
Last updated on 09th Aug 2025| 12194
- Introduction to PyTorch
- History and Background
- Features of PyTorch
- Tensors in PyTorch
- Dynamic vs Static Computation
- Building Neural Networks
- PyTorch vs TensorFlow
- Popular Libraries and Extensions
- Final Thoughts
Introduction to PyTorch
PyTorch is an open‑source, Python based deep learning framework renowned for its flexibility, ease of use, and dynamic computation graph, ata-driven decision-making, and building end-to-end machine learning pipelines, supporting a wide range of applications from research prototypes to production-level AI systems in Machine Learning Training . Launched in late 2016, PyTorch quickly gained popularity in academia, then enterprise, becoming one of the top frameworks for deep learning.PyTorch is an open-source deep learning framework widely used for building and training neural networks. Developed by Facebook’s AI Research lab, it has gained popularity for its dynamic computation graph, which allows for flexible model building and easier debugging compared to static graph frameworks. PyTorch supports a wide range of applications, including computer vision, natural language processing, and reinforcement learning.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
History and Background
Founded by Facebook’s AI Research lab (FAIR), PyTorch emerged as the successor to the Lua-based Torch framework. It introduced modern Pythonic design with GPU acceleration:
- January 2017: 0.1.0 beta release .
- Late 2017: Release of 1.0 alpha with eager execution by default.
- December 2018: Version 1.0 stable, signaling maturity.
- 2020–2022: Expanded tooling (TorchServe, TorchVision, TorchText) and export formats (ONNX).
- Present: Deep Learning Explained offers deployment solutions (TorchScript, TorchServe, TFLite), seamless integration with cloud resources, and strong mobile support, making it an ideal choice for both research and production environments.
PyTorch’s rise stemmed from its developer-friendly interface, fast-paced innovation, and vibrant community.
Features of PyTorch
- Dynamic Computation Graphs: Build neural nets on-the-fly using runtime modifications ideal for research that requires flexibility.
- Pythonic Design: It integrates naturally with Python libraries like NumPy, SciPy, and ecosystem tools.
- GPU Acceleration: Decision Tree Algorithm in Machine Learning , while keeping it contextually appropriate (even though GPU usage isn’t typically a key feature of decision trees it might be mentioned in a broader framework or library support context).
- Rich Ecosystem: Includes domain-specific libraries: TorchVision (vision), TorchText (NLP), TorchAudio (audio), TorchGeometric (graphs), Ignite (training loops), Lightning (scaling), etc.
- Interoperability and Export: Supports ONNX for cross-framework export; TorchScript enables model serialization and optimization.
- Community and Support: Strong GitHub presence, academic citations, conferences, and tutorials make it accessible and well-documented.
- import torch
- x = torch.tensor([1.0, 2.0, 3.0])
- y = torch.tensor([[1, 2], [3, 4]])
- z = torch.zeros(3, 3)
- r = torch.rand(2, 4)
- import numpy as np
- a = np.array([1, 2, 3])
- t = torch.from_numpy(a)
- n = t.numpy()
- Default mode operations run immediately.
- Intuitive Python-style coding.
- Useful for variable-length inputs and debugging.
- Convert models via torch.jit.trace or torch.jit.script.
- Enables serialization, optimization, and deployment.
- Required for some production environments and mobile.
- TorchVision: Fraud Detection Using Machine Learning, Models, transforms, datasets for vision.
- TorchText: NLP utilities tokenizers, data iterators.
- TorchAudio: Tools for audio pipelines.
- PyTorch Lightning: Structured abstraction for cleaner code, easier scaling.
- Ignite: Lightweight framework for training loops.
- Catalyst: High-level deep learning library.
- FastAI: Easy-to-use APIs built on top of PyTorch.
- Hugging Face Transformers: Pretrained NLP models in PyTorch.
- Detectron2: Facebook’s object detection/segmentation toolbox.
- TorchGeometric (PyG): Graph deep learning utilities.
- Deep Graph Library (DGL): Another graph-network framework.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Tensors in PyTorch
Tensors are the fundamental data structure in PyTorch, similar to NumPy arrays but with additional capabilities optimized for deep learning. A tensor is a multi-dimensional array that can be used to represent scalars (0D), vectors (1D), matrices (2D), computer vision or higher-dimensional data like images and videos. In PyTorch, tensors are central to building neural networks. They store the inputs, outputs, model parameters, and Understand Random Forest Algorithm gradients during training. PyTorch tensors support a wide range of operations such as mathematical computations, reshaping, slicing, and broadcasting, many of which are performed efficiently on GPUs for faster computation.
Creating tensors is simple and flexible:
Tensors can also be converted between NumPy arrays and PyTorch easily:
PyTorch’s autograd system tracks operations on tensors that require gradients, enabling automatic differentiation, a key feature for training neural networks.

Dynamic vs Static Computation
Dynamic Computation (Eager Mode)
Dynamic computation, often referred to as eager mode, is a programming paradigm in deep learning frameworks where operations are executed immediately as they are called, rather than being staged for later execution. This is known as the define-by-run approach and contrasts with static computation graphs, where the entire graph must be defined before execution.
Static Computation (TorchScript Mode)
Data-driven decision-making, and building end-to-end Machine Learning Training pipelines, including the use of static computation also known as TorchScript mode in PyTorch which involves converting dynamic Python-based models into a static, serializable, and optimizable computation graph. Unlike eager mode (dynamic computation), where operations are executed immediately, TorchScript builds a computation graph ahead of time, allowing for improved performance, Features of PyTorch, deployment, and hardware optimization.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Building Neural Networks
Building neural networks involves designing and connecting layers of artificial neurons that can learn patterns from data. A typical neural network consists of an input layer, one or more hidden layers, and an output layer. Each layer is made up of units (neurons) that perform mathematical transformations on the data, usually through weighted sums followed by non-linear activation functions.
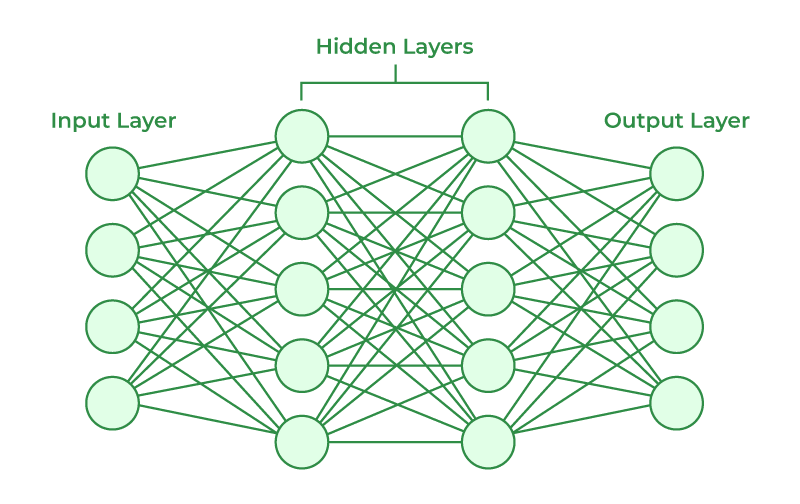
In modern deep learning frameworks like PyTorch , Python or TensorFlow, building a neural network often means defining the model architecture using predefined layer classes, Building Neural Networks, computer vision specifying the forward pass (how data flows through the network), and then training the model using an optimization algorithm like stochastic gradient descent. The process also involves choosing a loss function, initializing weights, Features of PyTorch, tuning hyperparameters (like learning rate and batch size), and monitoring performance during training. Once trained, the network can make predictions or be further fine-tuned for specific tasks such as image classification, Natural Language Processing, or time-series forecasting.
PyTorch vs TensorFlow
| Aspect | PyTorch | TensorFlow (2.x) |
|---|---|---|
| Computation Graph | Dynamic (eager) | Static (with eager enabled) |
| Debugging | Native Python debugging | Eager helps, but tracing complex |
| API Style | Pythonic | More verbose; sub-libraries |
| Community | Popular in research | Stronger enterprise adoption |
PyTorch is known for fast iteration and ease of experimentation, while TensorFlow has maturity in industrial deployment. Over time, the lines have blurred. TF2 adopts eager execution and nicer APIs; PyTorch focuses on serving and mobile.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Popular Libraries and Extensions
PyTorch’s ecosystem offers rich, purpose-built libraries:
These libraries reduce boilerplate and help you build top-tier architectures quickly.
Final Thoughts
Neural networks have become a cornerstone of modern artificial intelligence, enabling breakthroughs across fields like computer vision, natural language processing, Python and speech recognition. Building and training effective neural networks requires a solid understanding of key components such as tensors, computation modes (dynamic vs static), and training techniques like managing epochs, batches, and iterations. Tools like PyTorch make this process accessible, combining flexibility for research with pathways to production through features like TorchScript. Monitoring performance, preventing overfitting with techniques like early stopping, Features of PyTorch, Machine Learning Training ,natural language and using visualization tools are all essential to ensuring models remain accurate and reliable. As deep learning continues to evolve, mastering these fundamentals empowers you to build robust, scalable, and intelligent systems for a wide range of real-world applications.




