
Last updated on 07th Oct 2025| 9950
- Introduction
- Why Hadoop? The Big Data Boom
- How Java Skills Complement Hadoop
- Key Hadoop Ecosystem Tools for Java Professionals
- Learning Curve: From OOP to Distributed Processing
- Roadmap to Transition: Java to Hadoop
- Must-Have Skills and Technologies
- Real-World Job Roles and Career Paths
- Final Thoughts
Introduction
Switching careers from Java to Hadoop has become a compelling path for many professionals in today’s fast-evolving technology landscape. For decades, Java has been a cornerstone language in the IT industry, powering web applications, enterprise systems, Android development, and more. However, with the explosion of Big Data, the demand has shifted toward technologies capable of processing and analyzing massive volumes of data in real-time. To stay competitive in this evolving landscape, enrolling in Data Science Training is a forward-thinking move arming professionals with the tools, techniques, and frameworks needed to extract insights, build scalable solutions, and drive innovation in real-time analytics. Today, businesses run on data, and the need for professionals who can store, manage, and extract insights from large datasets has surged. This shift has given rise to Apache Hadoop, a dominant Big Data framework that complements Java skills perfectly. For developers considering switching careers from Java to Hadoop, the transition is not only logical but also highly advantageous, offering opportunities to work on modern data ecosystems and large-scale distributed systems. Ultimately, switching careers from Java to Hadoop opens doors to future-ready, high-demand roles in the world of Big Data.
Why Hadoop? The Big Data Boom
Organizations across the globe generate terabytes of data every day. Traditional relational databases are unable to handle the Volume, Variety, and Velocity of such data effectively. Hadoop emerged as a solution to these limitations by enabling distributed storage and parallel processing across clusters of commodity hardware. To extend these capabilities for real-time access and scalability, understanding HBase and Its Architecture is essential revealing how column-oriented storage, automatic sharding, and tight Hadoop integration empower high-throughput, low-latency data systems.
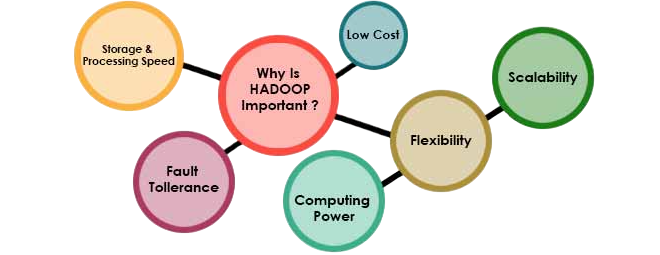
Key reasons for Hadoop’s relevance:
- Open-source and community-driven
- Scalable and fault-tolerant
- Can handle structured, semi-structured, and unstructured data
- Powers real-time analytics, data lakes, and machine learning pipelines
- Backbone of major tech firms like Facebook, Yahoo, and Netflix
In this data-driven economy, Hadoop skills are in high demand making it a promising field for professionals ready to reskill.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
How Java Skills Complement Hadoop
If you’re a Java developer, you already possess a strong foundation that translates well into Hadoop. In fact, Hadoop is written in Java, and many of its APIs are Java-based. To simplify complex data processing tasks on Hadoop, understanding What is Apache Pig is essential offering a high-level scripting platform that abstracts Java complexity and accelerates development with its data flow language, Pig Latin.
Here’s how your Java experience helps:
- Object-Oriented Concepts: Hadoop’s architecture and APIs are designed with OOP principles in mind.
- Multithreading & Exception Handling: Useful for understanding parallel task execution in MapReduce.
- JVM Familiarity: Easier environment setup, configuration, and debugging of Hadoop tools.
- Code Modularity: Writing clean, scalable mappers and reducers is second nature to Java developers.
- Enterprise Project Experience: Valuable in Big Data deployments that involve data modeling and system integration.
Thus, your transition is more of a shift in mindset and tooling than starting from scratch.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Key Hadoop Ecosystem Tools for Java Professionals
The Hadoop ecosystem comprises several components and tools, and Java developers can gain proficiency in many of them due to their programming familiarity. To extend this expertise into cloud-native analytics, understanding What is Azure Databricks is essential revealing how Apache Spark, collaborative notebooks, and scalable data engineering workflows converge on a unified platform for enterprise-grade insights.
Tools Java Developers Should Focus On:
- HDFS (Hadoop Distributed File System): Understand how large data is stored across nodes.
- MapReduce: Core data processing framework natively written in Java.
- YARN (Yet Another Resource Negotiator): Manages cluster resources.
- Hive: Data warehousing and SQL-based queries (can be extended via Java UDFs).
- Pig: Data flow scripting easier for quick prototyping.
- Sqoop: Transfer data between RDBMS and HDFS (works well with JDBC).
- HBase: Columnar NoSQL database integrated with Hadoop Java APIs available.
- Oozie: Java-based workflow scheduler for Hadoop jobs.
- Apache Spark: In-memory computation engine; supports Java API for DataFrames and RDDs.
For Java professionals, starting with MapReduce and HDFS, then moving to higher-level abstractions like Hive and Spark, offers a smooth learning gradient.

Learning Curve: From OOP to Distributed Processing
Making the leap from standard Java programming to the Hadoop framework requires a fundamental change in a developer’s mindset. It shifts from centralized, object-based structures to a distributed, functional approach for handling data. Programmers need to adopt new design principles, where processing data at its source takes priority over application-specific logic. The emphasis moves away from changing object states and toward applying a series of transformations to unchangeable datasets. The Hadoop environment brings its own set of challenges, like managing clusters of machines, designing systems to be fault-tolerant for node failures, and developing reliable data replication strategies. To tackle these complexities with confidence, enrolling in Data Science Training is a smart choice arming professionals with the skills to architect resilient systems, optimize distributed processing, and implement robust data engineering solutions. The infrastructure changes too, moving from familiar web or application servers to a new system of data nodes and mappers. While learning both bulk batch processing and real-time stream processing can seem daunting at first, these ideas mostly build on established programming logic. With focused learning, managing large amounts of data can become a natural skill. By understanding the basic principles of Hadoop’s distributed system, developers can effectively leverage the power of parallel computing and unlock data-handling abilities that go far beyond what traditional programming can offer.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Roadmap to Transition: Java to Hadoop
For a Java developer to successfully transition into the big data field, a careful and well-rounded learning path is crucial for mastering Hadoop and its related technologies. Start by building a solid foundation in big data theory, focusing on the key features of volume, velocity, and variety (the 3Vs). Additionally, explore real-world business problems that Hadoop can effectively solve. Next, dive into Hadoop’s core architecture by understanding its key components: the Hadoop Distributed File System (HDFS) for storage, the MapReduce processing model, and the YARN resource manager. Setting up a single-node, pseudo-distributed cluster on your local machine is vital for practical experience. The next step is to apply your knowledge to handle large datasets. To see how these technical foundations support organizational transformation, explore Data-Driven Culture Explained a guide to embedding analytics into decision-making, collaboration, and scalable innovation. Get hands-on by coding classic MapReduce jobs like the WordCount algorithm and other data aggregation tasks. Then, expand your skills by exploring the broader Hadoop ecosystem. Familiarize yourself with tools like Hive for data warehousing, Pig for scripting, Sqoop for database transfers, and HBase for NoSQL. A great exercise is to use your existing Java skills to create custom User-Defined Functions (UDFs) in Hive. To improve your skills further, incorporate modern frameworks like Apache Spark for faster processing and learn about technologies for managing real-time data streams, such as Apache Kafka and Flume. The final goal of this learning journey should be to complete a full data engineering project.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Must-Have Skills and Technologies
To stand out as a Hadoop professional, you should aim to build expertise in a combination of Hadoop core components and supporting technologies. Equally important is understanding Data Governance Explained a framework that ensures data integrity, security, and compliance across distributed systems, helping professionals manage sensitive information responsibly while scaling analytics initiatives.
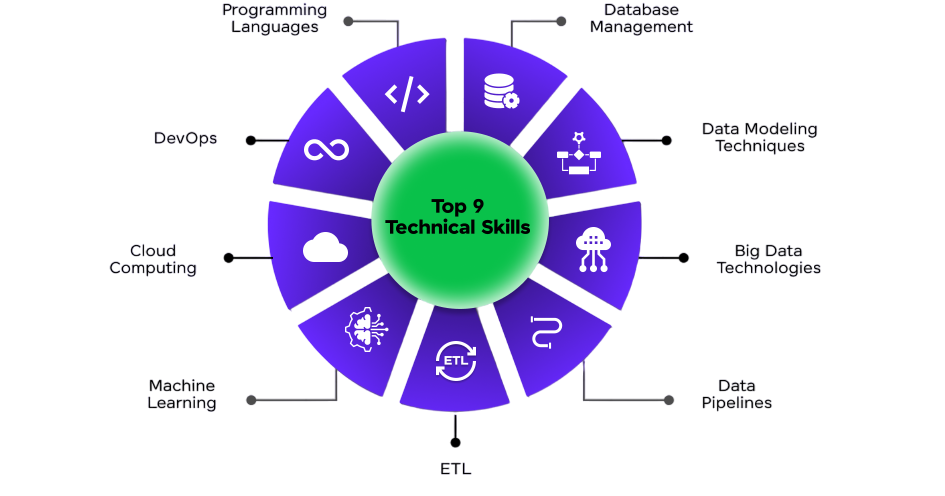
Core Technical Skills:
- Java/Scala/Python: Preferred for MapReduce and Spark
- HDFS and MapReduce programming
- SQL & HiveQL
- Linux and Shell Scripting
- Apache Spark
- NoSQL databases (HBase, Cassandra)
- Data ingestion tools (Sqoop, Flume, Kafka)
- Scheduling tools (Oozie, Airflow)
Optional but Valuable:
- Cloud Hadoop platforms: AWS EMR, Google Dataproc
- Data modeling and schema design
- Machine learning basics using Spark MLlib
- Docker/Kubernetes for Hadoop deployments
Your Java background ensures you pick up most of these faster than someone from a non-programming background.
Real-World Job Roles and Career Paths
Switching to Hadoop doesn’t mean you become just a “Hadoop Developer”. It opens doors to a range of data-focused roles. To navigate these opportunities effectively, understanding Apache Hive vs HBase is essential highlighting the differences between batch-oriented SQL querying and real-time NoSQL access, and helping professionals choose the right tool for their data architecture needs.
Career Paths:
- Big Data Developer
- Hadoop Developer
- Data Engineer
- ETL Engineer (Big Data ETL)
- Spark Developer
- Machine Learning Engineer
- Data Architect
Typical Responsibilities:
- Writing scalable MapReduce/Spark jobs
- Data ingestion, transformation, and pipeline orchestration
- Real-time and batch data analysis
- Building data lakes and warehouses
- Optimizing storage, job performance, and resource usage
These roles not only leverage your programming skills but also place you at the heart of modern business decision-making through data.
Final Thought
Switching your career from Java to Hadoop is not a leap into the unknown, it’s an evolution of your existing skill set. With Java as the backbone of Hadoop’s core systems and APIs, you already have a strategic advantage. All you need is the right training, hands-on practice, and project experience to reposition yourself as a data engineer or Hadoop expert. Enrolling in Data Science Training can accelerate that transition providing the technical depth, real-world exposure, and certification pathways needed to thrive in today’s data-driven roles. In the journey of switching careers from Java to Hadoop, you’ll discover that Big Data is no longer just a buzzword, it’s the backbone of digital business, and Hadoop remains one of its strongest pillars. Whether you’re interested in data lakes, real-time analytics, or building machine learning pipelines, Switching Career from Java to Hadoop equips you to tackle some of the most exciting and impactful challenges in the tech industry today.




