
Last updated on 06th Nov 2025| 10773
- Overview of Hadoop Ecosystem
- Hadoop Developer Responsibilities
- Hadoop Components (HDFS, MapReduce, etc.)
- Required Programming Languages
- Working with Big Data Tools
- Data Pipeline Creation
- Debugging and Performance Tuning
- Soft Skills and Team Collaboration
- Experience and Learning Path
- Summary
Overview of Hadoop Ecosystem
The Hadoop ecosystem is a suite of open-source software frameworks that facilitate the processing of large data sets in a distributed computing environment. Built by the Apache Software Foundation, Hadoop consists of several interconnected modules that allow data to be stored, processed, analyzed, and managed efficiently across multiple nodes. In Data Science Training ElasticSearch acts as a powerful search and analytics engine that indexes Hadoop data efficiently.Supporting tools such as Hive, Pig, HBase, Sqoop, Flume, Oozie, and others extend its capabilities, making Hadoop an essential platform for managing Big Data workloads. These components work in synergy to provide fault tolerance, scalability, and cost-effectiveness, thus transforming the way data is handled in enterprises. Hadoop is widely used in industries such as retail, finance, healthcare, telecommunications, and social media to analyze customer behavior, detect fraud, and perform trend forecasting.
Hadoop Developer Responsibilities
Hadoop Developer Responsibilities play an essential role in the field of big data by developing, implementing, and improving applications within the Hadoop ecosystem. They write and refine MapReduce programs to process large amounts of data efficiently.
- They also use tools like Pig, Hive, and Spark to create scripts and workflows that transform datasets effectively.
- Another important duty is loading data into Hadoop clusters, often using Sqoop and Flume to extract information from relational databases and log systems.
- Ensuring that Hadoop-based systems are available, reliable, and secure is a key part of their job, especially when integrating with Tableau Software for data visualization and reporting.
Hadoop Developer Responsibilities also connect the system with real-time processing tools such as Apache Kafka and Apache Storm. They clean and transform data to prepare it for analysis and manage data workflows using tools like Oozie or Apache Airflow. By creating scalable and reusable code libraries for data processing pipelines, they help other teams, such as data scientists and analysts, access well-organized and clean datasets. This supports a solid data structure and analytics efforts.
Hadoop Components (HDFS, MapReduce, etc.)
The ecosystem of Hadoop is based on a number of essential elements that provide effective data processing and storage. Large datasets are stored across several machines using HDFS (Hadoop Distributed File System), which divides them into blocks and distributes them for fault tolerance and dependability. By dividing data into chunks, processing each one separately, then combining the results, Tableau Desktop Certification enables parallel data processing. YARN, or Yet Another Resource Negotiator, effectively schedules jobs and controls the cluster’s computing resources.
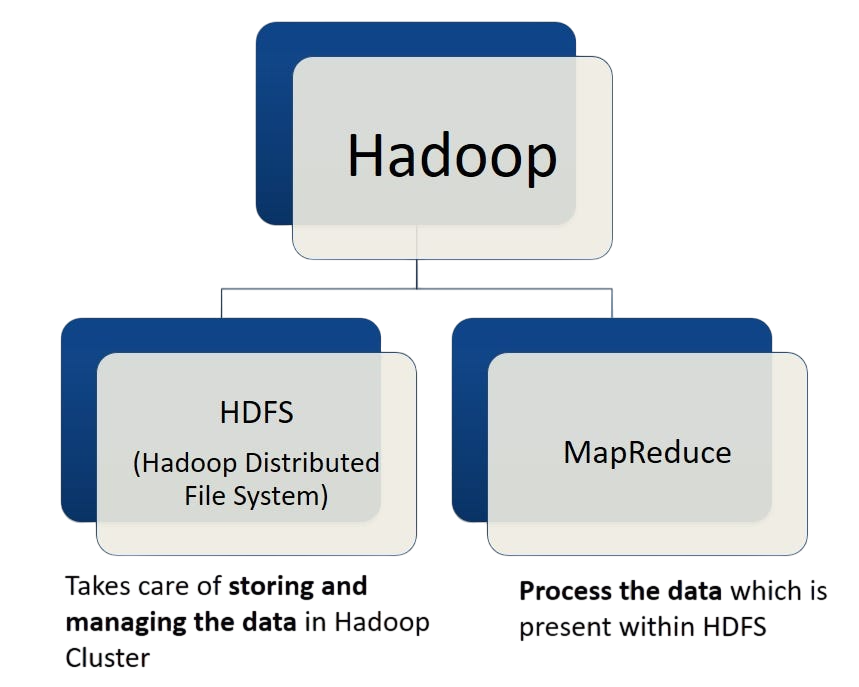
Users accustomed to relational databases can query Hadoop data using Hive’s SQL-like interface. Pig uses a scripting language called Pig Latin to make data analysis easier. For random, real-time read/write operations, HBase, a NoSQL database based on HDFS, is perfect, while Apache Storm handles real-time stream processing efficiently. Flume gathers and aggregates log data into Hadoop, whereas Sqoop moves data between relational databases and Hadoop. Lastly, Oozie is a workflow scheduler that ensures seamless operation across data pipelines by automating the execution of Hadoop activities in a distributed context. Together, these elements enable effective Big Data management and processing.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Required Programming Languages
Hadoop development demands proficiency in multiple programming languages:
- Java: The default and most extensively used language for writing Hadoop MapReduce programs.
- Python: Popular for scripting and used with PySpark in data processing and machine learning.
- Scala: Used in conjunction with Apache Spark for functional programming features, especially when exploring concepts in BI vs Data Science .
- SQL: Required for querying data using Hive, Impala, or Spark SQL.
- Shell Scripting: Helpful in managing automation scripts for data pipelines.
- Debug MapReduce and Spark jobs using logs and monitoring tools like Ganglia or Cloudera Manager.
- Tune job parameters such as block size, replication factor, and memory allocation when working with IBM Big Data Infosphere to optimize performance and efficiency.
- Optimize SQL queries in Hive for faster data retrieval.
- Resolve data skew and bottlenecks by distributing tasks evenly across nodes.
- Manage cluster resources efficiently to maximize throughput.
- Communication: To clearly explain data structures and processes to business and technical teams.
- Team Collaboration: Working in tandem with data scientists, analysts, and system administrators.
- Time Management: Prioritizing tasks effectively under tight deadlines, especially when managing real-time data streams with Apache Kafka .
- Adaptability: Staying updated with evolving technologies and adapting to new tools or requirements.
- Analytical Thinking: Breaking down complex problems and implementing effective solutions.
- Educational Background: Most developers have a degree in Computer Science, Information Technology, or Engineering.
- Programming Skills: Mastery of Java and Python is essential.
- Linux Fundamentals: Since Hadoop runs on Linux, command-line proficiency is necessary.
- Hadoop Certifications: Credentials from Cloudera, Hortonworks, or MapR validate your skills and enhance your expertise in integrating tools like Spotfire for advanced analytics and visualization.
- Projects and Internships: Hands-on experience with real-world data sets boosts employability.
- Online Courses: Platforms like Coursera, edX, and Udacity offer specialized Big Data programs.
Knowledge of these languages enables developers to craft versatile and scalable applications within the Hadoop framework.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Working with Big Data Tools
Beyond Hadoop’s native functionalities, developers often turn to various third-party Big Data tools to improve their projects. Apache Spark, for instance, offers in-memory data processing, making it suitable for real-time and iterative workloads. Kafka is crucial for creating real-time data pipelines and streaming applications. At its core, Data Science Training covers the Hadoop Distributed File System (HDFS) for storage and MapReduce for processing. NiFi automates the flow of data between systems, significantly streamlining operations. Zookeeper is key for maintaining distributed synchronization and managing configurations, ensuring systems operate smoothly. Finally, Apache Airflow helps manage complex data pipelines and their dependencies. Getting to know these tools not only boosts the performance of data applications but also improves their scalability and manageability, leading to more robust solutions overall.

Data Pipeline Creation
Creating effective data pipelines is important for any Hadoop Developer. These pipelines manage how data moves from its initial collection to its final analysis. First, during the ingestion phase, developers use tools like Sqoop to import data from SQL databases or Flume to collect log data. Next, the processing step transforms and enriches this data using technologies such as MapReduce, Hive, or Spark. After processing, the data is stored in systems like HDFS or HBase. This setup allows for quick access and easy querying, which is essential for Comparative Analysis . Finally, to keep everything organized, Oozie schedules and automates job execution and workflow management. By building reliable data pipelines, developers ensure that information is delivered accurately and consistently. This is vital for effective downstream analysis and reporting. This structured approach not only simplifies data management but also improves the overall quality of insights drawn from the data.
Debugging and Performance Tuning
As big data workloads scale, so do the complexities of managing them. Hadoop Developers must:
These optimization skills help reduce latency, save computational resources, and ensure system stability.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Soft Skills and Team Collaboration
Technical skills aside, Hadoop developers must also possess strong soft skills, including:
These interpersonal qualities contribute to overall project success and cross-functional cooperation.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Experience and Learning Path
Becoming a Hadoop Developer involves a mix of formal education, practical experience, and ongoing learning:
Continued learning ensures that professionals remain competitive in an evolving job market.
Conclusion
Hadoop Developer Responsibilities play a critical role in designing and maintaining systems that process massive volumes of data. From ingesting and transforming data to managing distributed clusters and ensuring performance optimization, their responsibilities are diverse and vital for any data-driven enterprise. Equipped with the right technical and soft skills gained through Data Science Training these professionals can expect robust career growth and lucrative opportunities in a wide range of industries. As Big Data continues to influence business decisions, the demand for skilled Hadoop Developer Responsibilities remains strong, making it a rewarding and future-proof career choice.




