
Last updated on 06th Oct 2025| 10363
- Introduction
- What is HDFS?
- Evolution and History of HDFS
- HDFS Architecture Overview
- Key Components of HDFS
- How HDFS Works
- Features and Benefits of HDFS
- Use Cases and Applications of HDFS
- Conclusion
Introduction
In today’s digital age, organizations generate massive volumes of data every second from social media interactions and e-commerce transactions to sensor logs, mobile usage, and IoT devices. Storing and managing this big data reliably and efficiently became a challenge for traditional file systems, which were never designed to handle such volume, velocity, and variety. To overcome these limitations, professionals increasingly rely on specialized Data Science Training building the expertise needed to implement scalable architectures, optimize data workflows, and extract insights from complex, high-throughput environments. This challenge gave rise to a new generation of storage solutions most notably, the Hadoop Distributed File System (HDFS), a fundamental component of the Apache Hadoop ecosystem. HDFS addresses the critical need for scalable, fault-tolerant, and high-throughput storage, laying the foundation for big data analytics.
What is HDFS?
HDFS (Hadoop Distributed File System) is a distributed file system designed to run on commodity hardware and support large-scale data storage. It allows data to be stored across multiple machines while appearing to users as a single unified system. HDFS is the primary storage system used by Hadoop applications, optimized for high-throughput access to large datasets and designed to store files that are gigabytes to terabytes in size. While its architecture ensures scalability and fault tolerance, maintaining data integrity across such volumes requires a clear framework this is where Data Governance Explained becomes essential, outlining the policies, roles, and standards that ensure responsible data management in distributed environments. In essence, HDFS breaks large files into blocks and distributes them across a cluster of nodes. This distribution, coupled with data replication, ensures both fault tolerance and parallel data processing, two cornerstones of Hadoop’s design.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Evolution and History of HDFS
HDFS (Hadoop Distributed File System) was inspired by Google’s GFS (Google File System) and was created as part of the Apache Hadoop project, initiated by Doug Cutting and Mike Cafarella in 2006. Originally designed to support the Nutch web crawler, Hadoop quickly evolved into a general-purpose big data processing platform, and HDFS became its core storage component.
Key historical milestones:
- 2006: Hadoop project started; HDFS designed based on GFS.
- 2008: Yahoo adopted and scaled Hadoop to store petabytes of data.
- 2010: HDFS became widely adopted in enterprise big data solutions.
- Present: HDFS is used by hundreds of companies, including Facebook, LinkedIn, Twitter, and Netflix.
Over the years, HDFS (Hadoop Distributed File System) has matured to support federation, high availability (HA), snapshots, and HDFS erasure coding, making it more robust and enterprise-ready.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
HDFS Architecture Overview
At its core, HDFS Architecture follows a master/slave architecture and is composed of two main types of nodes: the NameNode and the DataNode. Understanding how these components interact is fundamental to mastering Big Data Analytics, where efficient data storage, fault tolerance, and distributed processing form the backbone of scalable analytical systems.
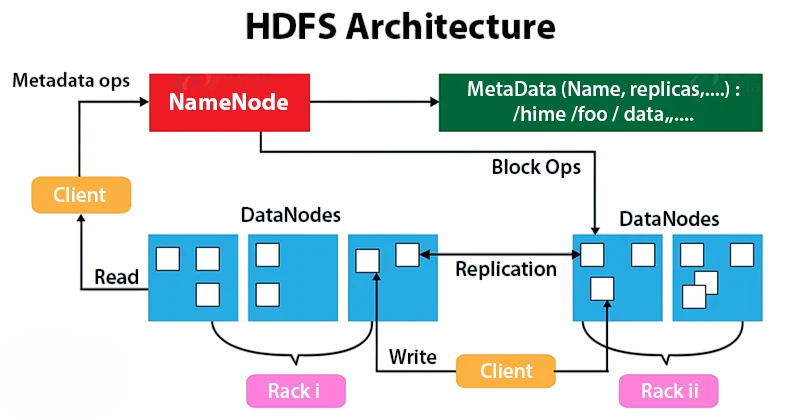
- NameNode: The master server that manages the metadata and namespace of the file system.
- DataNodes: Worker nodes responsible for storing actual data blocks and serving read/write requests from clients.
High-Level Architecture:
- A file is split into blocks: Default size: 128 MB or 256 MB.
- Each block is replicated: Across multiple DataNodes (default: 3 copies).
- NameNode: Keeps track of where blocks are stored, but does not store data itself.
- Clients: Access files by first contacting the NameNode for metadata, then communicating directly with DataNodes for data.
HDFS Architecture ensures fault tolerance, scalability, and parallel processing capabilities that are essential for big data operations.

Key Components of HDFS
The intricate design Hadoop Distributed File System (HDFS) is made up of various components that work together in a delightful manner to provide strong and effective data storage. One component among these is the NameNode that functions like a central metadata server, which is in charge of the file system namespace keeping records of directory structures, file names, and block locations, besides storing important metadata in memory for quick access.
To master such architectural elements within distributed systems, targeted Data Science Training is essential enabling professionals to design efficient storage frameworks and manage metadata for high-performance analytics. Alongside the NameNode, DataNodes are needed to carry the data blocks on local disks, send a kind of heartbeat every so often and block reports, they also perform the work of the client read/write requests, and as a result of the automatic data replication, parts of the data are spread across the nodes. The Secondary NameNode, however, only has the authority to be the most indispensable helper as it usually joins the system snapshots with the transaction logs and thus assuages the problem of memory load besides facilitating the process of crash recovery.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
How HDFS Works
HDFS (Hadoop Distributed File System) manages file reading and writing requests through a complex distributed architecture that guarantees excellent performance and reliability. In the process of file writing, the client starts the operation by contacting the NameNode, which first checks the namespace and creates a new file, then it also provides a list of DataNodes to store the blocks. Subsequently, the file is broken down into blocks in a very organized manner and is sent through a pipeline mechanism, with each block being replicated on different DataNodes to ensure that the data is not lost. To process and analyze this distributed data efficiently, tools like Apache Pig play a crucial role offering a high-level scripting platform that simplifies complex data transformations across Hadoop ecosystems. The client is then given a success response when the last block writing and confirmation have been done successfully. In the same way, file reading operations include the client asking the NameNode for file metadata, which gives accurate locations of the blocks, thus enabling the direct parallel access of the blocks from the DataNodes that are suitable for the given locations.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
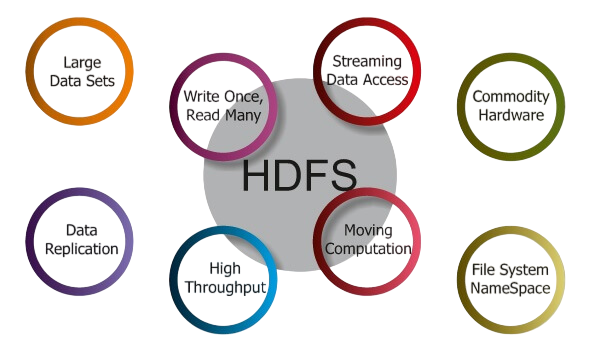
Features and Benefits of HDFS
HDFS (Hadoop Distributed File System) is designed specifically to meet the demands of large-scale data processing. To extract meaningful insights from this data efficiently, tools like Spark SQL and the DataFrame API are essential offering a unified interface for querying structured data, optimizing performance, and simplifying analytics across distributed environments.
Key Features:
- Scalability: Easily scales to thousands of nodes and petabytes of data.
- Fault Tolerance: Automatic block replication and re-replication on failure.
- High Throughput: Optimized for batch processing of large files, not low-latency transactions.
- Data Locality: Computation is moved to where the data resides, reducing network overhead.
- Write-Once, Read-Many Model: Simplifies consistency, ideal for log data and analytics.
- Replication Factor: Adjustable per file for critical or temporary data.
- Rack Awareness: Distributes replicas across different racks to avoid data loss from hardware failure.
- Integration with Hadoop Ecosystem: Works seamlessly with MapReduce, Hive, Pig, Spark, and HBase.
These features make HDFS the de facto standard for big data storage in many organizations.
Use Cases and Applications of HDFS
HDFS is a cornerstone of big data infrastructure, enabling diverse use cases from batch processing to long-term archival. But when speed and responsiveness are critical, Real-Time Analytics and Apache Spark’s capabilities take center stage empowering systems to process streaming data instantly, detect anomalies, and deliver actionable insights with minimal latency.
Popular Use Cases:
- Data Lakes: Central storage for structured, semi-structured, and unstructured data.
- Batch Processing: Supports tools like Hadoop MapReduce, Spark, and Hive for analytics.
- ETL Pipelines: Ingest, transform, and store massive datasets efficiently.
- Log and Event Storage: Stores logs from servers, applications, and sensors.
- Machine Learning: Acts as a data source for model training in distributed ML environments.
- Archiving: Economical long-term storage with compression and redundancy.
Industry Applications:
- Retail: Customer behavior analysis, fraud detection, inventory forecasting.
- Finance: Risk modeling, real-time trade analysis.
- Healthcare: Patient record analysis, genome sequencing.
- Telecommunications: Network traffic monitoring, call data record storage.
- Government: Public data management, census data analytics.
Organizations like Facebook, Yahoo, and Spotify rely on HDFS to manage massive datasets daily.
Conclusion
Apache HDFS (Hadoop Distributed File System) remains the foundation of the Hadoop ecosystem, enabling scalable, fault-tolerant, and distributed storage for massive volumes of data. As organizations continue to embrace data-driven strategies, the need for systems like HDFS is stronger than ever. Its design principles data locality, redundancy, horizontal scaling, and simplicity make it ideal for storing and processing big data workloads. To harness these capabilities effectively, professionals turn to specialized Data Science Training, which equips them to architect resilient data infrastructures and optimize performance across distributed environments. While newer file systems and cloud-native storage solutions have emerged, HDFS continues to evolve and stay relevant, especially in on-premise big data environments or hybrid cloud architectures. Whether you’re building a recommendation engine, analyzing billions of log entries, or managing a data lake, HDFS offers the reliability and performance required to handle data at scale.




