
Last updated on 11th Aug 2025| 12310
- Introduction to Long Short Term Memory
- Need for LSTM
- LSTM Architecture Explained
- Gates in LSTM: Input, Forget, Output
- How LSTM Handles Sequence Data
- LSTM vs Traditional RNN
- Applications of LSTM (Text, Audio, Time Series)
- Code Example with Keras/TensorFlow
- Conclusion
Introduction to Long Short Term Memory
Long Short-Term Memory (LSTM) is a specialized type of Recurrent Neural Network (RNN) designed to model and learn from sequential data. Traditional RNNs struggle with capturing long-term dependencies due to problems like vanishing gradients during training. LSTM addresses this by incorporating memory cells and gating mechanisms that regulate the flow of information, allowing the network to remember or forget information over extended sequences. This unique architecture enables LSTM networks to excel at tasks involving time-series data, natural language processing, speech recognition, and other applications where context over time is crucial. By effectively managing information across many time steps, LSTMs have become a foundational tool in modern deep learning. Recurrent Neural Networks (RNNs) are a class of neural networks that excel at handling sequential data. Unlike feedforward neural networks, RNNs have connections that form cycles, allowing them to retain a form of memory. This memory makes RNNs suitable for tasks where the order of input data is important, such as time series forecasting, natural language processing, and audio signal processing. RNNs work by taking in a sequence of inputs and producing a sequence of outputs, with each output depending on both the current input and the previous hidden state. However, standard RNNs face challenges like vanishing and exploding gradients, which make them ineffective for learning long-range dependencies. Recurrent Neural Networks (RNNs) are a specialized class of artificial neural networks designed for processing sequential data. Unlike traditional feedforward neural networks, RNNs have loops in their architecture that allow information to persist across time steps. This makes them particularly effective for tasks where the order of inputs matters, such as natural language processing, time series forecasting, and speech recognition. The key feature of an RNN is its ability to maintain a “memory” of previous inputs using its hidden state. As it processes each element of a sequence, the RNN updates this hidden state based on both the current input and the previous hidden state, allowing it to learn temporal patterns and dependencies. Despite their strengths, RNNs face challenges such as vanishing and exploding gradients, which can make Machine Learning Training difficult over long sequences. To overcome these limitations, advanced variants like Long Short Term Memory (LSTM) and Gated Recurrent Units (GRU) were developed. These architectures include gating mechanisms that help preserve information over longer time spans.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Need for LSTM
- While Recurrent Neural Networks (RNNs) are designed to handle sequential data by maintaining a memory of previous inputs, they struggle with learning long-term dependencies.
- This is due to the vanishing and exploding gradient problems during backpropagation through time.
- As a result, standard RNNs often fail to capture important patterns when the gap between relevant information and its use becomes too large for example, in long sentences or time series with delayed effects.
- Long Short-Term Memory (LSTM) networks were introduced to address these limitations. LSTMs use a more sophisticated internal structure that includes memory cells and gating mechanisms (input, forget, and output gates) to control the flow of information.
- This allows them to retain important information over long periods and selectively forget irrelevant data, making them far more effective at modeling long-term dependencies than traditional RNNs.
- Long Short Term Memory LSTMs have been highly successful in applications such as machine translation, speech recognition, gradients, natural language and text generation tasks where context over time is critical.
- Their ability to learn from long sequences while avoiding the training issues of standard RNNs makes them a vital advancement in sequence modeling.
LSTM Architecture Explained
LSTM units are composed of a cell, an input gate, a forget gate, and an output gate. The cell remembers values over arbitrary time intervals, and the gates regulate the flow of information into and out of the cell.
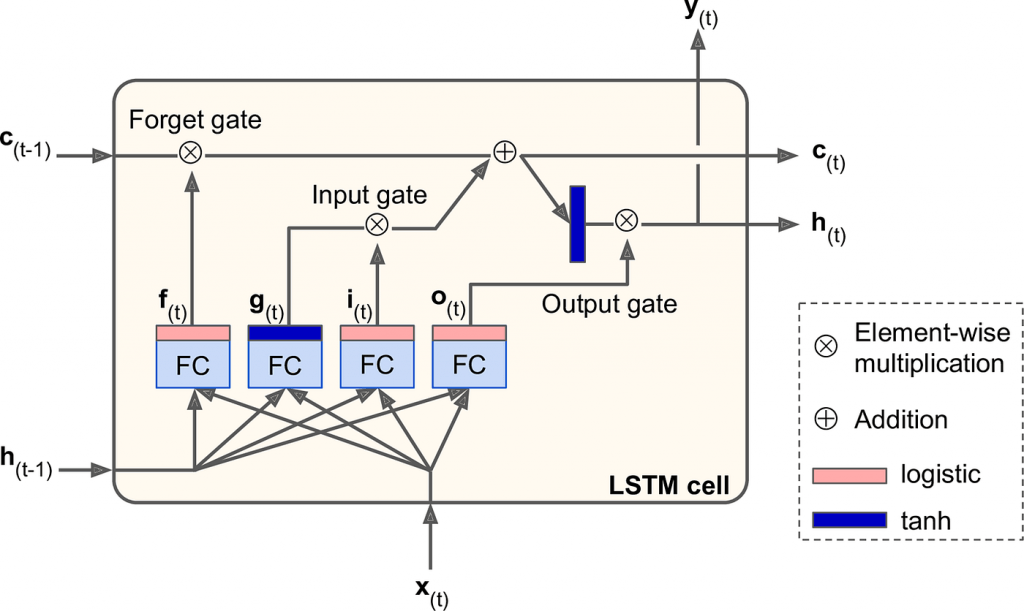
Key Components:
- Cell State: The cell state acts as a memory conveyor belt, carrying relevant information across time steps. The gates modify this state to add or remove information as needed.
- Forget Gate: This gate decides what information to discard from the cell state. It uses a sigmoid activation function to output values between 0 and 1—where 0 means “completely forget” and 1 means “completely keep.”
- Input Gate: The input gate controls how much new information is added to the cell state. It has two parts: a sigmoid layer to decide what values to update, and a tanh layer to create candidate values.
- Output Gate: This gate decides what information from the cell state is passed to the hidden state and the output. The combination of the cell state and the gate’s output forms the final hidden state for the time step.
LSTM’s gating mechanism enables it to retain important information over long sequences, making it ideal for tasks like text generation, machine translation, and time series prediction.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Gates in LSTM: Input, Forget, Output
- Forget Gate: The forget gate decides what information to discard from the cell state. It takes the previous hidden state and current input and passes them through a sigmoid function:
- Input Gate: The input gate decides what new information to add to the cell state:
- Output Gate: The output gate determines the value of the next hidden state:
ft = sigmoid(Wf · [ht-1, xt] + bf)<
it = sigmoid(Wi · [ht-1, xt] + bi)
Ct~ = tanh(Wc · [ht-1, xt] + bc)
Ct = ft * Ct-1 + it * Ct~
ot = sigmoid(Wo · [ht-1, xt] + bo)
ht = ot * tanh(Ct)

How LSTM Handles Sequence Data
LSTM Handles Sequence Data one element at a time while maintaining a hidden state that is carried forward. For a sequence [x1, x2, …, xn], the network processes each element while updating its internal states. This sequential processing allows LSTM networks to learn dependencies across time steps. For example, in language modeling, LSTMs can learn the context required to predict the next word in a sentence by remembering previous words. Long Short Term Memory (LSTM) networks are specifically designed to handle sequence data by capturing both short- and long-term dependencies. In traditional RNNs, each element in a sequence is processed one at a time, with information passed from one time step to the next. However, RNNs struggle with retaining information over long sequences due to vanishing gradients during Machine Learning Training. LSTMs overcome this limitation through a more complex internal architecture that includes a cell state and three gates input, forget, and output. These gates regulate the flow of information, allowing the network to remember or forget data selectively as it processes each step in the sequence. When LSTM processes a sequence, it updates its internal memory (cell state) at every time step based on both the current input and the hidden state from the previous step. The forget gate removes irrelevant information, the input gate adds new, useful data, and the output gate determines what information is passed to the next layer or output. This design allows LSTMs to effectively model context over time, making them ideal for applications like natural language processing, speech recognition, and time series forecasting, where the meaning or outcome depends on earlier inputs in the sequence.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
LSTM vs Traditional RNN
Traditional RNNs suffer from short-term memory due to gradient vanishing or explosion during backpropagation through time (BPTT). LSTMs solve this by using gates to regulate the flow of gradients, thereby preserving long-term dependencies.
Comparison:
- Memory: RNNs have short memory; LSTMs have long-term memory.
- Training Stability: RNNs are unstable over long sequences; LSTMs are more stable.
- Complexity: LSTMs have a more complex architecture.
- Performance: LSTMs generally outperform RNNs in tasks with long sequences.
Applications of LSTM (Text, Audio, Time Series)
LSTM networks have found applications in various domains:
- Sentiment analysis
- Machine translation
- Text generation
- Speech recognition
- Voice synthesis
- Audio event detection
- Stock market prediction
- Weather forecasting
- Anomaly detection in sensor data
Text Processing
Audio Processing
Time Series
Code Example with Keras/TensorFlow
- import numpy as np
- import tensorflow as tf
- from tensorflow.keras.models import Sequential
- from tensorflow.keras.layers import LSTM, Dense
- # Generate dummy sequential data
- x_train = np.random.random((100, 10, 1))
- y_train = np.random.random((100, 1))
- # Build LSTM model
- model = Sequential()
- model.add(LSTM(50, input_shape=(10, 1)))
- model.add(Dense(1))
- model.compile(optimizer=’adam’, loss=’mean_squared_error’)
- model.fit(x_train, y_train, epochs=10, batch_size=16)
This example demonstrates a basic LSTM model with 50 units, trained on dummy sequence data with 10 time steps and 1 feature per step.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Conclusion
LSTM networks have revolutionized how we process sequence data, offering a solution to the challenges posed by traditional RNNs. With their gated architecture, Machine Learning Training LSTMs can retain information over long periods, making them suitable for complex tasks in text, audio,Keras, LSTM Handles Sequence Data, natural language and time series domains. However, their computational complexity and limitations in handling very long sequences have led to the rise of alternatives like GRUs and Transformers. Despite this, Long Short Term Memory LSTMs remain a cornerstone in the toolkit of any deep learning practitioner working with sequential data. Mastery of LSTM architecture and its applications paves the way for tackling a broad spectrum of AI challenges.




