
Last updated on 06th Aug 2025| 11942
- What is Ensemble Learning?
- Bagging vs Boosting
- Random Forests
- AdaBoost
- Gradient Boosting Machines (GBM)
- XGBoost Overview
- Bias-Variance Reduction
- Practical Applications
- Model Selection in Ensembles
- Ensemble Techniques in Deep Learning
- Conclusion
What Is Ensemble Learning?
Ensemble learning is a powerful method for predictive modeling. It goes beyond the limits of individual algorithms by combining several base learners to create a more effective predictor. By bringing together different models, researchers use collective intelligence to reduce the biases of each model and lower prediction errors. Key strategies like bagging, boosting, stacking, and voting help this collaborative method systematically reduce variance and bias core ensemble techniques emphasized in Machine Learning Training. This approach often performs better than single-model solutions. Through training models in parallel, refining them sequentially, and integrating meta-models, ensemble methods build a strong framework that tackles complex regression and classification tasks. This approach takes advantage of different perspectives, showing a smart method for improving predictive performance in machine learning applications.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Bagging vs Boosting
Bagging
Bagging, or bootstrap aggregating, is a strong machine learning technique that reduces model variance. It does this by training multiple independent models on different random subsets of data. Each model learns from a distinct bootstrapped sample with replacement, which significantly cuts down on overfitting and improves predictive performance a technique often paired with Decision Trees in Machine Learning to enhance ensemble methods like bagging. Researchers take advantage of the method’s main strengths, including its simplicity for parallel processing, its ability to handle noisy training labels, and its effectiveness with unstable base learners like deep decision trees. While bagging is great for reducing variance, it’s important for practitioners to remember that it doesn’t fix underlying model bias. This makes it a smart choice for improving model stability and generalization.
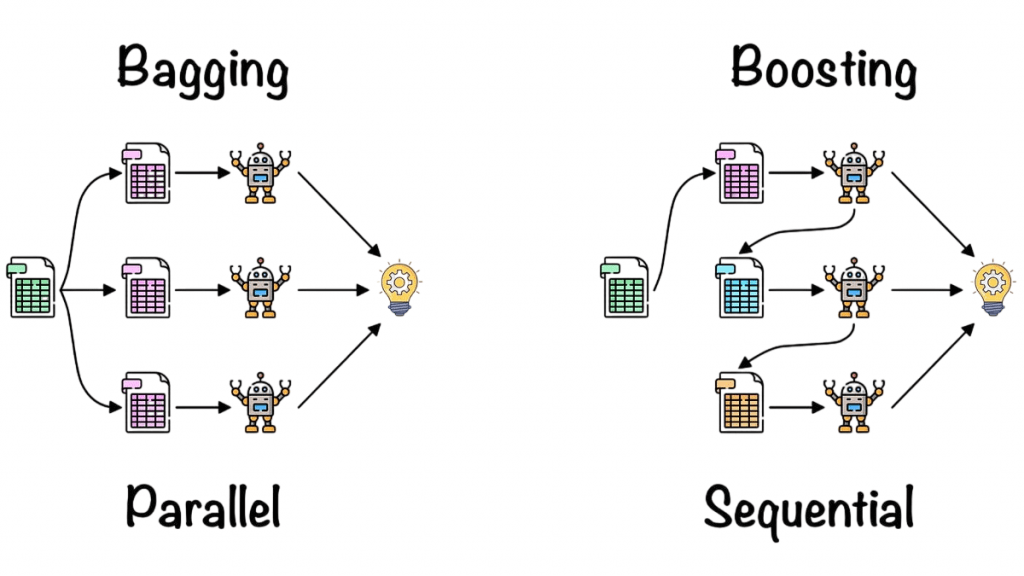
Boosting
Boosting techniques use an ensemble learning method that builds strong predictive models step by step. It addresses the mistakes made by previous learners. AdaBoost was the first to use this approach by changing sample weights after each round. Gradient boosting improved this process by using gradient descent optimization on the loss function. These algorithms offer notable benefits; they reduce model bias and variance while providing excellent performance on complex tasks. However, users should be cautious of possible downsides, such as a higher risk of overfitting and the time-consuming nature of the sequential training process. Despite these issues, boosting remains a powerful machine learning technique, allowing for more detailed and flexible predictive modeling in various fields.
Random Forests
Random Forests are a bagging ensemble of decision trees that also incorporate feature randomness. Each tree is trained on a random subset of features and a bootstrap sample, reducing feature correlation and further decreasing variance an approach widely studied in Pattern Recognition and Machine Learning.
Key Aspects
- Parallelism: Trees are independent and trained concurrently.
- Out-of-Bag (OOB) estimation: Approximates validation without needing hold-out data.
- Robustness: Resistant to overfitting and noise.
Advantages:
- High accuracy in practice.
- Low tuning requirement.
- Useful feature importance metrics.
Limitations:
- Less interpretable than single trees.
- Can struggle with high-dimensional, sparse data.
- Initialize sample weights equally.
- Train a weak learner.
- Compute classification error, update sample weights: misclassified samples are weighted more heavily.
- Reiterate; final output is a weighted sum of weak learners.
- Simple and often effective “out of the box”.
- Focuses on difficult examples.
- Can combine strong learners too.
- Sensitive to noisy data and outliers.
- Less scalable than other methods.
- Bagging: Decreases variance by averaging predictions from unstable learners.
- Boosting: Reduces bias through sequential fitting of residuals, adding explanatory power incrementally.
- Stacking: Harnesses model diversity via meta-learning to capture complex data patterns.
- Tabular Data: Algorithms like XGBoost and LightGBM often outperform deep neural networks.
- Finance: Used in credit scoring and fraud detection systems.
- Healthcare: Applied to disease diagnostics and risk stratification models.
- Computer Vision: Bagging and stacking strategies across multiple CNNs enhance performance.
- Science: Enables accurate predictions in areas like galaxy classification and protein folding.
- Bagging: Train multiple neural networks using varied initializations or data augmentations.
- Boosting: Employ deep learning variants such as Gradient Boosted Decision Trees with Neural Network leaves.
- Stacking: Combine CNNs and RNNs through meta-models to capture layered patterns.
- Bayesian / MC Dropout: Use dropout during inference to estimate uncertainty in predictions.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
AdaBoost
AdaBoost (Adaptive Boosting) introduced by Freund and Schapire (1995), sequentially trains weak classifiers (often decision stumps) and combines them weighted by performance Training steps:
Advantages:
Limitations:
Ridge regression is stable and performs well in scenarios with noisy data or moderate feature correlation. However, its models remain non-sparse, which can be a disadvantage for interpretability.

Gradient Boosting Machines (GBM)
Gradient Boosting Machines (GBM) build on traditional boosting algorithms by using gradient descent in function spaces. Researchers fit new trees to the negative gradient of the loss function a core technique in Machine Learning Training that enables iterative model refinement and improved predictive accuracy. This shows GBM’s impressive ability to handle both regression and classification tasks with flexible loss functions like squared error and logistic loss. Improved versions include smart limits like shrinkage parameters, controlled tree depth, and thoughtful subsampling of rows and features to reduce the risk of overfitting. Gradient boosting machines method allows data scientists to create strong, high-performance predictive models that can effectively manage complex data while remaining efficient and capable of generalization.
XGBoost Overview
XGBoost, a powerful machine learning algorithm introduced in 2016, has quickly gained popularity in predictive modeling due to its strong performance and flexibility. The algorithm stands out because of techniques like regularization for each tree leaf, finding splits that are aware of sparsity, and efficient weighted quantile sketch calculations. Its solid structure supports parallel training and distributed computing, allowing data scientists to easily manage complex datasets for classification and regression tasks.
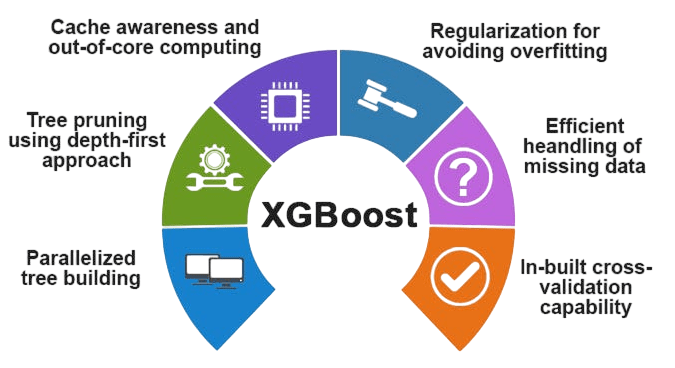
What makes XGBoost unique is its impressive ability to handle missing values and adapt to custom objectives, making it a favored choice among machine learning experts. Known as the “king of algorithms” in competitive modeling and industry applications, XGBoost continues to show unmatched scalability and predictive accuracy, reinforcing its role as a game-changing tool in modern data science.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Bias Variance Reduction
Ensemble error reduction strategies such as bagging, boosting, and stacking play a critical role in minimizing variance and bias across models. These techniques are foundational in scalable systems like Overview of ML on AWS, where distributed training and deployment amplify their impact.
Theory shows ensembles perform better when base learners are both accurate and diverse. Adding many correlated learners yields diminishing returns optimal ensemble size depends on the task.
Practical Applications
Ensemble learning powers many real-world systems:
Ensemble’s robustness, performance, and interpretability make it the go-to for complex prediction tasks.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Model Selection in Ensembles
When designing machine learning ensembles, data scientists need to take a strategic approach to improve performance. Researchers should choose base learners that focus on diversity, using a mix of algorithms such as decision trees, support vector machines, and neural networks. They should apply techniques like bagging by adjusting important parameters, including the number of estimators, maximum depth, and minimum sample size skills that directly influence model performance and are often reflected in Machine Learning Engineer Salary benchmarks. For boosting methods, practitioners must work on refining learning rates, the number of estimators, and tree complexity to improve predictive power. When creating stacking strategies, data scientists should pick a suitable meta-learner, like logistic regression, and carefully manage cross-validation folds. To reduce the risk of overfitting, researchers can use strong evaluation techniques such as cross-validation and out-of-bag scoring. Sophisticated model selection methods, including nested cross-validation and Bayesian hyperparameter tuning tools like Optuna and Hyperopt, help data scientists optimize algorithms across various machine learning techniques.
Ensemble Techniques in Deep Learning
Deep Ensemble Techniques
Used in domains like Alzheimer’s classification, where ensemble deep models outperform single models Combining XGBoost with deep nets improves tabular data performance. Deep ensembles improve calibration, robustness, and accuracy particularly in high-stakes applications.
Conclusion
Ensemble learning is a method where machine learning experts combine multiple models to improve predictive performance. Researchers use different techniques like bagging, boosting, stacking, and deep ensemble methods to reduce variance and fix bias, leading to stronger and more general predictions an essential focus in Machine Learning Training workflows. Data scientists have shown that frameworks such as XGBoost, random forests, and various ensemble models are effective in important areas, from data science competitions to complex applications in healthcare and finance. To make the most of ensemble learning, practitioners need to choose a variety of base learners, fine-tune hyperparameters with cross-validation, use strict evaluation methods to avoid overfitting, and select ensemble techniques that fit the task and the data. This careful approach helps ensemble learning push the limits of predictive modeling, providing more advanced and reliable artificial intelligence solutions.

