
Last updated on 08th Oct 2025| 10494
- Introduction to Hadoop and Spark
- Architecture Comparison
- Batch vs Real-Time Processing
- Programming Models
- Performance Metrics
- Cost and Maintenance
- Industry Adoption
- Ecosystem and Tool Support
- Future Trends
- Conclusion
Introduction to Hadoop and Spark
With the explosion of data in the digital age, organizations are increasingly relying on powerful frameworks to store, manage, and process big data frameworks. In today’s data-driven world, organizations rely heavily on big data frameworks to store, process, and analyze massive datasets efficiently. Apache Hadoop and Apache Spark are two leading big data frameworks, each with its own strengths, and are often covered in any comprehensive Data Science course Two strong tools for distributed data processing, Apache Hadoop and Apache Spark, allow enterprises to manage enormous datasets across clusters. Spark improves distributed data processing through in-memory computation and real-time capabilities, whereas Hadoop depends on disk-based storage and the MapReduce paradigm. The comparison between Hadoop Spark highlights two of the most popular big data frameworks used for large-scale data processing.
Architecture Comparison
Apache Hadoop Architecture consists primarily of two components:
- HDFS (Hadoop Distributed File System): A scalable file storage system that distributes data across multiple nodes.
- MapReduce : A programming model for batch processing of large datasets.
- YARN (Yet Another Resource Negotiator): Manages resources across the cluster.
Each processing job in Hadoop reads data from HDFS, performs operations, and writes back the result, often resulting in high disk I/O and latency an architectural contrast also seen in debates likeTMRW Cassandra vs MongoDB. Both Hadoop and Spark are essential components of contemporary data analytics, allowing businesses to effectively handle and examine massive datasets. Spark’s real-time processing capabilities make it perfect for interactive and streaming data analytics, while Hadoop is best suited for batch-oriented data analytics jobs.
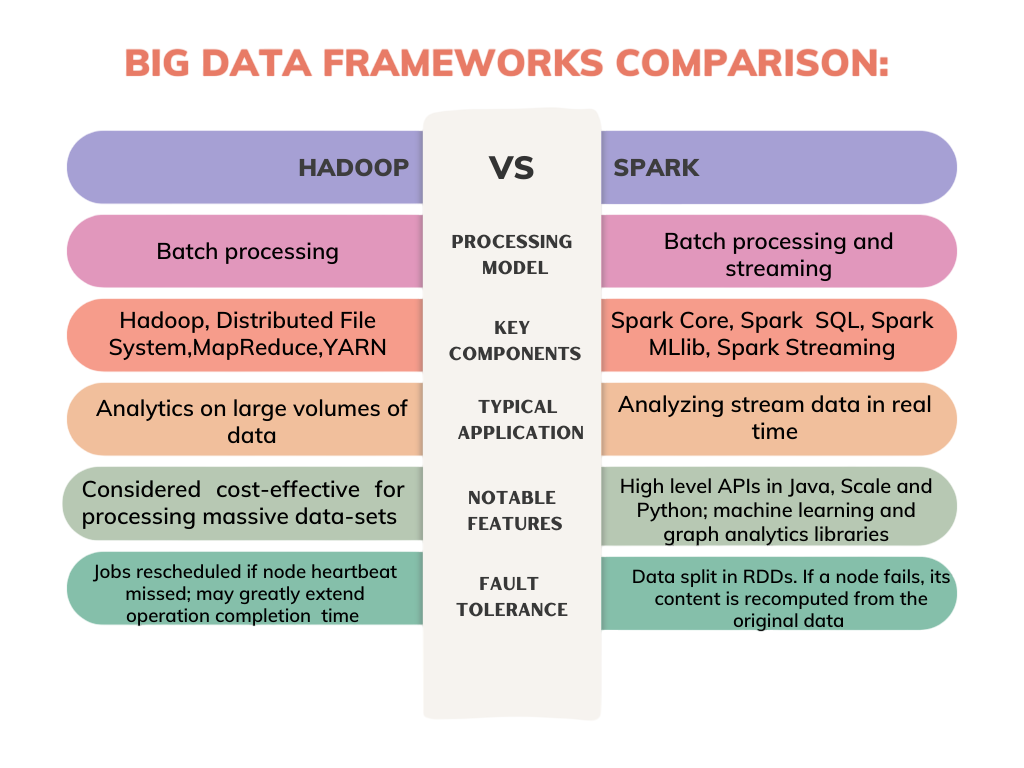
Apache Spark Architecture, on the other hand, is designed for in-memory computing. Key components include:
- Driver Program : Initiates Spark jobs and converts them into tasks.
- Cluster Manager : Manages the cluster and assigns resources.
- Executors : Run the tasks and return the results to the driver.
- RDDs (Resilient Distributed Datasets): Immutable distributed collections that allow transformations and actions.
Unlike Hadoop, Spark stores intermediate results in memory, reducing disk I/O and enabling faster execution.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Batch vs Real-Time Processing
- Monthly report generation
- Data archival
- Log analysis
- Spark Streaming allows processing of live data streams.
- Structured Streaming provides higher-level APIs for streaming jobs.
- Map Phase – Processes input data into key-value pairs.
- Reduce Phase – Aggregates data based on keys.
- Java
- Scala
- Python (PySpark)
- Up to 100x faster performance for certain workloads.
- Lower latency for iterative algorithms like machine learning and graph processing.
- Reduced disk I/O, which is a major performance bottleneck in Hadoop.
- For CPU-bound batch jobs on commodity hardware: Hadoop is reliable.
- For memory-bound iterative or real-time jobs: Spark is far superior.
- Runs well on commodity hardware.
- Storage costs are lower due to disk-based design.
- Larger clusters needed for performance scalability.
- Requires skilled professionals to manage HDFS, YARN, and tuning of MapReduce jobs—key competencies for building a Successful Career in Big Data Hadoop Spark:
- Requires higher memory capacity.
- Smaller clusters can deliver high performance.
- Reduces job execution time, which may lower cloud computation costs.
- Maintenance and optimization are easier due to concise APIs and better community support.
- Hive: Data warehouse layer for querying using SQL.
- Pig: Data flow language for transformation.
- HBase: NoSQL database over HDFS.
- Sqoop and Flume: Data ingestion tools.
- Oozie: Workflow scheduler. Spark Ecosystem:
- Spark SQL: For querying structured data.
- MLlib: Machine learning library.
- GraphX: Graph processing.
- Spark Streaming: Real-time stream processing.
- Delta Lake / Apache Hudi: Enable ACID transactions and data lake capabilities.
- Hadoop is expected to decline in popularity as real-time requirements increase.
- Spark continues to evolve with structured streaming, Kubernetes-native deployment, and Delta Lake integration.
- Unified platforms like Databricks (built on Spark) are gaining ground in enterprise analytics.
However, Hadoop is not designed for real-time processing. Integrations with tools like Apache Storm or Apache Flink are needed to process streaming data, which adds complexity.
Spark supports both batch and real-time processing natively, making it a key technology behind many of the 10 Real-Life Big Data Applications discussed in modern analytics.
This makes Spark suitable for scenarios like fraud detection, monitoring systems, and interactive data analysis.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Programming Models
Hadoop’s programming model is based on Java and the MapReduce paradigm, which consists of:
This model is powerful but can be verbose and complex for iterative tasks or workflows
Spark provides a more flexible and developer-friendly programming model, which is why it’s often recommended in guides like Avoid These Top 5 Mistakes when choosing big data tools. It supports APIs in:
Spark’s core abstraction, the RDD, allows users to apply transformations (like map, filter) and actions (like count, collect). It also supports DataFrames and Datasets for structured data, making data manipulation similar to SQL or Pandas in Python. This versatility makes Spark easier to adopt for data scientists and developers familiar with high-level languages.In the age of cloud computing, Hadoop and Spark are crucial frameworks that make big data processing scalable and effective. Due to its in-memory features and ease of deployment, Spark has been a popular choice for many organisations as cloud computing has grown. Spark and Hadoop are both still developing to better interface with cloud computing platforms and provide adaptable solutions for a range of data workloads.

Performance Metrics
Performance is a crucial factor in deciding between Hadoop and Spark. While Hadoop is disk-based and reads/writes data to HDFS between every MapReduce job stage, Spark keeps data in-memory, leading to:
However, Spark’s in-memory nature also demands more RAM, a point often emphasized in a Data Science course when discussing resource requirements for big data tools. In low-memory environments or when data size exceeds memory, Spark can degrade in performance due to frequent disk spillovers.
In summary:
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Cost and Maintenance
Cost is not only about software but also about infrastructure and human resources.
Hadoop:When run on cloud platforms like AWS EMR or Google Dataproc, Spark tends to be more cost-efficient for high-speed processing and iterative tasks, while Hadoop is better for long-running, low-priority jobs.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Industry Adoption
Hadoop was the standard for big data in the early 2010s and is still used in many legacy systems. Enterprises like Yahoo, Facebook, and LinkedIn built large-scale Hadoop clusters to manage data. Spark, however, has rapidly gained popularity since 2014 and is now favored by companies like Netflix, Uber, and Airbnb for its speed and flexibility qualities that also make it well-suited for implementing and optimizing An ETL Audit Process. It has become the default choice for data science and machine learning workloads. In modern cloud-native environments, Spark is more readily adopted due to compatibility with Kubernetes, integration with cloud storage, and support for modern analytics tools.Spark’s in-memory capability makes it the tool of choice for iterative algorithms, while Hadoop remains a good fit for high-throughput storage-heavy workloads.
Ecosystem and Tool Support
Both Hadoop and Spark have rich ecosystems, but they differ in integration and community support.
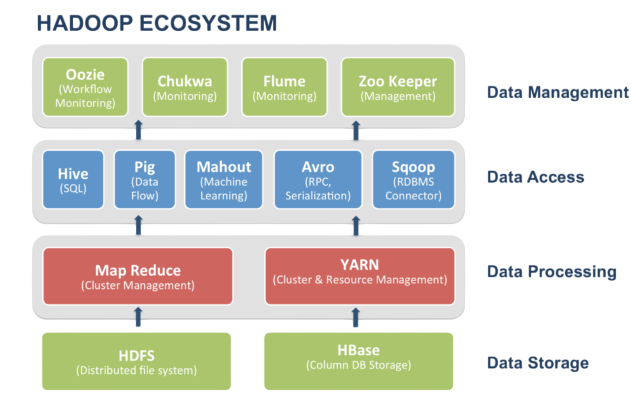
Although many Hadoop ecosystem tools now integrate with Spark, Spark’s unified engine and libraries offer a more seamless and scalable experience, as emphasized in Key Hadoop Skills for Success highlighting the importance of understanding both platforms.
Future Trends
The big data landscape is moving toward real-time, cloud-native, and AI-powered platforms. In this future:
Moreover, the industry is witnessing a shift toward serverless data processing, where Spark-as-a-Service is offered by platforms like AWS Glue and GCP DataProc Serverless making deployment and scalability effortless. Hadoop will continue to be used in legacy and high-volume archival storage systems, but Spark is poised to dominate future data workflows, especially those that involve real-time insights and AI.
Conclusion
In the ever-evolving world of big data, selecting the right tool can dramatically impact performance, cost, and development velocity. Hadoop and Spark each have their strengths Hadoop is reliable and robust for traditional batch processing,While Spark offers unparalleled speed and versatility across a wider range of modern use cases, it is frequently highlighted in any Data Science course as a go-to tool for scalable analytics. Whether you’re building a real-time analytics dashboard or processing petabytes of data in a nightly job, understanding the trade-offs between these two frameworks is essential. By aligning your technology stack with your organizational needs and technical capabilities, you can unlock the full potential of big data.




