
Last updated on 08th Oct 2025| 10170
- Introduction: The Era of Big Data Careers
- Why Big Data Skills are in High Demand
- Data Storage Technologies: HDFS and Beyond
- Data Processing Tools: Hadoop, Spark, and Flink
- Data Warehousing and Query Engines
- Mastering Data Ingestion Tools
- Real-Time Data Streaming Technologies
- NoSQL Databases and Their Use Cases
- Conclusion
Introduction: The Era of Big Data Careers
The digital universe is growing at an unprecedented rate, with data volumes expanding exponentially each year. In this age of digital transformation, data is not just a byproduct of business it is a strategic asset. Consequently, the demand for professionals who can work with and extract value from this data has skyrocketed. Whether you’re a fresher looking to enter the tech industry or an experienced professional aiming to reskill, Big Data Training proficiency in Big Data technologies is rapidly becoming essential to building a sustainable, high-paying career. In today’s digital world, data is being generated at an unprecedented scale, driving the rapid growth of the big data industry. As organizations increasingly rely on data to make informed decisions, the demand for skilled professionals in big data analytics, engineering, and architecture is soaring. From finance to healthcare, big data careers are reshaping industries and opening up exciting opportunities for those with the right skills. This era marks a powerful shift where data isn’t just a byproduct, but a key asset fueling innovation, strategy, and competitive advantage.
Why Big Data Skills are in High Demand
Businesses across sectors from healthcare and finance to e-commerce and entertainment are leveraging Big Data for better decision-making, forecasting, and personalized services. The ability to handle, process, and derive insights from large and complex datasets is a specialized skill set that not only demands technical expertise but also an understanding of data ecosystems. As more organizations transition to data-driven operations, Big Data professionals are being hired at aggressive rates Data Integration . Employers value candidates who are proficient in the tools and platforms that dominate this space.
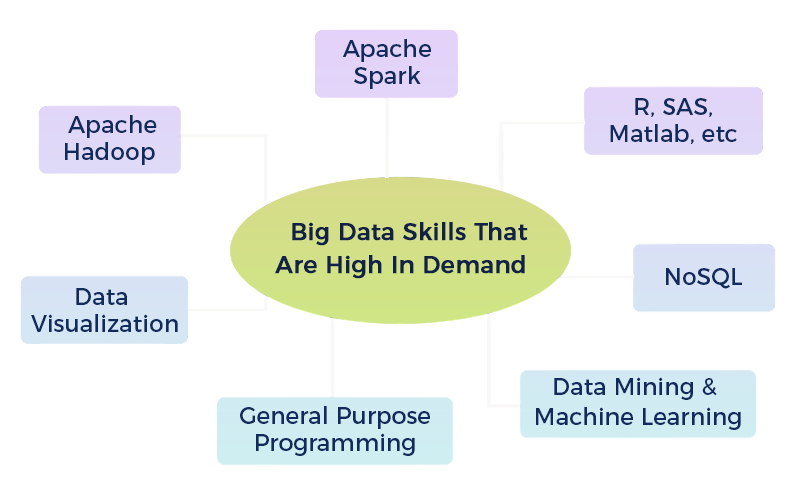
These are no longer niche skills; they are mandatory proficiencies that unlock top-tier job roles such as Data Engineer, Data Analyst, Machine Learning Engineer, and Big Data Architect. Big data skills are in high demand as organizations seek to harness vast amounts of data for insights and decision-making. With the rise of AI, IoT, and digital transformation, professionals who can analyze, manage, and interpret complex data are essential for driving innovation, efficiency, and competitive advantage.
Do You Want to Learn More About Big Data Analytics? Get Info From Our Big Data Course Training Today!
Data Storage Technologies: HDFS and Beyond
- HDFS (Hadoop Distributed File System): Core storage layer of the Hadoop ecosystem, designed for storing large datasets across distributed clusters.
- Scalability: HDFS supports horizontal scaling, making it suitable for big data applications.
- Fault Tolerance: Data is replicated across nodes, ensuring reliability and data recovery in case of hardware failures.
- Limitations of HDFS: Not ideal for real-time processing or small files; high latency and complexity in data retrieval.
- Amazon S3: Cloud-based, scalable object storage with high availability and durability.
- Google Cloud Storage: Offers seamless integration with big data tools and supports analytics workloads.
- Apache Cassandra: NoSQL database designed for real-time data storage across distributed systems Big Data Training.
- Apache HBase: Columnar store built on top of HDFS for real-time read/write access to large datasets.
- Delta Lake / Apache Iceberg: Modern storage layers that bring ACID transactions to data lakes.
- Choosing the Right Storage: Depends on factors like use case (batch vs. real-time), scalability needs, data volume, and integration with analytics tools.
Beyond HDFS – Modern Alternatives:
Data Processing Tools: Hadoop, Spark, and Flink
Apache Hadoop
- Batch Processing Framework: Processes large datasets in batches using the MapReduce paradigm.
- Scalability: Can handle petabytes of data across distributed clusters.
- Storage Integration: Works closely with HDFS for data storage and retrieval.
- Limitations: Slower processing speed, not suitable for real-time analytics.
- In-Memory Processing: Much faster than Hadoop MapReduce due to in-memory computation.
- Supports Multiple Workloads: Handles batch processing, streaming, machine learning, and SQL queries Data Governance .
- Ease of Use: Offers APIs in Scala, Python, Java, and R.
- Highly Scalable: Works well in both standalone and distributed environments.
Apache Spark
- Stream-First Architecture: Designed for real-time stream processing, with strong support for batch jobs as well.
- Low Latency & High Throughput: Ideal for event-driven and real-time applications.
- Stateful Stream Processing: Maintains application state across events for complex event processing Apache Spark Certification.
- Fault Tolerance: Supports exactly-once state consistency guarantees using checkpointing.
Apache Flink
- Use Hadoop for large-scale batch jobs with high fault tolerance.
- Use Spark for fast, flexible analytics across batch and streaming data.
- Use Flink for low-latency, real-time data processing with complex event handling.
- Apache Sqoop – Transfers structured data between RDBMS and HDFS.
- Apache Flume – Ingests log and event data into Hadoop.
- Apache NiFi – Provides a UI-driven approach to building robust data flow pipelines Big Data is Transforming Retail Industry .
- Kafka Connect – Ingests data into Apache Kafka for real-time pipelines.
- Apache Kafka – The gold standard for real-time data pipelines, acting as a distributed message queue.
- Apache Storm – An older real-time computation system known for low-latency processing Big Data Drives Small and Medium .
- Apache Flink – Offers advanced stream and batch processing capabilities in a single engine.
- Amazon Kinesis and Azure Event Hubs – Cloud-based streaming platforms.
Choosing the Right Tool
Would You Like to Know More About Big Data? Sign Up For Our Big Data Analytics Course Training Now!
Data Warehousing and Query Engines
In the modern Data Warehousing and Query landscape, data warehousing plays a crucial role in enabling organizations to store, manage, and analyze large volumes of structured data efficiently. Traditional data warehouses, such as Amazon Redshift, Google BigQuery, and Snowflake, offer scalable, high-performance solutions for running complex analytical queries over massive datasets. These platforms support SQL-based querying and integrate well with business intelligence tools, making them ideal for reporting Big Data Can Help You Do Wonders, dashboarding, and decision-making. Complementing data warehouses are powerful query engines like Apache Hive, Presto (Trino), and Apache Drill, which allow users to run SQL queries directly on data stored in distributed file systems such as HDFS, S3, or data lakes. These engines abstract the complexity of the underlying data structure and provide a familiar interface for analysts and data engineers. They are particularly useful for interactive analytics, ad-hoc querying, and unifying data from multiple sources without needing to move or transform it first. Together, data warehouses and query engines form the backbone of enterprise analytics, enabling scalable, real-time insights from vast and diverse data sources.

Mastering Data Ingestion Tools
A critical step in any Big Data pipeline is ingesting data from various sources databases, logs, IoT devices, or social media.
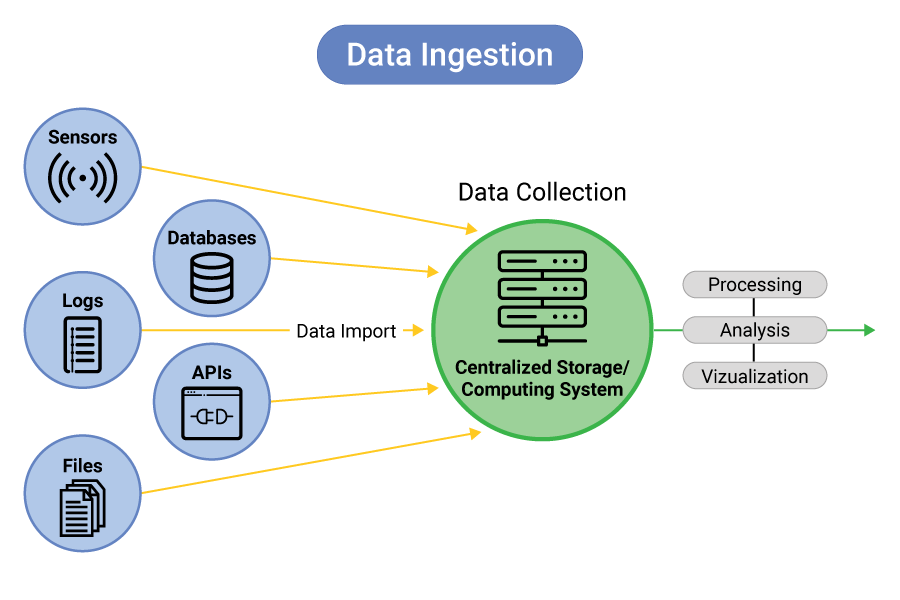
Tools to master include:
Knowing how to build efficient ingestion workflows is a vital skill for data engineers and architects.
Gain Your Master’s Certification in Big Data Analytics Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Real-Time Data Streaming Technologies
As the world moves toward real-time decision-making, the demand for stream processing technologies is rising dramatically.
Key platforms include:
Organizations dealing with fraud detection, live analytics, and monitoring systems look for professionals proficient in these tools to build scalable, event-driven architectures.
Preparing for Big Data Analytics Job? Have a Look at Our Blog on Big Data Analytics Interview Questions & Answer To Ace Your Interview!
NoSQL Databases and Their Use Cases
NoSQL databases have become essential in the era of big data and cloud-native applications due to their flexibility, scalability, and ability to handle diverse data types. Unlike traditional relational databases, NoSQL systems are designed to store and process unstructured or semi-structured data with ease, making them suitable for modern use cases where data models evolve quickly. Common types of NoSQL databases include document stores (e.g., MongoDB), wide-column stores (e.g., Apache Cassandra), key-value stores (e.g., Redis), and graph databases (e.g., Neo4j). Each type of NoSQL database is optimized for specific scenarios. For instance, MongoDB is widely used in content management systems, e-commerce platforms, What is Data Pipelining and mobile apps due to its flexible document structure and ease of use. Cassandra, on the other hand, is ideal for high-write, distributed applications such as IoT platforms, recommendation engines, and real-time analytics. Redis excels in caching, session management, and real-time leaderboards thanks to its in-memory speed. Graph databases are used in social networks, fraud detection, and network analysis where relationships between data points are key. As the need for scalable and high-performance systems continues to grow, NoSQL databases offer tailored solutions that align with the dynamic demands of modern applications across various industries.
Conclusion
The field of Big Data is dynamic and constantly evolving, but its relevance and career potential are undeniable. From storage systems and processing engines to real-time analytics and cloud data platforms, today’s Data Streaming professionals must equip themselves with a well-rounded and continually updated skillset Big Data Training. Gaining proficiency in these essential Big Data technologies doesn’t just make you job-ready, it makes you future-proof in a world where data is at the heart of every innovation. Whether you’re aiming to become a Data Warehousing and Query, architect, analyst, or scientist, mastering these technologies is the first and most crucial step in your Big Data career journey.




