
Last updated on 12th Aug 2025| 12590
- Introduction to Reinforcement Learning
- Key Terminology (Agent, Environment, Reward)
- Types of RL (Model-based vs Model-free)
- Markov Decision Process (MDP)
- Q-Learning
- Deep Q Networks (DQN)
- Policy Gradient Methods
- Exploration vs Exploitation
- Applications of RL
- Tools and Libraries
- Challenges in RL
- Future Directions
- Conclusion
Introduction to Reinforcement Learning
Reinforcement Learning (RL) is a dynamic area within machine learning where agents learn to make decisions by interacting with an environment. Machine Learning Training plays a crucial role in shaping intelligent systems. Unlike supervised learning, where labeled data is provided, RL agents learn through trial and error, receiving feedback in the form of rewards or penalties. The power of RL lies in its ability to solve problems that involve sequential decision making, such as teaching a robot to walk, playing video games, or optimizing supply chains. It mimics human learning patterns: observe, act, and improve.
Key Terminology
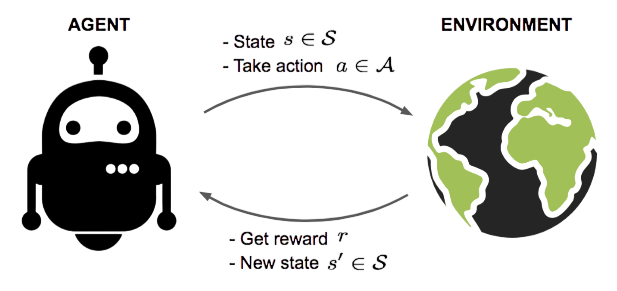
In the field of Reinforcement Learning (RL), understanding the basic components is key to grasping how intelligent systems learn and make decisions. At the center of this framework, the agent interacts with its environment by observing states, taking actions, and adjusting based on the rewards it receives. The environment gives important feedback that shapes the agent’s decision making. Each state reflects the agent’s current situation, while actions are the strategic choices the agent can make to affect the environment. Rewards act as feedback that steers the agent toward better behavior by encouraging actions that maximize overall performance over time. To complement this reinforcement learning framework with margin-based classification techniques, exploring Support Vector Machine (SVM) Algorithm reveals how SVMs construct optimal hyperplanes to separate classes leveraging kernel functions and support vectors to handle both linear and non-linear data across decision-making systems and predictive environments. The policy serves as a guide that dictates how the agent chooses actions in different states; this can be either certain or random. The value function further improves this learning process by estimating the potential long-term benefits of being in a certain state or taking specific actions. This ultimately helps the agent create more sophisticated decision making strategies.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Types of RL
Types of RL can be broadly categorized into two main types: model-based and model-free approaches. Model-based methods attempt to understand the environment’s dynamics, while model-free methods learn optimal policies directly from experience. To complement these reinforcement learning strategies with interpretable decision-making tools, exploring Decision Trees in Machine Learning reveals how tree-based models segment data through hierarchical splits offering visual clarity, low entropy classification, and transparent logic that can enhance policy evaluation and state-action mapping in RL systems.
Model-Based RL
- The agent builds a model of the environment (transition probabilities, reward functions).
- It uses this model to simulate outcomes and make decisions.
- Efficient in data usage but computationally complex.
- Example: Planning a route on a map with known paths and traffic patterns.
Model-Free RL
- The agent learns the optimal policy directly from interactions with the environment without an explicit model.
- Popular due to simplicity and wide applicability.
Model-free RL is further divided into:
- Value-Based Methods (e.g., Q-Learning)
- Policy-Based Methods (e.g., Policy Gradient)
- Actor-Critic Methods (combination of value and policy methods)
Markov Decision Process (MDP)
At the heart of RL lies the Markov Decision Process (MDP), a mathematical framework that models decision making in RL.
An MDP is defined by:
- S: A set of states.
- A: A set of actions.
- P(s’|s, a): Transition probability (next state given current state and action).
- R(s, a): Reward function.
- γ: Discount factor (0 ≤ γ < 1), which determines the importance of future rewards.
Markov Decision Process Property: The future is independent of the past given the present state.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Q-Learning
Q-Learning is a strong model-free, off-policy reinforcement learning algorithm that aims to learn the best action-value function through an iterative process. The algorithm starts by setting up a Q-table randomly. It then explores and updates action values using an exploration strategy like ε-greedy. At each step, it picks an action, observes the reward and the next state, and refines its Q-values using a learning rate and discount factor.
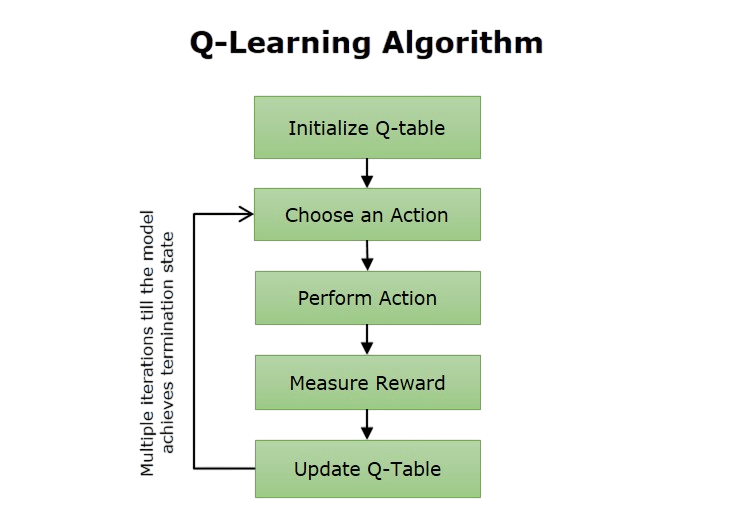
Its main strength is its simplicity and effectiveness for small, discrete action spaces, making it especially useful for simple decision making situations. However, practitioners need to be aware of its limitations, such as its difficulty in managing large or continuous state spaces. They can tackle these issues using techniques like Deep Q-Networks. Despite these limitations, Q-Learning remains a key method in reinforcement learning, offering an easy-to-understand framework for agents to learn the best strategies through trial and error.

Deep Q Networks (DQN)
Deep Q Networks (DQN) mark a significant development in reinforcement learning. They build on traditional Q-learning and use deep neural networks to estimate the Q-function effectively. DQN uses a Q-Network that predicts Q-values directly from raw inputs like pixel data. This capacity allows it to manage high-dimensional inputs, such as complex visual environments. The algorithm features experience replay, which stores past interactions in a buffer. It then randomly samples from this buffer to reduce learning correlations. Deep Q Networks, a key method in Machine Learning Training, also employs a separate target network to provide stable Q-value estimates. These design choices help DQN achieve outstanding performance, showing human-level abilities in tough Atari game settings. However, DQN has its challenges. The algorithm is sensitive to hyperparameter tuning, and it can become unstable without careful adjustments to learning rates and discount factors. Even with these issues, Deep Q Networks has become an important method in machine learning. It connects traditional reinforcement learning with more advanced deep learning techniques.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Policy Gradient Methods
Instead of estimating value functions, these methods directly optimize the policy. To complement this policy-centric approach with foundational modeling techniques, exploring Pattern Recognition and Machine Learning reveals how statistical, structural, and neural algorithms are used to identify patterns enabling systems to classify data, adapt to dynamic environments, and refine decision-making strategies across reinforcement learning and supervised learning tasks.
Policy Gradient Objective:
- J(θ)=Eπθ[R]J(\theta) = \mathbb{E}_{\pi_\theta}[R]
- Uθ←θ+α∇θJ(θ)\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)
Popular Algorithms:
- REINFORCE: Monte Carlo estimation of gradients.
- Actor-Critic: Combines value estimation (critic) with policy updates (actor).
Benefits:
- Works in continuous action spaces.
- Can represent stochastic policies.
Downsides:
- High variance in gradient estimates.
- Slower convergence than value-based methods.
Exploration vs Exploitation
A central trade-off in RL:
- Exploration: Trying new actions to discover rewards.
- Exploitation: Using known information to maximize rewards.
Strategies:
- ε-Greedy: Choose a random action with ε probability, otherwise the best-known action.
- Softmax: Chooses actions probabilistically based on their Q-values.
- Upper Confidence Bound (UCB): Balances estimated value with uncertainty.
Balancing exploration and exploitation is key for long-term success in RL environments.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Applications of Reinforcement Learning
RL has seen tremendous success across industries: from optimizing supply chains and diagnosing medical conditions to enhancing financial forecasting and personalizing entertainment experiences. To complement these breakthroughs with scalable cloud infrastructure, exploring Overview of ML on AWS reveals how Amazon’s machine learning services like S3, Redshift, SageMaker, and Textract enable developers to build predictive models, automate workflows, and deploy intelligent applications across healthcare, retail, media, and finance.
- Teaching robots to walk, grasp, or navigate.
- RL is used to control and adapt behavior in real-time.
Robotics
Gaming
- DeepMind’s AlphaGo and AlphaZero.
- Training agents to master video games like Dota 2 and StarCraft II.
Finance
- Portfolio optimization.
- Algorithmic trading using reward functions tied to return and risk.
- Decision making in navigation, obstacle avoidance, and control.
- Dynamic personalization using user interactions as feedback.
- Optimizing treatment policies.
- Scheduling appointments and resource allocation.
Recommendation Systems
Healthcare
Tools and Libraries
A variety of open-source libraries support RL development:
- Benchmark environments for RL algorithms.
- Compatible with many RL libraries.
- High-level implementations of popular RL algorithms.
- Built on PyTorch.
- TensorFlow-based framework for scalable RL.
- Scalable and distributed RL.
- Useful for industrial-scale problems.
- Google’s research framework for RL experimentation.
- Multi-agent RL environments.
OpenAI Gym
Stable-Baselines3
TensorFlow Agents (TF-Agents)
RLlib (Ray)
Dopamine
PettingZoo
Each tool caters to different levels of abstraction, scalability, and experimentation.
Challenges in RL
Despite its transformative potential, researchers face several key challenges in Reinforcement Learning (RL). They deal with sample inefficiency, which needs many interactions for effective learning, by using innovative methods like model-based RL and experience replay techniques. Sparse rewards make the learning process harder because delayed or infrequent feedback complicates training agents. In response, researchers use solutions such as reward shaping and hierarchical RL strategies. The instability of training deep RL models requires them to carefully tune hyperparameters and use stabilization methods like target networks. To complement these reinforcement learning challenges with framework-level support, exploring Keras vs TensorFlow reveals how Keras simplifies model development with a high-level API ideal for rapid prototyping, while TensorFlow offers granular control and scalability making both valuable for building and stabilizing deep RL architectures. Generalization limitations also create problems, as RL agents may overfit to specific training environments. To address this, researchers create techniques like domain randomization and curriculum learning.
Future Directions
Reinforcement Learning is evolving rapidly. Future research and applications may focus on:
- Hierarchical RL: Breaks tasks into subtasks to learn complex behaviors more efficiently.
- Meta-Learning: Agents that can learn how to learn, adapting quickly to new tasks.
- Offline RL: Learning from historical data without active environment interaction.
- Multi-Agent RL: Agents that collaborate or compete, simulating real-world interactions.
- Integration with Other ML Paradigms: Combining RL with supervised learning, unsupervised learning, and NLP for holistic AI systems.
- Better Simulators: Realistic environments that bridge the gap between simulation and the real world (sim-to-real transfer).
Conclusion
Reinforcement Learning is a transformative technology with broad applications, from gaming to medicine. Understanding its foundational concepts agents, environments, rewards, and policies lays the groundwork for exploring powerful algorithms like Q-Learning, DQN, and Policy Gradients, all of which are central to Machine Learning Training. As computational power and algorithmic sophistication grow, RL will play an increasingly vital role in building autonomous, intelligent systems. However, practitioners must address challenges like sample inefficiency, safety, and generalization to unlock its full potential. Whether you’re a researcher, engineer, or enthusiast, RL offers a fascinating journey into the science of learning by doing.

