
Last updated on 13th Oct 2025| 12938
- ML with Python
- Installing Required Packages
- Understanding Pandas and NumPy
- Building ML Models
- Model Evaluation Metrics
- Hyperparameter Tuning
- Using Scikit-Learn
- Real-World Examples
- Model Deployment
- Summary
ML with Python
Machine Learning in Python enables computers to find patterns in data and make decisions without needing extensive programming. Python is the go-to language for ML because of its clear syntax, which allows for quick prototyping. Users gain a lot from a well-developed set of libraries, including NumPy for numerical calculations, Pandas for data manipulation, Matplotlib for data visualization, and Scikit-learn for various machine learning methods. To master these tools and apply them in real-world scenarios, explore Machine Learning Training a hands-on program designed to build core competencies in data modeling, algorithm design, and predictive analytics. These tools simplify the development process and improve productivity. Additionally, Python works well with deep learning frameworks like TensorFlow and PyTorch, making it a great choice for creating complex models. The power of Machine Learning in Python lies in its flexibility, it supports the entire ML workflow, from data extraction to modeling and deployment. Typical uses of Machine Learning in Python include making predictions based on data, such as sales forecasting, classification tasks like spam detection and image recognition, recommendation systems that improve user experiences, spotting anomalies to find unusual patterns, and Natural Language Processing (NLP) for understanding and managing human language.
Installing Required Packages
Create an isolated environment to manage dependencies: this ensures reproducibility and prevents conflicts across projects. To decide which framework best suits your workflow, explore Keras vs TensorFlow a detailed comparison that breaks down architecture, ease of use, performance, and real-world applications for both deep learning libraries.
- python3 -m venv ml-env
- source ml-env/bin/activate
- conda create -n ml-env python=3.10
- conda activate ml-env
Install key packages: pip install numpy pandas matplotlib seaborn scikit-learn jupyter
- numpy: numerical computing
- pandas: data manipulation and analysis
- matplotlib/seaborn: visualization
- scikit-learn: main ML library
- jupyter: interactive exploration
- black: code formatter
- mypy: type checking
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Understanding Pandas and NumPy
NumPy
Core library providing ndarray, efficient multi-dimensional arrays. Supports vectorized operations for speed. To see how these capabilities integrate into scalable cloud workflows, explore Overview of ML on AWS a practical guide that explains how AWS services support data preprocessing, model training, and deployment at scale using powerful libraries and infrastructure.
- import numpy as np
- a = np.array([1, 2, 3])
- b = np.arange(4)
- print(a * 2, b + a[:3])
Pandas
Built on NumPy, introducing DataFrames (tabular data) and Series. Common use cases:
- import pandas as pd
- df = pd.read_csv(“data.csv”)
- print(df.shape, df.head(), df.describe(), df.info())
- print(df[“feature”].value_counts(), df[“target”].mean())
Use .loc for label-based indexing and .iloc for position-based selection. Supports filtering, grouping, merging, and pivoting for data manipulation.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Building ML Models
Common classifiers:
- LogisticRegression: Used for binary and multi-class classification problems.
- DecisionTreeClassifier: Builds a tree structure to classify data based on feature splits.
- RandomForestClassifier: An ensemble of decision trees that improves accuracy and reduces overfitting.
- SVC: Support Vector Classifier, effective for high-dimensional spaces and margin-based classification.
- KNeighborsClassifier: Classifies based on the majority label among nearest neighbors.
- GradientBoostingClassifier: Builds an ensemble of weak learners in sequence to improve performance.
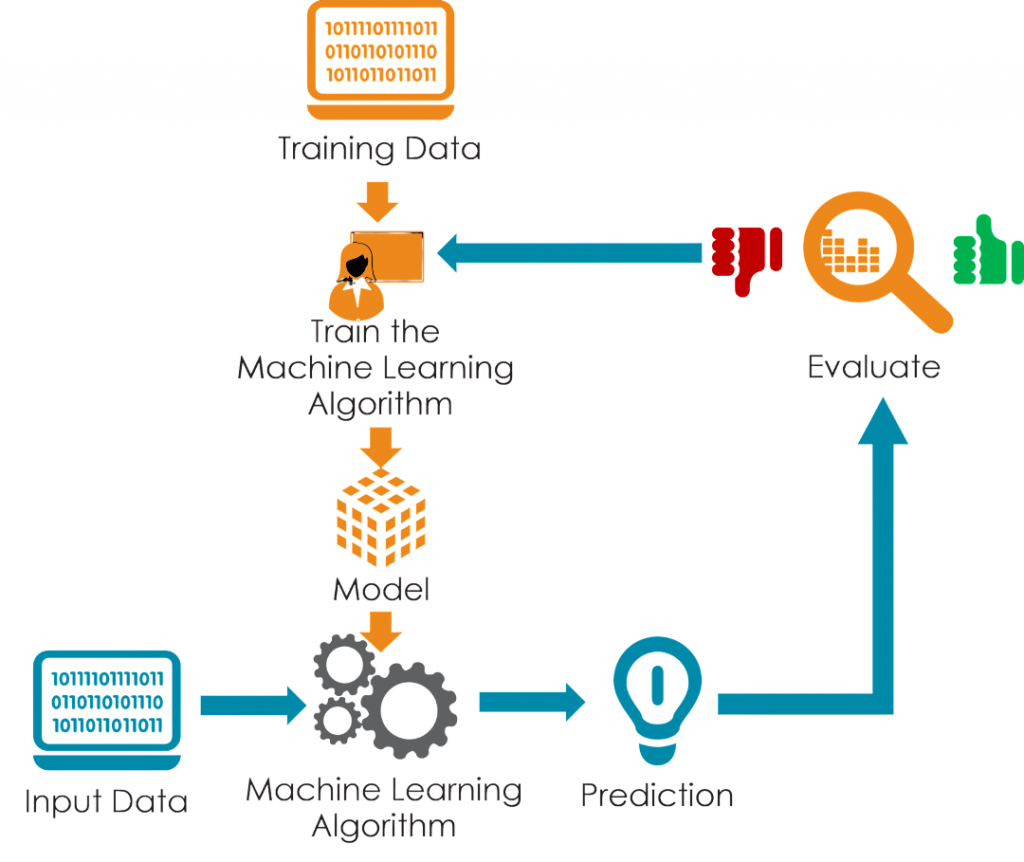
Common regressors:
- LinearRegression: Models the relationship between features and a continuous target variable.
- Ridge: Linear regression with L2 regularization to prevent overfitting.
- Lasso: Linear regression with L1 regularization for feature selection.
- DecisionTreeRegressor: Predicts continuous values using a tree-based structure.
- RandomForestRegressor: An ensemble of decision trees for regression tasks, improving accuracy and robustness.
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier(n_estimators=100, random_state=42)
- model.fit(X_train, y_train)
- from sklearn.pipeline import Pipeline
- pipe = Pipeline([
- (‘scaler’, StandardScaler()),
- (‘clf’, RandomForestClassifier(random_state=42))
- ])
- pipe.fit(X_train, y_train)
- from sklearn.model_selection import cross_val_score
- scores = cross_val_score(pipe, X_train, y_train, cv=5, scoring=’accuracy’)
- print(“CV accuracy:”, scores.mean())

Model Evaluation Metrics
Classification Metrics:
- Accuracy: Measures the proportion of correct predictions out of all predictions.
- Precision: Measures how many predicted positives are actually positive.
- Recall: Measures how many actual positives were correctly predicted.
- from sklearn.metrics import classification_report, roc_auc_score
- y_pred = pipe.predict(X_test)
- print(classification_report(y_test, y_pred))
- print(“ROC AUC:”, roc_auc_score(y_test, pipe.predict_proba(X_test)[:,1]))
- from sklearn.metrics import mean_squared_error, r2_score
- y_pred = pipe.predict(X_test)
- print(“RMSE:”, mean_squared_error(y_test, y_pred)**0.5)
- print(“R2:”, r2_score(y_test, y_pred))
Use cross-validation scores with metrics to validate model stability.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
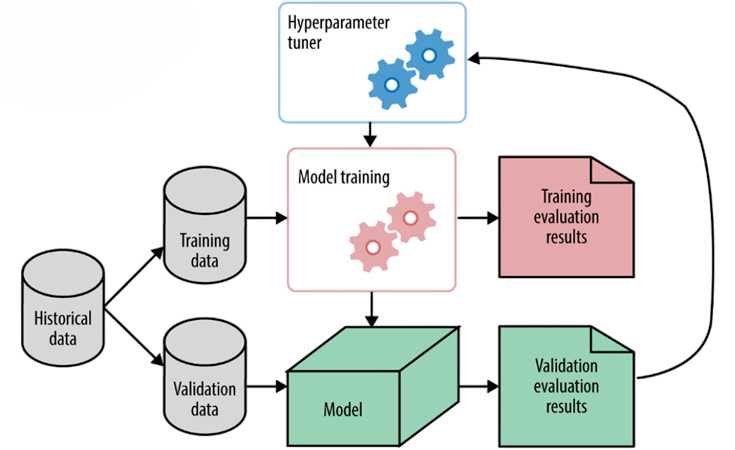
Hyperparameter Tuning
Optimize model performance on validation data:
- from sklearn.model_selection import GridSearchCV
- param_grid = {
- ‘clf__n_estimators’: [50, 100, 200],
- ‘clf__max_depth’: [None, 5, 10]
- }
- grid = GridSearchCV(pipe, param_grid, cv=5, scoring=’accuracy’)
- grid.fit(X_train, y_train)
- print(grid.best_params_, grid.best_score_)
- from sklearn.model_selection import RandomizedSearchCV
- param_dist = {‘clf__n_estimators’: [50,100,200,500], ‘clf__max_depth’: [None,5,10,20]}
- rand = RandomizedSearchCV(pipe, param_dist, n_iter=10, cv=5)
- rand.fit(X_train, y_train)
- print(rand.best_params_, rand.best_score_)
Nested cross-validation ensures unbiased performance while tuning.
Using Scikit-Learn
Scikit-Learn is a complete solution for standard machine learning tasks. It is designed to make the process easier for users. At its core, it has a consistent estimator API that simplifies fitting, predicting, and transforming data. This straightforward approach helps users focus on creating effective models without getting overwhelmed by complicated interfaces. Scikit-Learn also provides a variety of built-in transformers and selectors, which can greatly improve data preprocessing. To explore more resources like this, dive into Machine Learning Tools that highlights essential libraries, frameworks, and utilities for building scalable, production-ready AI solutions. Its pipelines allow for smooth chaining of these steps, ensuring a seamless workflow from start to finish. Additionally, Scikit-Learn works well with various visualization tools and feature selection methods, helping users analyze their data more effectively. For those wanting to expand their modeling options, Scikit-Learn is very flexible.
- from sklearn.ensemble import StackingClassifier
- estimators = [
- (‘rf’, RandomForestClassifier(n_estimators=100)),
- (‘knn’, KNeighborsClassifier())
- ]
- stack = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
- stack.fit(X_train, y_train)
- print(“Stacking accuracy:”, stack.score(X_test, y_test))
Scikit-learn’s documentation includes many user-friendly examples and relevant datasets like Iris, Boston, MNIST.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Real-World Examples
In the Several methodologies have been developed to address different challenges across various domains. For instance, housing price prediction utilizing the Boston dataset involves a comprehensive regression pipeline that initiates with preprocessing the data, followed by feature selection, and culminating in the application of a suitable model to forecast property values. In contrast, customer churn prediction focuses on classification through user metrics, which begins with data preprocessing, progresses to employing a Random Forest model, and concludes with a thorough evaluation of the results. Similarly, spam detection is approached by processing text emails using the TF-IDF method, followed by the application of either logistic regression or support vector machines (SVM) to classify the emails effectively. Additionally, credit card fraud detection tackles the issue of class imbalance through specialized handling techniques, feature scaling, and utilizes a Random Forest model, with evaluation metrics based on the ROC-AUC score to gauge performance. In the field of image classification, particularly for digit recognition using the MNIST dataset, the process starts with flattening the image pixels, followed by applying various classifiers to accurately identify the digits. Walkthroughs can include: dataset download, pipeline build, evaluation, report, and model export. To deepen your understanding of these workflows and the theory behind them, explore Deep Learning Books collection that covers neural architectures, optimization strategies, and real-world deployment techniques for aspiring AI practitioners.
Model Deployment
Move from notebook to production via: robust data pipelines, scalable model deployment, and continuous performance monitoring. To master the techniques that make this transition seamless, explore Machine Learning Algorithms guide that breaks down essential models, their use cases, and how they power real-world AI systems.
- import joblib
- joblib.dump(grid.best_estimator_, ‘model.pkl’)
- model = joblib.load(‘model.pkl’)
- from fastapi import FastAPI
- import joblib, pandas as pd
- app = FastAPI()
- model = joblib.load(‘model.pkl’)
- @app.post(“/predict”)
- def predict(data: dict):
- df = pd.DataFrame([data])
- pred = model.predict(df)
- return {“prediction”: pred.tolist()}
- FROM python:3.10-slim
- WORKDIR /app
- COPY requirements.txt .
- RUN pip install -r requirements.txt
- COPY . .
- CMD [“uvicorn”, “app:app”, “–host”, “0.0.0.0”, “–port”, “80”]
- Cloud services: AWS SageMaker, GCP AI Platform, Azure ML
- Serverless APIs via AWS Lambda, GCP Cloud Functions
- Batch pipelines with Airflow / Prefect
Model monitoring and versioning are essential tools like MLflow, DVC, or TensorBoard help.
Summary
This guide on Machine Learning in Python offers a practical overview of machine learning, covering everything from setting up your environment to deployment strategies. It starts with key libraries like Pandas and NumPy, which help with data handling. You’ll learn how to preprocess your data and do exploratory data analysis (EDA) to find patterns and insights. The guide introduces machine learning pipelines, focusing on model building, evaluation, and techniques like hyperparameter tuning to ensure your models work well in real-world situations. To apply these techniques with confidence, explore Machine Learning Training a hands-on program that teaches data preprocessing, pipeline design, and model optimization for production-ready AI solutions. Key practices include keeping a reproducible environment, using DataFrame pipelines to prevent data leakage, and cross-validating your models for thorough validation.

