
Last updated on 06th Nov 2025| 12717
- Getting Started with Machine Learning
- Probability and Statistics
- Linear and Logistic Regression
- Supervised and Unsupervised Learning
- Decision Trees and Ensemble Methods
- Neural Networks and Deep Learning
- Natural Language Processing
- Model Evaluation and Validation
- Clustering Techniques
- Conclusion
Getting Started with ML
Machine Learning (ML) is a subfield of artificial intelligence (AI) that empowers computers to learn from data and improve over time without being explicitly programmed. By detecting patterns and learning from past experiences, ML models can make predictions, automate decisions, and uncover insights across domains such as healthcare, finance, marketing, and more. Machine learning (ML) is broadly categorized into supervised, unsupervised, semi-supervised, and reinforcement learning. These categories form the foundation of Machine learning training and determine the approach used to develop models based on the nature of the data and the problem at hand. The choice of method depends on the problem, available data, and desired outcome. Modern technology now relies heavily on machine learning, which powers everything from self-driving cars to recommendation systems on e-commerce sites. Its capacity to extract significant patterns from massive datasets which are frequently obscured by noise or complexity and use them to address practical issues is the secret to its efficacy.
Probability and Statistics
Probability and statistics form the mathematical foundation of machine learning. They help quantify uncertainty, describe data distributions, and form the basis for many algorithms used in Machine Learning Techniques. Understanding these concepts is crucial for designing and evaluating models, as they influence how algorithms interpret data and make predictions.
- Key Concepts:
- Probability: Measures the likelihood of events.
- Conditional Probability: P(A∣B)P(A|B) – the probability of A occurring given B.
- Bayes’ Theorem: P(A∣B)=P(B∣A)⋅P(A)P(B)P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} – critical for algorithms like Naive Bayes.
- Distributions: Normal, Bernoulli, Binomial, Poisson, etc.
- Descriptive Statistics: Mean, median, mode, variance, standard deviation.
- Inferential Statistics: Hypothesis testing, confidence intervals, p-values.
These concepts guide data interpretation and help build reliable models.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Linear and Logistic Regression
Linear RegressionUsed for predicting a continuous outcome based on one or more predictors.
- y=β0+β1x+εy = \beta_0 + \beta_1 x + \varepsilon
It fits a line to minimize the difference between predicted and actual values (often via least squares).
Logistic RegressionUsed for binary classification (e.g., spam vs not spam). It uses the logistic (sigmoid) function to predict probabilities:
- P(y=1)=11+e−(β0+β1x)P(y=1) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x)}}
These models are easy to interpret and form the building blocks for more complex algorithms.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Supervised and Unsupervised Learning
- Supervised Learning
- Data has input-output pairs.
- The model learns a mapping function.
- Examples: Classification (e.g., SVM, Decision Trees), Regression (e.g., Linear, Ridge). Unsupervised Learning
- No labels provided; the model discovers hidden patterns.
- Examples: Clustering (K-Means), Dimensionality Reduction (PCA), Association Rules.
- Activation Functions: ReLU, Sigmoid, Tanh.
- Loss Functions: Cross-entropy, MSE.
- Backpropagation: Algorithm to update weights using gradients.
- Accuracy: Correct predictions / Total predictions.
- Precision & Recall: Useful for imbalanced datasets.
- F1 Score: Harmonic mean of precision and recall.
- Confusion Matrix: Visual representation of prediction vs actual. Regression Metrics:
- MSE (Mean Squared Error), RMSE, MAE.
- Normalization/Standardization: Rescales data for uniformity.
- Binning: Converts numerical variables into categorical.
- Polynomial Features: Adds interaction terms.
- Encoding: One-hot encoding for categorical variables.
- Dimensionality Reduction: PCA, t-SNE to reduce feature space.
Supervised learning is dominant in practical applications, but unsupervised learning is key for data exploration and pattern discovery. What is Logistic Regression? It is a supervised learning algorithm used for binary classification, where the output is a probability that is mapped to two classes, making it useful for tasks like spam detection, medical diagnosis, and more.
Decision Trees and Ensemble Methods
A model that resembles a flowchart and divides data according to feature thresholds is called a decision tree. They offer lucid insights into the decision-making process and are simple to understand. Nevertheless, decision trees are susceptible to overfitting, particularly when they become deep and pick up on data noise.
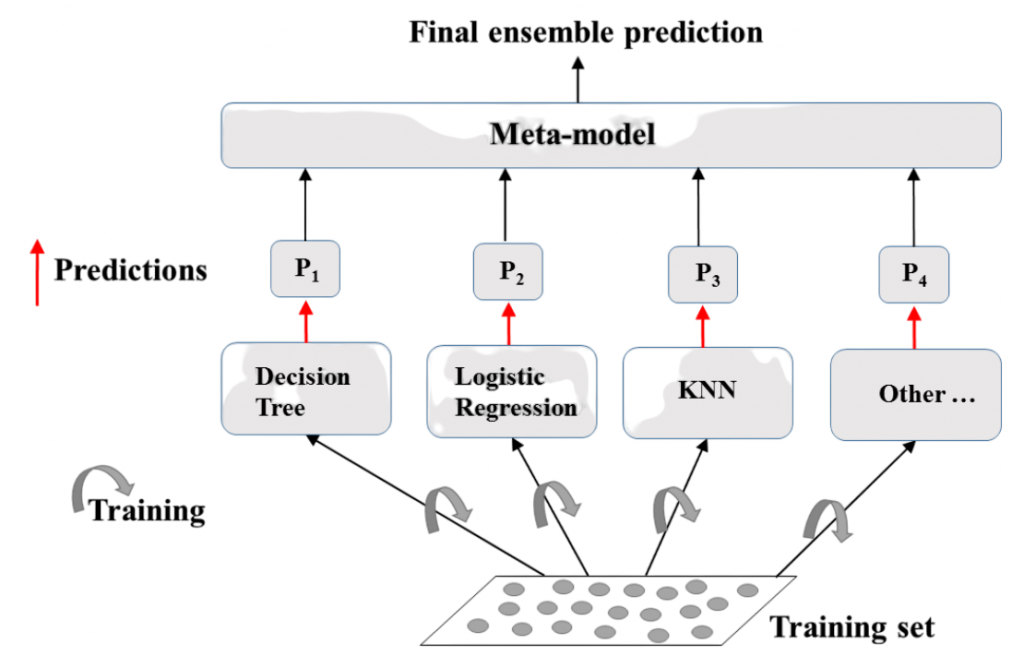
By merging several models, ensemble methods seek to enhance model performance. For instance, Random Forest uses bagging to combine several decision trees, which lowers volatility and boosts stability. This technique is part of Bagging vs Boosting in Machine Learning where bagging focuses on reducing variance by training multiple models independently and then averaging their predictions, while boosting focuses on reducing bias by training models sequentially and adjusting based on previous errors. Gradient Boosting, which includes well-known implementations like XGBoost, reduces bias by building trees one after the other while concentrating on minimising the errors of the prior model.

Neural Networks and Deep Learning
Neural NetworksInspired by the human brain, they consist of interconnected nodes (neurons) across input, hidden, and output layers. This architecture is commonly used in Support Vector Machine (SVM) models, where the goal is to find a hyperplane that best separates different classes in the feature space. While neural networks aim to model complex, non-linear relationships, SVM focuses on maximizing the margin between classes for better generalization.
Deep LearningRefers to neural networks with many hidden layers.
Deep learning is the driver behind breakthroughs in computer vision, speech recognition, and NLP.
Natural Language Processing
Machines can comprehend, analyse, and produce human language thanks to Natural Language Processing (NLP). It includes a number of fundamental tasks, such as named entity recognition (NER), which identifies entities like people, locations, and organisations, and text classification, which is utilised for applications like sentiment analysis and spam detection. Additionally, NLP underpins text generation, which entails producing new text using language models like LSTMs or Transformers, and machine translation, which enables programs like Google Translate to translate text between languages. Machine learning training plays a critical role in improving these NLP tasks by fine-tuning models for more accurate predictions and translations. Text data frequently needs preprocessing, such as tokenization, stopword removal, and stemming or lemmatization to standardise the content, before these tasks are applied. Well-known libraries like spaCy, NLTK, Transformers, and Gensim offer powerful capabilities for a variety of NLP applications to make these procedures easier.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Model Evaluation and Validation
Evaluating model performance is crucial to avoid overfitting and ensure generalization.
- Classification Metrics:
Clustering Techniques
A machine learning technique called clustering puts related data points together without the need for pre-established labels. For this reason, a number of well-known algorithms are frequently employed. K-Means is effective for huge datasets because it splits data into K clusters by minimizing the variance within each cluster. Similarly, Naive Bayes Theorem is widely used in classification problems, especially when the data is categorical. While K-Means groups data based on distance and similarity, Naive Bayes applies probabilistic principles to predict the likelihood of a class given a set of features, making it a powerful tool for text classification, such as spam detection. DBSCAN is a density-based clustering technique that uses data point density to find clusters of different sizes and shapes. A dendrogram, a tree-like structure created by hierarchical clustering, depicts nested groups and their connections.
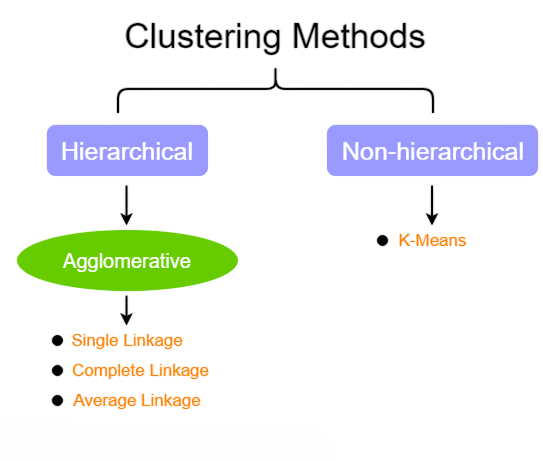
Organisations can find patterns and insights from unlabeled data by using clustering algorithms, which are frequently used in fields like customer segmentation, social network analysis, and anomaly detection.
Feature Engineering
- Techniques:
Good features often outperform complex algorithms. This step is critical in the ML pipeline.
ML Tools and Libraries
The creation of machine learning applications is aided by a variety of tools and libraries. One such tool is Splunk Security ML which is specifically designed to help with security analytics using machine learning. It leverages advanced ML algorithms to detect anomalies, identify potential threats, and analyze large volumes of security data. This is particularly useful in industries where data security is paramount, allowing businesses to proactively respond to security incidents and reduce risks. R is still widely used in academics and for statistical research, but Python is the most popular programming language because of its extensive library and framework ecosystem. Important libraries include PyTorch, which is popular in deep learning projects and research-friendly, TensorFlow and Keras for deep learning, and Scikit-learn for conventional machine learning techniques. Libraries like XGBoost and LightGBM allow gradient boosting techniques, while Pandas and NumPy facilitate data handling and processing.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Conclusion
The way that technology interacts with data and affects decision-making is being revolutionised by machine learning (ML). ML offers a variety of methods that assist us in comprehending, forecasting, and automating processes, ranging from the ease of linear regression to the intricacy of deep learning. A solid background in statistics and mathematics, competence with programming and other machine learning tools, and an inquisitive, iterative approach to problem-solving are all necessary for success in this subject. Machine learning training helps to develop these skills by providing hands-on experience with real-world datasets and algorithms, enabling learners to apply theoretical knowledge to practical challenges. Machine learning gives you the ability to transform unprocessed data into actionable insight, whether you’re creating a model to identify illnesses, streamline operations, or address practical problems. You can use machine learning (ML) to create better educated, data-driven judgements by continuously learning and improving methodologies.

