
Last updated on 30th Sep 2025| 10034
- Introduction to CCA 175
- Exam Objectives and Syllabus
- Eligibility and Prerequisites
- Spark and Hadoop Topics
- Hands-On Lab Setup
- Tips for Preparing
- Sample Questions and Answers
- Conclusion
Introduction to CCA 175
The Cloudera Certified Associate (CCA) 175 Spark and Hadoop Developer certification is a globally recognized credential for professionals aiming to validate their expertise in developing data processing applications using Apache Spark and Hadoop. This certification, offered by Cloudera, is designed to test the practical abilities of candidates to perform real-world data engineering tasks. With the data landscape constantly evolving, possessing hands-on knowledge of big data frameworks like Spark and Hadoop is highly valuable for aspiring data professionals. CCA 175, or Cloudera Certified Associate Data Analyst, is an entry-level certification designed for individuals who want to demonstrate their skills in data analysis using Cloudera’s platform. It focuses on querying and analyzing data stored in Hadoop using tools like Apache Hive and Apache Impala Data Science Training . Candidates learn to write efficient SQL queries, create reports, and perform data transformations. This certification validates foundational knowledge essential for data analysts working with big data technologies. Earning CCA 175 helps professionals enhance their career prospects by proving their ability to work effectively in modern data ecosystems. The CCA 175 (Cloudera Certified Associate – Spark and Hadoop Developer) certification is designed for developers working with Apache Spark and Hadoop ecosystems. It validates skills in data ingestion, transformation, and analysis using Spark Core, Spark SQL, and Spark Streaming on the Cloudera platform. Candidates must demonstrate the ability to write functional Spark applications in Scala or Python and work with HDFS, Hive, and other data tools. The exam is performance-based, conducted in a live cluster environment. Data-Driven Culture Earning the CCA 175 certifies practical big data development skills and enhances job opportunities in data engineering and analytics roles across industries.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Exam Objectives and Syllabus
The CCA 175 exam evaluates a candidate’s capabilities across several practical domains. These include data ingestion using tools such as Sqoop and Flume, data transformation using Spark Core and Spark SQL, and data storage strategies on Hadoop Distributed File System (HDFS). The exam also covers workflow management, focusing on the integration and debugging of applications built on Spark and the broader Hadoop ecosystem. The detailed syllabus involves tools and technologies like Apache Spark Big Data Analysis (RDDs, DataFrames, Datasets), Apache Hadoop (HDFS, MapReduce, YARN), Hive, Impala, Sqoop, Flume, and various file formats like Avro, ORC, and Parquet.

Candidates are expected to demonstrate proficiency in handling large datasets, data movement, and complex transformations. The CCA 175 exam tests practical skills in Apache Spark and Hadoop development. Key objectives include data ingestion from various sources (HDFS, Flume, Kafka), data transformation using Spark Core APIs, and data analysis with Spark SQL and DataFrames. Candidates must also demonstrate knowledge of working with Hive tables, partitioning, and performance optimization. Azure Databricks Spark Streaming tasks are included to assess real-time data processing skills. The syllabus covers programming in Scala or Python, understanding of HDFS commands, and managing data formats like JSON, Avro, and Parquet. The exam is hands-on, requiring candidates to solve real-world problems in a live Cloudera environment.
Eligibility and Prerequisites
- Basic Programming Knowledge – Proficiency in Python or Scala is essential.
- Understanding of Big Data Concepts – Familiarity with Hadoop, Spark, and distributed computing.
- Experience with Linux/Unix – Ability to work in a command-line environment.
- Knowledge of HDFS – Understanding Hadoop Distributed File System operations Elasticsearch Nested Mapping .
- SQL Skills – Ability to write queries and work with Hive tables.
- Data Formats – Familiarity with JSON, Avro, Parquet, etc.
- Hands-on Practice – Experience running Spark jobs in a real or simulated cluster.
- No Formal Degree Required – Open to all backgrounds with relevant skills.
- System Requirements – Minimum 8GB RAM, 64-bit OS, and sufficient disk space.
- Install VirtualBox/VMware – Set up a virtual environment for Cloudera QuickStart VM.
- Download Cloudera QuickStart VM – Get the official VM image for practice.
- Install Hadoop and Spark – Alternatively, install components manually using a Linux distribution Various Talend Products and their Features .
- Set Up IDE – Use IntelliJ IDEA or VS Code for Scala/Python development.
- Configure Environment Variables – Set paths for Hadoop, Spark, and Java.
- Test Sample Jobs – Run basic Spark and Hadoop commands.
- Practice Exam Tasks – Simulate real-world tasks in your setup.
- sqoop import –connect jdbc:mysql://localhost/db –username user –password pass \ –table employees –target-dir /user/hadoop/employees
- rdd = sc.textFile(“hdfs://input.txt”)
- words = rdd.flatMap(lambda x: x.split(” “))
- wordCount = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
- wordCount.saveAsTextFile(“hdfs://output”)
- CREATE TABLE emp (id INT, name STRING, salary FLOAT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’;
- LOAD DATA INPATH ‘/user/hive/emp.csv’ INTO TABLE emp;
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Spark and Hadoop Topics
The core of the CCA 175 exam lies in assessing practical application. Key areas include Spark Core and Spark SQL, where candidates write optimized applications using RDDs and DataFrames. Another important area is data ingestion, where tools like Sqoop and Flume are used to import data from relational databases and real-time sources into HDFS. Other covered topics include data transformation workflows using Spark, writing data in different formats, querying large datasets with Hive and Impala, and understanding HDFS file systems. Additionally, candidates need to be comfortable with compression techniques, partitioning strategies, and data serialization formats. The CCA 175 exam focuses on key Spark and Hadoop topics essential Data Science Training for big data development. Core Spark topics include Spark Core APIs for RDD transformations and actions, Spark SQL for querying structured data, and Spark Streaming for real-time data processing. Candidates must understand working with DataFrames, datasets, and Spark configurations.
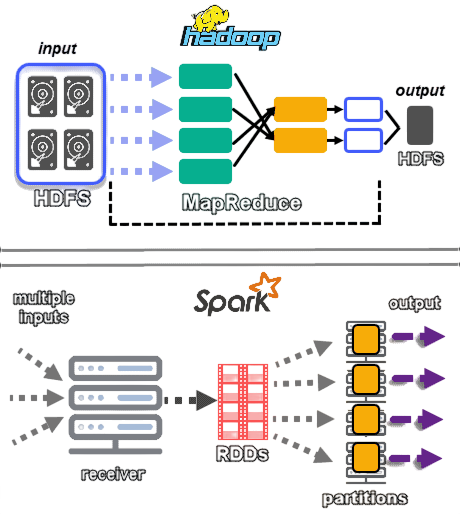
Hadoop-related topics cover HDFS architecture, file operations, and data ingestion using tools like Sqoop and Flume. The exam also includes Hive integration, data serialization formats (Avro, Parquet, JSON), and performance tuning techniques. Proficiency in using Scala or Python to write Spark applications is critical for passing the certification.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Hands-On Lab Setup

Tips for Preparing
Tips for Preparing for the CCA 175 exam involves both theoretical study and practical execution. Begin by thoroughly reviewing Cloudera’s official exam guide and syllabus. Use practice books like “Learning Spark” and “Hadoop: The Definitive Guide” to strengthen foundational concepts. Online courses on Udemy, Coursera, and DataCamp provide structured content and hands-on labs. Solve sample problems and take mock exams to get accustomed to the exam pattern. Most importantly, remember that the exam is open-terminal with no internet access, so practice syntax and commands rigorously. Preparing for the CCA 175 exam requires a strategic approach Data Architect Salary in India . Start by mastering Spark and Hadoop fundamentals through official documentation and online courses. Focus on hands-on practice using the Cloudera QuickStart VM or a custom lab setup. Practice writing Spark applications in Python or Scala, and work extensively with HDFS, Hive, and various data formats like JSON and Parquet. Simulate real exam tasks and time yourself to build speed and accuracy. Join forums or study groups for peer support and insights. Review past exam experiences and practice mock scenarios. Consistent coding and real-world data problem solving are key to success.
Sample Questions and Answers
To help candidates understand the format and expectations, here are a few sample tasks:
Ingesting Data from MySQL using Sqoop:
Writing a Basic Spark Transformation in Python:
Creating and Loading Data into a Hive Table:
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Ace Your Interview!
Conclusion
The CCA 175 certification is a valuable credential for aspiring big data developers, validating their practical skills in Apache Spark and Hadoop ecosystems. It emphasizes real-world data processing tasks, requiring candidates to demonstrate their ability to ingest, transform, and analyze data using Spark Core, Spark SQL, Recommended Study Resources and Spark Streaming. With its hands-on, performance-based format, the exam ensures that certified individuals are job-ready and capable of working in production environments <Data Science Training. Preparing for CCA 175 involves a solid understanding of big data concepts, programming proficiency in Python or Scala, and hands-on experience with tools like HDFS, Hive, and Sqoop. Setting up a local lab or using virtual environments like the Cloudera QuickStart VM is crucial for gaining practical experience. Candidates should also focus on working with different data formats and optimizing performance in distributed systems. Successfully earning the CCA 175 certification not only boosts your resume but also opens doors to roles such as data engineer, big data developer, or Spark specialist. With the growing demand for data-driven solutions across industries, certified professionals are well-positioned to take advantage of numerous career opportunities. Consistent practice, a clear study plan, Sample Questions and




