
Last updated on 07th Oct 2025| 10176
- Introduction
- What is Apache Spark?
- History and Evolution of Apache Spark
- Core Components of Apache Spark
- Apache Spark Architecture Explained
- Key Features and Capabilities
- Spark Ecosystem and Libraries
- Apache Spark vs Hadoop MapReduce
- Conclusion
Introduction
As the volume of data generated by organizations has exploded, the need for fast, scalable, and flexible data processing frameworks has become more critical than ever. Traditional systems like Hadoop MapReduce, while revolutionary at the time, introduced significant limitations such as high latency, rigid processing models, and disk I/O overhead. To overcome these bottlenecks and build scalable, intelligent data workflows, enrolling in Data Science Training is a strategic step equipping professionals with modern tools and techniques to design low-latency, high-throughput solutions that go beyond legacy architectures. Businesses today require real-time analytics, machine learning capabilities, and faster data insights to stay competitive in the digital landscape. This demand paved the way for Apache Spark, a lightning-fast, in-memory data processing engine that offers a more versatile, user-friendly, and powerful alternative to earlier big data tools.
What is Apache Spark?
Apache Spark is an open-source unified analytics engine for large-scale data processing. Designed for speed, ease of use, and sophisticated analytics, Spark enables developers and data scientists to write applications in Java, Scala, Python, R, and SQL that can process massive datasets efficiently. Spark is known for its ability to perform in-memory computation, which drastically reduces the time it takes to process data compared to disk-based systems like Hadoop MapReduce. To extend this performance into live data pipelines, explore Apache Spark Streaming a powerful engine for real-time analytics that processes continuous data streams with low latency across distributed clusters. It supports batch processing, stream processing, machine learning, and graph computation, all under a single unified engine. Simply put, Apache Spark is the backbone of modern big data analytics and is widely used across industries such as finance, healthcare, retail, telecommunications, and more.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
History and Evolution of Apache Spark
Apache Spark was born at UC Berkeley’s AMPLab in 2009 as a research project aimed at overcoming the inefficiencies of Hadoop MapReduce. The team wanted to build a data processing engine that could handle iterative algorithms (like those in machine learning) and interactive data analysis more efficiently. To bridge Hadoop with traditional databases, explore What Is Apache Sqoop a tool designed to efficiently transfer bulk data between Hadoop and structured datastores like MySQL, Oracle, and PostgreSQL.
- 2010: Spark was open-sourced.
- 2013: Spark became an Apache Incubator project.
- 2014: Spark was promoted to a top-level Apache project.
- Now: Spark is one of the most active projects in the Apache ecosystem with contributions from hundreds of companies.
Major companies like Netflix, Alibaba, Uber, Pinterest, and NASA use Apache Spark at scale to handle data-intensive workloads.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Core Components of Apache Spark
Apache Spark is composed of several fundamental components that together create a powerful data processing platform. To see how these capabilities translate into real-world impact, explore PayPal Leverages Big Data Analytics a case study revealing how Spark’s scalability, speed, and modular design empower PayPal to detect fraud, personalize services, and optimize transaction flows across billions of data points.
- Spark Core: The foundation of Spark, responsible for task scheduling, memory management, fault recovery, and interacting with storage systems like HDFS, S3, and Cassandra. It includes the RDD (Resilient Distributed Dataset) API for low-level transformations and actions.
- Spark SQL: Provides a DataFrame API and supports SQL queries over structured and semi-structured data. Enables querying data using familiar SQL syntax, with support for Hive compatibility, JDBC, and Thrift server access.
- Spark Streaming: Facilitates real-time stream processing of live data. Converts streaming data into micro-batches for fault-tolerant and scalable processing.
- MLlib (Machine Learning Library): Built-in library for machine learning and statistical algorithms like classification, regression, clustering, and recommendation. Supports pipelines, tuning, and model evaluation.
- GraphX: A library for graph computation using Spark’s RDDs. Enables analytics on data structured as graphs like social networks, page ranking, etc.
These components allow Spark to offer end-to-end big data solutions in a single platform.

Apache Spark Architecture Explained
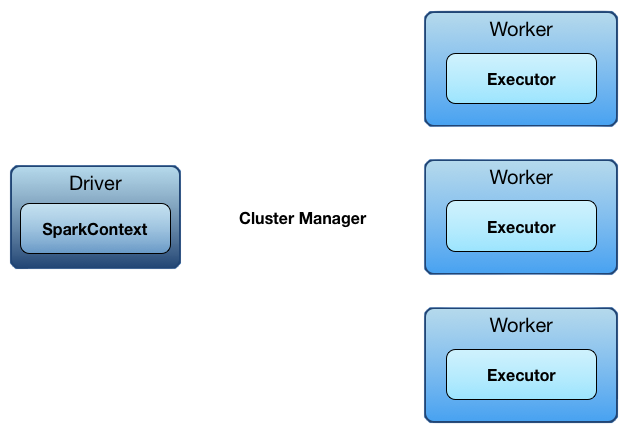
Apache Spark Architecture uses a unique master-slave design to manage distributed computing tasks efficiently, even in complex environments. The main system is guided by a driver program that handles the entire application life cycle and serves as the key entry point through SparkContext. To master this orchestration and build production-grade data workflows, enrolling in Data Science Training is a smart move equipping learners with the skills to manage Spark’s execution model, optimize resource allocation, and scale applications across distributed environments. This driver interacts effectively with various cluster managers like Standalone, YARN, Apache Mesos, and Kubernetes, which allocate resources for different applications in a flexible way. The workers on the nodes where the executors are sent perform the tasks. They process parts of the job and store information for quicker access. By using Directed Acyclic Graphs (DAGs), Spark can optimize execution plans better than traditional MapReduce models. Apache Spark Architecture capability allows for more flexible and manageable data processing workflows that can be adjusted to meet different computational needs.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Key Features and Capabilities
Apache Spark is a powerful data processing framework that offers a remarkable set of features. It has transformed how we manage analytics on a large scale. Spark uses in-memory computing to reduce wait times to nearly zero, enabling very fast data transformations. It also supports several programming languages, including Python, Scala, Java, R, and SQL, giving it great flexibility. With its unified engine, Spark can combine batch processing, streaming analytics, machine learning, and graph computations all on one platform without any difficulties.
The strong design of the framework helps prevent data loss during errors, using RDD lineage and data replication. Its smart lazy evaluation method enhances computational efficiency by only considering processing when it is necessary. To integrate Spark with scalable messaging systems, explore What is Apache Kafka a distributed event streaming platform that enables high-throughput, fault-tolerant data pipelines across real-time applications. Spark is built for large-scale operations, making it easy to handle petabytes of data across thousands of nodes. It offers many deployment options, including local machines, cloud services, and on-premises clusters. Additionally, Spark integrates well with various tools like HDFS, Hive, Cassandra, and Kafka.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Spark Ecosystem and Libraries
Apache Spark Ecosystem is supported by a rich tools and libraries that extend its functionality. To complement Spark’s analytical power with scalable search capabilities, explore Apache SolrCloud a distributed search platform that enables fault-tolerant indexing, real-time querying, and seamless data discovery across large-scale datasets.
- Delta Lake: Adds ACID transactions, schema enforcement, and time travel to Spark data lakes.
- Apache Kafka + Spark: Enables real-time ingestion and processing of streaming data.
- Koalas: Bridges the gap between Pandas and Spark DataFrames for easier migration.
- Airflow or Oozie: Workflow schedulers that orchestrate Spark jobs.
- MLflow: Tracks, packages, and deploys machine learning models with Spark integration.
This vibrant ecosystem supports the entire data lifecycle from ingestion and transformation to analytics and machine learning.
Apache Spark vs Hadoop MapReduce
Apache Spark is often compared to Hadoop MapReduce, its predecessor in large-scale data processing. To understand how these technologies fit into broader analytical roles, explore Data Science vs Data Analytics vs Big Data a comparative guide that clarifies the distinctions between predictive modeling, business intelligence, and scalable infrastructure in today’s data-driven landscape.
| Feature | Apache Spark | Hadoop MapReduce |
|---|---|---|
| Speed | In-memory, faster (up to 100x) | Disk-based, slower |
| Ease of Use | Rich APIs, interactive shells | Java-based, complex programming |
| Latency | Low (real-time, micro-batch) | High (batch-oriented) |
| Processing Types | Batch, Streaming, ML, Graph | Batch only |
| Data Caching | Yes | No |
| Deployment | Local, cloud, YARN, Kubernetes | YARN, cloud |
| Fault Tolerance | Through RDD lineage | Through replication and retries |
While MapReduce is still used in legacy systems, Spark is now the de facto standard for new big data projects due to its flexibility and performance.
Conclusion
Apache Spark has fundamentally transformed how organizations process and analyze big data. Its speed, scalability, and unified architecture make it the go-to solution for modern data engineering, analytics, and machine learning tasks. Whether you’re building a streaming analytics engine, training predictive models, or transforming petabytes of data, Spark provides the tools and performance required for today’s data-driven world. With ongoing support from the open-source community and enterprise contributions, Spark continues to evolve, making it a future-proof investment for teams aiming to build robust data platforms. To harness its full potential, enrolling in Data Science Training is a strategic move equipping professionals with the skills to design, deploy, and optimize Spark-powered solutions across real-world scenarios. Its integration with modern cloud services, ML frameworks, and real-time engines ensures that Apache Spark will remain at the forefront of big data innovation for years to come.




