
Last updated on 06th Aug 2025| 12314
- What is a Cost Function?
- Role in Supervised Learning
- Mean Squared Error (MSE)
- Cross-Entropy Loss
- Hinge Loss
- Custom Loss Functions
- Gradient Descent and Optimization
- Cost vs Loss vs Objective Functions
- Conclusion
What is a Cost Function?
ACost Function in Machine Learning , also called a loss function or objective function, is a mathematical function that measures the difference between the predicted output of a machine learning model and the actual target values. It assigns a numerical cost or penalty for incorrect predictions, with the goal of minimizing this Custom Loss Functions during training.In Machine Learning Training , the cost function is fundamental to training models that make accurate predictions. It quantifies how well a model’s predictions match the actual data and guides the learning algorithm in optimizing model parameters. This article explores cost functions in depth, including types, their roles in different learning contexts, optimization techniques, and practical considerations like overfitting and regularization.
Looking to boost your cybersecurity knowledge? Start here! CyberSecurity Online Training Today!
Role in Supervised Learning
- Foundation for Predictive Modeling: Supervised learning is used to build models that can predict outcomes based on labeled input-output pairs. It’s the most widely used machine learning approach in practical applications.
- Learning from Labeled Data: AdaBoost in Machine Learning algorithm, meaning it is trained on a dataset where the correct output (label) is already known.. It learns to map inputs (features) to outputs (targets).
- Generalization to Unseen Data: The goal is to train a model that can generalize from the training data to make accurate predictions on new, unseen data.
- Examples of Algorithms Used: Includes linear regression, logistic regression, decision trees, support vector machines (SVMs), random forests, and neural networks.
- Applications Across Domains: Supervised learning powers applications in finance (fraud detection), healthcare (disease diagnosis), marketing (customer segmentation), and technology (speech recognition, image classification).
- Model Evaluation Metrics: Common metrics include accuracy, precision, recall, F1-score for classification and mean squared error (MSE), R² score for regression.
Mean Squared Error (MSE)
Mean Squared Error (MSE) is a commonly used loss function and evaluation metric in regression problems within supervised learning. In Ensemble Learning performance is often evaluated using metrics like Mean Squared Error (MSE), which measures the average of the squares of the errors that is, the average squared difference between the predicted values and the actual target values.
Formula:
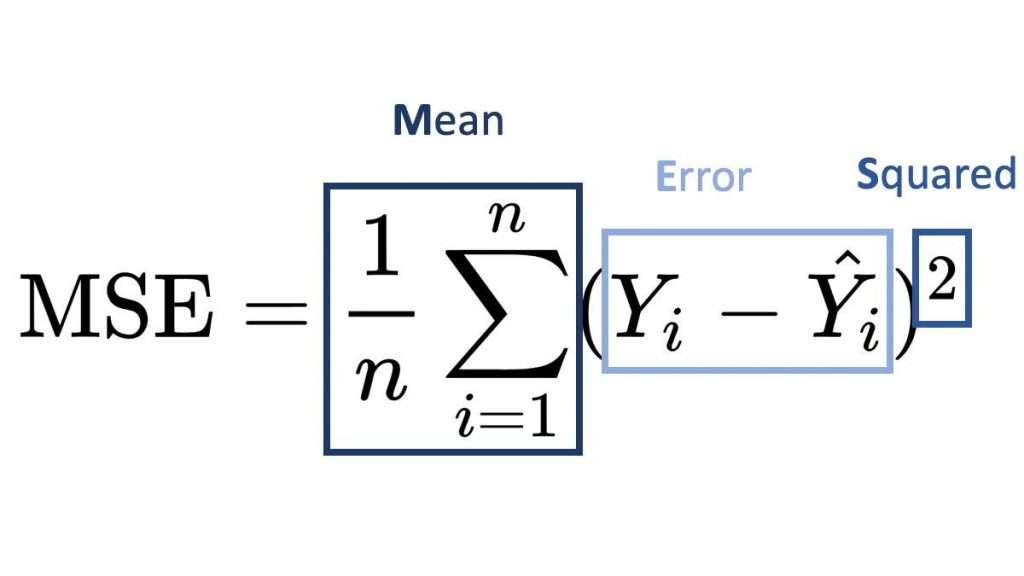
Where:
- n = number of data points
- Yi = actual (true) value
- y^i = predicted value
Key Characteristics:
- Always non-negative: MSE is zero only when all predictions are perfect.
- Penalizes larger errors More heavily due to the squaring of differences.
- Sensitive to outliers: A few large errors can significantly increase the MSE.
- Used for Multi-Class Classification: Applied when there are more than two possible output classes.
- Compares Predicted and True Distributions: Measures the difference between the predicted probability distribution (from softmax) and the actual class label (one-hot encoded).
- Penalizes Confident Wrong Predictions: Higher loss is assigned when the model is confident about the wrong class.
- Minimized During Training: In Regularization in Machine Learning , the goal is to reduce the loss by increasing the predicted probability for the correct class while preventing the model from overfitting.
- Works with Softmax Activation: Typically used in neural networks with softmax in the output layer to produce class probabilities.
- Effective for Many Tasks: Common in image classification, text classification, language modeling, and more.
- Sensitive to Probability Confidence: Not just whether the prediction is right or wrong but how confident the model is about its prediction.
- Weighted loss to handle imbalanced datasets by giving higher penalty to minority classes.
- Huber loss, which combines MSE and MAE to be robust to outliers.
- Task-specific losses in computer vision, Radial Basis Function such as Intersection-over-Union (IoU) loss for segmentation.
- Defined as differentiable functions compatible with optimization algorithms.
- Easily implemented in frameworks like TensorFlow, PyTorch, or scikit-learn.
Would You Like to Know More About Database? Sign Up For Our Database Online Training Now!
Cross-Entropy Loss
Cross-Entropy Loss, also known as log loss, is a widely used loss function in classification problems, particularly for binary and multi-class classification tasks. It measures the difference between the predicted probability distribution and the actual labels. In simpler terms, it quantifies how close or far the predicted probabilities are from the true class labels. A lower cross-entropy ,Role in Supervised Learning value indicates better model performance. In binary classification, cross-entropy compares the predicted probability of the positive Custom Loss with the actual class label (0 or 1). For multi-class problems, it evaluates the entire probability distribution predicted by the model across all classes. Mathematically, it is calculated using logarithms, which heavily penalize predictions that are confident but incorrect. This makes cross-entropy, Squared Error especially effective when using models like logistic regression or neural networks, where outputs are probabilities derived from softmax or sigmoid functions. Because of its probabilistic nature and sensitivity to incorrect predictions, cross-entropy loss is a preferred choice for training deep learning models in tasks such as image recognition, text classification, and language modeling.

Multi-Class Cross-Entropy
Hinge Loss
Hinge loss is primarily used in Support Vector Machines (SVMs) for classification, focusing on maximizing the margin between classes.Hinge Loss is a loss function primarily used for training classifiers, especially in Support Vector Machines (SVMs). It is designed for binary classification tasks where the labels are
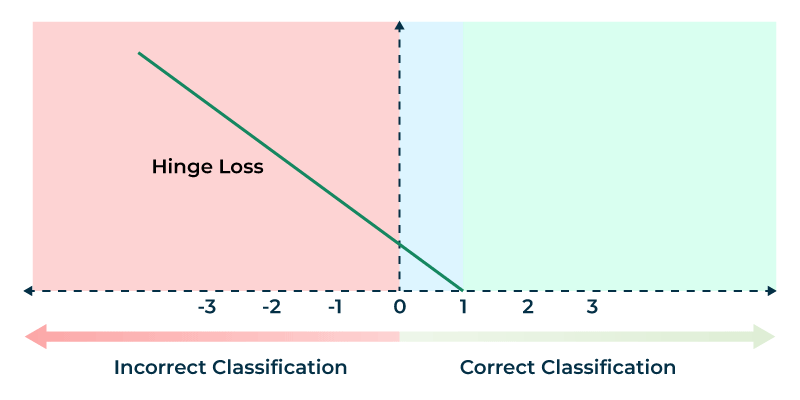
Hinge Loss encourages the model not just to classify correctly, but to do so with a margin of confidence. If the prediction is on the correct side of the decision boundary but too close to it, Hinge Loss still penalizes it, pushing the model to make more confident decisions. Mathematically, if the product of the true label and the predicted value is greater than or equal to 1, the loss is zero; otherwise, Role in Supervised Learning Cost Function in Machine Learning Training the loss increases linearly as the prediction moves further away from the correct margin. This makes Hinge Loss particularly effective for maximizing class separation and is one of the reasons it is central to the functioning of SVMs.
Looking to Master Cybersecurity? Discover the Available at ACTE Now! Today!
Custom Loss Functions
Sometimes, standard cost functions don’t capture domain-specific needs or complex objectives. Custom loss functions are crafted to address such scenarios.
Examples
How to Implement
Gradient Descent and Optimization
Once the cost function is defined, the goal is to minimize it by adjusting the model’s parameters.Gradient Descent is a fundamental optimization algorithm used in Cost Function in Machine Learning to minimize a model’s loss function, which measures how far the model’s predictions are from the actual values. In the context of combating Cyber Extortion , the goal of training a model is to find the optimal set of parameters (like weights and biases) that reduce the loss as much as possible to accurately detect and prevent malicious activities. Gradient Descent works by computing the gradient the direction and rate of the steepest increase in the loss and then updating the model’s parameters in the opposite direction, effectively moving “downhill” toward the minimum loss. This process is repeated over many iterations, gradually improving the model. Variants such as Stochastic Gradient Descent (SGD), Mini-Batch Gradient Descent, and Adam are used to speed up convergence and handle large datasets more efficiently. Gradient Descent lies at the heart of training most machine learning and deep learning models, enabling them to learn from data and make accurate predictions.
Preparing for a Career in Cybersecurity? Don’t Miss Our Blog Cyber Security Interview Questions and Answers To Ace Your Interview!
Cost vs Loss vs Objective Functions
| Term | Scope | Purpose | Example |
|---|---|---|---|
| Loss Function | Single data point | Measures prediction error for one sample | (y−y^)2(y – \hat{y})^2(y−y^)2 |
| Cost Function | Entire dataset (average loss) | Measures model’s overall error | 1n∑(y−y^)2\frac{1}{n} \sum (y – \hat{y})^2n1∑(y−y^)2 |
| Objective Function | Dataset + additional terms | Function to minimize (e.g., cost + regularization) | Cost + L1/L2 penalties |
Conclusion
The Cost Function in Machine Learning Training is the cornerstone of supervised machine learning, encapsulating the model’s objective to minimize prediction errors. Understanding different cost functions MSE, Role in Supervised Learning, cross-entropy, hinge loss and their applications helps tailor models for various tasks. Coupled with optimization algorithms like gradient descent and enhanced by regularization, cost functions enable robust and generalizable machine learning models.The ability to design or Custom Loss Functions appropriate cost functions, visualize their convergence, and incorporate domain-specific knowledge through custom losses is critical for developing effective machine learning systems that perform well in real-world applications.

