
Last updated on 09th Oct 2025| 10125
- What is Big Data?
- Characteristics of Big Data
- Technologies Supporting Big Data
- Hadoop Ecosystem Overview
- Introduction to HDFS
- Introduction to MapReduce
- Data Ingestion Tools (Sqoop, Flume)
- NoSQL Databases Overview
- Big Data Analytics Tools
- Conclusion
What is Big Data?
Guide to Big Data serves as a roadmap for understanding how massive and complex datasets are transforming modern industries. Big Data includes large and complex datasets that traditional data processing tools struggle to manage. These datasets come from sources like social media, sensors, online transactions, GPS logs, and Internet of Things (IoT) devices. The goal is not just to collect this data, but to extract valuable insights that can guide important decisions. To learn how to transform raw data into strategic intelligence, visit Data Science Training a hands-on course that teaches the tools, techniques, and analytical mindset needed to turn complex datasets into actionable outcomes. As our digital world expands, Big Data has become crucial in various industries, such as finance, healthcare, retail, and manufacturing. By using these large datasets, organizations can spot trends, improve customer experiences, and boost efficiency. In a time when information is everywhere, using Big Data helps businesses stay competitive and meet their customers’ changing needs. This Guide to Big Data highlights how organizations can turn raw information into strategic advantage in the data-driven era.
Characteristics of Big Data
The main features of today’s data ecosystem are described by a five-dimensional model known as the 5 Vs. This framework offers a clear view of the complex nature of large datasets. Volume refers to the enormous amount of information generated. Modern organizations handle vast quantities of data from many sources, such as server logs, multimedia files, and customer transaction records. Velocity emphasizes the fast pace at which this data is created and needs to be processed. This is crucial in fast-changing environments like cybersecurity and stock market analysis, where quick action is necessary. The Variety principle describes the diverse types of data. This includes well-organized structured formats, as well as semi-structured and unstructured forms. To understand how different platforms handle this diversity and speed, visit Hadoop Vs Apache Spark a detailed comparison that explores performance, scalability, and use-case alignment across modern data ecosystems. All these types require flexible and powerful tools for management. Veracity represents an important aspect, focusing on the accuracy and reliability of information. This requires careful filtering to remove noise and inconsistencies. In the end, these four dimensions lead to Value. This is about transforming raw data into a strategic asset. The true power of Big Data is achieved when it provides actionable insights that drive significant advancements in research and improve business strategies. This process turns vast streams of information into valuable insights that can change performance and foster innovation.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Technologies Supporting Big Data
Managing Big Data requires a technology stack that supports storage, processing, analysis, and visualization. Key technologies include Hadoop, MapReduce, Hive, Pig, and Spark each playing a vital role in handling large-scale data workflows. To explore the essential tools and skills needed for this career path, visit How to Become a Hadoop Developer a detailed guide that outlines the learning roadmap, core competencies, and industry expectations for aspiring data engineers.
- Distributed Storage: Hadoop Distributed File System (HDFS), Amazon S3
- Processing Frameworks: Apache MapReduce, Apache Spark
- Data Ingestion Tools: Apache Sqoop, Apache Flume, Apache Kafka
- NoSQL Databases: MongoDB, Cassandra, HBase
- Analytics and Visualization: Hive, Pig, Tableau, Power BI
- Workflow and Orchestration: Apache Oozie, Apache Airflow
Managing Big Data requires a technology stack that supports storage, processing, analysis, and visualization.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Hadoop Ecosystem Overview
Hadoop is an open-source framework for distributed storage and parallel data processing. Hadoop ecosystem consists of various components: HDFS for storage, MapReduce for processing, and tools like Hive, Pig, and HBase for querying and managing data. To explore the scale, complexity, and architecture behind these technologies, visit How big Is Big Data an in-depth article that explains the magnitude of modern datasets and the infrastructure required to handle them efficiently.
- HDFS: A distributed file system that stores data across multiple nodes.
- MapReduce: A programming model to process large datasets in parallel.
- YARN (Yet Another Resource Negotiator): Manages system resources and job scheduling.
- Hive: A data warehouse infrastructure built on Hadoop for querying using SQL-like syntax.
- Pig: A platform for data flow scripting that simplifies complex MapReduce programs.
- HBase: A column-oriented NoSQL database that runs on top of HDFS.
- ZooKeeper: Provides centralized configuration and synchronization services.
- Oozie: A workflow scheduler that automates job execution in Hadoop.
Hadoop is an open-source framework for distributed storage and parallel data processing.

Introduction to HDFS
The Hadoop Distributed File System (HDFS) provides a modern approach to managing large datasets. Its main strategy is to break every file into smaller 128MB chunks and distribute them across a cluster of computers. For greater reliability, HDFS doesn’t just keep one copy; it automatically creates duplicates of each chunk, usually making three copies on different computers to avoid any single point of failure. Two key parts make this system function. The NameNode acts as the brain of the system, tracking the metadata and the location of each data chunk. To understand how these distributed systems operate and support scalable analytics, visit Data Science Training a hands-on course that teaches the architecture, tools, and techniques behind fault-tolerant data platforms. The DataNodes handle the actual storage of the data. Together, they form a strong and flexible structure, perfect for data-intensive tasks that need to process large amounts of information quickly.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Introduction to MapReduce
Hadoop’s MapReduce model provides an effective way to process large amounts of data across many computers at the same time. The process has two main stages: Map and Reduce. First, the Map stage takes a large, complex dataset and breaks it into smaller, more manageable pieces. It organizes this data into simple key-value pairs, allowing multiple computers to work on different parts of the data at once.
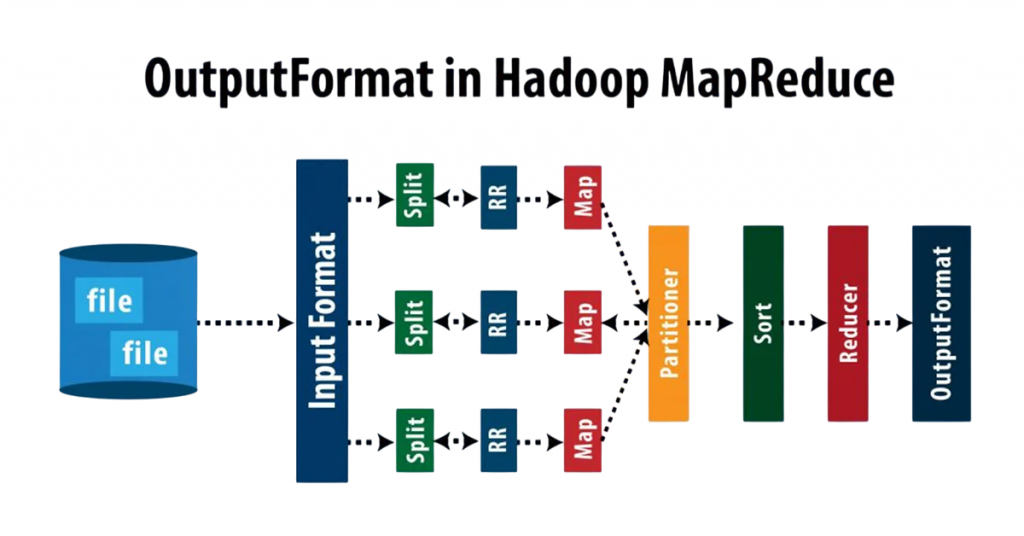
Next, the Reduce stage collects the results from all the individual Map tasks. It combines these outputs to produce a final, unified answer. This is where tasks like counting items, sorting data, or filtering information take place—core operations that drive efficiency and accuracy in retail environments. To explore how these data-driven processes are reshaping customer experiences and inventory management, visit Big Data is Transforming Retail Industry an insightful article that highlights the technologies, trends, and strategies powering retail innovation. By splitting the work this way, organizations can analyze massive datasets quickly and efficiently, making MapReduce a key part of modern big data analysis.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Data Ingestion Tools (Sqoop, Flume)
Efficient data ingestion is vital to populate the Hadoop ecosystem, enabling seamless integration of structured and unstructured data from various sources. To understand the foundational principles behind this process and explore the broader architecture, visit Essential Concepts of Big Data an in-depth article that breaks down ingestion strategies, ecosystem components, and the role of Hadoop in scalable data management.
- Sqoop: Transfers bulk data between Hadoop and RDBMS. Common use cases include importing MySQL tables into HDFS.
- Flume: Collects and transfers log data from various sources like web servers to HDFS or HBase in real-time.
Both tools help bridge the gap between traditional systems and Big Data infrastructure.
NoSQL Databases Overview
Master the challenges of today’s large, diverse, and constantly changing datasets. Unlike traditional relational systems, these databases can scale by adding more servers and use different data structures for specific tasks. Document databases, like MongoDB, store data in flexible, JSON-like documents. This flexibility makes them ideal for applications that change over time. To explore how these technologies fit into modern analytics workflows and career paths, visit Become a Big Data Analyst a practical guide that outlines the tools, skills, and strategies needed to thrive in today’s data-driven roles.
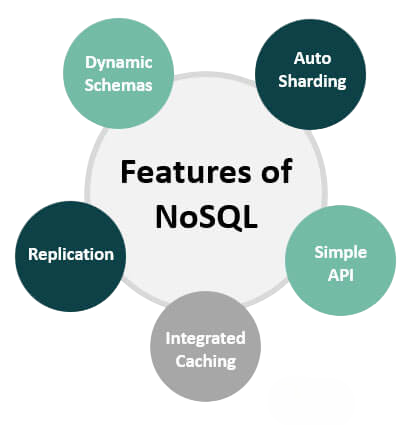
Key-value stores, such as Redis, work like a high-speed dictionary. They link a simple key to a value for very fast data retrieval. Column-oriented databases, including Cassandra and HBase, organize data by columns instead of rows. This structure optimizes large-scale analytical queries. Graph databases, like Neo4j, focus on mapping and exploring the complex connections in highly linked data. By offering these flexible and high-performing storage options, NoSQL technologies have become essential in the Big Data landscape. They help organizations manage and understand complex information flows quickly and efficiently.
Big Data Analytics Tools
Analytics is the ultimate goal of Big Data. Tools for analytics include Hadoop, Spark, Hive, and advanced machine learning platforms that help extract insights from massive datasets. To see how these tools are applied at scale, visit Facebook is Using Big Data an in-depth article that explores how one of the world’s largest tech companies leverages data to personalize experiences, optimize performance, and drive innovation.
- Hive: SQL-like querying over large datasets stored in HDFS.
- Pig: High-level scripting language for data analysis.
- Spark SQL: Enables querying structured data with higher performance.
- Tableau & Power BI: Used for creating dashboards and visualizations for non-technical users.
- R & Python: Used for statistical modeling and machine learning.
These tools support tasks from ETL (Extract, Transform, Load) to business intelligence.
Conclusion
A Guide to Big Data serves as a gateway for anyone eager to understand how data transforms decisions and innovation. Big Data represents a major shift in how organizations use information to create value. It’s not just a passing trend; it offers a chance for anyone to tap into the potential of large amounts of data. By gaining the right skills and tools, individuals can learn to analyze data and tackle real-world challenges. This tutorial is made for beginners, providing a simple pathway into the world of Big Data. To start your journey with a structured, beginner-friendly curriculum, visit Data Science Training a foundational program that introduces key concepts, tools, and techniques for launching a successful career in analytics. Throughout the course, you will learn the key concepts and methods needed to start your journey in data analysis. Whether you want to boost your career or simply understand this important field better, this guide gives you a strong foundation to get the most out of Big Data and its transformative power. Get ready to explore the exciting opportunities, this Guide to Big Data is your roadmap to mastering data-driven thinking and unlocking new possibilities.




