
Last updated on 13th Aug 2025| 12540
- Introduction to Deep Learning
- Difference Between ML and Deep Learning
- Neural Network Basics
- Activation Functions and Optimizers
- Feedforward vs Recurrent Neural Networks
- Convolutional Neural Networks (CNNs)
- Overfitting and Regularization
- Building a Deep Learning Model Step-by-Step
- Real-World Applications
- Future Scope
Introduction to Deep Learning
Deep learning is a subfield of machine learning that focuses on algorithms inspired by the structure and function of the brain, known as artificial neural networks. It enables computers to learn from large amounts of data and perform tasks such as image and speech recognition, natural language processing, and even playing strategic games with superhuman performance capabilities thoroughly explored in Machine Learning Training, where learners master supervised and unsupervised learning, deep neural networks, and real-world deployment strategies across domains like vision, NLP, and reinforcement learning. Deep learning excels at automatically extracting high-level features from raw data and has revolutionized many industries, including healthcare, finance, entertainment, and transportation.
Difference Between ML and Deep Learning
Reinforcement Learning (RL) has the potential to bring about significant change, but it faces tough challenges that need smart solutions. Despite its promise, RL runs into major issues, including sample inefficiency. This means it often needs many interactions to learn well. We can tackle this with techniques like model-based approaches and experience replay. Sparse rewards add to the difficulty, as delayed or rare feedback can slow down the agent’s development. Strategies such as reward shaping and hierarchical reinforcement learning can help. To complement these reinforcement learning challenges with structured evaluation metrics, exploring Confusion Matrix in Machine Learning reveals how classification outcomes true positives, false positives, true negatives, and false negatives are organized into a matrix that helps assess model accuracy, precision, recall, and error types, guiding more effective tuning and feedback strategies in sparse-reward environments. Training stability is also a big concern. Deep RL models need careful tuning of hyperparameters and methods like target networks to achieve steady results. Generalization is another issue since RL agents can overfit to specific training environments. Domain randomization and curriculum learning can help with this. Importantly, safety and ethical issues are critical, especially in high-stakes areas like healthcare and self-driving cars, where unexpected behaviors from the agent could lead to serious outcomes.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Neural Network Basics
At the heart of deep learning are artificial neural networks, inspired by the human brain’s structure. A basic neural network consists of: input layers, hidden layers, and output layers that process data through weighted connections and activation functions. To complement these architectures with ensemble learning strategies, exploring Bagging vs Boosting in Machine Learning reveals how bagging reduces variance by training models independently on random subsets, while boosting reduces bias by sequentially correcting errors both enhancing neural network stability and generalization.
- Input Layer: Receives the raw data.
- Hidden Layers: Consist of neurons (nodes) that process the input data using weights and biases.
- Output Layer: Produces the final prediction or classification.
Each neuron computes a weighted sum of its inputs, applies an activation function, and passes the result to the next layer. This structure allows the network to learn complex patterns.
Activation Functions and Optimizers
Activation Functions introduce non-linearity into the network, enabling it to learn from complex data. Common activation functions include:
- Sigmoid: Outputs values between 0 and 1; useful for binary classification.
- Tanh: Outputs values between -1 and 1; better than sigmoid for zero-centered data.
- ReLU (Rectified Linear Unit): Most commonly used; efficient and effective.
- Leaky ReLU and ELU: Variants that address the dying neuron problem.
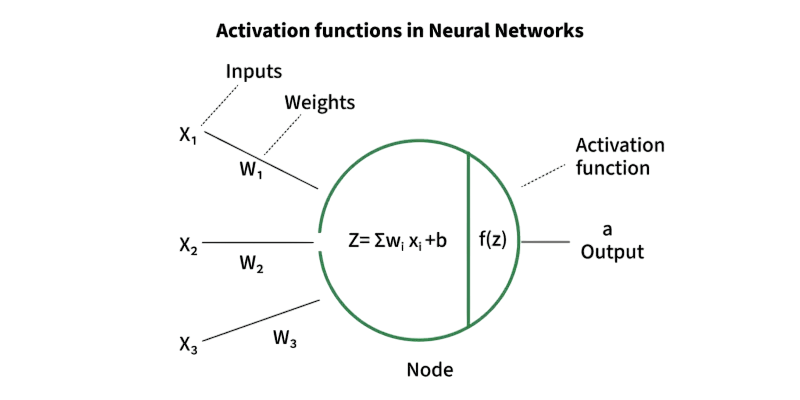
Optimizers
Optimizers adjust the weights of the neural network to minimize the loss function. Popular optimizers include:
- Stochastic Gradient Descent (SGD): Updates weights using a random subset of data.
- Adam (Adaptive Moment Estimation): Combines the advantages of AdaGrad and RMSprop.
- RMSprop: Adjusts the learning rate based on a moving average of recent gradients.
Choosing the right activation function and optimizer is crucial for efficient and effective model training.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Feedforward vs Recurrent Neural Networks
Neural networks include a variety of designs, each suited for different computational challenges. Feedforward Neural Networks (FNN) are the basic model. They have a one-way data flow from input to output, which makes them effective for tasks where inputs and outputs are independent. On the other hand, Recurrent Neural Networks (RNN) are designed to work with sequential data like time series and text. To understand how these architectures fit into the broader landscape, exploring What Is Machine Learning reveals how core techniques like regression, classification, clustering, and anomaly detection empower systems to learn from data automating predictions and uncovering patterns across diverse domains.
They have unique loop structures that allow information to persist. This feature makes RNNs well-suited for complex tasks such as language modeling, speech recognition, and machine translation. To overcome the limits of traditional RNNs, new architectures like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) were developed. These models offer better ways to capture long-term dependencies and allow for more efficient processing of sequential data.

Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a powerful deep learning architecture designed to process images and spatial data efficiently. These networks have key components, including convolutional layers that use special filters to pull out important visual features like edges and textures. Pooling layers reduce the size of the data and help prevent overfitting core concepts covered in Machine Learning Training, where learners explore deep learning architectures, optimize neural networks, and apply CNNs to real-world tasks like image classification and object detection. Fully connected layers handle the final classification based on the extracted features. With these methods, CNNs have changed computer vision technologies. They have led to important improvements in applications like image classification, object detection, and facial recognition. Their ability to learn and recognize complex patterns makes them essential in modern artificial intelligence and machine learning.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Overfitting and Regularization
Overfitting
Occurs when a model learns the training data too well, including noise and outliers, leading to poor generalization on new data.
Techniques to Prevent Overfitting:
- Regularization (L1, L2): Adds a penalty term to the loss function.
- Dropout: Randomly disables neurons during training.
- Early Stopping: Stops training when validation performance starts to degrade.
- Data Augmentation: Increases dataset size by altering existing data.
These techniques ensure the model generalizes well to unseen data.
Building a Deep Learning Model Step-by-Step
Machine learning model development follows a clear and repetitive process. It starts with defining the specific problem type, such as classification or regression. Data preparation is essential. This includes thorough cleaning, normalization, and splitting the data into training, validation, and test sets. Choosing the right model architecture for the problem, such as using Convolutional Neural Networks (CNNs) for image tasks, lays the groundwork for success. Next, researchers compile the model by carefully specifying optimizers, loss functions, and evaluation metrics. They then train the model on the prepared dataset. Detailed evaluation with validation and test sets helps measure performance. Iterative hyperparameter tuning, which involves adjusting learning rates, batch sizes, and training epochs, enhances the model’s capabilities. To complement these training workflows with robust classification techniques, exploring Support Vector Machine (SVM) Algorithm reveals how SVMs construct optimal hyperplanes using kernel functions enabling precise separation of classes, efficient handling of high-dimensional data, and strong generalization even with limited samples. The last stage is deploying the model through APIs or integrating it directly into applications. This process usually requires several experimental iterations to get the best results. It highlights the importance of ongoing improvements and flexibility in developing machine learning models.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Real-World Applications
Deep learning is used across a wide range of domains: from autonomous driving and speech recognition to medical diagnostics and financial forecasting. To complement these neural architectures with interpretable models, exploring Decision Trees in Machine Learning reveals how tree-based algorithms segment data through hierarchical splits offering visual clarity, low entropy classification, and transparent logic that supports decision-making in both structured and unstructured environments.
- Healthcare: Disease detection, medical imaging, drug discovery.
- Finance: Fraud detection, algorithmic trading, credit scoring.
- Retail: Recommendation systems, inventory management, customer analytics.
- Entertainment: Content recommendation, facial recognition in photos.
- Transportation: Autonomous vehicles, route optimization.
- Manufacturing: Predictive maintenance, quality control.
These applications highlight the transformative impact of deep learning across industries.
Future Scope
The future of deep learning looks promising, with trends including transformer-based architectures, multimodal learning, federated training, and edge deployment topics actively explored in Machine Learning Training, where learners stay ahead of the curve by mastering emerging techniques, scalable frameworks, and real-world applications across industries.
- Self-Supervised Learning: Reducing reliance on labeled data.
- Multimodal Learning: Combining vision, language, and audio for richer understanding.
- Neuro-Symbolic AI: Integrating neural networks with symbolic reasoning.
- Federated Learning: Training models across decentralized devices while preserving privacy.
- AI Hardware Advances: Development of specialized chips for faster training and inference.
As deep learning continues to evolve, it will enable new capabilities and redefine what’s possible with artificial intelligence.

