Cost reduction – As MapReduce is highly scalable, it reduces the cost of storage and processing in order to meet the growing data requirements.
Advantages of MapReduce:
Here we learn some important Advantages of MapReduce Programming Framework,
1. Scalability
Hadoop as a platform that is highly scalable and is largely because of its ability that it stores and distributes large data sets across lots of servers. The servers used here are quite inexpensive and can operate in parallel. The processing power of the system can be improved with the addition of more servers. The traditional relational database management systems or RDBMS were not able to scale to process huge data sets.
2. Flexibility
Hadoop MapReduce programming model offers flexibility to process structure or unstructured data by various business organizations who can make use of the data and can operate on different types of data. Thus, they can generate a business value out of those data which are meaningful and useful for the business organizations for analysis. Irrespective of the data source whether it be a social media, clickstream, email, etc. Hadoop offers support for a lot of languages used for data processing. Along with all this, Hadoop MapReduce programming allows many applications such as marketing analysis, recommendation system, data warehouse, and fraud detection.

3. Security and Authentication
If any outsider person gets access to all the data of the organization and can manipulate multiple petabytes of the data it can do much harm in terms of business dealing in operation to the business organization. This risk is addressed by the MapReduce programming model by working with hdfs and HBase that allows high security allowing only the approved user to operate on the stored data in the system.
4. Cost-effective solution
Such a system is highly scalable and is a very cost-effective solution for a business model that needs to store data which is growing exponentially inline of current day requirement. In the case of old traditional relational database management systems, it was not so easy to process the data as with the Hadoop system in terms of scalability. In such cases, the business was forced to downsize the data and further implement classification based on assumptions how certain data could be valuable to the organization and hence removing the raw data. Here the Hadoop scaleout architecture with MapReduce programming comes to the rescue.
5. Fast
Hadoop distributed file system HDFS is a key feature used in Hadoop which is basically implementing a mapping system to locate data in a cluster. MapReduce programming is the tool used for data processing and it is located also in the same server allowing faster processing of data. Hadoop MapReduce processes large volumes of data that is unstructured or semi-structured in less time.
6. A simple model of programming
MapReduce programming is based on a very simple programming model which basically allows the programmers to develop a MapReduce program that can handle many more tasks with more ease and efficiency. MapReduce programming model is written using Java language is very popular and very easy to learn. It is easy for people to learn Java programming and design data processing model that meets their business need.
7. Parallel processing
The programming model divides the tasks in a manner that allows the execution of the independent task in parallel. Hence this parallel processing makes it easier for the processes to take on each of the tasks which helps to run the program in much less time.
8. Availability and resilient nature
Hadoop MapReduce programming model processes the data by sending the data to an individual node as well as forward the same set of data to the other nodes residing in the network. As a result, in case of failure in a particular node, the same data copy is still available on the other nodes which can be used whenever it is required ensuring the availability of data.
In this way, Hadoop is fault tolerant. This is a unique functionality offered in Hadoop MapReduce that it is able to quickly recognize the fault and apply a quick fix for an automatic recovery solution.
How MapReduce Works?
The whole process goes through four phases of execution namely, splitting, mapping, shuffling, and reducing.
Let’s understand this with an example –
Consider you have following input data for your Map Reduce Program
- Welcome to Hadoop Class
- Hadoop is good
Hadoop is bad
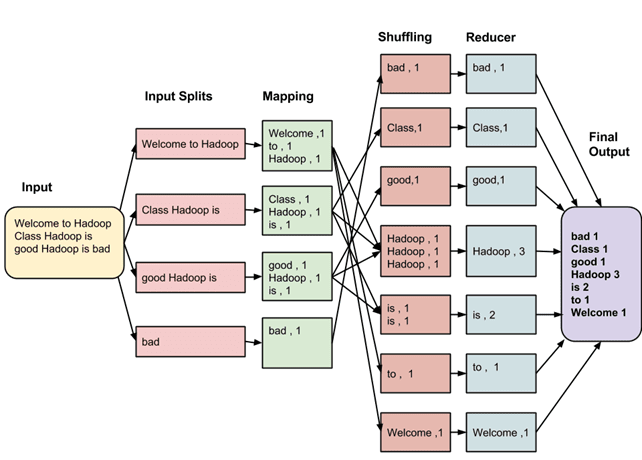
How MapReduce Organizes Work?
Hadoop divides the job into tasks. There are two types of tasks:
- Map tasks (Splits & Mapping)
- Reduce tasks (Shuffling, Reducing)
as mentioned above.
The complete execution process (execution of Map and Reduce tasks, both) is controlled by two types of entities called
- Jobtracker: Acts like a master (responsible for complete execution of submitted job)
- Multiple Task Trackers: Acts like slaves, each of them performing the job
For every job submitted for execution in the system, there is one Jobtracker that resides on Namenode and there are multiple tasktrackers which reside on Datanode.
- A job is divided into multiple tasks which are then run onto multiple data nodes in a cluster.
- It is the responsibility of job tracker to coordinate the activity by scheduling tasks to run on different data nodes.
- Execution of individual task is then to look after by task tracker, which resides on every data node executing part of the job.
- Task tracker’s responsibility is to send the progress report to the job tracker.
- In addition, task tracker periodically sends ‘heartbeat’ signal to the Jobtracker so as to notify him of the current state of the system.
- Thus job tracker keeps track of the overall progress of each job. In the event of task failure, the job tracker can reschedule it on a different task tracker.




