
Last updated on 30th Sep 2025| 10077
- Introduction to Apache Spark and Its Capabilities
- Setting Up Apache Spark Environment (Local & Cluster)
- Data Cleaning and Preprocessing Project with PySpark
- Building a Word Count Program Using Spark RDDs
- Real-Time Data Processing with Spark Streaming
- Spark SQL Project: Analyzing Structured Data
- E-commerce Recommendation Engine Using Spark MLlib
- Conclusion
Introduction to Apache Spark and Its Capabilities
Apache Spark is a powerful open-source distributed computing system designed for big data processing and analytics. Originally developed at UC Berkeley’s AMPLab, Spark provides an easy-to-use interface for processing large datasets quickly across clusters of computers. Unlike traditional batch processing systems, Spark supports both batch and real-time data processing, making it highly versatile for various data-driven applications. One of Spark’s key strengths is its in-memory computing capability, which significantly speeds up data processing tasks by reducing disk I/O operations. Data Science Training It supports multiple programming languages including Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. Spark’s ecosystem includes several built-in libraries for SQL queries (Spark SQL), machine learning (MLlib), graph processing (GraphX), and real-time data streaming (Spark Streaming). This comprehensive suite enables users to build complex data pipelines and advanced analytics applications efficiently. With its scalability, speed, and ease of use, Apache Spark has become a popular choice for industries like finance, healthcare, and e-commerce that require fast, reliable big data processing. Whether you are analyzing large datasets, building machine learning models, or processing streaming data, Spark offers the tools and flexibility to meet modern data challenges.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Setting Up Apache Spark Environment (Local & Cluster)
Local Setup:
- Install Java (JDK 8 or later) as Spark requires it to run.
- Download Apache Spark from the official website.
- Set environment variables like SPARK_HOME and update PATH.
- Run Spark in standalone mode on your local machine using spark-shell or pyspark.
- Use IDEs like IntelliJ or Jupyter Notebook for development Data Architect Salary in India .
- Choose a cluster manager: Standalone, Apache Hadoop YARN, or Apache Mesos.
- Configure Spark on each node in the cluster by installing Spark and Java.
- Set up SSH access for password-less communication between nodes.
- Configure Spark’s spark-env.sh and spark-defaults.conf for cluster settings.
- Deploy the Spark master and worker nodes.
- Submit jobs to the cluster using spark-submit with appropriate resource configurations.
- Monitor cluster health using Spark’s Web UI.
- Optionally integrate with Hadoop HDFS or cloud storage for data input/output Data Integration .
- Use containerization (Docker, Kubernetes) for easier cluster deployment and management.
- Project Objective: Clean and prepare raw data to improve its quality and make it suitable for analysis or machine learning.
- Data Loading: Use PySpark’s SparkSession to load datasets from sources like CSV, JSON, or Parquet files.
- Handling Missing Values: Identify and handle missing data by removing rows, filling with default values, or using imputation techniques.
- Data Type Conversion: Convert columns to appropriate data types (e.g., strings to integers or timestamps) to ensure accurate processing.
- Removing Duplicates: Cassandra Keyspace Detect and remove duplicate records to maintain data integrity.
- Filtering and Cleaning: Apply filters to remove invalid or irrelevant data. Use PySpark functions to trim spaces, correct typos, and standardize formats.
- Feature Engineering: Create new columns based on existing data, such as extracting date parts, calculating ratios, or encoding categorical variables.
- Data Transformation: Normalize or scale numeric columns and encode categorical features using techniques like one-hot encoding or label encoding.
- Saving Cleaned Data: Export the cleaned and preprocessed data back to storage for downstream tasks.
- rdd = spark.sparkContext.textFile(“hdfs://…/input.txt”)
- counts = (rdd.flatMap(lambda line: line.split())
- .map(lambda w: (w.lower(), 1))
- .reduceByKey(lambda a, b: a + b))
- counts.saveAsTextFile(“hdfs://…/wordcounts”)
- stream = spark.readStream \
- .format(“socket”) \
- .option(“host”, “localhost”) \
- .option(“port”, 9999) \
- .load()
- words = stream.selectExpr(“explode(split(value, ‘ ‘)) AS word”)
- count = words.groupBy(“word”).count()
- query = (count.writeStream
- .outputMode(“complete”)
- .format(“console”)
- .start())
- query.awaitTermination()
- Objective: Build a personalized product recommendation system to improve user experience and increase sales.
- Data Collection: Gather user behavior data such as clicks, purchases, ratings, and browsing history.
- Data Preparation: Clean and preprocess data using Spark to handle missing values, duplicates, and normalize features.
- Feature Engineering: Create user and product features, such as purchase frequency, product categories, and user preferences.
- Model Selection: Use Spark MLlib’s collaborative filtering algorithm (ALS – Alternating Least Squares) Data Governance for building recommendations based on user-item interactions.
- Training: Split data into training and testing sets; train the ALS model using Spark’s distributed computing capabilities.
- Evaluation: Measure model accuracy with metrics like RMSE (Root Mean Squared Error) to fine-tune parameters.
- Prediction: Generate top-N product recommendations for each user.
- Deployment: Integrate the recommendation engine into the e-commerce platform for real-time personalized suggestions.
- Scalability: Leverage Spark’s distributed architecture to handle large datasets and support real-time updates.
Cluster Setup:
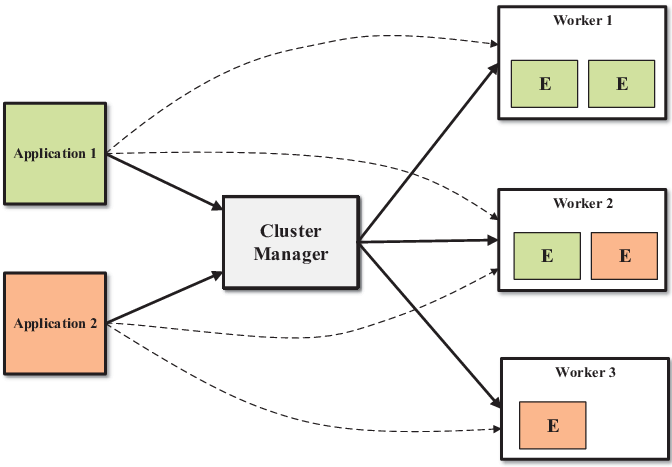
Additional Tools:
Data Cleaning and Preprocessing Project with PySpark
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Building a Word Count Program Using Spark RDDs
A classic entry-level Spark project, Data Science Training using RDDs to count words in a large text:
This helps grasp RDD transformations and actions, and Spark’s distributed architecture.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Real-Time Data Processing with Spark Streaming
Apache Spark Certification Demonstrate live data processing (e.g., logs, tweets, IoT) using either DStreams or Structured Streaming.
Example (TCP stream word count):
Process and visualize real-time insights from streaming data.

Spark SQL Project: Analyzing Structured Data
Spark SQL is a powerful module in Apache Spark that allows users to run SQL queries on large-scale structured data with high efficiency. In a typical Spark SQL project, structured data from sources such as CSV files, JSON, or databases is loaded into DataFrames, which provide a distributed collection of data organized into named columns. Users can then leverage familiar SQL syntax to query, filter, aggregate, Apache Hive vs HBase and join datasets, making complex data analysis straightforward and intuitive.
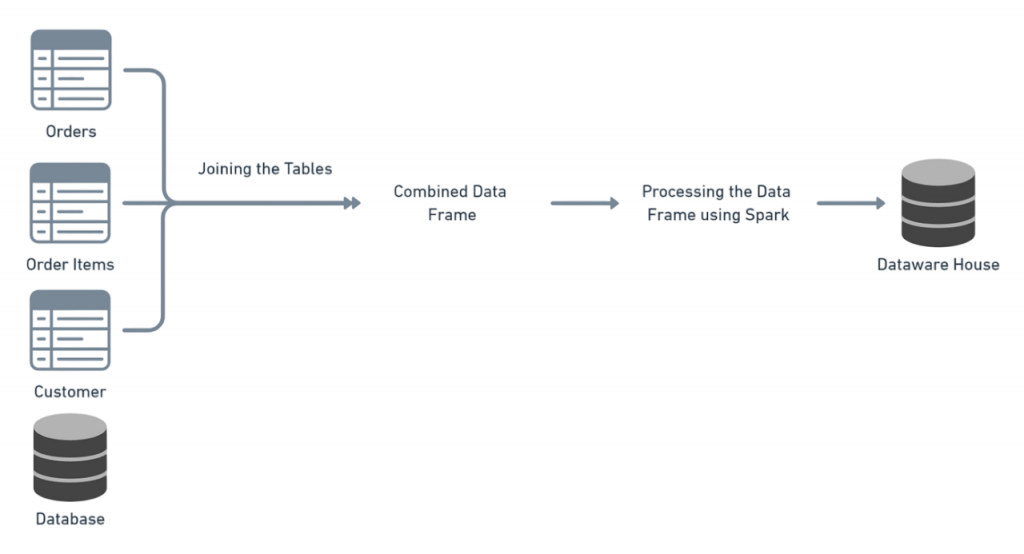
Spark SQL optimizes query execution through its Catalyst optimizer and Tungsten execution engine, ensuring fast performance even with massive datasets. This project often involves tasks like exploring data patterns, calculating key metrics, and generating reports that help businesses make informed decisions. By combining the ease of SQL with the scalability of Spark, Spark SQL projects enable analysts and engineers to efficiently extract valuable insights from structured data in big data environments.
E-commerce Recommendation Engine Using Spark MLlib
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Ace Your Interview!
Conclusion
These projects cover Spark’s diverse capabilities from RDD and DataFrame processing to streaming, SQL, and ML with applications in e‑commerce, IoT, streaming analytics, and recommendation systems. They align with industry trends and provide experience in the full data pipeline from ingestion and processing to analysis and presentation. By implementing these projects, you’ll gain hands-on expertise in Spark and create a portfolio Data Science Training that demonstrates your data engineering and analytics skills. Let me know if you’d like code templates, Dockerfiles, or notebook versions of any of these examples. Data cleaning and preprocessing are critical steps in any data analysis or machine learning pipeline. Using PySpark enables handling large-scale datasets efficiently with distributed processing. This project demonstrates how to identify and address common data quality issues like missing values, duplicates, and inconsistent formats. By transforming raw data into a clean and structured format, PySpark empowers analysts and data scientists to build more accurate models and gain meaningful insights. Mastering these preprocessing techniques lays a strong foundation for advanced big data analytics and real-world applications.




