
Last updated on 04th Oct 2025| 9833
- Introduction: Why Hadoop Still Matters
- Understanding the Hadoop Ecosystem
- Key Skills Required for Hadoop Developers
- Top Interview Topics and Questions
- Mastering Hadoop Architecture
- Hands-On Projects and Portfolio Building
- Behavioral and Scenario-Based Questions
- Certifications That Strengthen Your Profile
- Conclusion: Final Tips to Ace the Interview
Introduction: Why Hadoop Still Matters
Hadoop Developer Interviews remain highly relevant even with the rise of newer data technologies like Apache Spark, Flink, and cloud-native services, because Hadoop is still a foundational technology in the Big Data space. It continues to power large-scale distributed data processing and storage systems, especially in legacy enterprise systems, banking, telecom, and government analytics. Advancing through Data Science Training equips professionals to modernize these infrastructures leveraging predictive analytics, scalable models, and real-time insights to transform traditional systems into agile, data-driven platforms. For job seekers, Hadoop Developer roles offer lucrative opportunities with competitive salaries, stable career growth, and real-world impact. Preparing well for Hadoop Developer Interviews ensures candidates can showcase their technical expertise, problem-solving abilities, and understanding of distributed systems. This guide is crafted to help you systematically prepare for Hadoop Developer Interviews and successfully land your desired role.
Understanding the Hadoop Ecosystem
A Hadoop Developer is the key person who handles and processes big data through a complex Hadoop ecosystem. The main framework for this system is made from the most fundamental components such as HDFS which is a distributed storage system, MapReduce which is a computational processing program, and YARN which is the resource manager for the cluster. Apart from these basic features, developers still have to deal with a variety of tools that are more specialized for different purposes like Hive which allows querying that is similar to SQL, Pig which is for data flow and ETL processes, HBase that is a NoSQL database, and some supporting technologies have been introduced for data integration and workflow management such as Sqoop, Flume, and Oozie. Understanding What Is MapReduce & Why It Is Important helps developers grasp the foundational processing model behind these tools enabling efficient data handling, parallel execution, and scalable analytics across distributed systems. Hadoop has evolved to a level that is close to reality and cloud technologies are part of it, these technologies are such as Spark, Kafka, and cloud platforms like AWS EMR and GCP Dataproc.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Key Skills Required for Hadoop Developers
To stand out in an interview, you need to demonstrate a blend of programming knowledge, big data tool proficiency, and architectural understanding. A clear grasp of What is Hive can significantly boost your credibility showcasing your ability to query large datasets using SQL-like syntax and integrate seamlessly with Hadoop-based data warehouses.
Core Technical Skills:
- Java or Python for MapReduce programming
- Strong knowledge of HDFS commands and operations
- Data ingestion using Flume, Sqoop, or Kafka
- Writing and optimizing HiveQL queries
- Scheduling workflows using Oozie
- Working knowledge of Shell scripting
Optional but Valued Skills:
- Spark for faster distributed computation
- AWS/Azure/GCP familiarity
- Data modeling with HBase
- Performance tuning and troubleshooting Hadoop clusters
Employers also value soft skills like communication, problem-solving, and the ability to understand business use cases.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Top Interview Topics and Questions
Hadoop interviews typically test both conceptual knowledge and hands-on skills. Here are some commonly asked topics and sample questions: HDFS architecture, MapReduce logic, Hive and Pig scripting, and cluster performance tuning. Staying updated with Top Influencers in Big Data & Analytics can sharpen your perspective offering insights into emerging trends, expert strategies, and real-world applications that interviewers value.
HDFS:
- What is block size in HDFS and how does it impact performance?
- How is fault tolerance achieved in HDFS?
- Explain replication in HDFS.
MapReduce:
- How does a MapReduce job execute internally?
- Differences between Mapper, Reducer, and Combiner?
- How to handle skewed data in MapReduce?
Hive:
- How is Hive different from RDBMS?
- What are partitions and buckets in Hive?
- How do you optimize Hive queries?
Pig:
- When would you use Pig over Hive?
- Explain the role of UDFs in Pig.
Sqoop & Flume:
- How do you transfer data from MySQL to HDFS using Sqoop?
- How does Flume ensure reliability in event collection?
YARN:
- What is the role of ResourceManager and NodeManager?
- How does YARN differ from classic MapReduce?
Prepare for short answers, diagram-based explanations, and even code snippets during technical rounds.

Mastering Hadoop Architecture
Data professionals skills in a Hadoop cluster are the very fabric of their success in the big data technology field which is very competitive. A typical candidate’s knowledge of the Hadoop architecture is what the interviewers are looking for. NameNode and DataNode are the two main things that the roles of the core components of the basic infrastructure are. Besides these main components, roles, candidates should also know well enough the functions of a secondary NameNode, how blocks of data are placed and what the principles of rack awareness are.
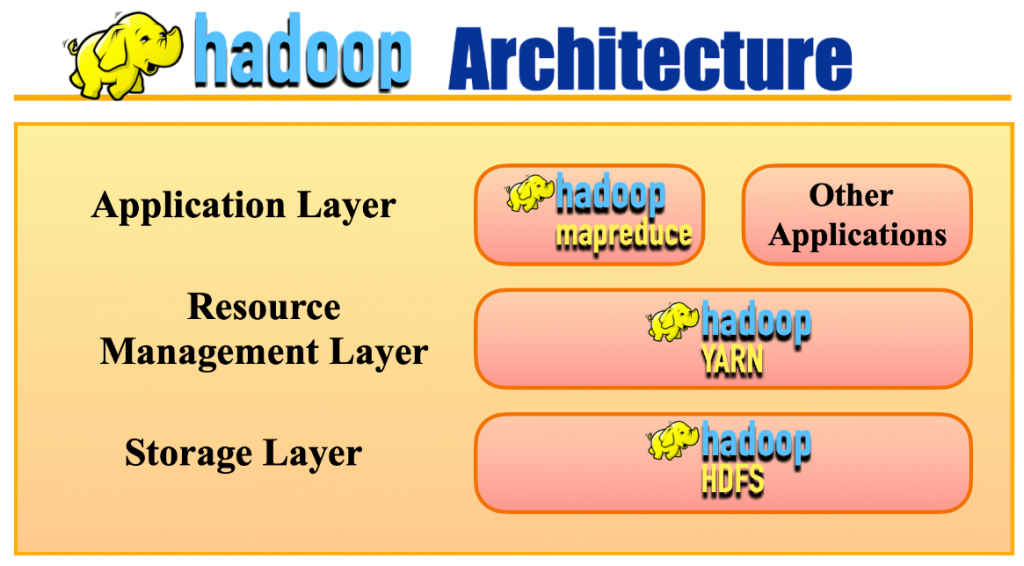
Strengthening these fundamentals through Data Science Training ensures a deeper grasp of Hadoop architecture bridging theoretical concepts with practical deployment strategies in distributed environments. One cannot be considered technically proficient without knowing the MapReduce job lifecycle from InputSplit through Mapper, Combiner, Partitioner to Reducer and Resource Management in YARN. Not only do the candidates’ technical depths get proven but also their skills of efficiently handling complex distributed computing environments are thereby recognized through the achievement of the mastery of the above intricate and interrelated systems.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Hands-On Projects and Portfolio Building
One will find out that in the market where data engineering is involved, it will be apparent that theory on its own will not be enough. Having mostly theoretical knowledge, data engineers find themselves stuck when confronted with a typical business problem. So for one to be successful, practical experience is the key. Consequently, those who want to be data engineers should not limit themselves to just the content of the books. Instead, they should create and have a portfolio impressive enough to show off their real-world skills. Building such a portfolio is a critical step toward becoming a Big Data Hadoop Architect a role that demands hands-on expertise in distributed systems, data pipeline design, and scalable architecture implementation. For example, a Log Analysis Pipeline work with the use of Flume and HDFS, an ETL operation done by Sqoop and Hive, or the integration of Kafka with Spark Streaming for Real-Time Analytics are some of the projects that one can create to raise the level of his professional profile significantly. What is more, these projects should be fully documented and the documentation should be published on writing repository services such as GitHub.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Behavioral and Scenario-Based Questions
Besides tech questions, interviews often include behavioral rounds and real-world scenarios to test how you solve problems. Understanding How to Become a Big Data Analyst equips you with both technical depth and strategic thinking helping you navigate complex datasets, communicate insights effectively, and respond confidently under pressure.
Sample Behavioral Questions:
- Tell us about a time when your MapReduce job failed. How did you debug it?
- How do you prioritize tasks in a data pipeline with multiple dependencies?
- Describe a time when you optimized a Hive query. What impact did it have?
To prepare:
- Practice STAR (Situation, Task, Action, Result) method.
- Relate answers to real projects or assignments.
- Show decision-making skills and ownership.
Certifications That Strengthen Your Profile
Certifications aren’t mandatory, but they add credibility and confidence especially if you’re from a non-computer science background. Exploring How Big Data Can Help You Do Wonders reveals how data-driven strategies can amplify your impact, regardless of your academic origin turning insights into innovation across industries.
Recommended Certifications:
- Cloudera Certified Associate (CCA) Spark and Hadoop Developer
- Hortonworks (now Cloudera) HDP Developer Certification
- Big Data Engineering Certificate – Coursera/edX/Udacity
- AWS Big Data Specialty (for cloud-based Hadoop clusters)
These certifications validate your skillset and make your resume more appealing to employers and recruiters.
Conclusion: Final Tips to Ace the Interview
Hadoop Developer Interviews are not just about memorizing concepts; they are about proving your ability to build, debug, and scale big data applications in real-world scenarios. To succeed, it’s important to learn how things work, not just what they do, and to practice problem-solving with Hadoop clusters or sandbox tools. Showing genuine interest in real-world applications, explaining your thought process clearly, and confidently diagramming Hadoop Architectures on the fly can make a big difference. Most importantly, always support your answers with examples or past experiences, as this demonstrates practical knowledge. Completing Data Science Training sharpens these abilities helping you articulate complex concepts, showcase hands-on expertise, and stand out in high-stakes technical interviews. With the right preparation strategy and mindset, candidates can walk into Hadoop Developer Interviews with confidence and truly stand out from the competition. Ultimately, mastering these skills ensures long-term success in Hadoop Developer Interviews and beyond.




