
Last updated on 09th Oct 2025| 10224
- Real-Time Stream Processing in Big Data
- Overview of Apache Kafka
- Overview of Apache Storm
- JSON Data Structure and Format
- Setting Up Kafka Producer for JSON
- Kafka Consumer Integration with Storm
- Creating Spouts and Bolts in Storm
- Parsing and Processing JSON in Storm
- Error Handling and Real-Time Data Pipeline
- Final Thoughts and Best Practices
Real-Time Stream Processing in Big Data
Stream Processing in Big Data has become a cornerstone of modern analytics, enabling organizations to make decisions in real time rather than waiting for traditional batch results. Whether it’s tracking user activity on a website, monitoring financial transactions for fraud, or ingesting telemetry data from IoT devices, processing data in real time allows for faster insights and quicker actions. To build the skills required for designing and deploying such intelligent systems, visit Data Science Training a hands-on program that equips learners with the tools, techniques, and mindset to thrive in real-time analytics and decision-making environments. Traditional batch-processing methods are insufficient for such requirements, leading to the rise of streaming platforms like Apache Kafka and Apache Storm. Real-time data streaming is the practice of continuously transmitting and processing data as it is generated. It contrasts with batch processing, where data is collected, stored, and processed later in chunks. Real-time processing offers significant advantages for applications that need instant insights, such as financial markets, healthcare monitoring, and smart city infrastructure. Stream Processing in Big Data will continue to drive innovation, efficiency, and smarter decision-making across industries.
Overview of Apache Kafka
Apache Kafka is a distributed messaging system designed for high-throughput and fault-tolerant data pipelines. It acts as a buffer between data producers and consumers, enabling asynchronous communication. Kafka is built around the concept of topics to which producers publish messages and from which consumers read messages. To understand how Kafka fits into the broader Big Data ecosystem, visit Skills Needed to Learn Hadoop a comprehensive guide that outlines the technical foundations, ecosystem tools, and practical competencies required to master Hadoop-based architectures.
- Producer: Sends messages (data) to Kafka topics.
- Broker: Stores and forwards messages.
- Consumer: Subscribes to topics and processes messages.
- ZooKeeper: Coordinates the Kafka cluster.
Kafka is ideal for decoupling data producers and consumers, scaling horizontally, and ensuring message durability through replication.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Overview of Apache Storm
Apache Storm is a distributed real-time computation system. Unlike Kafka, which handles messaging, Storm processes streaming data in a continuous fashion. Storm applications are called topologies, and they consist of spouts and bolts. To explore how these components fit into scalable architecture design, visit Become a Big Data Hadoop Architect a strategic guide that outlines the skills, tools, and architectural principles required to lead complex Big Data projects.
- Spout: Reads data from external sources (e.g., Kafka) and emits it into the Storm topology.
- Bolt: Receives data from spouts or other bolts, performs processing (e.g., filtering, parsing), and emits results.
Storm guarantees data processing through at-least-once semantics, and it can scale horizontally to handle large streams of data.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
JSON Data Structure and Format
JSON (JavaScript Object Notation) is a lightweight, human-readable data format commonly used for transmitting data between systems. It supports complex nested structures with key-value pairs, making it ideal for APIs, configuration files, and real-time data exchange. To learn how formats like JSON are applied in analytics workflows, visit Data Science Training a hands-on course that equips learners with the tools and techniques to manage, analyze, and visualize structured and semi-structured data effectively.
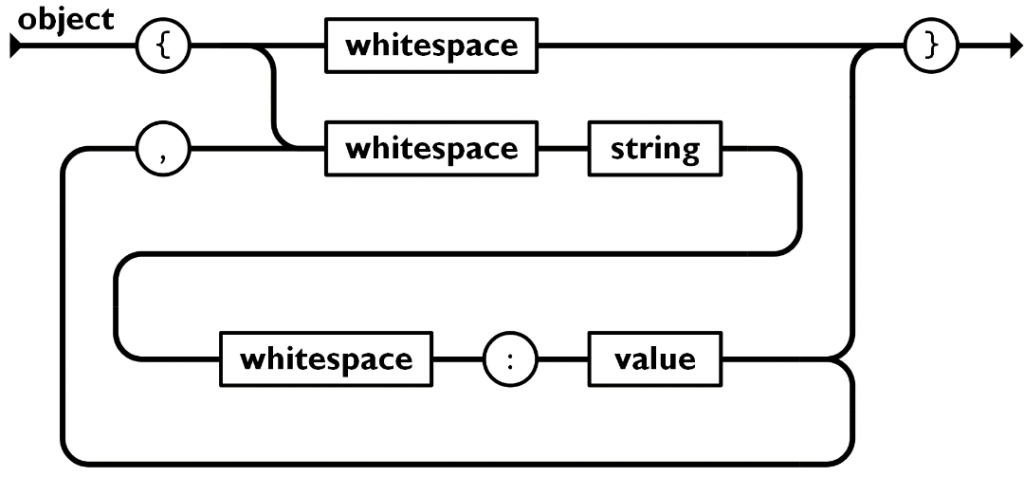
Example JSON message:
- {
- “userId”: 12345,
- “event”: “purchase”,
- “timestamp”: “2025-07-10T10:45:00Z”,
- “amount”: 299.99,
- “location”: {
- “city”: “Chennai”,
- “country”: “India”
- }
- }
This data can be serialized and sent over Kafka topics for real-time analysis.

Setting Up Kafka Producer for JSON
Kafka producers publish JSON messages to a specific topic. Below is a Python example using the kafka-python library, which demonstrates how data flows into distributed systems. To understand how this data can be queried and analyzed efficiently, visit What is Hive an introductory article that explains Hive’s role in simplifying SQL-like queries on large datasets stored in Hadoop.
- from kafka import KafkaProducer
- import json
- producer = KafkaProducer(
- bootstrap_servers=[‘localhost:9092’],
- value_serializer=lambda v: json.dumps(v).encode(‘utf-8’)
- )
- message = {
- “userId”: 1,
- “event”: “login”,
- “timestamp”: “2025-07-10T10:00:00Z”
- }
- producer.send(‘user-events’, value=message)
- producer.flush()
Ensure Kafka is running and the topic user-events exists before sending messages.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Kafka Consumer Integration with Storm
To integrate Kafka with Storm, use the KafkaSpout, which consumes messages from Kafka and emits them into the Storm topology. You must configure the Kafka broker, topic, and deserialization logic to ensure smooth data flow. To understand how these streaming components complement batch processing frameworks, visit What Is MapReduce & Why It Is Important a foundational article that explains the role of MapReduce in scalable data processing and its relevance in today’s hybrid architectures.
- KafkaSpoutConfig<String, String> spoutConfig = KafkaSpoutConfig.builder(“localhost:9092”, “user-events”)
- .setProp(ConsumerConfig.GROUP_ID_CONFIG, “storm-consumer”)
- .build();
- KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(spoutConfig);
This spout can then be used as the data source in your Storm topology.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Creating Spouts and Bolts in Storm
Define spouts to read messages and bolts to parse and process JSON. Here’s an example bolt that parses JSON strings and extracts key-value pairs for downstream processing. To understand how these components contribute to real-time analytics pipelines, visit What is Big Data Analytics an introductory article that explains the principles, tools, and applications driving insights from massive data streams.
- public class JSONParserBolt extends BaseBasicBolt {
- public void execute(Tuple input, BasicOutputCollector collector) {
- String jsonString = input.getString(0);
- try {
- JSONObject json = new JSONObject(jsonString);
- collector.emit(new Values(json.getInt(“userId”), json.getString(“event”)));
- } catch (JSONException e) {
- e.printStackTrace();
- }
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields(“userId”, “event”));
- }
- }
The bolt emits processed data to the next component for further analysis.
Parsing and Processing JSON in Storm
Once the JSON is parsed, the data can be enriched, filtered, aggregated, or stored in databases. A common use case is filtering events or performing real-time analytics based on user behavior.
Example: Count login events per user in real time.
- public class EventCounterBolt extends BaseBasicBolt {
- Map<Integer, Integer> counts = new HashMap<>();
- public void execute(Tuple input, BasicOutputCollector collector) {
- int userId = input.getIntegerByField(“userId”);
- counts.put(userId, counts.getOrDefault(userId, 0) + 1);
- System.out.println(“User ” + userId + ” event count: ” + counts.get(userId));
- }
- public void declareOutputFields(OutputFieldsDeclarer declarer) {}
- }
Error Handling and Real-Time Data Pipeline
Real-time systems must handle data inconsistencies, malformed JSON, and transient network failures gracefully. Use try-catch blocks, logging frameworks like Log4j, and implement retry logic where needed to ensure resilience. To set up the foundational environment for these systems, visit How to install Apache Spark a step-by-step guide that walks you through Spark installation, configuration, and readiness for real-time data processing.
Best practices include:
- Validating JSON schema before processing.
- Logging failed messages for future reprocessing.
- Using monitoring tools to observe message lag and throughput.
- E-commerce: Track cart abandonment, clicks, and purchases in real time.
- Finance: Monitor high-frequency transactions and detect anomalies.
- IoT: Process sensor data from smart devices for predictive maintenance.
- Healthcare: Stream patient data for immediate diagnosis alerts.
These pipelines enable timely interventions and automated decision-making.
Final Thoughts
Stream Processing in Big Data plays a crucial role in helping organizations manage and act on continuous flows of information. Implementing a real-time JSON processing pipeline using Kafka and Storm helps organizations turn data into actionable insights quickly and reliably. By keeping a modular and fault-tolerant structure, businesses can build smarter applications that handle large data streams easily. A successful approach includes strong monitoring for latency and possible failures, careful tracking of data lineage, and strict security measures like TLS and authentication. To master the skills behind these resilient architectures, visit Data Science Training a practical course that equips professionals with the tools, techniques, and mindset needed to thrive in today’s data-driven environments. As data-driven strategies become more important, these streaming technologies provide a solid base for modern solutions. Apache Kafka and Apache Storm together give developers and architects a flexible and scalable framework for processing complex JSON data in various industries. This enables new ideas in big data analytics, event-driven microservices, and IoT applications. By mastering these technologies, organizations can create new chances for real-time decision-making and improved operational efficiency. Stream Processing in Big Data continues to redefine how enterprises approach real-time analytics, driving faster decisions, innovation, and operational efficiency across sectors.




