
Last updated on 11th Aug 2025| 12539
- Definition of Supervised Learning
- Key Concepts: Input and Output Pairs
- Types: Classification and Regression
- Common Algorithms
- Training and Testing Process
- Evaluation Metrics
- Real-World Applications
- Advantages of Supervised Learning
- Limitations and Challenges
- Code Examples
- Summary
Definition of Supervised Learning
Supervised learning is a branch of machine learning where models are trained using labeled datasets. That means each input comes with a corresponding output, and the model learns to map the input to the correct output by minimizing the difference between its predictions and actual values. Machine Learning Training covers supervised learning techniques in depth, enabling learners to build accurate models for classification, regression, and forecasting tasks. For example, if you’re training a model to classify emails as spam or not spam, each email (input) in the training dataset is already labeled as spam or not (output). The model learns to recognize patterns and relationships in the data to predict labels for new, unseen emails.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Key Concepts: Input and Output Pairs
In supervised learning, the main goal is to create a predictive function f that connects input features X, such as height, weight, or pixel values, to corresponding output labels Y, like classification categories or numerical predictions. This process includes training a model on historical data, where pairs of input-output examples serve as the foundation. The main principle allows the algorithm to identify patterns and relationships within the data. To complement this learning framework with a foundational classification technique, exploring What is Logistic Regression reveals how the sigmoid function transforms linear combinations into probabilities enabling binary and multiclass predictions with high interpretability, efficient training, and broad applications across domains like healthcare, marketing, and finance. This helps it generalize and make accurate predictions for new, unseen inputs. The model’s performance depends greatly on the quality and variety of the labeled training data. Typically, more diverse and representative datasets lead to stronger and more reliable predictive abilities.
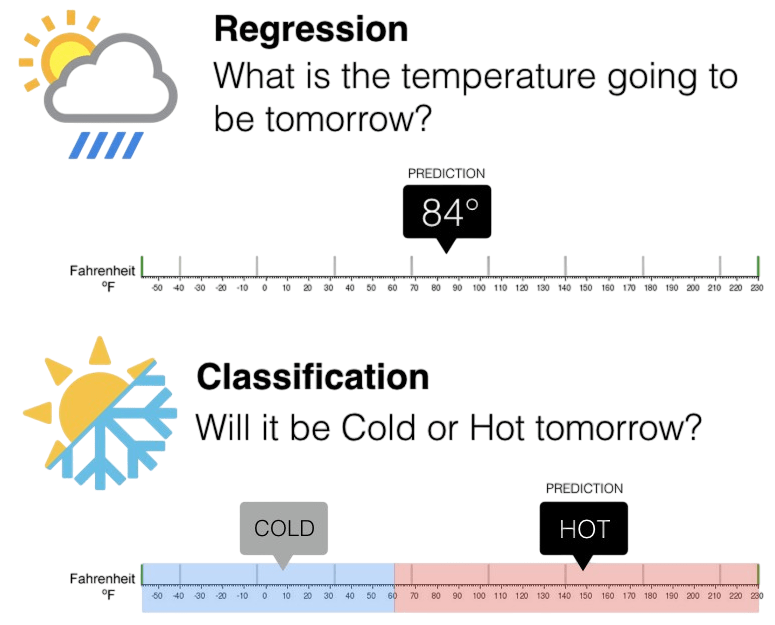
Types: Classification and Regression
- Classification: Used when the output is categorical (discrete values).
- Algorithms: Logistic Regression, Decision Trees, Random Forest, SVM, k-NN.
- Regression: Used when the output is continuous (numerical values).
- Examples: Predicting house prices, stock prices, or temperature.
- Algorithms: Linear Regression, Ridge Regression, Lasso, SVR.
Common Algorithms
- Linear Regression: A basic regression algorithm that models the relationship between one or more features and a continuous target.
- To complement this approach with a more robust and margin-based technique, exploring Support Vector Machine (SVM) Algorithm reveals how SVMs can handle both classification and regression tasks by constructing optimal hyperplanes maximizing separation between classes or minimizing error in continuous predictions using kernel tricks and support vectors.
- Logistic Regression: A classification algorithm that predicts probabilities and uses a threshold to classify inputs.
- Decision Trees: Hierarchical models that split data based on feature values to reach a decision (output).
- Support Vector Machines (SVM): Powerful classifiers that find the optimal boundary (hyperplane) between different classes.
- k-Nearest Neighbors (k-NN): A non-parametric algorithm that classifies based on the majority label among the k closest data points.
- Random Forest: An ensemble method that builds multiple decision trees and aggregates their outputs.
- Finance: Credit scoring, stock price prediction, fraud detection.
- Healthcare: Disease diagnosis, patient risk prediction, medical imaging.
- Retail: Customer segmentation, recommendation systems, and predictive analytics are just a few examples of how intelligent algorithms transform raw data into actionable insights.
- To complement these applications with foundational understanding, exploring What Is Machine Learning reveals how supervised and unsupervised techniques like regression, classification, and clustering enable systems to learn from historical data, adapt to patterns, and automate decision-making across industries.
- Education: Student performance prediction, personalized learning.
- Manufacturing: Predictive maintenance, quality control.
- Marketing: Churn prediction, lead scoring.
- High Accuracy: Especially with large and high-quality labeled datasets.
- Versatility: Applies to both regression and classification problems.
- Interpretability: Many models (like linear regression and decision trees) are easy to interpret.
- Transferability: Models trained in one domain (e.g., sentiment analysis) can often be adapted to similar tasks.
- Requires Labeled Data: Gathering and labeling large datasets is time-consuming and expensive.
- Overfitting: Model learns the noise in training data, performing poorly on new data.
- Underfitting: The model is too simplistic to capture data patterns.
- Bias in Data: Can lead to biased predictions and unfair outcomes.
- Not Ideal for Unstructured Problems: Doesn’t perform well without clear input-output mappings.
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import accuracy_score
- # Load dataset
- iris = load_iris()
- X, y = iris.data, iris.target
- # Split data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- # Train model
- model = RandomForestClassifier()
- model.fit(X_train, y_train)
- # Predict
- y_pred = model.predict(X_test)
- # Evaluate
- print(“Accuracy:”, accuracy_score(y_test, y_pred))
- from sklearn.datasets import load_boston
- from sklearn.linear_model import LinearRegression
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import mean_squared_error
- # Load dataset
- boston = load_boston()
- X, y = boston.data, boston.target
- # Split data
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- # Train model
- model = LinearRegression()
- model.fit(X_train, y_train)
- # Predict
- y_pred = model.predict(X_test)
- # Evaluate
- print(“MSE:”, mean_squared_error(y_test, y_pred))
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Training and Testing Process
In machine learning model development, researchers carefully split datasets to ensure strong and trustworthy performance. They usually assign 70 to 80% of the available data for the training and testing process and set aside 20 to 30%, which creates a balanced method for evaluating the model. Cross-validation improves this process by dividing the data into several folds, providing a better assessment of model performance. Machine Learning Training teaches best practices for model evaluation, including cross-validation techniques that enhance reliability and generalization. During model training, researchers input pairs of data into the algorithm, allowing it to adjust its internal settings and reduce prediction errors. In the following testing phase, they check the model’s performance with new data, which is essential for understanding how well it can generalize and perform in real-world situations. Training and Testing Process plan helps keep machine learning models precise in their training environment and flexible and dependable when facing new, varied datasets.

Evaluation Metrics
In machine learning model evaluation metrics, several key metrics give insights into performance for classification and regression tasks. For classification problems, accuracy measures how many samples were correctly classified. Precision calculates the ratio of true positives to total positive predictions. To complement these evaluation metrics with a structured diagnostic tool, exploring What is a Confusion Matrix in Machine Learning reveals how this matrix organizes predictions into true positives, true negatives, false positives, and false negatives offering a granular view of model performance and guiding improvements in classification accuracy, recall, and F1-score. Recall, or sensitivity, checks the model’s ability to identify all relevant instances. The F1 score balances precision and recall. The confusion matrix shows true versus predicted classifications in detail.
In regression analysis, performance metrics like Mean Absolute Error (MAE) measure the average absolute differences between predictions and actual values. Mean Squared Error (MSE) highlights larger errors by using squared differences. The Root Mean Squared Error (RMSE) standardizes the measure of model deviation. The R² score shows the model’s explanatory power by indicating how well it captures the variability of the target variable.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Real-World Applications
Advantages of Supervised Learning
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Limitations and Challenges
Code Examples (Python + Scikit-learn)
Classification Example: Iris Dataset. This dataset is widely used to demonstrate supervised learning techniques due to its well-labeled structure and balanced class distribution. To complement such examples with ensemble learning strategies, exploring Bagging vs Boosting reveals how bagging reduces variance by training models independently on random subsets, while boosting reduces bias by sequentially correcting errors both enhancing classification accuracy and robustness when applied to datasets like Iris.
Regression Example: Boston Housing Dataset
Summary
Supervised learning is a cornerstone of modern AI, enabling machines to learn from historical data to make future predictions. By understanding its type classification and regression you can tackle a wide variety of practical problems across industries. Machine Learning Training equips learners to apply the right modeling approach based on problem type, data characteristics, and business objectives. While powerful, supervised learning does come with challenges, particularly the reliance on labeled data and risk of overfitting. Equipped with the right knowledge, tools like Scikit-learn, and a few starter projects, you’re well on your way to mastering supervised learning. Whether you’re building spam filters, medical diagnostic tools, or stock price predictors, the principles of supervised learning will remain at the heart of your solutions.

