
Last updated on 08th Oct 2025| 10110
- Introduction Gleam of Analytics
- What is Apache Spark?
- Spark’s Rise: From MapReduce to Lightning-Fast Processing
- The Core Features That Make Spark Shine
- Spark vs. Traditional Big Data Tools
- Real-Time Processing: Spark Streaming in Action
- Spark in Machine Learning and AI Workflows
- The Role of Spark in Modern Data Architectures
- Industries Transformed by Spark Analytics
- Conclusion
Introduction Gleam of Analytics
In today’s data-centric world, Gleam of Analytics represents the shift from simply understanding what happened to predicting what will happen next instantly and at scale. As businesses generate massive volumes of data from countless sources, the tools they depend on must be both fast and flexible. Apache Spark has emerged as the gleaming light in this evolution, reshaping analytics with its unmatched speed and versatility. To turn this technological momentum into career growth, explore Data Science Training a hands-on program that equips professionals with the skills to build scalable models, interpret complex datasets, and drive intelligent business outcomes. Where earlier frameworks struggled with sluggish processing or clunky development cycles, Spark has provided a unified platform that allows businesses to run complex analytics workloads efficiently, whether for batch, real-time, or machine learning tasks truly embodying the Gleam of Analytics in the modern data era.
What is Apache Spark?
Apache Spark is an open-source, distributed computing engine designed for fast and scalable data processing. Initially developed at UC Berkeley’s AMPLab, it has become one of the most powerful engines in the Apache big data ecosystem. Spark allows developers to write applications quickly in Java, Scala, Python, or R and run them across clusters of computers. To explore more technologies that support scalable analytics and real-time processing, visit Data Analytics Tools for Big Data a detailed article that highlights key platforms, programming languages, and frameworks used to extract insights from massive datasets. At its core, Spark provides a resilient, in-memory data processing framework that can handle everything from SQL queries and streaming analytics to machine learning and graph computation all within a single unified environment. This has made it a go-to platform for modern analytics solutions across industries.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Spark’s Rise: From MapReduce to Lightning-Fast Processing
- Before Spark, MapReduce was the reigning standard for big data processing. While MapReduce was groundbreaking for its time, it had major limitations especially in terms of speed and flexibility. Every step of data processing required writing results to disk, which made iterative tasks like machine learning or real-time analytics inefficient.
- Spark challenged that model by introducing in-memory computing, drastically reducing latency. It allowed datasets to be stored in RAM across the cluster, which significantly sped up operations. This breakthrough made Spark 100x faster than MapReduce in many scenarios, turning it into the natural successor for high-performance analytics tasks.
- In-Memory Computing: Allows repeated access to data without writing to disk, which accelerates complex workflows.
- Unified Analytics Engine: Supports SQL (via Spark SQL), streaming data (via Spark Streaming), machine learning (via MLlib), and graph analytics (via GraphX).
- Rich API Support: Developers can choose from Scala, Python, Java, or R, making Spark highly accessible and versatile.
- Lazy Evaluation: Spark builds execution plans that optimize performance before any data is actually processed.
- Fault Tolerance: Through its RDDs (Resilient Distributed Datasets), Spark can recover from node failures automatically.
- Clean and prepare datasets at scale
- Train models across distributed environments
- Apply predictive analytics in real-time
- Integrate models with streaming pipelines for continuous learning
- Finance: Real-time risk analytics, fraud detection, and customer segmentation
- Healthcare: Large-scale genomic data analysis, medical image processing, and personalized treatments
- Retail: Recommendation engines, inventory forecasting, and dynamic pricing models
- Telecommunications: Network optimization, churn prediction, and call detail record analysis
- Media & Entertainment: Viewer behavior analysis, content recommendation, and A/B testing
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
The Core Features That Make Spark Shine
Several features contribute to Spark’s reputation as the ultimate analytics platform: in-memory processing, fault tolerance, and seamless integration with diverse data sources. These capabilities thrive in environments where decisions are backed by evidence and insights. To explore how organizations foster this mindset, visit Data-Driven Culture an insightful article that highlights the values, practices, and technologies that turn raw data into strategic advantage.
Together, these features form a cohesive platform that delivers high-speed, flexible, and fault-tolerant analytics.

Spark vs. Traditional Big Data Tools
While Hadoop’s MapReduce was foundational, Spark outperforms it in almost every critical dimension. MapReduce works well for sequential, disk-heavy operations, but falters in scenarios requiring multiple steps or real-time responses. Spark, on the other hand, was built for interactive and iterative processing, making it ideal for machine learning, real-time dashboards, and dynamic ETL jobs. Compared to other tools like Hive or Pig, Spark brings unmatched speed and capability.
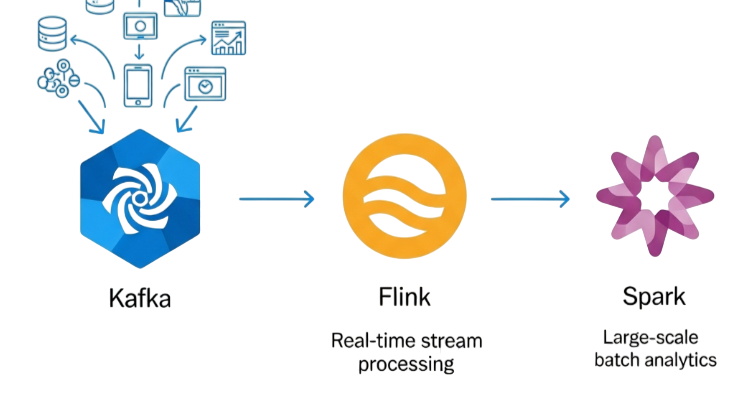
To gain hands-on experience with these advanced workflows, explore Data Science Training a practical program designed to help professionals master scalable analytics, intelligent automation, and real-time data engineering. Hive queries that take minutes can be executed in seconds with Spark SQL. Similarly, Spark Streaming processes data in near real-time, whereas traditional batch frameworks require waiting until data is stored and partitioned.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Real-Time Processing: Spark Streaming in Action
This solution changes how businesses engage with data by allowing fast processing in less than a second. It takes in live information streams from sources like Kafka, Flume, and Amazon Kinesis and uses a micro-batching setup to deliver almost instant analytical results. This ability helps organizations shift from analyzing past data to making decisions based on current insights. Key use cases include real-time fraud detection in finance, live analysis of clickstreams for e-commerce, constant monitoring of IoT sensor networks, and dynamic delivery of personalized content. To understand how these diverse data streams are unified for actionable intelligence, visit Data Integration Guide a practical article that explores tools, techniques, and architectures for seamless data consolidation across platforms. Essentially, its processing speed lets companies seize opportunities and manage risks more quickly than ever before.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Spark in Machine Learning and AI Workflows
Spark is not just a data processing engine, it’s a platform for intelligent analytics. With MLlib, Spark provides a powerful, scalable machine learning library that supports classification, regression, clustering, and recommendation algorithms. To ensure these models operate within ethical, secure, and compliant boundaries, visit Data Governance an essential article that explains the policies, frameworks, and controls needed to manage data responsibly across the analytics lifecycle.
Data scientists can use Spark to:
With support for integration with TensorFlow, XGBoost, and even deep learning frameworks, Spark is becoming an essential component in end-to-end AI pipelines.
The Role of Spark in Modern Data Architectures
Modern enterprises are shifting from monolithic systems to data lakes and microservices architectures. Spark fits perfectly in this environment, often serving as the core compute engine in big data platforms. It works seamlessly with storage systems like HDFS, Amazon S3, Google Cloud Storage, and Azure Blob. It also integrates with orchestrators like Kubernetes and workflow engines like Apache Airflow. To see how these capabilities translate into practical applications, visit Apache Spark with These Real-World Projects a hands-on article showcasing how Spark powers scalable solutions across industries like finance, healthcare, and e-commerce. As a result, Spark is often the engine behind ETL pipelines, ad-hoc data science experiments, real-time analytics dashboards, and predictive modeling environments. Its versatility means organizations can standardize on Spark for a broad range of data tasks, reducing overhead and improving scalability.
Industries Transformed by Spark Analytics
The impact of Spark can be seen across a wide range of industries: from real-time fraud detection in banking to genomic data analysis in healthcare. These applications often rely on robust data warehousing and retrieval systems. To compare two foundational technologies in this space, visit Apache Hive vs HBase a detailed article that explores their architectural differences, query models, and suitability for batch versus real-time workloads.
In each case, Spark’s ability to handle diverse data types, high velocity, and massive volumes has made it a critical asset in competitive and regulated environments.
Conclusion
Apache Spark has done more than just improve analytics, it has redefined what’s possible with data. Its blazing-fast performance, scalability, and ease of use have made it the tool of choice for both data engineers and data scientists. From batch processing to streaming, from ETL to AI, Spark delivers one of the most comprehensive platforms available for modern data workloads. To master these capabilities and apply them in real-world scenarios, explore Data Science Training a career-focused program that equips learners with hands-on experience in scalable analytics, machine learning workflows, and intelligent data engineering. As businesses increasingly rely on real-time insights and predictive intelligence, Spark will continue to be at the forefront. It is not just a framework, it’s the ultimate gleam of analytics, lighting the path to smarter, faster, and more innovative data-driven strategies.




