
Last updated on 04th Oct 2025| 10500
- Introduction to Apache Spark
- What are RDDs in Apache Spark?
- What are DataFrames in Apache Spark?
- Core Differences Between RDDs and DataFrames
- Performance Comparison: RDDs vs. DataFrames
- Use Cases: When to Use RDDs
- Use Cases: When to Use DataFrames
- Converting Between RDDs and DataFrames
- Conclusion
Introduction to Apache Spark
Apache Spark is one of the most powerful and popular open-source big data processing engines used for batch and real-time analytics. It’s built for speed, scalability, and ease of use, making it a favorite among data engineers and scientists alike. Spark offers several core abstractions for handling data, the most prominent being RDDs (Resilient Distributed Datasets) and DataFrames. Understanding these two core components is essential for anyone working with Spark,Data Science Training as the choice between RDDs vs DataFrames can significantly impact application performance, readability, and scalability. Apache Spark is a fast, open-source unified analytics engine designed for big data processing. It offers in-memory computing, enabling high-speed data analysis and supports diverse workloads like batch processing, streaming, machine learning, and graph analytics. Spark simplifies complex data workflows with easy-to-use APIs across multiple languages.
What are RDDs in Apache Spark?
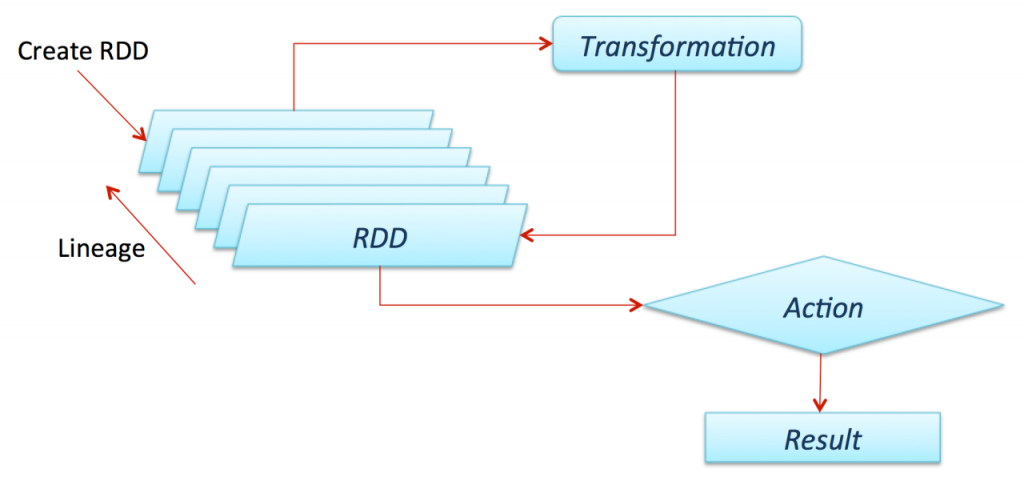
RDD, or Resilient Distributed Dataset, is the original low-level data abstraction in Apache Spark. It represents an immutable, distributed collection of objects that can be processed in parallel. RDDs in Apache Spark provide fine-grained control over data and operations Kafka vs RabbitMQ , making them useful in scenarios that require custom processing logic or low-level transformations.
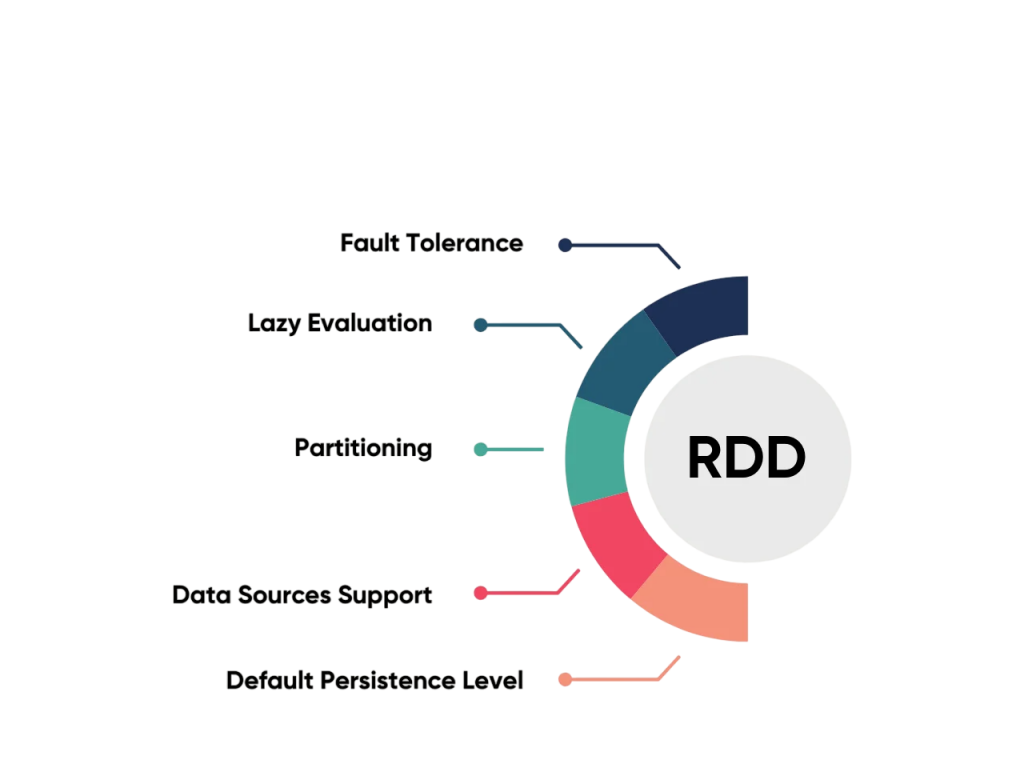
Key Characteristics of RDDs:
- Fault-tolerant: Built to recover automatically from failures.
- Distributed: Data is split across multiple nodes in a cluster.
- Immutable: Once created, an RDD cannot be changed. Transformations result in a new RDD.
- Lazy Evaluation: Transformations are not executed immediately but only when an action is called.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
What are DataFrames in Apache Spark?
- Structured Data Representation: DataFrames organize data into named columns, similar to tables in a relational database.
- Distributed Collection: They are distributed across a cluster, enabling parallel processing of large datasets.
- Schema-Aware: DataFrames have an explicit schema, defining data types for each column, which helps optimize queries.
- Supports Multiple Languages: Dedup : Splunk Documentation Accessible through APIs in Python, Scala, Java, and R.
- Optimized Execution: Uses Spark’s Catalyst optimizer to plan and execute efficient query operations.
- Easy Data Manipulation: Provides a wide range of functions for filtering, aggregation, and transformation of data.
- Integration: Works seamlessly with various data sources like JSON, Parquet, Hive, and JDBC.
- Low-level API with fine-grained control over data.
- No automatic query optimization.
- Can be slower and use more resources.
- Requires more manual coding and management.
- Best for unstructured data and complex transformations What is Data Pipelining.
- High-level, tabular abstraction with named columns and schema.
- Uses Spark’s Catalyst optimizer for efficient query planning.
- Generally faster and better at memory management.
- Provides concise, expressive APIs for data manipulation.
- Ideal for structured data and SQL-like operations.
- When you need fine-grained control over your data processing logic.
- When dealing with unstructured data or binary formats that don’t fit into DataFrame schemas.
- For complex transformations, aggregations, or custom partitioning.
- When using legacy Spark code or libraries that are built around RDDs.
- Use spark.createDataFrame(rdd) to convert an RDD to a DataFrame.
- Requires defining a schema (either programmatically or by using case classes/Row objects).
- Enables leveraging DataFrame optimizations on existing RDD data.
- Use the .rdd method on a DataFrame to convert it back to an RDD.
- This gives access to low-level RDD operations and fine-grained control Elasticsearch Nested Mapping .
- May result in losing schema information and optimization benefits.
- Convert RDD to DataFrame for better performance and SQL operations.
- Convert DataFrame to RDD for complex transformations not supported by DataFrames.
- Language Support: Supported in Scala, Python (PySpark), and Java APIs.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Core Differences Between RDDs and DataFrames
| Feature | RDDs | DataFrames |
|---|---|---|
| Abstraction Level | Low-level | DataFrames |
| Performance | Moderate | High (due to optimizations) |
| Ease of Use | Complex | Simple, declarative API |
| Optimizations | No automatic optimization | Catalyst & Tungsten for query optimization |
| Schema | No schema | Has schema (structured data) |
These differences highlight that while RDDs offer more control, Data Science Training DataFrames offer more power in terms of speed and efficiency, especially for structured data.

Performance Comparison: RDDs vs. DataFrames
RDDs (Resilient Distributed Datasets):
DataFrames:
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Use Cases: When to Use RDDs
While RDDs are not the recommended default for most workflows today, they still serve important purposes What is Splunk Rex .
When to Choose RDDs:
RDDs offer flexibility and transparency but require more effort from the developer in terms of performance tuning.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Use Cases: When to Use DataFrames
DataFrames in Apache Spark are best suited for scenarios involving structured or semi-structured data where schema and optimization are important. They excel in handling large datasets that require SQL-like querying, filtering, aggregation, and transformation. When working with data sources such as JSON, Parquet, CSV, or databases, DataFrames provide a convenient and efficient interface for seamless data integration. Their built-in schema enables Spark’s Catalyst optimizer to generate efficient execution plans What is Azure Data Lake , making DataFrames ideal for complex analytical queries that demand high performance. They are also perfect for machine learning pipelines, where structured input data is processed in stages. Additionally, DataFrames support multiple programming languages like Python, Scala, and Java, offering flexibility for diverse development teams. Overall, DataFrames are the preferred choice when ease of use, performance optimization, and working with tabular data are priorities, enabling faster development and better resource utilization in big data applications.
Converting Between RDDs and DataFrames
RDD to DataFrame:
DataFrame to RDD:
Use Cases:
Conclusion
In summary, both RDDs vs DataFrames play crucial roles in Apache Spark’s ecosystem. While RDDs offer low-level control and flexibility for complex, unstructured data transformations, Converting Between RDDs and DataFrames DataFrames provide a higher-level, optimized abstraction ideal for structured data and SQL-like operations. Understanding when and how to use each, as well as converting between them, empowers data professionals to maximize Spark’s performance and versatility. By leveraging DataFrames’ built-in optimizations and RDDs’ fine-grained control, Data Science Training developers can build efficient, scalable big data applications tailored to diverse processing needs. In modern Spark development, DataFrames are preferred for most tasks, due to their performance optimization, ease of use, and compatibility with Spark SQL. However, RDDs still have their place in low-level system development, research, and scenarios requiring custom data manipulation. By understanding the strengths and trade-offs of both, developers can build highly scalable, maintainable, and performant data pipelines tailored to business needs.




