
Last updated on 09th Aug 2025| 12064
- Introduction to Deep Learning
- Differences Between ML and DL
- Neural Network Architecture
- Activation Functions
- Training Deep Neural Networks
- Popular DL Frameworks
- Applications of Deep Learning
- Challenges in DL
- Future Scope
- Summary
Introduction to Deep Learning
Deep Learning (DL) is a specialized branch of Machine Learning (ML) where models use multi-layered neural networks to represent data . It mimics the brain-like processing of information working through input, multiple hidden layers, and output. These deep networks can extract hierarchical features (from edges to shapes to objects) and are at the core of modern AI capabilities. Deep learning revolutionized AI across fields like image recognition, speech processing, natural language understanding, and reinforcement learning, delivering breakthrough results from autonomous driving to medical diagnosis.Deep learning is a subset of Machine Learning Training that focuses on algorithms inspired by the structure and function of the human brain, particularly artificial neural networks. Unlike traditional machine learning, which often relies on manual feature extraction, deep learning models automatically learn hierarchical features from data. This makes them especially powerful for complex tasks such as image recognition, natural language processing, speech recognition, and autonomous driving. At the heart of deep learning are deep neural networks, which consist of multiple layers of interconnected nodes (neurons). Each layer transforms the input data into increasingly abstract representations, enabling the network to learn intricate patterns. As more data becomes available and computational power increases, deep learning has become the driving force behind many of today’s most advanced AI applications. Deep learning frameworks like TensorFlow, PyTorch, and Keras have made it easier for developers and researchers to build and train complex models. With continued innovation and real-world success, deep learning is transforming industries and pushing the boundaries of what machines can achieve.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Differences Between ML and DL
Machine Learning (ML) and Deep Learning (DL) are closely related fields within artificial intelligence, but they differ in approach, complexity, and application.
- Machine Learning relies on algorithms like decision trees, support vector machines, and linear regression, often requiring manual feature engineering.
- Deep Learning uses artificial neural networks with multiple layers (hence “deep”) to automatically learn features from raw data.
- ML models typically perform well with smaller datasets.
- DL models require large amounts of data to achieve high performance due to their complexity.
- ML can run efficiently on traditional CPUs.
- DL often requires GPUs or TPUs for accelerated computation, especially during training.
- ML models are generally easier to interpret and debug.
- DL models, while more powerful, are often considered “black boxes” due to their layered architecture.
- ML is suitable for structured data and simpler tasks.
- DL excels in tasks like image classification, speech recognition, and natural language processing, where data is unstructured and patterns are complex.
Structure and Algorithms:
Data Requirements:
Hardware Dependency:
Interpretability:
Performance on Complex Tasks:
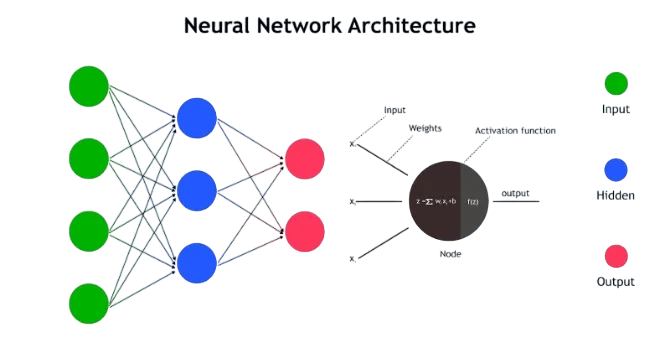
Neural Network Architecture
Neural networks are made of interconnected neurons (perceptrons) arranged in layers. Over time, architectures evolved:
- Perceptron (single layer) → MLP (one or more hidden layers; enabled by backpropagation).
- CNNs: Ideal for image tasks, learn local filters and spatial hierarchies.
- RNNs/LSTM/GRU: Designed for sequential data (text, speech) by maintaining memory.
- Transformers: Use self-attention, powering modern NLP (e.g. BERT, GPT).
- GANs: Pair generator and discriminator for data synthesis.
Deep Reinforcement Learning, Autoencoders, and hybrids add diversity.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Activation Functions
Activation functions play a vital role in neural networks by introducing non-linearity into the model, allowing it to learn and represent complex relationships in data. In essence, they determine whether a neurons should be activated or not, which directly affects how signals flow through the network and how the model learns from data. Without activation functions, even a deep network natural language with many layers would behave like a single-layer linear model, PyTorch severely limiting its capacity to capture intricate patterns. There are several types of activation functions, each with its own characteristics and ideal use cases. The ReLU (Rectified Linear Unit) is the most commonly used in hidden layers; it outputs zero for negative inputs and the input itself for positive values. ReLU is computationally efficient and helps mitigate the vanishing gradient problem, which can hinder Machine Learning Training in deep networks. However, it can suffer from the “dying ReLU” issue, where some neurons stop activating entirely. Other widely used activation functions include the Sigmoid function, which maps input values to a range between 0 and 1. It was historically popular in early neural networks, particularly in binary classification tasks, but it’s prone to causing vanishing gradients during training. The Tanh (hyperbolic tangent) function addresses some of Sigmoid’s limitations by mapping inputs between -1 and 1, PyTorch making it zero-centered and often more effective in certain scenarios. More recent alternatives like Leaky ReLU, ELU (Exponential Linear Unit), and Swish have been developed to overcome specific shortcomings of traditional activation functions. Choosing the right activation function depends on the task, Applications of deep learning model architecture, and training behavior. It is a critical design decision that can significantly influence a model’s performance, convergence speed, and overall learning capacity.

Training Deep Neural Networks
Training involves:
- Forward pass: Compute outputs.
- Backpropagation: Compute gradients.
Loss calculation (e.g., cross-entropy, MSE).
Weight updates via optimizers (SGD, Adam).
Challenges & solutions:
- Overfitting (model too complex): Mitigate using dropout, early stopping, weight decay, batch norm, data augmentation.
- Data scarcity: Use transfer learning or semi-/self-supervised strategies.
- Computational demand: Train on GPUs/TPUs; compress models via pruning, knowledge distillation, quantization.
Monitoring training via validation metrics and adjusting hyperparameters helps control bias-variance balance.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Popular DL Frameworks
Major frameworks include:
- TensorFlow (Google): Graph-based, supports CPU/GPU/TPU, serialization for production .
- PyTorch (Meta): Dynamic graphs, Pythonic, research-friendly.
- Keras: High-level wrapper over TF for fast prototyping.
- Others: MXNet, Caffe, Theano, JAX, Chainer, especially for specialized use cases .
- Computer Vision: Image classification, object detection (YOLO, Faster R-CNN), segmentation (U-Net)
- NLP: Translation, sentiment, summarization with RNNs and Transformers.
- Speech: Recognition (e.g., DeepSpeech), speaker identification.
- Autonomous systems: Self-driving cars, robotics.
- Healthcare: Imaging diagnostics, genomics.
- Finance: Fraud detection, automated trading, algorithmic strategies. Recommendation systems, anomaly detection, generative models (GANs for art, synthetic images)
- Efficient DL: Smaller, faster models via compression, pruning, and quantization.
- Self-/unsupervised learning: Reducing dependence on labeled data.
- Multimodal AI: Unified models that integrate vision, language, audio.
- Better interpretability: Increased transparency for safety‑critical domains.
- Edge AI: AI running on-device for privacy and latency.
- DL in scientific discovery: Protein folding, drug discovery, climate modeling, materials science.
- Ethical AI: Regulations and standards for fairness, accountability, and robustness.

These have diverse strengths: PyTorch for research, TensorFlow for scalable deployment, Keras for usability.
Applications of Deep Learning
DL excels in:
Challenges in DL
Despite its remarkable success across various fields, deep learning comes with several significant challenges that researchers and practitioners must address. One of the primary issues is the requirement for large amounts of labeled data, which can be expensive, time-consuming, or even impractical to obtain, especially for specialized domains. Additionally, deep learning models are computationally intensive, often requiring powerful hardware like GPUs or TPUs for training and inference, which can limit accessibility for smaller organizations or researchers. Another major challenge is the lack of interpretability. Applications of deep learning models, especially deep neural networks, often operate as “black boxes,” making it difficult to understand why a particular prediction was made. This is particularly problematic in high-stakes applications such as healthcare, finance, or law, where transparency and trust are crucial. Overfitting is also a common issue, especially when models are trained on small or noisy datasets. Without proper regularization techniques or validation, models may memorize training data rather than learn general patterns. Furthermore, deep network models can be sensitive to adversarial examples of small, carefully crafted changes to input data that can fool a model into making incorrect predictions.Lastly, the development and tuning of deep learning models require significant expertise. Choosing the right architecture, setting hyperparameters, and debugging training processes can be complex and time-consuming. As deep learning continues to evolve, addressing these challenges will be critical to making the technology more robust, transparent, and accessible for broader real-world adoption.Researchers are making progress in model compression, Neural network architecture natural language interpretability frameworks, ethical guidelines, and training efficiency.transformative impact across industries.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Future Scope
Looking ahead, major trends include:
Summary
Deep Learning stands out by automating feature Machine Learning Training , scaling with data, and delivering breakthroughs in perception and decision-making. Core elements include.Applications of deep learning is not just academic, it’s shaping the future of industries, governance, neurons, PyTorch natural language and technology. deep networks in Neural network architecture , data strategies, and ethical deployment will be key to the next wave of AI.




