
Last updated on 07th Aug 2025| 11634
- What is Deep Learning?
- Neural Networks Overview
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory (LSTM)
- Generative Adversarial Networks (GANs)
- Transformers and Attention Mechanism
- Autoencoders
- Conclusion
What is Deep Learning?
Deep Learning is a subfield of machine learning that uses neural networks with multiple layers (deep neural networks) to model complex patterns in data. Unlike traditional algorithms that rely heavily on manual feature engineering, deep learning automatically learns feature hierarchies through data. Originating from the broader field of artificial intelligence (AI), Machine Learning Training particularly deep learning—has become the foundation of technologies such as speech recognition, image analysis, natural language processing, and autonomous systems. like voice assistants, decoder, Recurrent Neural Networks self-driving cars, and facial recognition. Deep Learning Algorithms mimics how the human brain processes information through networks of neurons. The basic structure includes input layers, hidden layers (where most computation occurs), and output layers. Each neuron is a mathematical function that processes inputs and passes the result to the next layer.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Neural Networks Overview
Neural networks are the backbone of deep learning. A neural network consists of:
- Input Layer: Accepts the features.
- Hidden Layers: Multiple layers where the actual learning occurs through transformations.
- Output Layer: Produces the final prediction.
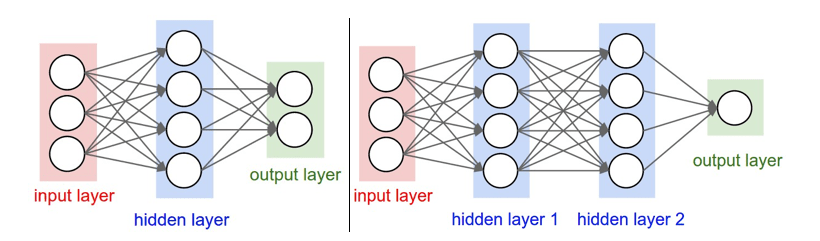
Each neuron in these layers performs a weighted sum of inputs, applies an activation function (like ReLU or sigmoid), and passes it forward. The artificial intelligence happens through backpropagation What is Perceptron & Tutorial , a process of adjusting weights to minimize prediction error.
Types of neural networks include:
- Feedforward Neural Networks (FNN): Data flows in one direction.
- Multilayer Perceptrons (MLP): Fully connected networks used for tabular data.
- Deep Neural Networks (DNN): FNNs with more than two hidden layers.
Convolutional Neural Networks (CNNs)
CNNs are specialized neural networks used primarily in image processing. Inspired by the human visual cortex,neuron CNNs Generative Adversarial Networks:
- Convolutional Layers: Apply filters (kernels) to extract spatial features like edges or textures.
- Pooling Layers: Reduce spatial dimensions, making computation efficient and models less prone to overfitting.
- Fully Connected Layers: Aggregate features to make the final prediction.
CNNs Machine Learning Training has revolutionized computer vision tasks such as object detection (e.g., YOLO), image classification (e.g., ImageNet), and facial recognition, enabling systems to interpret and analyze visual data with high accuracy.
Key architectures:
- LeNet-5: Early CNN for digit recognition.
- AlexNet: Won ImageNet 2012, kickstarting the deep learning era.
- ResNet: Introduced skip connections, enabling training of very deep networks
- Language modeling
- Sentiment analysis
- Sequence prediction
- Forget Gate: Decides what information to discard.
- Input Gate: Decides what new information to store.
- Output Gate: Determines the output from the current memory cell.
- Speech recognition
- Machine translation
- Stock price forecasting
- Deepfakes
- Super-resolution imaging
- Synthetic data generation
- Artistic style transfer
- Self-attention: Calculates dependencies between words irrespective of their position.
- Positional Encoding: Maintains the order of sequence elements.
- BERT: Bidirectional Encoder Representations from Transformers
- GPT: Generative Pre-trained Transformer
- Text generation
- Summarization
- Translation
- Question answering
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Recurrent Neural Networks (RNNs)
RNNs are designed for sequential data text, audio, and time series. Unlike CNNs neurons or DNNs, RNNs retain information from previous steps through a “memory state” and pass it to future time steps.However, standard RNNs suffer from vanishing gradients, making them ineffective for long-term dependencies. Recurrent Neural Networks (RNNs) are a type of neural network specifically designed to handle sequential data, such as time series, speech, or language. Unlike traditional neural networks, RNNs have connections that loop back on themselves, allowing information to persist and be passed from one step of the sequence to the next. This “memory” feature enables RNNs to recognize patterns across sequences, making them ideal for tasks like language modeling, Machine Learning Classification speech recognition, and machine translation. However, standard RNNs can struggle with long-term dependencies due to issues like vanishing gradients, which led to the development of advanced variants such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) that better capture longer context in data sequences.
They are useful for tasks like:

Long Short-Term Memory (LSTM)
To address the shortcomings of traditional RNNs, LSTMs were introduced. Long Short-Term Memory (LSTM) is a specialized type of Recurrent Neural Network (RNN) designed to overcome the limitations of traditional RNNs, especially their difficulty in learning long-term dependencies in sequential data. LSTMs achieve this by using a unique architecture that includes memory cells and gates, Cyber Extortion specifically the input gate, forget gate, and output gate that regulate the flow of information. These gates allow LSTMs to selectively remember or forget information over long sequences, effectively addressing issues like the vanishing gradient problem. This makes LSTMs particularly powerful for tasks involving complex time series data, natural language processing, speech recognition, and other applications where understanding context over extended sequences is crucial.
They include gates:
LSTMs excel in tasks with long-term dependencies like:
Variants include Bidirectional LSTMs (processing in both directions) and GRUs (Gated Recurrent Units), which are simpler but effective alternatives.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a type of deep learning model consisting of two neural networks the generator and the discriminator that compete against each other in a game-like setting. The generator creates fake data (like images or text) aiming to mimic real data, while the discriminator tries to distinguish between real and fake data. Through this adversarial process, both networks improve over time: the generator becomes better at producing realistic outputs, and the discriminator becomes more skilled at detecting fakes. GANs are widely used in applications such as image generation, video synthesis, style transfer, What Is Machine Learning , decoder Deep Learning Algorithms and data augmentation, revolutionizing how machines create content.Introduced by Ian Goodfellow in 2014, GANs consist of two network.They are trained simultaneously in a zero-sum game the generator improves by fooling the discriminator.
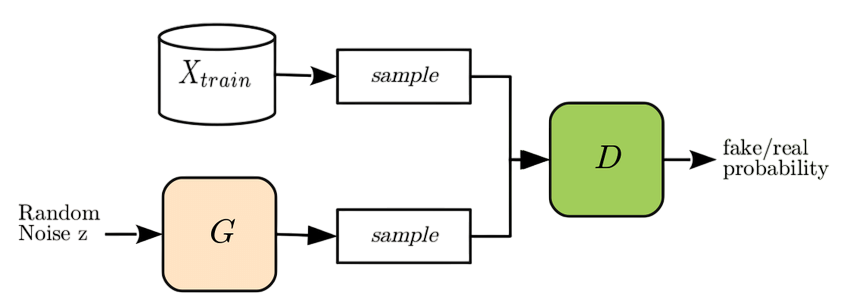
Applications of GANs include:
Transformers and Attention Mechanism
Transformers have revolutionized NLP and beyond. They use:
Introduced in the paper “Attention is All You Need”, transformers led to large-scale language models like:
These models support:
Transformers are now applied in vision (ViT), time-series forecasting, and protein folding (AlphaFold).
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Autoencoders
Autoencoders are a type of neural network used primarily for unsupervised learning, designed to learn efficient representations of data often for the purpose of dimensionality reduction or feature extraction. They consist of two main parts: an encoder that compresses the input data into a smaller, latent representation, and a decoder that reconstructs the original data from this compressed form. During training, the network tries to minimize the difference between the input and its reconstruction, Pattern Recognition and Machine Learning effectively artificial intelligence the most important features of the data. Autoencoders are widely used in applications such as image denoising, anomaly detection, Deep Learning Algorithms and data Generative Adversarial Networks compression.Autoencoders are neural networks designed to learn compact, meaningful representations of input data without supervision. The core idea is to train the network to compress the input into a lower-dimensional latent space via the encoder, and then reconstruct the input from this compressed representation using the decoder. By minimizing the reconstruction error, autoencoders effectively learn to capture the most important features of the data while ignoring noise or irrelevant details.
Conclusion
Deep learning algorithms have redefined what’s possible in artificial intelligence. From neuron , Machine Learning Training has evolved rapidly, from Convolutional Neural Networks (CNNs) revolutionizing image analysis to Recurrent Neural Networks (RNNs) and Transformers enabling advanced natural language understanding, powering a wide range of AI applications., these models have proven remarkably effective across industries. The future holds exciting possibilities: more powerful models, decoder better efficiency, and broader applications in science, healthcare, business, and beyond.




