
Last updated on 08th Oct 2025| 10767
- Introduction to Hadoop
- History and Evolution
- Components of Hadoop Ecosystem
- HDFS Overview
- MapReduce Overview
- YARN and Resource Management
- Common Hadoop Tools (Hive, Pig, etc.)
- Hadoop Distributions
- Conclusion
Introduction to Hadoop
Hadoop is an open-source framework designed for distributed storage and processing of vast amounts of data. It enables organizations to process big data sets using clusters of computers with simple programming models. Hadoop is known for its scalability, fault tolerance, and ability to handle unstructured and semi-structured data. It originated from efforts to support distributed computing models inspired by Google’s File System (GFS) and MapReduce frameworks. Hadoop is an open-source framework designed to store and process massive datasets across clusters of commodity hardware Data Science Training. It addresses the challenges of big data by distributing storage with its Hadoop Distributed File System (HDFS) and enabling parallel processing through the MapReduce programming model. Hadoop’s scalable architecture allows organizations to handle vast amounts of structured and unstructured data efficiently. Over time, the Hadoop ecosystem has expanded to include tools like YARN for resource management and Apache Spark for faster in-memory processing. Today, Hadoop remains a cornerstone technology for big data analytics, powering applications in industries ranging from finance to healthcare.
History and Evolution
The origins of Hadoop trace back to the early 2000s. Doug Cutting and Mike Cafarella created Hadoop as part of the Apache Nutch project. Named after Cutting’s son’s toy elephant, Hadoop quickly evolved when Yahoo hired Cutting to help scale their web search infrastructure. Hadoop became a top-level Apache project in 2008. Since then, its ecosystem has grown to support a wide variety of applications beyond search indexing, including financial analytics, fraud detection, Apache Hive vs HBase Guide recommendation engines, and more. Major contributors such as Cloudera, Hortonworks, and MapR helped shape its commercial adoption. Hadoop originated in 2005, inspired by Google’sMapReduce frameworks and Google File System papers. Developed by Doug Cutting and Mike Cafarella, it evolved from a simple framework into a robust ecosystem. Over time, Hadoop expanded with tools like YARN and Spark,Components of Hadoop becoming a foundational platform for big data processing worldwide.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
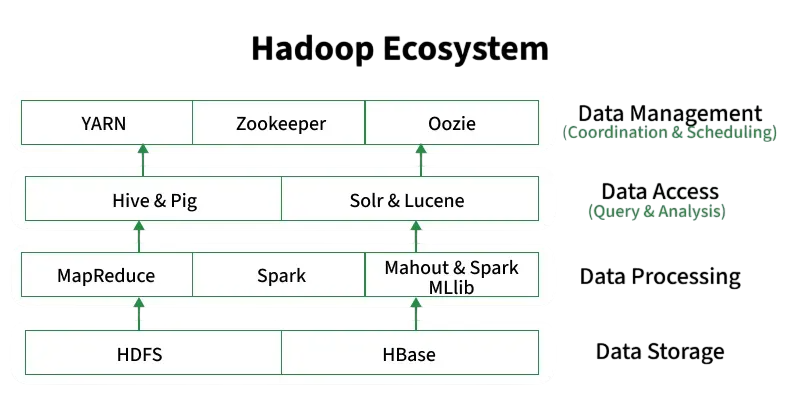
Components of Hadoop Ecosystem
The Hadoop ecosystem includes several integral components:
- HDFS (Hadoop Distributed File System): A storage system that splits large data files into blocks and distributes them across nodes in a cluster.
- MapReduce: A processing engine that performs distributed data computation in parallel using two phases – Map and Reduce An ETL Audit Process .
- YARN (Yet Another Resource Negotiator): Handles resource management and job scheduling.
- Hive: Provides SQL-like querying capabilities on large datasets.
- Pig: Offers a high-level scripting language for data transformation.
- HBase: A NoSQL database that supports real-time read/write access.
- Sqoop: Used for transferring data between Hadoop and relational databases.
- Flume: Collects, aggregates, and moves large amounts of log data.
- Oozie: Workflow scheduler for managing Hadoop jobs.
- HDFS (Hadoop Distributed File System) is Hadoop’s primary storage system.
- Designed to store very large files across multiple machines.
- Uses data replication (typically three copies) to ensure fault tolerance and reliability.
- Splits files into blocks (default 128MB or 256MB) BFSI Sector Big Data Insights distributed across cluster nodes.
- Provides high throughput access for large-scale data processing.
- Built to run on commodity hardware with built-in failure recovery.
- Uses a NameNode to manage metadata and DataNodes to store actual data.
- ResourceManager (RM): Allocates resources across applications.
- NodeManager (NM): Monitors resources on each node.
- ApplicationMaster (AM): Manages the execution of individual applications.
- Hive: Enables SQL-like querying on Hadoop data through HiveQL. Ideal for analysts familiar with SQL.
- Pig: Uses Pig Latin scripting language for data transformation. Suited for researchers and developers Elasticsearch Nested Mapping .
- HBase: Column-family NoSQL database for real-time querying.
- Sqoop: Imports/export data between Hadoop and traditional databases like MySQL.
- Flume: Ingests log data from multiple sources.
- Oozie: Manages complex job workflows.
- Zookeeper: Centralized service for maintaining configuration and synchronization.
- Cloudera: Includes CDP (Cloudera Data Platform), formerly Cloudera + Hortonworks.
- MapR: Offered advanced features like real-time streaming and POSIX file system support.
- Amazon EMR: A cloud-based Hadoop distribution on AWS What is Azure Data Lake .
- Google Dataproc: Managed Hadoop/Spark cluster service.

To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
HDFS Overview

YARN and Resource Management
YARN separates the job scheduling and resource management functions Data Science Training from the MapReduce engine. It introduces:
YARN allows multiple data processing engines (e.g., MapReduce, Spark, Tez) to run concurrently, improving cluster utilization and performance.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Common Hadoop Tools (Hive, Pig, etc.)
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Hadoop Distributions
Several organizations offer commercial Hadoop distributions:
These distributions often bundle additional management tools, security, and support for enterprise deployment.
Conclusion
Hadoop remains a cornerstone of Big Data technology. From humble beginnings as part of an academic project to being a foundation for enterprise-grade analytics, Hadoop has revolutionized how we store and process data. Despite emerging alternatives, it continues to thrive due to its ecosystem Data Science Training , MapReduce frameworks, community, and adaptability. Whether you’re a data engineer, analyst, or architect, understanding Hadoop is crucial for navigating the Big Data landscape. The more proficient you are with its tools and concepts, Hadoop Tools the more value you can bring to modern data-driven enterprises.




