
Last updated on 08th Oct 2025| 10178
- Introduction to Solr and Hadoop
- The Need for Big Data Search
- Solr Architecture Overview
- Hadoop Overview and Ecosystem
- Integrating Solr with Hadoop
- Indexing Big Data with Solr
- Real-Time Search Use Cases
- Data Pipelines with Solr and Hadoop
- Performance Considerations
- Final Thoughts
Introduction to Solr and Hadoop
In the era of massive data generation, efficient storage and retrieval systems have become paramount. Apache Solr and Hadoop are two widely adopted technologies that serve different yet complementary purposes in the Big Data ecosystem. Solr is an open-source search platform built on Apache Lucene, designed for indexing and querying large volumes of text-centric data. To gain the skills needed to integrate such search technologies into modern analytics workflows, explore Data Science Training a hands-on program that empowers professionals to combine scalable search, intelligent querying, and predictive modeling across diverse data environments. Hadoop, on the other hand, is an open-source framework that facilitates distributed storage and processing of large data sets using commodity hardware. Combining Solr and Hadoop creates a powerful solution for storing, processing, indexing, and searching Big Data. This integration offers real-time insights, scalable architecture, and high-speed data querying, making it ideal for data-intensive applications.
The Need for Big Data Search
Organizations today collect vast amounts of structured and unstructured data from various sources like social media, sensors, logs, and customer interactions. Extracting meaningful insights from such massive data volumes requires more than just storage and processing, it requires robust search capabilities. Traditional databases often fall short in delivering fast and scalable search results over massive datasets. To explore modern solutions built for speed and distributed querying, visit Hive vs Impala a comparative article that breaks down execution models, latency differences, and ideal use cases for big data environments. Solr addresses this limitation by offering full-text search, faceting, highlighting, real-time indexing, and distributed search capabilities. When combined with Hadoop’s scalable storage and data processing features, it allows enterprises to index and search Big Data efficiently.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Solr Architecture Overview
Solr’s architecture is designed for scalability and performance. The key components include distributed indexing, fault-tolerant search capabilities, and real-time analytics integration. To understand how such technologies address enterprise pain points, visit Big Data Challenges With Solutions a practical article that explores common bottlenecks in data systems and offers proven strategies for overcoming them.
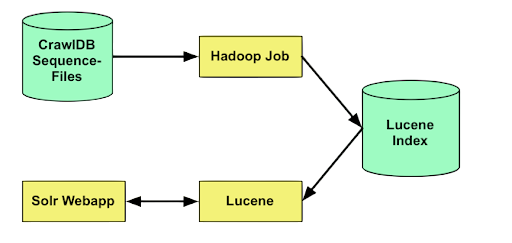
- Solr Core: A single index with its own configuration and schema.
- Indexing: Adds documents to the Solr index.
- Query Processing: Retrieves documents matching specific queries.
- Faceting: Breaks down search results by categories.
- Sharding and Replication: Supports distributed indexing and searching.
- SolrCloud: Provides fault tolerance, distributed indexing, and load balancing.
Solr works best with semi-structured and textual data and provides REST-like HTTP APIs for communication.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Hadoop Overview and Ecosystem
Hadoop provides a platform for processing Big Data using distributed computing. The Hadoop ecosystem includes tools for storage, resource management, and parallel processing. To compare two of its most powerful engines, visit Spark vs MapReduce a detailed article that examines execution speed, fault tolerance, and suitability for real-time versus batch workloads.
- HDFS (Hadoop Distributed File System): Stores data across multiple machines.
- MapReduce: Processes large datasets in parallel.
- YARN (Yet Another Resource Negotiator): Manages resources and job scheduling.
- Hive: Data warehousing and SQL querying.
- Pig: High-level platform for creating MapReduce programs.
- HBase: NoSQL database on top of HDFS.
- Flume and Sqoop: Data ingestion tools.
Hadoop is particularly useful for batch processing of vast data sets, storing unstructured data, and handling diverse data formats.

Integrating Solr with Hadoop
The combination of the Hadoop ecosystem and the Solr search platform creates a strong framework for accessing and querying large amounts of data in HDFS. By using various methods, such as Apache Solr with MapReduce, the Apache Kite SDK’s Morphlines, Apache Nutch, and dedicated connectors like the Lily Indexer or Cloudera Search, organizations can effectively process, reshape, and index complex datasets. This effective mix allows for quick indexing, great scalability, and distributed information retrieval across large data structures. To master these technologies and apply them in real-world data workflows, explore Data Science Training a hands-on program that equips professionals to build intelligent pipelines, optimize search frameworks, and scale analytics across enterprise systems. As a result, businesses can turn raw data into strategic, searchable assets. This gives decision-makers clear and consistent information, no matter the technological setup.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Indexing Big Data with Solr
To make Big Data with Solr searchable and useful for analysis, raw information must go through several transformation stages. It all starts with data purification. This step is crucial for removing errors, duplicates, and empty fields, making sure the information is trustworthy. Next, the data is structured by mapping its fields to a Solr schema. This organization helps with quick and accurate lookups.
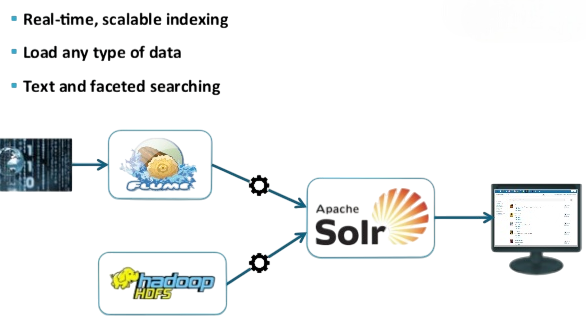
Organizations have flexible options for this process. To understand the infrastructure that supports such scalable data operations, visit What Is a Hadoop Cluster a detailed article that explains how distributed nodes work together to store, process, and manage massive datasets efficiently. They can upload large datasets at once using batch indexing or capture live information instantly with real-time indexing tools like Kafka. Continuous performance tracking is important to keep the system running smoothly as the index grows.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Real-Time Search Use Cases
Organizations use Solr-Hadoop integration in various real-time applications: from log indexing and anomaly detection to predictive maintenance and customer behavior modeling. To understand how data deduplication enhances these workflows, visit Dedup : Splunk Documentation a technical guide that explains how Splunk’s dedup command filters duplicate events, streamlines search results, and improves query performance.
- E-commerce: Product recommendations, real-time inventory search, and price comparison.
- Log Analytics: Real-time monitoring of server logs and error detection.
- Social Media Analysis: Indexing tweets and posts for sentiment analysis.
- Fraud Detection: Monitoring transactional data for anomalies.
- Healthcare: Searching patient records and medical literature.
Such use cases demand real-time indexing, scalability, and precision in results.
Data Pipelines with Solr + Hadoop
Crafting a high-performance data workflow involves a careful process made up of a series of distinct, important steps. The first step is data acquisition, where strong solutions like Kafka and Flume are used to efficiently collect and direct information streams. Once gathered, this data is stored in HDFS, creating a strong and expandable base for storage. Next, an important processing layer uses technologies like Spark, Hive, and MapReduce to clean, structure, and transform raw inputs into useful information. To understand how these stages connect in a seamless workflow, visit What is Data Pipelining a comprehensive article that explains the architecture, orchestration, and optimization strategies behind modern data pipelines. After this refinement, the structured data is organized in Solr, which makes it easy to query and access data through user-friendly APIs and front-end applications. One key aspect of this setup is its operational flexibility.
Performance Considerations
To ensure optimal performance: teams often rely on precise field extraction and pattern matching to streamline search queries and reduce noise. For a deeper look into one of the most powerful tools for this task, visit What is Splunk Rex a focused article that explains how the Rex command uses regular expressions to extract fields, transform data, and refine search results in Splunk.
- Tune JVM and GC: Manage Java memory and garbage collection.
- Optimize Indexing Strategy: Use field-level tuning and avoid unnecessary fields.
- Use Replication and Sharding: Spread data for horizontal scaling.
- Enable Caching: Result set, filter, and document caching.
- Monitor with Tools: Use Ganglia, Prometheus, or Solr Admin UI for metrics.
Balancing indexing speed with query performance is critical.
Final Thoughts
The synergy between Apache Solr and Hadoop provides a compelling solution for organizations dealing with massive datasets. While Hadoop excels in storage and batch processing, Solr brings in the power of search and real-time insights. This combination offers not just performance and scalability, but also adaptability to different use cases across industries. To gain hands-on expertise in leveraging these technologies, explore Data Science Training a practical program that equips professionals to build scalable pipelines, integrate search frameworks, and drive intelligent analytics across domains. As data continues to grow, leveraging the strengths of both Solr and Hadoop can help businesses stay ahead in their analytics and decision-making capabilities. Whether you’re setting up a data-driven e-commerce platform or analyzing social media trends, Solr and Hadoop together offer the tools you need to harness the power of Big Data.




