
Last updated on 06th Nov 2025| 10273
- What is Big Data?
- 5 V’s of Big Data
- Milestones in Big Data Development
- Key Technologies (Hadoop, Spark, etc.)
- Industry Adoption
- Success Stories
- Common Challenges
- Current Trends
- Role of AI and ML in Big Data
- Future Outlook
- What is Hadoop?
- Need for Hadoop in Big Data
- Hadoop Distributions (CDH, HDP, etc.)
- Conclusion
What is Big Data?
Big Data refers to the large volumes of structured, semi-structured, and unstructured data generated by digital processes, social media, sensors, devices, and enterprise applications. It is defined not only by its size but also by the complexity and speed at which it is generated and processed. Big Data leads to insights that support better decisions, innovation, and strategic business actions across industries. The idea of managing and analyzing massive data sets has existed since the early 2000s, when companies began recognizing the value of data beyond traditional structured formats. The term “Big Data” became popular when industry leaders like Doug Laney introduced the 3 V’s model (Volume, Velocity, and Variety). At first, traditional RDBMS systems had trouble with the complexity, and new frameworks like Hadoop emerged to store and process data at scale. Over the years, Big Data Hadoop Certification Training changed from a niche capability to an essential function for businesses of all sizes, leading to the creation of better analytics tools and scalable storage platforms.
5 V’s of Big Data
These dimensions define the challenges associated with Big Data and help businesses evaluate its relevance. Together, they frame the multi-dimensional challenges of Big Data in terms of collection, processing, and analysis.
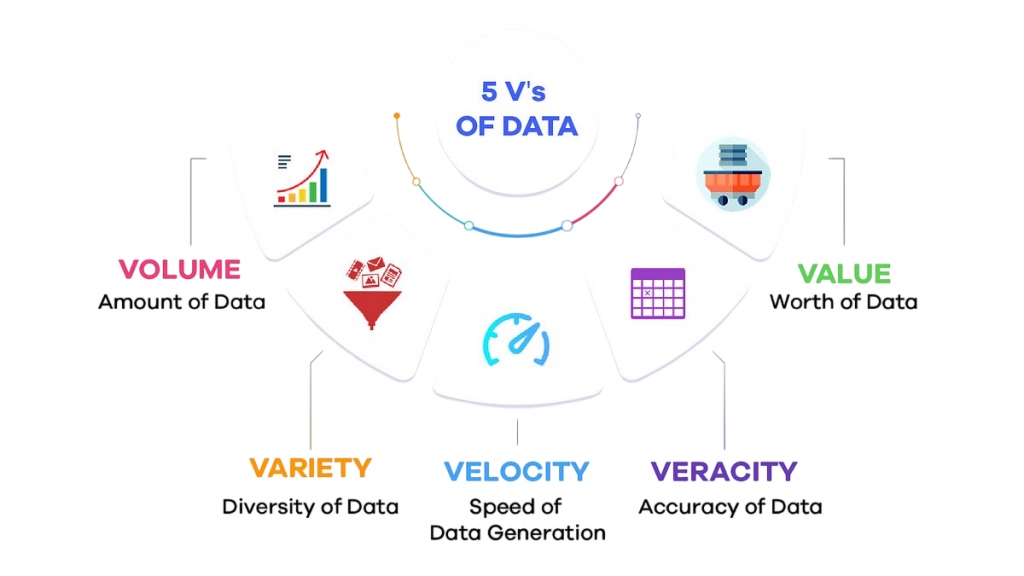
- Volume: Refers to the vast amounts of data generated every second.
- Velocity: The speed at which new data is generated and needs to be processed.
- Variety: Includes different types of data: text, video, images, logs, and more.
- Veracity: Refers to the uncertainty or trustworthiness of the data.
- Value: Means the meaningful insights derived from Big Data analytics.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Milestones in Big Data Development
These milestones show the technology’s growth and wider enterprise use. With advancements in computing infrastructure, cloud environments, and real-time stream processing, the reach and influence of Big Data keeps expanding.
- 2004: Google publishes the MapReduce paper.
- 2005: Launch of Hadoop as an open-source project.
- 2006: Amazon Web Services introduces cloud storage.
- 2009: Emergence of NoSQL databases like Cassandra and MongoDB.
- 2013: Apache Spark becomes a preferred Big Data processing engine.
- 2020 and beyond: Rise of real-time analytics and cloud-native data platforms.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Key Technologies (Hadoop, Spark, etc.)
These technologies form the foundation of modern data pipelines, supporting analytics on both real-time and historical data. Their integration creates a complete ecosystem that powers machine learning, business intelligence, and operational systems.
- Apache Hadoop: A framework for distributed storage and processing using MapReduce and HDFS.
- Apache Spark: An in-memory data processing engine suitable for real-time and batch analytics.
- Kafka: A distributed event streaming platform for creating real-time data pipelines.
- Hive & Pig: Tools for querying and analyzing large datasets with SQL-like syntax.
- NoSQL Databases: MongoDB, Cassandra, and HBase provide scalable data storage for unstructured data.

Industry Adoption
Each industry tailors its Big Data strategy to extract insights and improve operations. For instance, predictive models in healthcare can save lives, while real-time fraud analytics in finance protect billions in assets.
- Retail: Personalization and inventory forecasting.
- Healthcare: Predictive diagnostics and patient record analysis.
- Finance: Fraud detection and customer behavior analysis.
- Manufacturing: Predictive maintenance and supply chain optimization.
- Government: Policy planning and crime analysis.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Success Stories
These companies illustrate how Big Data Hadoop Certification Training can enhance customer experience, lower operational costs, and stimulate business innovation.
- Netflix: Uses Big Data to make content recommendations and create original programming based on viewing habits.
- Amazon: Optimizes its supply chain and improves customer experiences through data-driven decisions.
- Walmart: Employs real-time inventory tracking and dynamic pricing models.
- UPS: Optimizes routes, saving millions in fuel and improving delivery times.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Common Challenges
Addressing these challenges requires a mix of technological innovation, skilled professionals, and clear organizational strategy.

- Data Silos: Fragmented data systems hinder unified analysis.
- Data Quality: Inaccurate or inconsistent data can lead to incorrect insights.
- Talent Gap: There is a shortage of skilled data engineers and scientists.
- Security & Privacy: Handling large-scale sensitive data needs strong security measures.
- Scalability Costs: Managing infrastructure for petabyte-scale data can be costly.
Current Trends
Businesses are increasingly focusing on agile, accessible, and intelligent data solutions. Making data insights available empowers teams to make quicker, insight-driven decisions.
- Real-Time Analytics: Making decisions at the speed of business.
- Data as a Service (DaaS): Cloud-based data storage and processing.
- AI/ML Integration: Using Big Data to train machine learning models.
- Edge Computing: Processing data closer to where it is generated.
- Data Democratization: Makes data insights accessible to non-technical users.
Role of AI and ML in Big Data
Artificial Intelligence and Machine Learning rely heavily on data. Big Data provides the necessary resources to train, validate, and improve complex algorithms. From fraud detection and recommendation engines to language translation and autonomous vehicles, AI/ML applications gain significant advantages from the scale and diversity of Big Data.
- Training and Validation: Large datasets are essential for building accurate and reliable AI models.
- Application Domains: AI/ML is used in fraud detection, recommendation systems, language translation, and autonomous technologies.
- Automation: Big Data enables automated data cleansing, feature selection, and model tuning.
- Emerging Models: Generative AI and reinforcement learning require vast and varied data inputs.
This creates a mutual relationship between AI development and Big Data capabilities, driving innovation and expanding possibilities.
Future Outlook
The future of Big Data involves its merging with yarn technologies like quantum computing, AI, blockchain, and IoT. We are moving toward decentralized data ecosystems, greater focus on ethical data use, and self-service analytics platforms. Data governance, real-time insights, and personalized user experiences will continue to drive innovation. Big Data is no longer just about managing information; it’s about unlocking its real potential to change the world. From autonomous systems and smart cities to personalized healthcare and environmental conservation, the data revolution is central to the digital future.
Understanding Hadoop Technology Before Hadoop Download
Before downloading Hadoop, it’s important to grasp its underlying architecture and why it is a key tool in Big Data processing.
- Distributed Storage: Hadoop uses HDFS (Hadoop Distributed File System) to store large datasets across multiple machines.
- Parallel Processing: The MapReduce programming model enables efficient data processing by distributing tasks across nodes.
- Scalability: Hadoop can scale horizontally by adding more nodes to handle growing data volumes.
- Fault Tolerance: Built-in mechanisms ensure data reliability even if individual nodes fail.
- Open Source Ecosystem: Hadoop integrates with tools like Hive, Pig, and Spark, making it versatile for various data tasks.
What is Hadoop?
Hadoop is an open-source framework that permits distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale from a single server to thousands of machines, providing fault tolerance and data redundancy.
- Distributed Processing: Executes tasks across multiple machines for faster and mohair scalable computation.
- Simple Programming Models: Uses MapReduce to simplify parallel data processing.
- Scalability: Easily expands from a single node to thousands of servers.
- Fault Tolerance: Automatically recovers from node failures without data loss.
- Data Redundancy: Stores multiple copies of data to ensure reliability and availability.
Need for Hadoop in Big Data
Traditional systems struggled with the volume and speed of modern data. Hadoop provided a solution by distributing both data storage and processing. This allows organizations to manage large amounts of data effectively.
Hadoop Ecosystem Overview
Hadoop is not just a single tool. It consists of:
- HDFS (Hadoop Distributed File System): Stores data across multiple nodes.
- Chunky knit blanket yarn(Yet Another Resource Negotiator): Manages computing resources.
- MapReduce: The programming model for data processing.
- Hive: Enables SQL-like queries for large datasets.
- Pig: A data flow language for analyzing large data sets.
- HBase: A columnar database for real-time read/write access.
- Flume: Facilitates data ingestion from various sources.
- Sqoop: Handles data import and export between Hadoop and relational databases.
Key Components
- HDFS: Manages data storage with replication.
- MapReduce: Processes large data sets simultaneously.
- Fingering weight cotton yarn: Allocates resources efficiently to applications.
Hadoop Distributions (CDH, HDP, etc.)
Various vendors provide their own Hadoop distributions, each offering unique features and strengths tailored to different enterprise needs.
- Cloudera (CDH): Secure enterprise-grade tools with many features.
- Hortonworks (hdp): Focuses on open-source and community-driven support.
- MapR: Known for high performance and real-time capabilities.
Conclusion
Big Data has become an essential part of modern enterprise strategy. With tools like Hadoop and Spark, companies can store, process, and extract value from massive datasets. Understanding the tech landscape before downloading and installing tools leads to better decisions and successful implementation. The future is undoubtedly data-driven, and those who master Big Data Hadoop Certification Training technologies will lead in innovation.




