
Last updated on 11th Oct 2025| 12805
- What is a Go Game?
- What is AlphaGo?
- Background and history of AlphaGo
- Who is Lee Sedol?
- AlphaGo vs Lee Sedol case study
- Further Development in AlphaGo
- Application of AlphaGo in Game Strategies
- Impact and Legacy
- Conclusion
What is Go Game?
Go is an ancient board game originating from China over 2,500 years ago, renowned for its strategic depth and elegance. Played on a grid of 19×19 lines, two players black and white take turns placing stones on the intersections with the goal of controlling territory. Unlike chess, which emphasizes direct attacks and piece value, Go focuses on balance, influence, and long-term strategy, Machine Learning Training where even a small move can have ripple effects across the board. The rules are deceptively simple: surround empty points to create territory, capture opponent stones by encircling them, and avoid repeating board positions. Despite this simplicity, the game generates a near-infinite number of possible configurations, making it incredibly complex. Go has fascinated mathematicians, AI researchers, and strategic thinkers for centuries. Modern AI, like DeepMind’s AlphaGo, demonstrated Go’s challenge by defeating top human players, highlighting the game’s rich combination of intuition, pattern recognition, and tactical skill.
What is AlphaGo?
With its sophisticated algorithms and machine learning, AlphaGo is a revolutionary creation in the area of artificial intelligence that is revolutionizing strategic decision-making processes. In artificial intelligence, AlphaGo is a DeepMind program that can play the complex and millennia-old board game Deep Learning with Apache Spark and Tensorflow of Go at a level that is above that of humans.
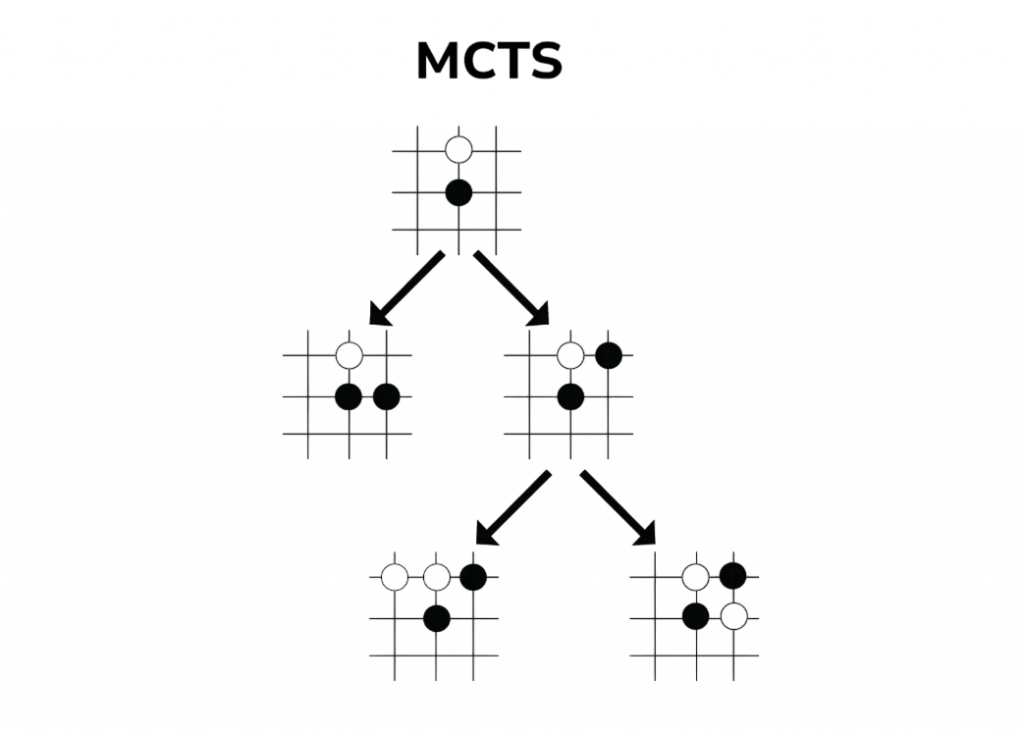
AlphaGo is composed of intricate components that collaborate to facilitate its stellar performance. In order to make it a master at Go, it employs advanced machine learning techniques such as deep neural networks and reinforcement learning. AlphaGo beats Lee Sedol. Though the system improves its gaming with reinforcement learning, through continuous self-improvement, neural networks are utilized to detect and evaluate board positions.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Background and history of AlphaGo
- Background and history of AlphaGo: AlphaGo’s roots lie in the pioneering efforts of DeepMind, a research facility for AI that sought to create new online game-playing software. In 2016, when AlphaGo beat world-renowned Go master Lee Sedol in a historic sequence of Go games, it made headlines globally. The milestone victory illustrated the potential of machine learning algorithms to excel in complex, strategic environments, and it was a turning point in the creation of AI systems.
- Key Milestones in the Development of AlphaGo: AlphaGo’s evolution has been characterized by major milestones that have revolutionized the domain Bagging vs Boosting in Machine Learning. Since its initial versions to its groundbreaking victory over human champions, AlphaGo beats Lee Sedol has evolved further, applying top-of-the-line strategies that have allowed it to reach unprecedented levels of performance.
Who is Lee Sedol?
In 1983, Lee was born in South Korea. ‘Bigeumdo Boy’ is his nickname, as he was born and raised on Bigeumdo Island. This is the story of machine learning, or rather, deep learning, proving its mettle hitherto unknown to the masses. In a record online game of Go, one of the world’s oldest board games that has been around in China for circa 2,500 years, it is the triumph of machines over men. Similar to playing four games on a single board, it is the most complex board game ever invented. Lee Sedol is a South Korean professional Go player, Machine Learning Training widely regarded as one of the greatest in the game’s history. Born in 1983, he became a 9-dan professional at a young age, earning numerous international titles and accolades throughout his career. Lee is best known globally for his historic 2016 match against Google DeepMind’s artificial intelligence program, AlphaGo. Although he lost the series 4-1, his single victory in the fourth game showcased human intuition and creativity, leaving a lasting legacy in the intersection of human skill and AI. Lee’s career has inspired generations of Go players worldwide.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
AlphaGo vs Lee Sedol case study
- Event: In March 2016, AlphaGo, an AI developed by DeepMind, played a five-game match against Lee Sedol, a 9-dan Go master.
- Significance: AlphaGo vs Lee Sedol case study.
- Lee Sedol’s Victory: He won the fourth game, demonstrating human intuition and the ability to exploit unconventional AI moves What Is Machine Learning .
- Impact on AI Research: The match highlighted the power of deep learning and reinforcement learning in mastering complex tasks.
- Global Attention: The event drew worldwide interest, emphasizing the intersection of human skill and artificial intelligence.

Further Development in AlphaGo
A crucial milestone in AI was achieved with the development of AlphaGo, and its progeny, AlphaGo Zero and AlphaZero, have taken it further. A summary of their contributions and impact is given below:
- Generalization of Algorithm: AlphaZero could learn and master different games, showcasing the flexibility and potential of general-purpose algorithms in AI.
- Versatility and Learning Efficiency: It learned to play each game to a world-champion level within hours of self-training, without any specific domain knowledge other than the basic rules of the games.
- Creative and Dynamic Play Styles: Particularly in chess, AlphaZero demonstrated a highly dynamic and unconventional style of play, which was often described as creative and inspiring by experts.
- Self-Play Reinforcement Learning: By competing against itself in games, AlphaGo Zero progressively improved its strategy through a process called reinforcement learning, beginning with random plays An Overview of ML on AWS.
- Single Neural Network: It simplified the architecture of the original AlphaGo by using a single neural network. Both board positions and moves were predicted by this network.
- Superior Performance: It quickly surpassed not only all previous versions of AlphaGo but also all human knowledge in Go, achieving superhuman performance.
AlphaZero: DeepMind created AlphaZero, which built on the approach of AlphaGo Zero anA crucial milestone in AI was achieved with the development of AlphaGo, Decision Trees in Machine Learning and its progeny, AlphaGo Zero and AlphaZero, have taken it further.
Key Features and Innovations:
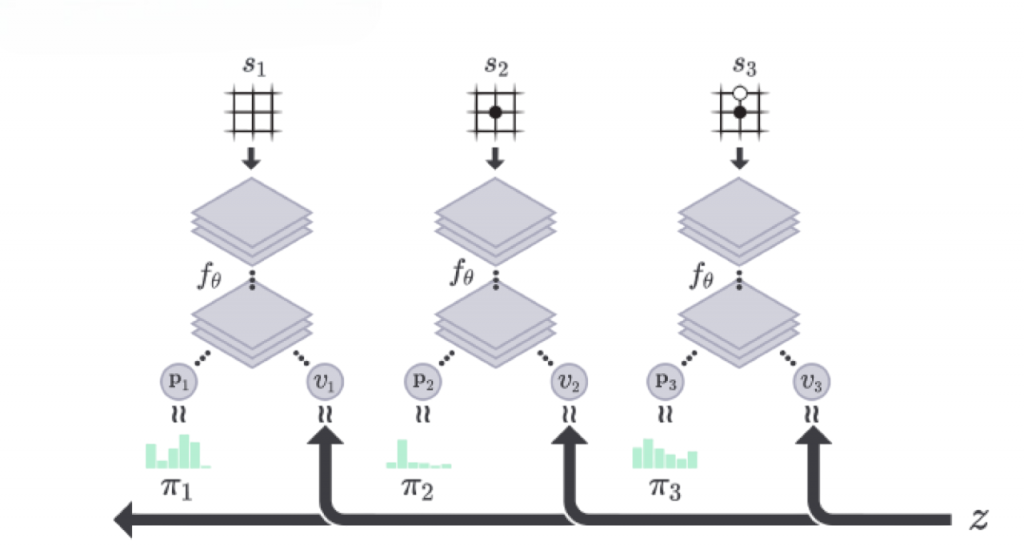
AlphaGo Zero: DeepMind developed AlphaGo Zero, a groundbreaking achievement in AI capabilities, after the success of the initial AlphaGo. AlphaGo Zero differed from its predecessor by learning entirely on its own based solely on the basics of Go and without human game data.
Key Features and Innovations
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Application of AlphaGo in Game Strategies
We look at how AlphaGo impacts strategic games with a solid understanding of its inner workings. AlphaGo is able to forecast opponent moves and adapt to different styles of play due to its value networks and policies. AlphaGo develops new strategies that defy traditional Go thinking and change the strategic terrain of the game by employing deep learning to study complex board positions.
- Positional Judgment: AlphaGo excels at evaluating the positional value of moves, considering factors such as territory control, influence, and potential for future expansion.
- Influence-Based Strategies: AlphaGo leverages its deep neural networks to assess the influence of moves on the overall board position, favoring moves that maximize influence over key areas.
- Flexible Tactical Responses: AlphaGo demonstrates remarkable flexibility in responding to tactical situations, adapting its strategies based on the evolving board state.
- Strategic Sacrifices: AlphaGo is unafraid to sacrifice stones strategically to achieve larger strategic goals, Machine Learning Engineer Salary such as securing territory or exerting influence.
- Long-Term Planning: AlphaGo exhibits sophisticated long-term planning capabilities, anticipating future developments and crafting strategies that unfold over multiple moves.
- Pressure and Influence: AlphaGo applies relentless pressure on opponents, leveraging its deep understanding of positional play to gradually squeeze out advantages.
- Balance of Territory and Influence: AlphaGo strikes a delicate balance between securing territory and exerting influence, optimizing its strategic choices to maximize overall board control.
- Adversarial Thinking: AlphaGo adopts an adversarial mindset, anticipating and countering opponent moves while proactively seeking opportunities to exploit weaknesses.
- Pointers: AlphaGo’s strategic judgments are guided by its policy networks, which offer insights into the most promising moves in a certain board position.
Impact and Legacy
Outside of Games and Research:
- Other AI Applications: The solutions developed have implications beyond the realm of games, including scheduling, optimization problems, and even the creation of medications. Driving Motivations for AI Research: These developments have driven further AI research, particularly, areas that require the combination of reinforcement learning and deep learning.
- Self-Improvement and Reinforcement Learning: Two of the most crucial subjects for current AI research, self-improvement and end-to-end learning, have been achieved by AlphaGo Zero and AlphaZero. Minimal Human Input: They promoted research into more independent The Best Machine Learning Tools learning systems requiring less human intervention by emphasizing the promise of AI systems that do not depend on vast amounts of human-curated data.
Methodological Changes in AI:
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Conclusion
AlphaGo is the epitome of AI research, AI game-playing, and AI decision-making, highlighting the breakthrough potential of deep learning and reinforcement learning to tackle difficult decision-making problems. AlphaGo’s dominance remains unparalleled in the ancient game of Go, not only proving Machine Learning Training AI’s capabilities but also introducing new avenues of research in game theory, deep learning, and reinforcement learning. AlphaGo is a testament to human ingenuity and the boundless potential of artificial intelligence

