
Last updated on 09th Aug 2025| 12144
- Introduction to Image Annotation
- Why Annotation is Important
- Types of Image Annotations
- Tools Used for Image Annotation
- Manual vs Automated Annotation
- Datasets for Computer Vision
- Quality Control in Annotation
- Challenges and Limitations
- Final Thoughts
Introduction to Image Annotation
In computer vision, image annotation is the process of labeling or tagging images to create ground-truth data for Machine Learning Training AI models. These annotations ranging from bounding boxes to semantic masks teach algorithms to understand visual content like objects, scenes, and actions. Image annotation has exploded in relevance over the last decade, underpinning AI applications as diverse as autonomous driving, medical diagnostics, surveillance, Types of Image Annotations , AR/VR, and more. High-quality, Automated Annotation consistent labeled data ensures that computer vision systems perform reliably in real-world conditions.Image annotation is the process of labeling or tagging visual data, typically images or video frames, to train computer vision models. It plays a foundational role in supervised machine learning by providing the ground truth that algorithms use to learn and make predictions. During annotation, specific objects, regions, or features within an image are marked and categorized this might include drawing bounding boxes around vehicles, segmenting a person’s silhouette, or labeling facial features. Depending on the use case, annotations can be as simple as assigning a label to an entire image or as complex as pixel-level segmentation for medical imaging. Common tasks that rely on image annotation include object detection, image classification, semantic segmentation, facial recognition, and autonomous driving. High-quality annotations are essential for model accuracy, generalization, and robustness. As a result, tools, techniques, and quality control measures in image annotation have become increasingly sophisticated, often involving manual labeling, AI-assisted annotation, or crowd-sourced platforms. The demand for precise and scalable annotation continues to grow alongside advancements in artificial intelligence, making image annotation a critical step in the computer vision pipeline.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Why Annotation is Important
Image annotation is critical for supervised learning, where models learn patterns from annotated examples. Here’s why it matters:
- Enables Model Learning: Algorithms rely on ground truth labels to detect and classify objects.
- Improves Accuracy: Detailed annotations (e.g., polygonal masks) support precise segmentation and detection.
- Provides Context: Semantic labeling helps Support Vector Machine models understand scenes and relationships between objects.
- Supports Safety-Critical Systems: In autonomous vehicles or healthcare, robust annotation directly impacts reliability and safety.
- Enables Transfer Learning: Standard, well-annotated datasets can be reused across projects.
High-quality annotation fosters reliable ML models; poor labeling or inconsistencies can severely degrade performance or generate bias.
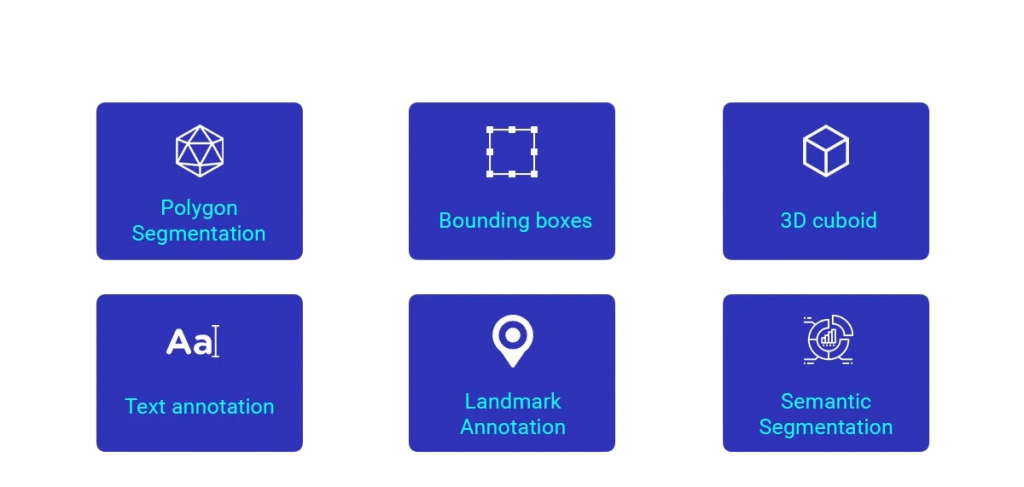
Types of Image Annotations
Types of Image Annotations comes in many forms, each tailored to specific tasks:
- Bounding Boxes: Rectangular boxes around target objects. Widely used in object detection.
- Semantic Segmentation: Pixel-wise labeling of classes (e.g., “background,” “road,” “car”). Enables object understanding at high resolution.
- Instance Segmentation: Decision Trees in Machine Learning can be used to distinguish between individual instances; for example, two cars in a scene can get separate masks.
- Polygon Annotation: Free-form shapes for irregular objects used when bounding boxes are too coarse.
- Polyline / Line Annotations: Useful to trace roads, polylines, or bodies.
- Keypoints & Landmarks: Represent object geometry. In facial or pose analysis, e.g. 68-point facial landmarks or joints in human pose.
- 3D Cuboids / 3D Bounding Boxes: Provide spatial annotation important in 3D object detection (e.g., LiDAR point clouds in self-driving cars).
- Image-Level Labels / Classification Tags: Labels for an entire image (e.g., “cat,” “outdoor”) used in classification tasks.
- Web-Based Platforms: Labelbox, SuperAnnotate, Scale AI, V7 Darwin, Hive AI enterprise-grade platforms offering collaboration, quality control, analytics.
- Open-Source Tools: LabelImg (bounding boxes), CVAT (bounding boxes, polygons, keypoints, segmentation, video), RectLabel (macOS), VoTT (Microsoft), makesense.ai, Label Studio.
- Custom Internal Tools: Machine Learning Training is used by large organizations for data security or project tailoring. (e.g., Waymo’s custom annotation tool for LiDAR and camera data).
- Automated / Semi-Automated Tools: Use pre-trained models to bootstrap annotation. Super Annotate, CVAT, and Labelbox offer auto-annotation features.
- Cloud-Based Services: AWS SageMaker Ground Truth, Google’s Vertex AI Data Labeling, Azure ML labeling, fully managed labeling pipelines with built-in quality mechanisms.
- Done by humans, ensures high fidelity.
- Pros: accuracy, can handle ambiguous edge cases, less reliance on model pre-training.
- Cons: time-consuming, labor-intensive, expensive, prone to human error/inconsistency.
- Bootstraps annotations using models to pre-label input; annotators review and refine.
- Pros: faster progress, scalable, lower cost.
- Cons: model bias propagation; poor if initial model quality is low; still needs human oversight.
- Cost & Time: Manual annotation is resource-intensive segmenting one image by hand can take minutes or hours.
- Consistency: Annotator subjectivity may lead to label drift; instructions must be precise.
- Scalability: Large datasets require significant effort to annotate; quality control becomes harder at scale.
- Complex Objects / Edge Cases: Occlusions, reflections, small objects, dense scenes are harder to accurately annotate.
- Tool Limitations: Many annotation tools are not embedded with advanced quality automation or custom annotation types (like 3D cuboids).
- Privacy & Legal Constraints: Especially in healthcare or surveillance, obtaining and handling sensitive imagery adds regulatory complexity.
- Bias: Annotation bias where annotators tend to miss or mislabel certain classes can affect model fairness.
Choosing the right annotation method depends on the end task: detection, classification, segmentation, pose estimation, or 3D modeling.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Tools Used for Image Annotation
Modern annotation leverages a broad ecosystem of tools:
Selection depends on annotation type (2D, 3D, video), workflow needs, collaboration scale, integration, and cost/security requirements.

Manual vs Automated Annotation
Manual Annotation
Automated Annotation
Semi Automated annotation is often best: models pre-label, humans validate and correct. This iterative process, commonly used in Pattern Recognition and Machine Learning, increases speed while retaining quality
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Datasets for Computer Vision
Datasets for Computer Vision play a critical role in training and evaluating models across a wide range of tasks such as image classification, object detection, segmentation, and facial recognition. Popular datasets like ImageNet, COCO (Common Objects in Context), and Pascal VOC provide large-scale, labeled data essential for developing and benchmarking deep learning models. For more specialized applications, there are domain-specific datasets such as MNIST for handwritten digit recognition, LFW (Labeled Faces in the Wild) for face verification, and KITTI for autonomous driving. High-quality datasets are crucial for achieving robust model performance, Enabling systems to learn complex patterns and generalize to real-world scenarios. With the rapid growth of computer vision applications, these advancements are well illustrated in Deep Learning Explained. the availability and diversity of datasets continue to expand, helping researchers and developers push the boundaries of what machines can see and understand.
Quality Control in Annotation
Quality Control in Annotation is a crucial component in the development of reliable and accurate machine learning models, particularly in areas like computer vision, natural language processing, and speech recognition. The success of supervised learning models heavily depends on the quality of the annotated data they are trained on. Poor annotations can lead to incorrect predictions, reduced model performance, and biased outcomes. Therefore, establishing a robust quality control (QC) process ensures the consistency, accuracy, and reliability of labeled datasets. Effective quality control in annotation begins with clear and detailed labeling guidelines. Annotators need to understand the task objectives, annotation rules, and edge cases. These guidelines help maintain consistency across multiple annotators and reduce ambiguity in the labeling process, as emphasized in An Overview of ML on AWS. Regular training and feedback sessions for annotators also improve labeling accuracy over time. Another essential QC strategy involves multiple rounds of review. This can include cross-verification by other annotators, spot-checking by quality assurance teams, or leveraging consensus-based approaches where multiple annotations are compared to identify discrepancies. Inter-annotator agreement metrics, such as Cohen’s Kappa or F1 score, Datasets for Computer Vision are commonly used to measure consistency and identify areas that need clarification or retraining.
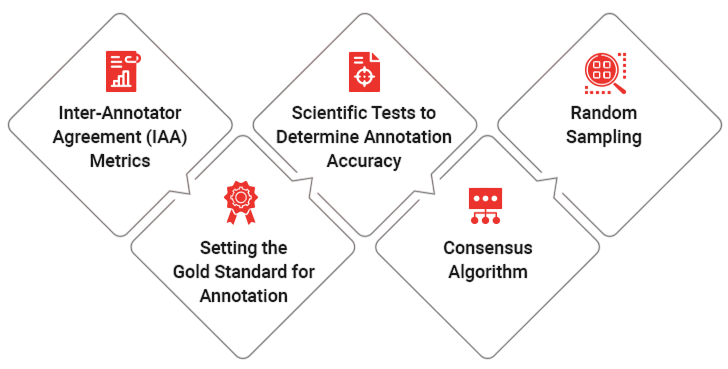
Automated tools and machine-assisted annotation methods can further support quality control by flagging anomalies or inconsistencies in the data. Active learning strategies can prioritize the most informative or uncertain samples for manual review, optimizing both annotation efficiency and accuracy. Finally, maintaining a feedback loop between model performance and annotation quality helps continuously refine the dataset. If the model struggles with specific categories or classes, revisiting the corresponding annotations may uncover labeling errors or ambiguities that need correction.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Challenges and Limitations
Annotation projects come with several roadblocks:
Navigating these challenges requires good project planning, clear datasets, and iterative QA mechanisms.
Final Thoughts
Image annotation is the powerful yet often invisible backbone of computer vision development. As more industries apply AI for automation, detection, and decision-making, high-quality Types of Image Annotations data becomes ever more critical. The growing annotation ecosystem from open-source tools to commercial platforms and managed services supports projects of all scales. Annotation roles not only provide immediate short-term opportunities but also offer strong pipelines into technical careers. Whether your aim is to run annotation teams, Datasets for Computer Vision build labeling platforms, or integrate annotation into Machine Learning Training , there’s a career path that aligns with your talents and ambitions. Ultimately, the investment in clean, consistent, and thoughtfully annotated data pays huge dividends: more robust models, higher accuracy, better understanding of the real-world, and ultimately, AI solutions that genuinely improve people’s lives.




